

October 5, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 27, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
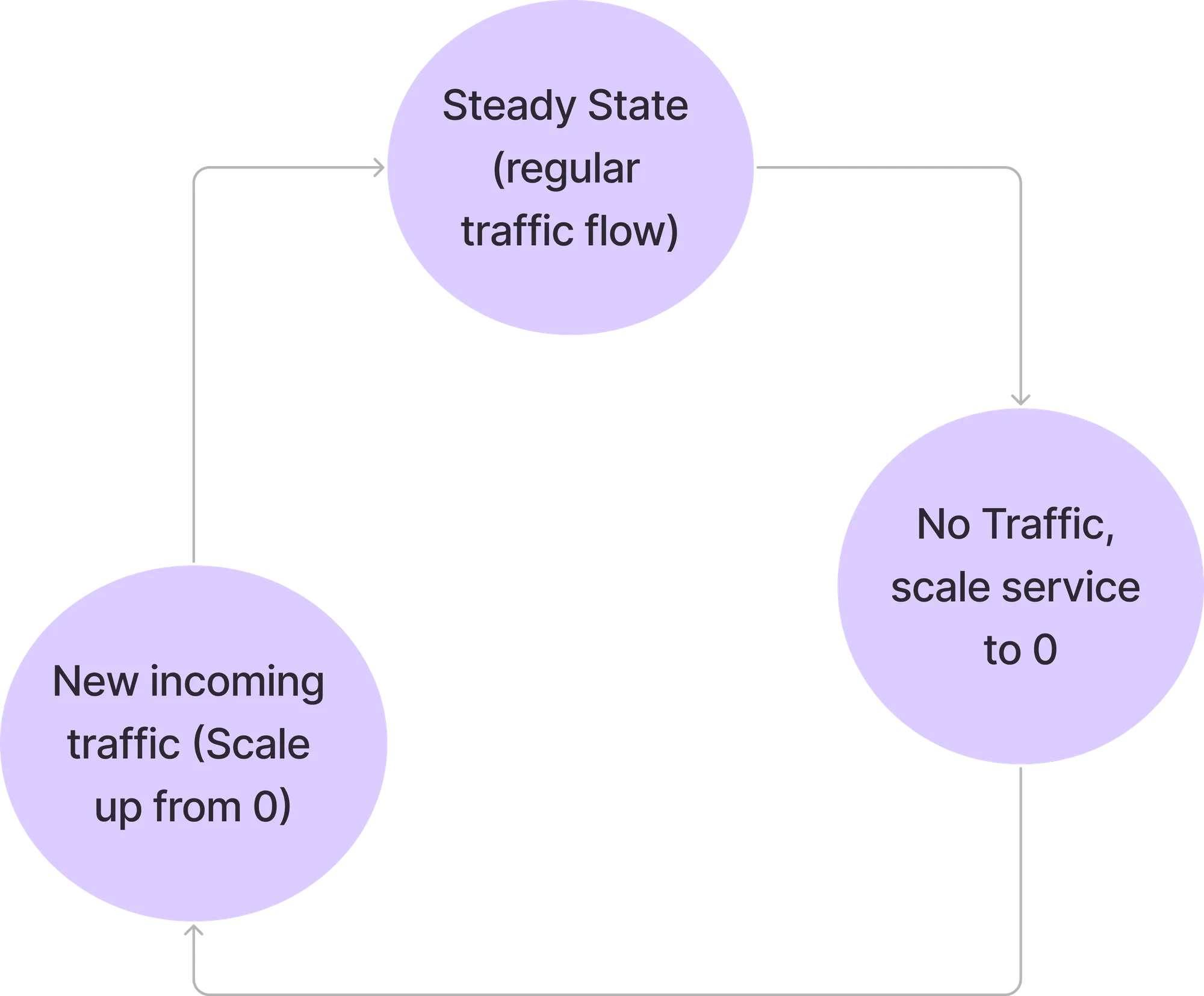
Elastisch ist eine innovative Open-Source-Lösung zur Optimierung der Kubernetes-Ressourcennutzung, indem Dienste während Leerlaufzeiten auf Null herunterskaliert und bei Bedarf wieder hochskaliert werden können. Elasti basiert auf einer Zweikomponenten-Architektur — einem Kubernetes-Controller und einem Request-Resolver — und verwaltet die Serviceverfügbarkeit nahtlos und minimiert gleichzeitig die Kosten. Dieser Beitrag soll einen technischen Überblick über die Architektur, Installation und Betriebsabläufe geben und sicherstellen, dass Sie Elasti effektiv in Ihre Kubernetes-Umgebungen integrieren und erweitern können.
💡 Diese Funktion ist in der Autoscaling-Suite von Truefoundry enthalten. Weitere Informationen finden Sie auf der Dokumentation.
Kubernetes bietet zwar robuste Skalierungsfunktionen durch HPA und Lösungen wie KEDA, aber die Skalierung auf null Replikate bleibt eine Herausforderung. Bestehende Ansätze lassen sich in der Regel in zwei Kategorien einteilen:
Elasti wurde entwickelt, um diese Einschränkungen mit drei zentralen Designzielen zu umgehen:
Elasti besteht aus zwei Kernkomponenten, die zusammenarbeiten, um die Serviceskalierung zu verwalten:
Controller (Betreiber):
Resolver:
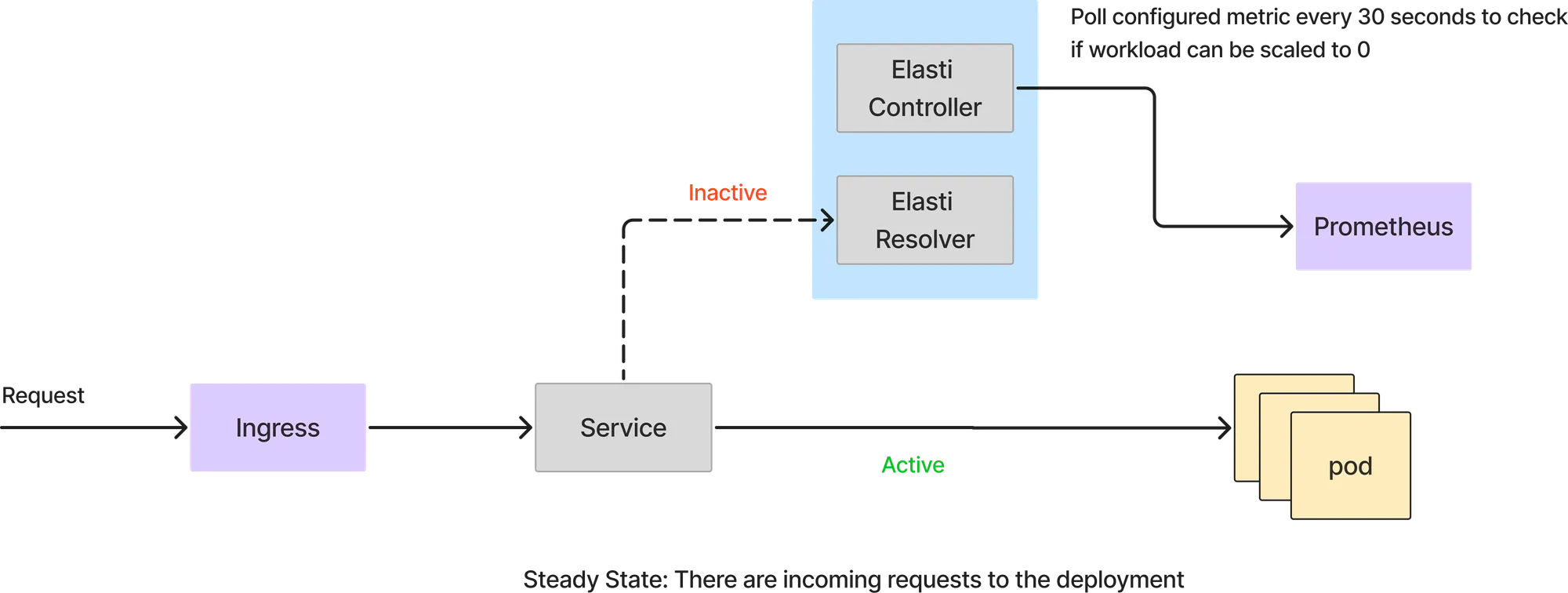
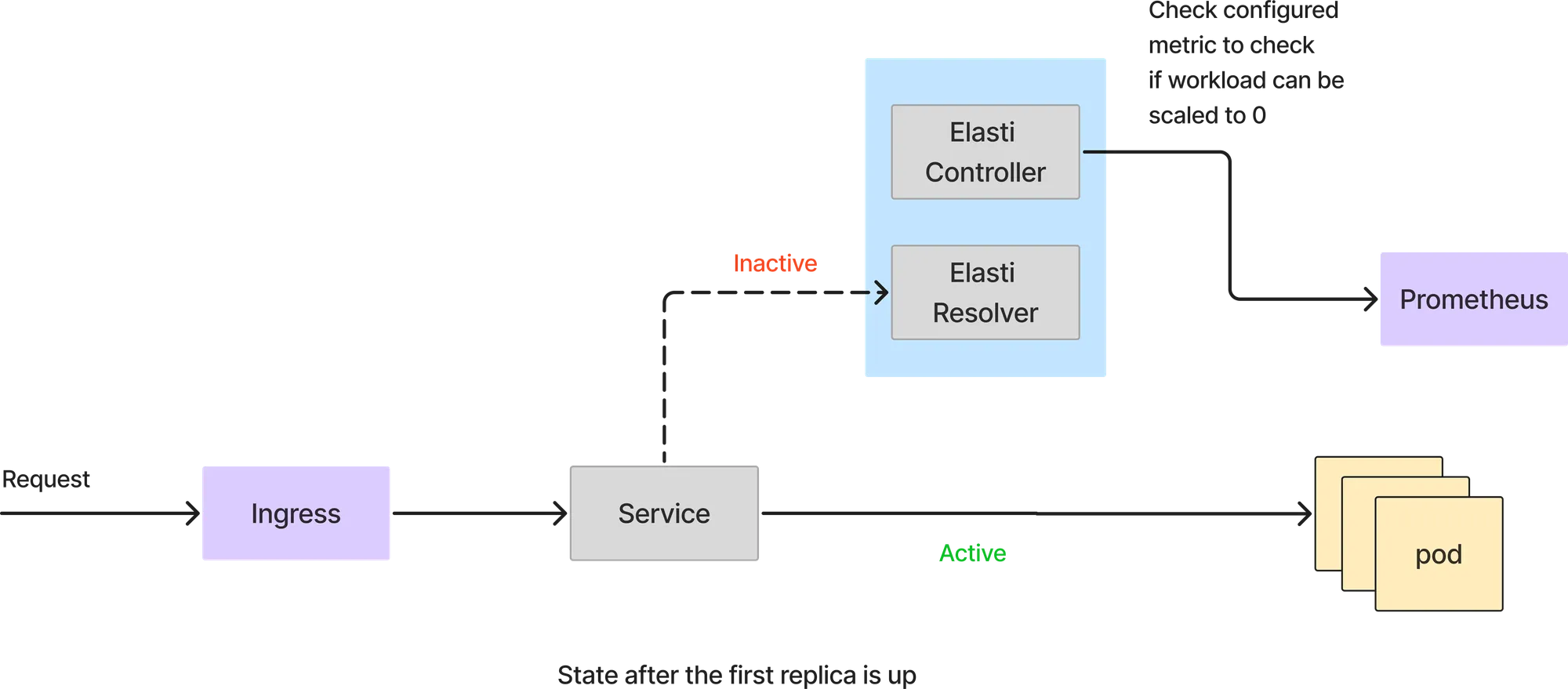
In diesem Modus werden alle Anfragen direkt von den Service-Pods bearbeitet. Der Elasti-Resolver wird nicht in den Anforderungspfad aufgenommen. Der Elasti-Controller fragt Prometheus weiterhin mit der konfigurierten Abfrage ab und überprüft das Ergebnis mit dem Schwellenwert, um festzustellen, ob der Dienst herunterskaliert werden kann.
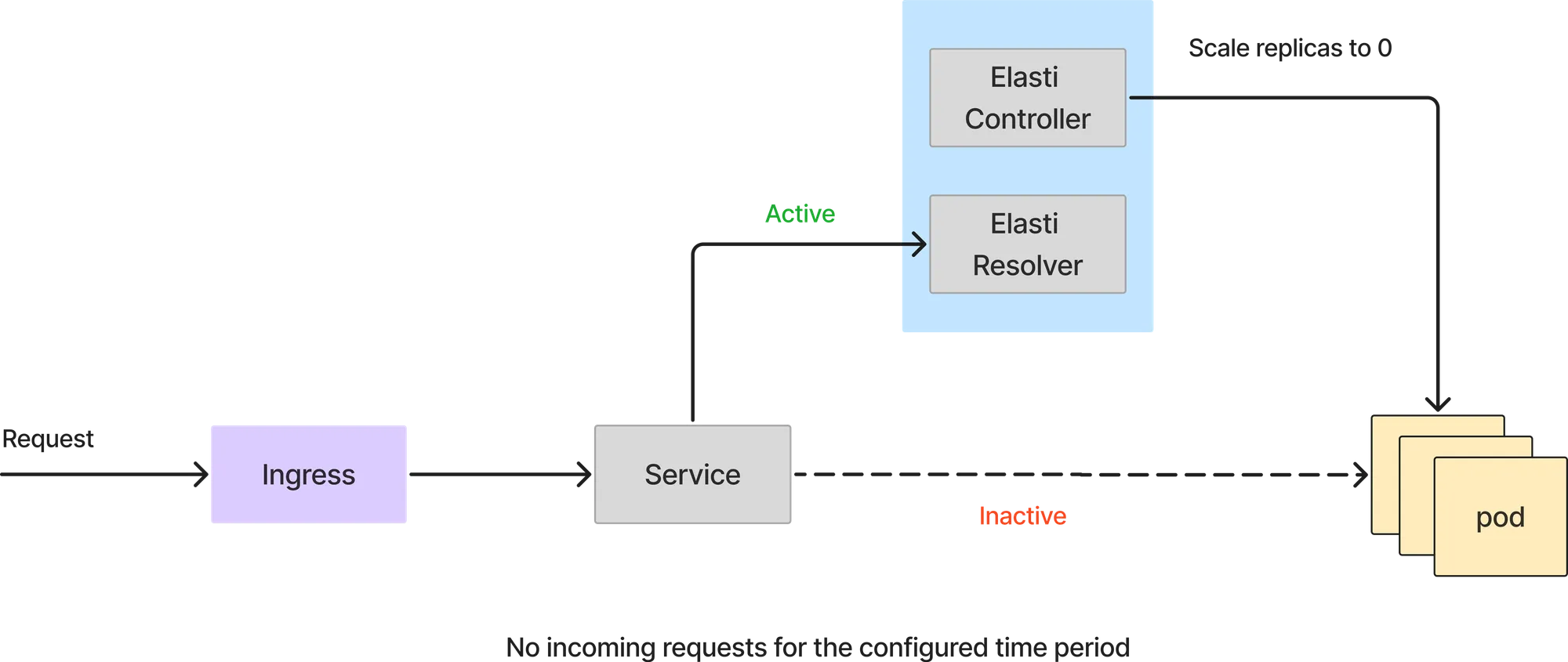
Wenn die Abfrage von Prometheus einen Wert zurückgibt, der unter dem Schwellenwert liegt, skaliert Elasti den Dienst auf 0 herunter. Bevor er auf 0 skaliert wird, leitet er die Anfragen um, die an den Elasti-Resolver weitergeleitet werden, um dann das Rollout/die Bereitstellung so zu ändern, dass es 0 Replikate hat. Außerdem wird Keda dann angehalten (falls Keda verwendet wird), um zu verhindern, dass der Dienst hochskaliert wird, da Keda mit minReplicas als 1 konfiguriert ist.
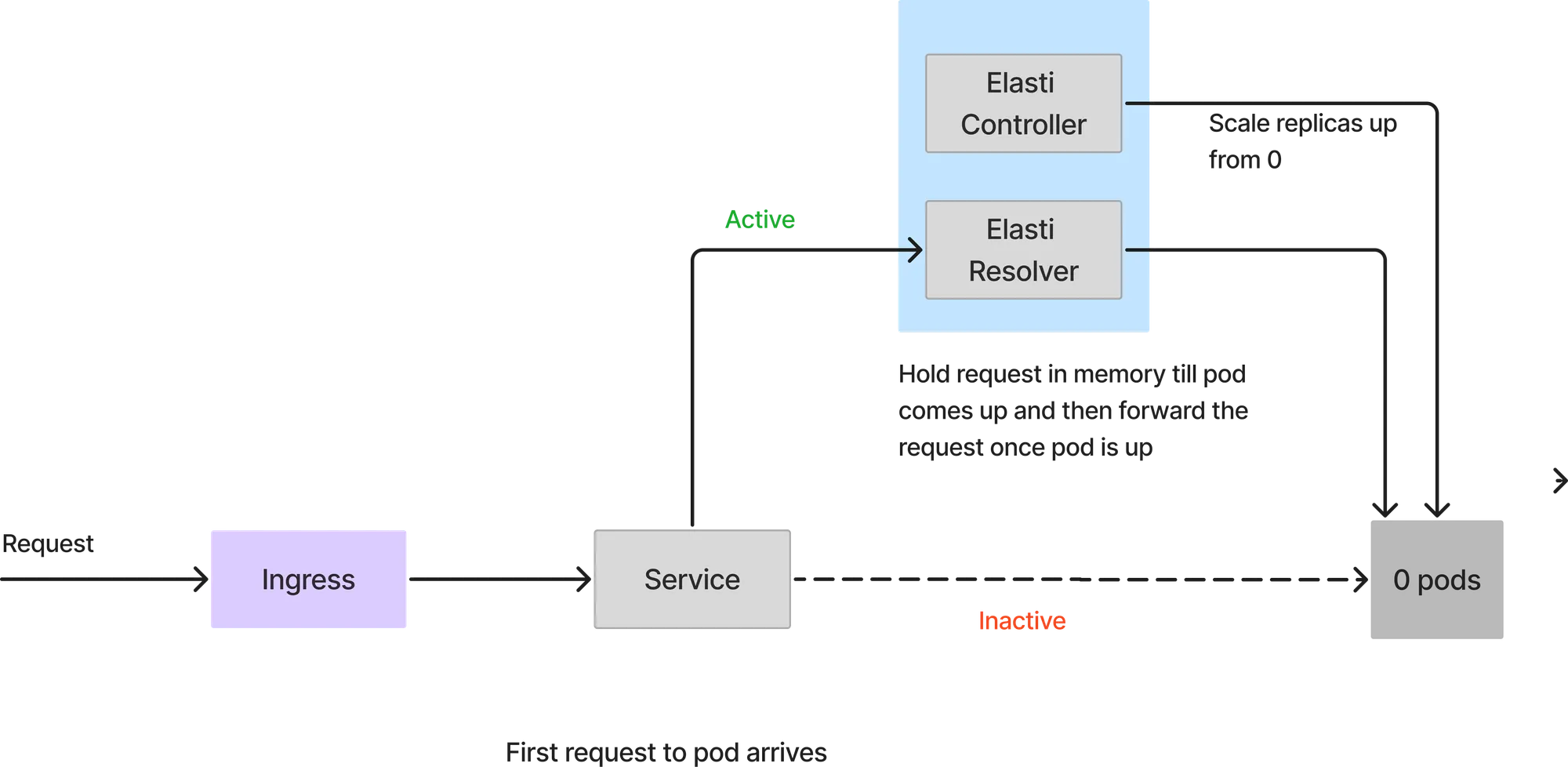
Da der Dienst auf 0 herunterskaliert ist, treffen alle Anfragen den Elasti-Resolver. Wenn die erste Anfrage eintrifft, skaliert Elasti den Dienst auf die konfigurierten MinTargetReplicas. Anschließend setzt es Keda fort, um die automatische Skalierung fortzusetzen, falls es zu einem plötzlichen Anstieg von Anfragen kommt. Außerdem wird der Dienst so geändert, dass er auf die tatsächlichen Service-Pods verweist, sobald der Pod hochgefahren ist. Die Anfragen, die an ElastiResolver eingegangen sind, werden bis zu 6 Minuten wiederholt und die Antwort wird an den Client zurückgesendet. Wenn der Pod länger als 6 Minuten braucht, um hochzufahren, wird die Anfrage verworfen.
Minikube starten
oder
Art Cluster erstellen --name elasti-demo
oder
Erstellen Sie einen lokalen Cluster mit Docker Desktop
Helm-Repo füge die Prometheus-Community hinzu https://prometheus-community.github.io/helm-charts
Helm-Repo-Aktualisierung
helm installiere kube-prometheus-stack prometheus-community/kube-prometheus-stack\
--Namespace-Überwachung\
--namespace erstellen\
--set alertmanager.enabled=falsch\
--set grafana.enabled=falsch\
--set prometheus.prometheusspec.serviceMonitorSelectorniluseHelmValues=Falsch
Installieren und konfigurieren Sie Prometheus im Überwachung Namensraum
Prometheus wird verwendet, um Metriken von Nginx-Ingress zu lesen, die dann von Elasti verwendet werden, um Metriken abzufragen, auf deren Grundlage es entscheidet, wann ein Service auf Null und von Null skaliert werden soll.
Helm-Repo füge Ingress-Nginx hinzu https://kubernetes.github.io/ingress-nginx
Helm-Repo-Aktualisierung
Helm installiere Ingress-Nginx Ingress-Nginx/Ingress-Nginx\
--namespace ingress-nginx\
--set controller.metrics.enabled=wahr\
--set controller.metrics.serviceMonitor.enabled=Wahr\
--namespace erstellen
Stellt einen Nginx-Controller in der Ingress-Nginx Namensraum
Der Controller wird verwendet, um den Verkehr an unseren Httpbin-Demo-Dienst weiterzuleiten.
4. Elasti einrichten:
Helm-Repo füge Elastic hinzu https://charts.truefoundry.com/elasti
Helm-Repo-Aktualisierung
Helm installiert Elastic oci: //tfy.jfrog.io/tfy-helm/elasti\
--namespace elasti --namespace erstellen
Elasti mit Helm im Namespace Elasti installieren
Sobald Elasti installiert ist, sollten Sie sehen, dass zwei Hauptkomponenten ausgeführt werden:
Weitere Konfigurationen finden Sie unter Werte.yaml um alle Konfigurationsoptionen in der Helm-Wertedatei zu sehen.
kubectl erstellt den Namespace Elasti-Demo
kubectl apply -n elasti-Demo -f\
https://raw.githubusercontent.com/truefoundry/elasti/refs/heads/main/playground/config/demo-application.yaml
Bereitstellen eines httpbin-Dienstes in der Elasti-Demo Namensraum
Dieser httpbin-Dienst wird verwendet, um zu demonstrieren, wie ein Dienst für die Verarbeitung des Datenverkehrs über Elasti konfiguriert wird.
Erstellen Sie eine Yaml-Datei mit der folgenden Konfiguration für einen ElastiService.
API-Version: elasti.truefoundry.com/v1alpha1
Art: ElastiService
Metadaten:
Name: http://bin-elasti
Namensraum: Elasti-Demo
spezifikation:
MinTarget-Replikate: 1
Dienst: httpbin
Abklingzeit: 5
Zielreferenz skalieren:
API-Version: Apps/v1
Art: Einsätze
Name: httpbin
löst aus:
- Typ: Prometheus
Metadaten:
Abfrage: sum (rate (nginx_ingress_controller_nginx_process_requests_total [1m])) oder vector (0)
Serveradresse: http://kube-prometheus-stack-prometheus.monitoring.svc.cluster.local:9090
Schwellenwert: „0,5"
demo-elasti-service.yaml
Sobald die Datei erstellt ist, wenden Sie den ElastiService an
kubectl apply -f https://raw.githubusercontent.com/truefoundry/elasti/refs/heads/main/playground/config/demo-elastiService.yaml
Einige wichtige Felder in der CRD-Spezifikation sind:
MinTarget-Repliken: Mindestanzahl der Replikate, die beim Eintreffen der ersten Anfrage angezeigt werden.Abklingzeit: Mindestzeit (in Sekunden), die nach einer Hochskalierung abgewartet werden muss, bevor eine Verkleinerung in Betracht gezogen wirdlöst aus: Liste der Bedingungen, die bestimmen, wann herunterskaliert werden muss (unterstützt derzeit nur Prometheus-Metriken)Zielreferenz skalieren: Referenz auf das Skalierungsziel, das dem in HorizontalPodAutoscaler verwendeten ähnelt.Weitere Informationen und die Konfiguration eines ElastiService für Ihren Anwendungsfall finden Sie in diesem Dokument.
Mit diesen Schritten haben Sie jetzt:
Mit dieser Konfiguration können Sie reale Routing-Szenarien testen und die Leistung und Metriken Ihres eingehenden Datenverkehrs überwachen.
Um dieses Setup zu testen, können Sie Anfragen an den Nginx-Load Balancer senden und die Pods unseres Demodienstes überwachen.
kubectl portforward svc/nginx-ingress-nginx-controller\
-n Eingangs-nginx 8080:80
Portweiterleitung zum Nginx-Controller
kubectl get pods -n elasti-Demo -w
Starte eine Uhr auf dem httpbin-Dienst
Jetzt können Sie eine Anfrage senden an http://localhost:8080/httpbin und Sie können sehen, wie der Service von Elasti auf 1 Replikat skaliert wird.
curl -v http://localhost:8080/httpbin
Senden Sie eine Anfrage an den httpbin-Dienst
Der Dienst wird dann wieder heruntergefahren, wenn keine Aktivität für Abklingzeit Sekunden, die im ElastiService angegeben sind (in diesem Fall 5 Sekunden).
Um Elasti zu deinstallieren, Sie müssen zuerst alle installierten ElastiServices entfernen. Löschen Sie dann einfach die Installationsdatei.
kubectl delete elastiservices --all
Helm deinstalliere elasti -n elasti
kubectl lösche den Namespace elasti
Elasti ist die beste Wahl, wenn Sie:
Elasti wurde aus der Notwendigkeit heraus entwickelt, eine spezifische Herausforderung in Kubernetes anzugehen: die Implementierung einer echten Skalierung bis auf Null, ohne die Integrität der Anfragen zu beeinträchtigen oder übermäßigen Overhead zu verursachen. Diese Lösung unterstützt systemeigenes Autoscaling mit HPA und KEDA und stellt so sicher, dass bestehende Servicekonfigurationen unverändert bleiben und gleichzeitig eine effiziente Ressourcennutzung erreicht wird.
Durch die Bereitstellung dieses Tools als Open-Source-Lösung möchten wir eine robuste Lösung für Umgebungen bereitstellen, die eine echte Skalierung bis auf Null, ohne Anforderungsverluste und einen minimalen betrieblichen Fußabdruck erfordern.
Wir freuen uns über Beiträge und Feedback aus der Community — erkunde die Entwicklungsdokument für weitere Informationen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.









.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




