

October 5, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: June 18, 2026
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Das Konfigurationsmanagement ist ein wichtiger Aspekt der Softwareentwicklung. In diesem Artikel wird das Warum und Was des Problems sowie die Gründe für die verschiedenen Lösungen, die es gibt, beleuchtet.

Der Ansatz zur Verwaltung der Konfiguration ändert sich, wenn die App skaliert — sowohl in Bezug auf den Traffic als auch in Bezug auf die Größe des Entwicklerteams. Um die Reise zu veranschaulichen, beginnen wir mit einer einfachen App.
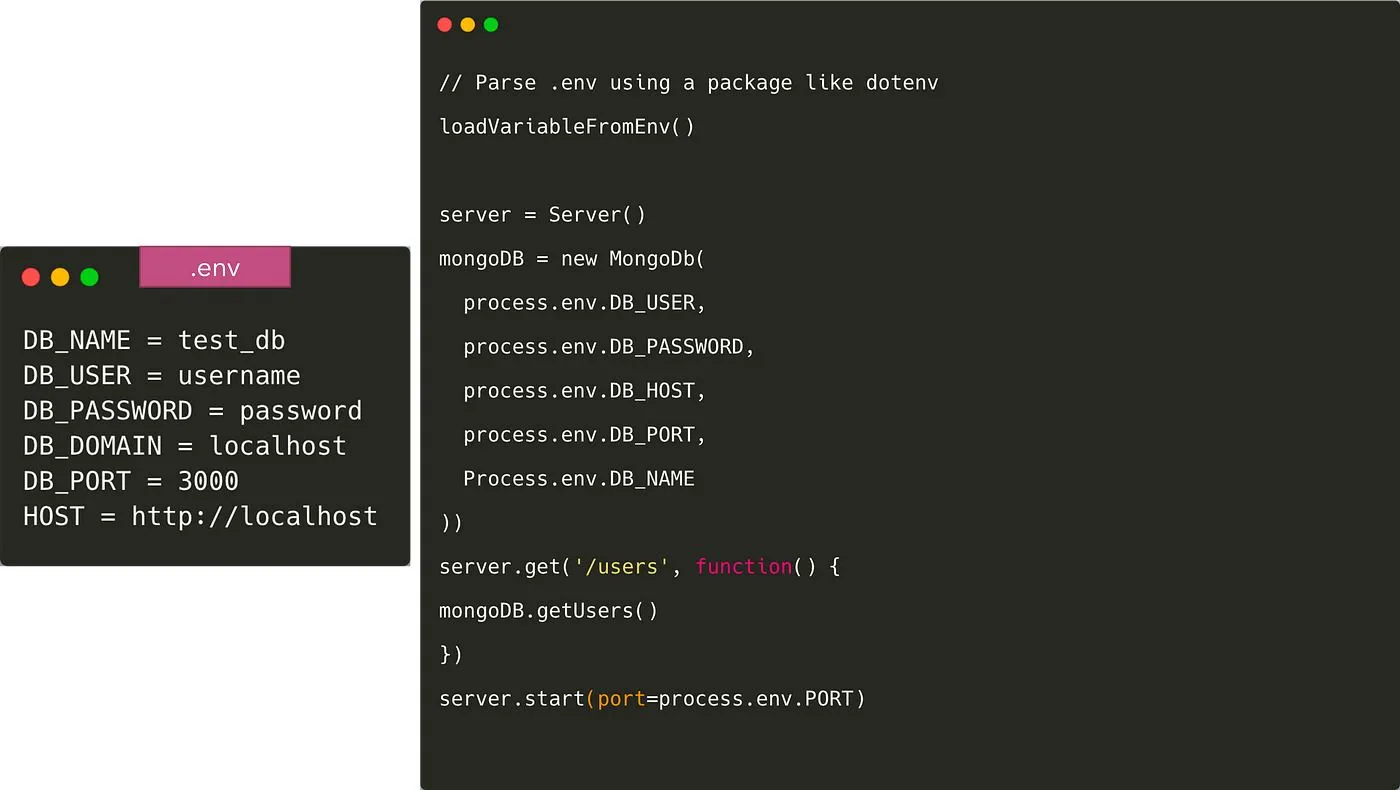
Dies ist eine einfache Server-App, die eine Verbindung zu MongoDB herstellt und die Liste der Benutzer zurückgibt. Der Code ist nur Pseudocode und soll keiner Sprache entsprechen.

Hardcode-Konfiguration in der App: ein GROSSES NEIN!

Wenn Sie die MongoDB-URI fest in die App einprogrammieren, wird es wirklich schwierig, die Anwendung in einer anderen Umgebung auszuführen — z. B. auf den Laptops anderer Teamkollegen oder für die Produktion. Wir sollten dem folgen 12-Faktor-App-Methodik hier, um die Konfiguration vom Code zu trennen.
„KONFIGURATION VOM CODE TRENNEN“
Nun stellt sich die Frage, was die Konfiguration einer App umfasst? Zitat von https://12factor.net/config
Eine App Konfiguration ist alles, was wahrscheinlich variieren wird zwischen bereitstellt (Staging, Produktion, Entwicklerumgebungen usw.). Dies beinhaltet:
1. Ressourcen-Handles für die Datenbank, Memcached und andere unterstützende Dienste
2. Anmeldeinformationen für externe Dienste wie Amazon S3 oder Twitter
3. Werte pro Bereitstellung, z. B. der kanonische Hostname für die Bereitstellung
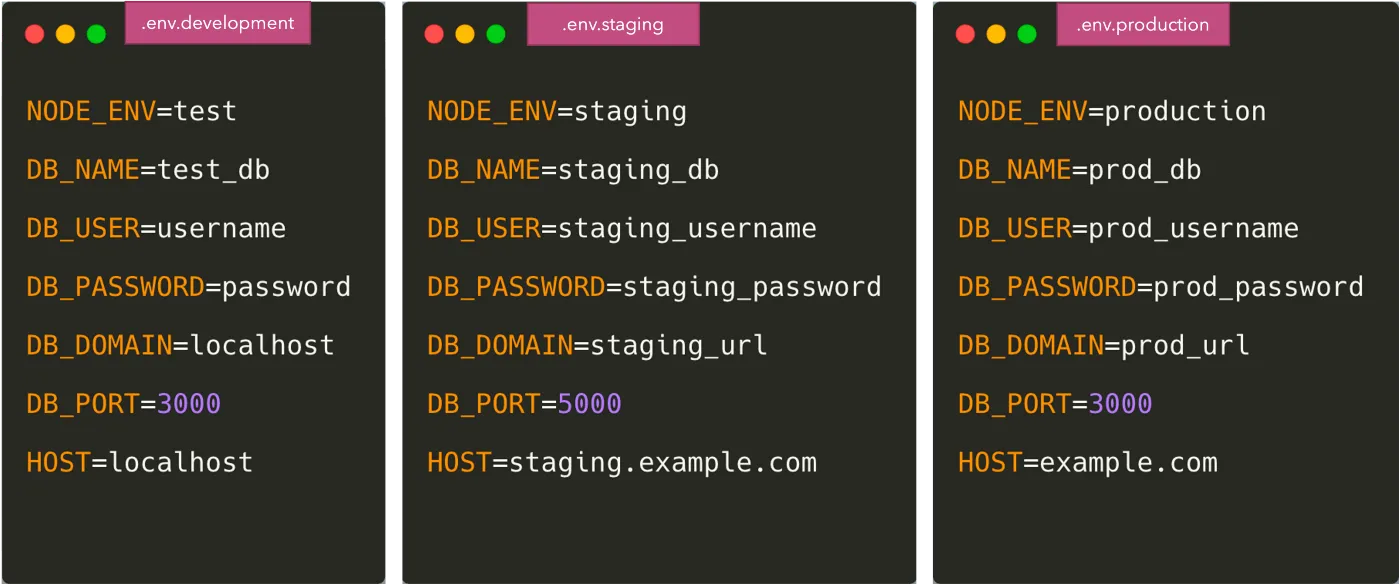
Die einfachste und gebräuchlichste Methode, die Konfiguration vom Code zu trennen, besteht darin, die Variablen in einer ENV-Datei abzulegen.
Sobald wir dies getan haben, müssen wir die Variablen im Code aus der Datei .env laden. Dazu gibt es mehrere Pakete dotenv und dotenv-expand. Die .env-Datei wird in diesem Fall nicht an Git übertragen und jeder Entwickler überschreibt die Variable entsprechend seiner eigenen Umgebung. Um allen Entwicklern eine Vorstellung davon zu geben, welche Umgebungsvariablen hinzugefügt werden müssen, übergeben wir normalerweise eine Datei wie .env.Beispiel zu Git.

Wir müssen auch Werte dieser Variablen in den Staging- und Produktionsumgebungen bereitstellen. Fast alle Bereitstellungssysteme bieten eine Möglichkeit, Umgebungsvariablen wie ConfigMap und Secrets in Kubernetes oder S3 für Elastic Container Service zu speichern und bereitzustellen.
Wir müssen diese Variablen in diese Umgebungen kopieren und sie synchronisieren, wenn Entwickler Umgebungsvariablen hinzufügen/entfernen. Ein möglicher Ansatz besteht darin, eine separate ENV-Datei für Staging-, Produktions- usw. Umgebungen zu verwenden.

Man kann vorschlagen, diese Dateien in Git zu speichern, aber es gibt eine großes Sicherheitsproblem in diesem Fall — speziell für einige der vertraulichen Anmeldeinformationen in den env-Dateien.
Die Menschen verwenden hier unterschiedliche Herangehensweisen — einige der bekanntesten Methoden sind jedoch:

Während wir eines dieser externen Systeme verwenden, haben wir jetzt die Konfiguration zwischen den.env-Dateien und den Secretmanagers aufgeteilt. Einige der nicht sensiblen Parameter stammen aus den.env-Dateien, andere aus dem Remote-Speicher der Anmeldeinformationen. Wir können argumentieren, dass wir alle Parameter im Remote-Speicher speichern können — aber das kann manchmal übertrieben sein. Am Ende haben wir also Folgendes:
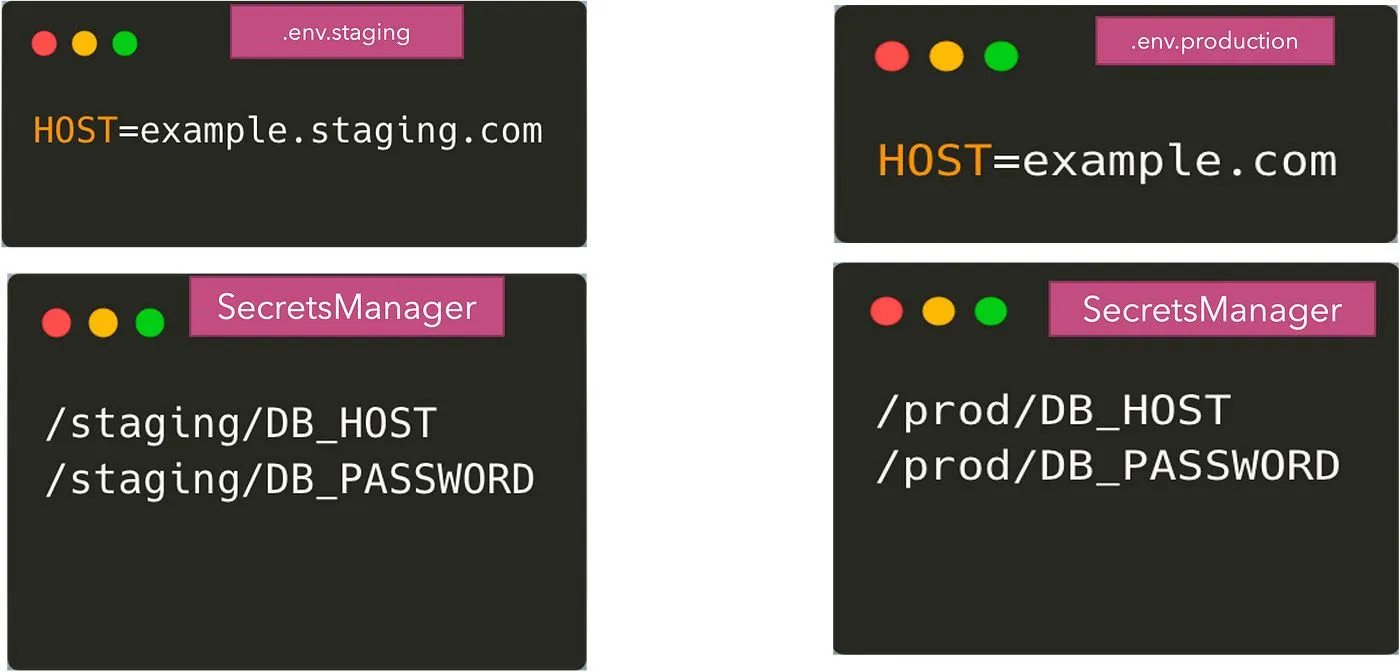
Unsere Anwendung benötigt jetzt Code zum Lesen aus diesen beiden Konfigurationsquellen. Das Lesen aus den.env-Dateien kann mit dem Paket dotenv erfolgen. Um die Umgebungsvariablen von den Secretmanagers abzurufen, müssen wir jedoch die entsprechenden APIs verwenden, um die Werte abzurufen.

Dies löst das Problem, unsere Konfiguration sicher zu halten und auch die 12-Faktoren-Methode zu befolgen.
Das Schreiben von Anwendungscode zum Abrufen von Geheimnissen ist jedoch eine sich wiederholende Praxis, bei der jede Anwendung jetzt Secretmanager-spezifischen Code hinzufügen muss, um die Werte von der API abzurufen. Das bedeutet auch, dass, wenn wir jemals unseren Secretsmanager-Anbieter ändern, der Code in allen Anwendungen geändert werden muss. Um dieses Problem zu lösen, gibt es mehrere Ansätze:
Das Konfigurationsmanagement ist komplex und sollte von Anfang an ordnungsgemäß durchgeführt werden, um sicherzustellen, dass die Geschwindigkeit der Entwickler hoch bleibt, ohne auf Sicherheitsaspekte zu verzichten. Kubernetes, das heute am häufigsten für die Bereitstellung von Anwendungen verwendet wird, verfügt über eine eigene Konfiguration und eine eigene Geheimverwaltung, auf die ich in einem anderen Artikel näher eingehen werde. Auch wenn Sie eine andere Methode für das Konfigurationsmanagement verwenden, erwähnen Sie dies bitte in den Kommentaren — ich würde gerne mehr erfahren und von Ihnen lernen!
Wahre Gießerei ist ein KI-Gateway für Unternehmen, das LLM, MCP und Agenten-Gateways umfasst und es Unternehmen ermöglicht, den Zugriff auf Modelle, Tools, Leitplanken und Agenten von einer einzigen Kontrollebene aus sicher zu verbinden, zu beobachten und zu steuern. Das AI Gateway ermöglicht folgende agentische Workloads:
a) Sicher — Lösung für Schlüsselverwaltung, Authentifizierung und Autorisierung
b) Effizient — Optimierung von Kosten, Latenz und Failovers für mehrere Regionen
c) Zukunftssicher — ermöglicht einheitliche und zusammensetzbare Verbindungen zwischen LLMs, MCPs und Guardrails von jedem Anbieter
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.








.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




