

July 1, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: June 12, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Large Language Models (LLMs) bieten leistungsstarke Funktionen, führen aber auch zu hohen Infrastrukturkosten, unvorhersehbaren Nutzungsmustern und Missbrauchspotenzial. In dem Maße, in dem Unternehmen LLMs in kundenorientierte Tools, interne Copiloten und API-Plattformen integrieren, wird die Notwendigkeit eines kontrollierten und zuverlässigen Zugriffs immer wichtiger. Hier spielt die Ratenbegrenzung eine entscheidende Rolle.
Im Zusammenhang mit LLM-Inferenz reicht die herkömmliche Ratenbegrenzung von Anfragen pro Sekunde (RPS) nicht aus. LLMs sind ressourcenintensiv, tokenbasiert und hinsichtlich der Rechenlast sehr unterschiedlich. Eine einzige Aufforderung zu einem 70B-Parametermodell kann Tausende von Token verbrauchen und die GPU-Latenz erheblich beeinträchtigen. Ohne angemessene Kontrollen kann eine gemeinsam genutzte Infrastruktur schnell instabil oder unerschwinglich werden.
Dieser Artikel erklärt, wie die Ratenbegrenzung in einem funktioniert KI-Gateway, warum es für eine skalierbare KI-Infrastruktur unerlässlich ist und wie TrueFoundry es standardmäßig aktiviert, um eine faire Nutzung, Kosteneffizienz und produktionsgerechte Leistung bei Multi-Tenant-Bereitstellungen zu gewährleisten.
Die Ratenbegrenzung ist ein Mechanismus, mit dem gesteuert wird, wie viele Anfragen ein Client innerhalb eines bestimmten Zeitfensters an ein System senden kann, und es ist eine Kernfunktion moderner KI-Gateways Verwaltung des LLM-Verkehrs. Es gewährleistet Fairness, verhindert Überlastung und gewährleistet die Verfügbarkeit, insbesondere in Umgebungen mit mehreren Benutzern. Herkömmliche APIs wenden oft einfache Grenzwerte wie 100 Anfragen pro Minute und Benutzer an, was für Standard-REST-Dienste gut funktioniert.
LLMs funktionieren jedoch sehr unterschiedlich. Jede Anfrage kann die Infrastruktur je nach Eingabegröße, Modelltyp und erwarteter Ausgabe erheblich unterschiedlich belasten. Beispielsweise kann eine Aufforderung mit 20 Token an ein 7B-Modell schnell abgeschlossen werden, während eine 2000-Token-Anfrage an ein 65B-Modell GPUs für mehrere Sekunden blockieren könnte. Selbst zwei identische Anfragen an verschiedene Modelle können die Rechenkosten um das Fünffache oder mehr variieren.
Dadurch sind anforderungsbasierte Grenzwerte unzureichend. Moderne LLM-Gateways müssen eine Token-basierte Ratenbegrenzung einführen, die die tatsächliche Anzahl der verarbeiteten Token und den Rechenaufwand pro Anruf berücksichtigt.
Zu den wichtigsten Faktoren, die bei der tokenbewussten Ratenbegrenzung berücksichtigt wurden, gehören:
Im Vergleich zu festen Anforderungslimits gelten Token-fähige Limits:
In generativen KI-Workflows wird die Ratenbegrenzung noch wichtiger. Ein einzelner Benutzer kann eine umfangreiche Backend-Verarbeitung durch Eingabeaufforderungen in langen Formularen, die Erfassung von Dokumenten oder durch Agenten in mehreren Schritten auslösen. Ohne Kontrollen kann dies zu GPU-Überlastung, hoher Latenz oder unerwarteten Kosten führen.
Die tatsächliche Nutzung ist oft unvorhersehbar, was auf Frontend-Apps, Testschleifen oder Automatisierung zurückzuführen ist. Die Ratenbegrenzung stellt sicher, dass diese Interaktionen stabil und effizient bleiben, auch wenn die Infrastruktur von Benutzern oder Mandanten gemeinsam genutzt wird.
Für jede LLM-Bereitstellung in Produktionsqualität ist eine intelligente Ratenbegrenzung keine optionale Funktion, sondern eine grundlegende Voraussetzung für Skalierbarkeit, Zuverlässigkeit und Kostenkontrolle.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Die Ratenbegrenzung ist mehr als ein Backend-Schutz. Für Plattformen, die LLMs bereitstellen — insbesondere für solche, die öffentliche oder mandantenfähige APIs anbieten — dient sie als strategische Ebene für Stabilität, Unternehmensführung und Geschäftsausrichtung. Ganz gleich, ob es sich um OpenAI, Anthropic oder mit TrueFoundry entwickelte Plattformen handelt, Ratenbegrenzungen dienen mehreren wichtigen Zwecken.
Infrastruktur vor Missbrauch schützen
Generative KI-Inferenz ist ressourcenintensiv. Ein plötzlicher Ausbruch langer Aufforderungen oder gleichzeitiger Anfragen kann GPU-Warteschlangen überlasten, die Latenz erhöhen oder sogar Dienste zum Erliegen bringen. Ratenbegrenzungen stellen sicher, dass der Datenverkehr kontrolliert und priorisiert verarbeitet wird, wodurch eine Überlastung der Ressourcen verhindert wird.
Sorgen Sie für Fairness zwischen Benutzern oder Mietern
In Mehrbenutzersystemen sollte die Nutzung eines Clients die Leistung anderer nicht beeinträchtigen. Ratenbegrenzungen helfen dabei, die Isolierung zwischen Benutzern, Teams oder API-Schlüsseln durchzusetzen. Dies garantiert ein konsistentes Serviceniveau, unabhängig davon, wie viele Benutzer gleichzeitig aktiv sind.
Passen Sie die Nutzung an die Preispläne an
Viele KI-Plattformen der Generation monetarisieren auf der Grundlage von Token oder Nutzungsstufen. Ratenlimits helfen dabei, diese Grenzen durchzusetzen. Zum Beispiel:
Vermeiden Sie Kostenüberraschungen und Überschreitungen
Die LLM-Nutzung kann leise und schnell skaliert werden. Ohne angemessene Grenzwerte können der Token-Verbrauch und die GPU-Auslastung sprunghaft ansteigen. Die Ratenbegrenzung hilft Plattformen, unerwartete Infrastrukturkosten zu verhindern und die Budgetkontrolle zu behalten.
Verbessern Sie die Zuverlässigkeit und das Benutzererlebnis
Wenn die Nutzung kontrolliert wird, bleiben die Systemwarteschlangen stabil. Dies führt zu einer geringeren Latenz, höheren Erfolgsraten und einer konsistenteren Benutzererfahrung, was besonders in Produktionsumgebungen mit SLAs wichtig ist.
In LLM-basierten Systemen haben nicht alle Anfragen die gleiche Wirkung. Eine kurze Aufforderung an ein kleines Modell verbraucht möglicherweise nur minimale Ressourcen, während eine lange Abfrage an ein großes Modell viel GPU-Zeit in Anspruch nehmen kann. Aufgrund dieser Variabilität wenden moderne Plattformen Ratenbegrenzungen für mehrere Dimensionen an, anstatt sich nur auf die Anzahl der Anfragen zu verlassen.
Hier sind die gängigsten Dimensionen, die für die effektive Ratenbegrenzung verwendet werden:
Die Verwendung dieser Dimensionen gibt Plattformteams die Flexibilität, die Ressourcennutzung an Infrastruktureinschränkungen, Benutzeranforderungen und Erwartungen an das Serviceniveau anzupassen.
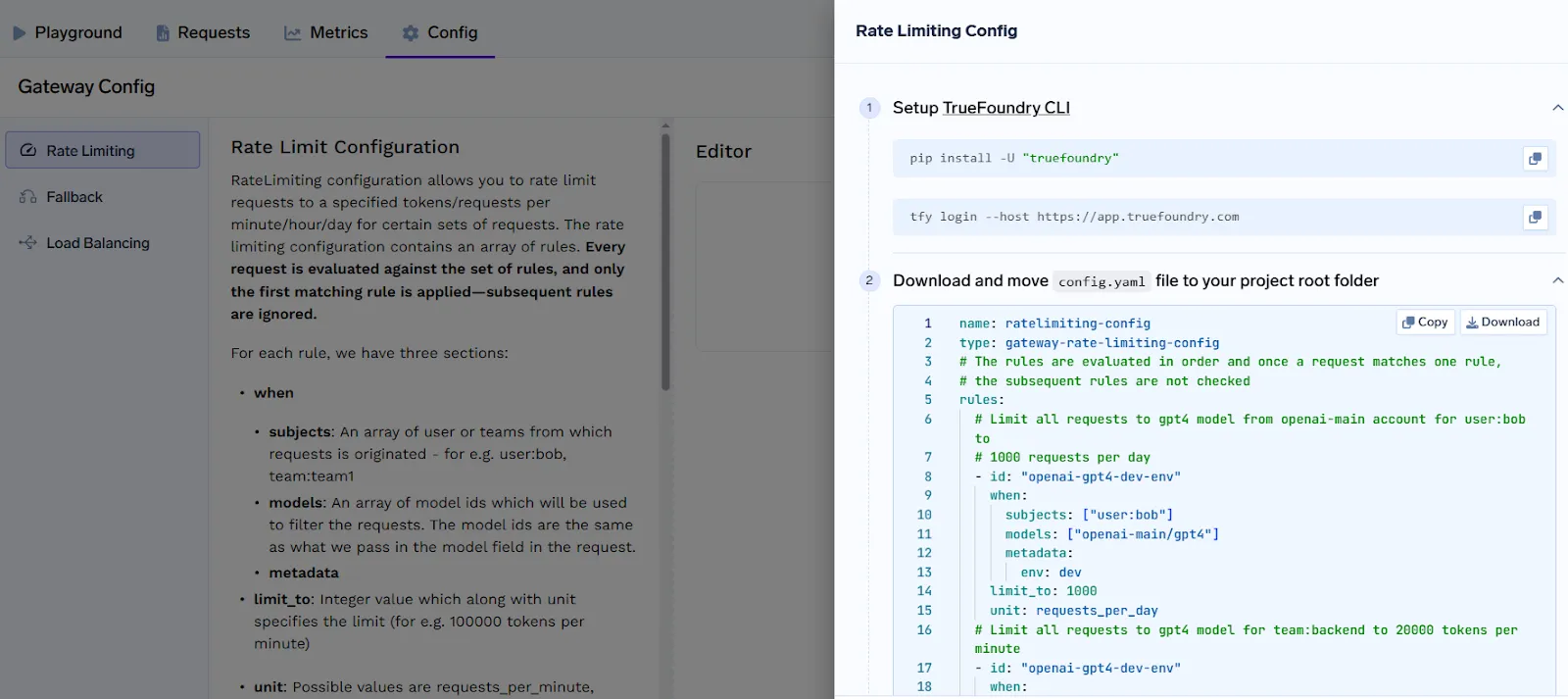
TrueFoundry bietet ein robustes und flexibles Ratenbegrenzungssystem, das es Plattformteams ermöglicht, den Zugriff auf LLM-Endpunkte auf der Grundlage von Anfragen oder der Token-Nutzung zu kontrollieren. Dies gewährleistet eine faire Zuweisung von Rechenleistung, verhindert Missbrauch und passt die Nutzung an Unternehmensrichtlinien oder Abrechnungsplänen an.
Das Herzstück des Ratenbegrenzungsmechanismus von TrueFoundry ist ein regelbasiertes Konfigurationssystem, das es Teams ermöglicht, präzise Richtlinien für Benutzer, Teams, virtuelle Konten und Modelle zu definieren und Metadaten anzufordern.
Regelbasierte Konfiguration
Die Ratenbegrenzung in TrueFoundry wird durch eine Liste von Regeln definiert, die jeweils Folgendes angeben:
Regeln werden in der richtigen Reihenfolge bewertet, daher sollten spezifischere Regeln den umfassenderen Regeln vorgezogen werden, um einen korrekten Abgleich sicherzustellen.
Unterstützte Limittypen
TrueFoundry unterstützt sowohl anforderungsbasierte als auch tokenbasierte Grenzwerte über verschiedene Zeitintervalle:
Dies ermöglicht die Durchsetzung von Richtlinien, die die tatsächliche Computernutzung widerspiegeln. Dies ist besonders wichtig, wenn Prompts mit variabler Länge für Modelle unterschiedlicher Größe bereitgestellt werden.
Häufige Anwendungsfälle
Die Flexibilität des Konfigurationssystems unterstützt eine Vielzahl von Anwendungsfällen:
Beispielkonfiguration
Name: ratelimiting-config
Typ: Gateway-Rate-Limiting-Config
Regeln:
- id: „spezifische Regel“
wann:
Betreff: ["user: bob@email.com „]
Modelle: ["openai-main/gpt4"]
begrenzung_bis: 1000
Einheit: requests_per_day
Dieses Beispiel begrenzt die GPT-4-Nutzung eines bestimmten Benutzers auf 1.000 Anfragen pro Tag. Das Ratenbegrenzungssystem von TrueFoundry ist so konzipiert, dass es sowohl leistungsstark als auch einfach zu verwalten ist. Mit tokenbasierten Kontrollen, granularem Targeting und klaren YAML-basierten Richtlinien können Teams die LLM-Nutzung problemlos skalieren und gleichzeitig die Kontrolle über Infrastruktur und Kosten behalten.
So wenden Sie die Konfiguration an
1. Installieren Sie die TrueFoundry CLI:
pip install -U „truefoundry“
versuche es mit dem Login --host https://app.truefoundry.com
2. Platziere deine config.yaml in Ihrem Projektverzeichnis.
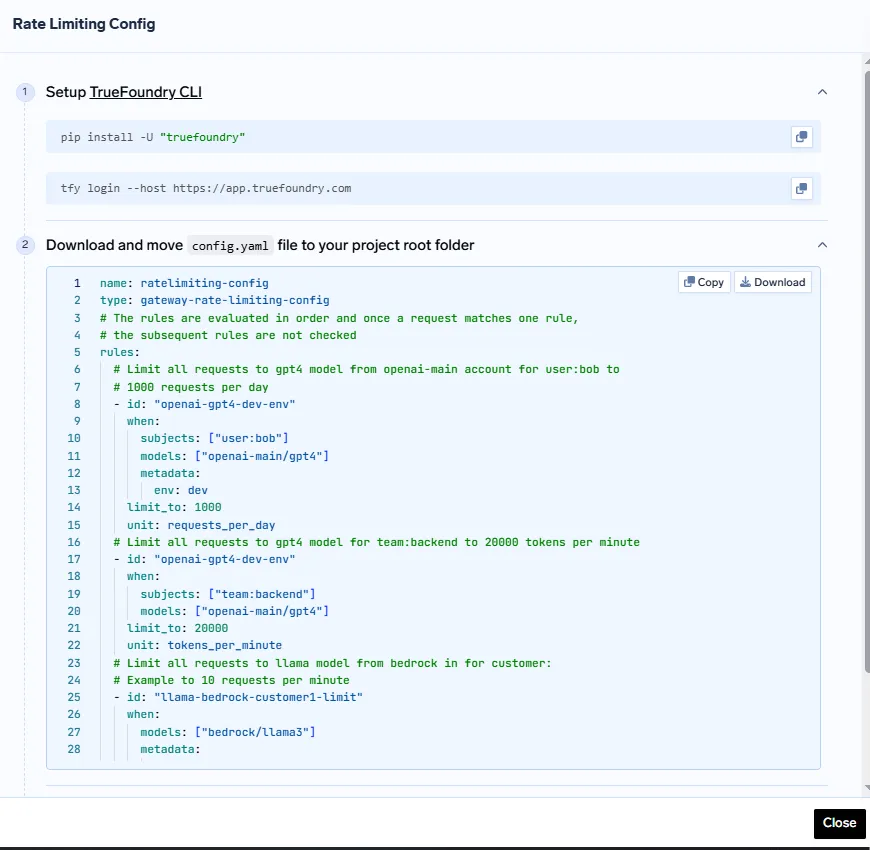
3. Wenden Sie die Konfiguration an mit:
tfy apply -f config.yaml
Dieser deklarative Ansatz stellt sicher, dass die Ratenlimits versionskontrolliert, reproduzierbar und an den Best Practices von GitOps ausgerichtet sind.
Feedback zu Ratenlimits in Echtzeit
Das Ratenbegrenzungssystem von TrueFoundry wurde entwickelt, um Kunden sofortiges, transparentes Feedback zu geben, wenn Limits überschritten werden oder kurz vor der Erschöpfung stehen. Dies hilft Entwicklern, Nutzungsgrenzen zu verstehen und Drosselung in ihren Anwendungen elegant zu handhaben.
Wenn eine Anfrage das definierte Ratenlimit überschreitet:
Dieser Feedback-Mechanismus unterstützt ein besseres Kundenverhalten, ermöglicht eine automatische Wiederholungslogik und stellt sicher, dass die Nutzung innerhalb der Kontingentgrenzen bleibt, ohne dass es zu Rätselraten kommt.
Dashboards und Benachrichtigungen
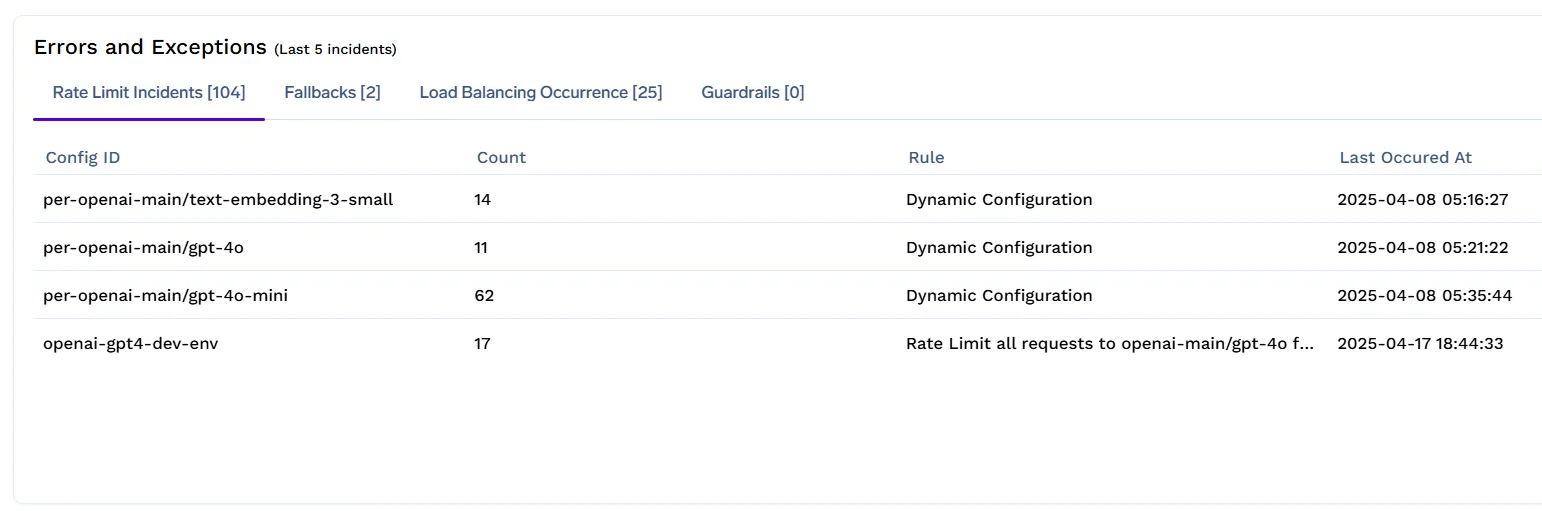
TrueFoundry bietet integrierte Beobachtbarkeit, mit der Plattformteams Richtlinien für Ratenlimits in Echtzeit überwachen und optimieren können.
Mithilfe des LLM Gateway-Dashboards können Sie Folgendes verfolgen:
Diese Erkenntnisse helfen dabei, Missbrauch zu erkennen, Limits proaktiv anzupassen und sicherzustellen, dass hochwertige Nutzer einen konsistenten Service erhalten.
Wenn LLM-APIs ausfallen, sei es aufgrund von Ratenbeschränkungen, internen Fehlern oder vorübergehenden Ausfällen, sorgen Fallback-Mechanismen dafür, dass Ihre Anwendungen reibungslos laufen. Anstatt Fehler an den Endbenutzer zurückzugeben, kann TrueFoundry die Anfrage automatisch an ein Backup-Modell oder einen Backup-Anbieter weiterleiten, sodass die Verfügbarkeit mit minimaler Unterbrechung aufrechterhalten wird.
Ausweichregeln werden auf der Grundlage bestimmter Bedingungen wie der Modell-ID, des anfragenden Benutzers oder Teams und Antwortcodes wie 429 oder 500 ausgelöst. Wenn eine Anfrage diese Bedingungen erfüllt, wird sie an ein oder mehrere alternative Modelle weitergeleitet, die in der Fallback-Konfiguration angegeben sind. Diese Fallback-Ziele können optional Überschreibungen von Parametern wie Temperatur- oder Maximalwerten beinhalten, sodass das Verhalten je nach Modellanbieter fein abgestimmt werden kann. Bei der Bewertung wird nur die erste Übereinstimmungsregel angewendet, wodurch eine vorhersehbare, deterministische Behandlung von Fehlern gewährleistet wird.
Eine typische Fallback-Regel in TrueFoundry umfasst die folgenden Komponenten:
Beispiel für eine Fallback-Konfiguration:
Name: Modell-Fallback-Konfiguration
Typ: Gateway-Fallback-Config
# Die Regeln werden der Reihe nach ausgewertet. Sobald eine Anfrage mit einer Regel übereinstimmt, werden die nachfolgenden Regeln nicht überprüft.
Regeln:
# Fallback auf gpt-4 in Azure oder AWS, wenn openai-main/gpt-4 mit 500 oder 503 fehlschlägt.
# Das openai-main-Ziel überschreibt auch einige Anforderungsparameter wie temperature und max_tokens.
- ID: „openai-gpt4-Fallback“
wann:
Modelle: ["openai-main/gpt4"]
Antwortstatuscodes: [500, 503]
Fallback_Modelle:
- Ziel: openai-main/gpt-4
Parameter überschreiben:
Temperatur: 0,9
max_token: 800
# Fallback auf llama3 auf Azure oder AWS, wenn bedrock/llama3 mit 500 oder 429 für customer1 fehlschlägt.
- ID: „llama-bedrock-customer1-fallback“
wann:
Modelle: ["bedrock/lama3"]
Metadaten:
Kunden-ID: Kunde1
Antwortstatuscodes: [500, 429]
Fallback_Modelle:
- Ziel: aws/llama3
- Ziel: Azure/Llama3
Das LLM Gateway von TrueFoundry unterstützt nativ das deklarative Fallback-Setup als Teil seines Konfigurationssystems. Auf diese Weise können Teams fehlertolerante Routing-Richtlinien definieren und die Verfügbarkeit ohne manuelles Eingreifen aufrechterhalten, insbesondere wenn sie mit mehreren Anbietern zusammenarbeiten. Intelligente Ratenbegrenzung und automatisiertes Fallback bilden zusammen die Grundlage für hochverfügbare KI-Dienste der Generation.
Auf jeder KI-Plattform mit mehreren Mandanten ist die Ratenbegrenzung von entscheidender Bedeutung, um Stabilität, Fairness und Kostenkontrolle zu gewährleisten. Es ermöglicht Teams, Zugriffsgrenzen nicht nur für einzelne Benutzer, sondern auch für Teams, virtuelle Konten und spezifische Modelle zu definieren, ohne dass eine benutzerdefinierte Logik erforderlich ist.
Das Gateway von TrueFoundry unterstützt die deklarative Ratenbegrenzung über die YAML-Konfiguration, bei der Regeln der Reihe nach ausgewertet werden. Die erste passende Regel wird angewendet, was bedeutet, dass spezifischere Regeln ganz oben platziert werden sollten, während allgemeinere Regeln weiter unten in der Konfiguration platziert werden sollten. Diese Struktur gewährleistet eine mehrschichtige Steuerung und gewährleistet gleichzeitig saubere, lesbare Konfigurationen.
Jede Regel kann die folgenden Komponenten enthalten:
Beispiele für Ratenbegrenzung für mehrere Mandanten
Spezifische Benutzeranfrage einschränken: Angenommen, Sie möchten alle Anfragen an das gpt4-Modell vom openai-main-Konto für die Benutzer bob@email.com und jack@email.com auf 1000 Anfragen pro Tag beschränken:
- id: „Benutzer-GPT4-Limit“
wann:
Betreff: ["user: bob@email.com „, „user: jack@email.com „]
Modelle: ["openai-main/gpt4"]
begrenzung_bis: 1000
Einheit: requests_per_day
Wenden Sie teamweite Limits an: Wenn Sie die Gesamtzahl der Anfragen für das Frontend-Team auf 5000 pro Tag beschränken möchten
- id: „Team-Frontend-Limit“
wann:
Themen: ["team:frontend"]
begrenzung_bis: 5000
Einheit: requests_per_day
Virtuelle Konten einschränken: Wenn Sie die Anzahl der Anfragen für das virtuelle Konto 'va-james' auf 1500 pro Tag begrenzen möchten
- id: „va-james-limit“
wann:
Betreff: ["virtuelles Konto:va-james"]
begrenzung_bis: 1500
Einheit: requests_per_day
Legen Sie globale Obergrenzen für alle Benutzer und Modelle fest:
- id: „{user} - {model} -Tageslimit“
wann: {}
begrenzung_bis: 1000000
Einheit: Tokens_per_Day
Dieses Setup ermöglicht es Plattformteams, die Nutzung über Geschäftsbereiche hinweg zu segmentieren, Kontingente pro Umgebung durchzusetzen und teure Modellendpunkte zu schützen und gleichzeitig skalierbare, zuverlässige KI-Workloads zu unterstützen.
Ratenbegrenzung ist mehr als eine Backend-Steuerung. Es ist ein entscheidender Faktor für eine zuverlässige, kosteneffiziente und faire Nutzung der LLM-Infrastruktur in großem Umfang. Ganz gleich, ob Sie eine Plattform mit mehreren Mandanten betreiben, Kunden einen mehrstufigen Zugang bieten oder interne KI-Workloads teamübergreifend ausführen, die Implementierung intelligenter, tokensensitiver Ratenbegrenzungen stellt sicher, dass Ihr System auch unter Druck vorhersehbar bleibt.
Neben der Geschwindigkeitsbegrenzung geben Funktionen wie Fallback-Routing, Echtzeit-Feedback und granulare Konfiguration den Entwicklungsteams die Tools an die Hand, um Leistung und Kontrolle in Einklang zu bringen. Das LLM Gateway von TrueFoundry vereint diese Funktionen mit einer deklarativen Schnittstelle, sodass Plattformteams Richtlinien definieren können, die transparent und überprüfbar sind und auf die Unternehmensziele abgestimmt sind.
Da die Einführung generativer KI immer schneller voranschreitet, werden Systeme, die intelligente Zutrittskontrolle durchsetzen, ohne die Benutzererfahrung oder die Verfügbarkeit zu beeinträchtigen, die nächste Generation der Infrastrukturstabilität definieren. Wenn Sie ein KI-Gateway aufbauen oder skalieren, sollten Sie nicht nur die Ratenbegrenzung in Betracht ziehen. Es ist etwas, das man vom ersten Tag an richtig machen muss.
Die Ratenbegrenzung im LLM-Gateway bezieht sich auf den Mechanismus, der verwendet wird, um die Häufigkeit eingehender Anfragen oder das Volumen der Token zu steuern, die ein Benutzer, ein Team oder eine Anwendung innerhalb eines bestimmten Zeitfensters verarbeiten kann. Im Gegensatz zu herkömmlichem API-Drosselung ist es tokenbewusst und berücksichtigt die tatsächliche Rechenlast verschiedener Modellarchitekturen. So wird sichergestellt, dass ressourcenintensive Abfragen das System nicht zum Absturz bringen.
Die Implementierung einer Ratenbegrenzung in LLM-Gateway-Umgebungen trägt zur Kostenkontrolle bei, indem unerwartete Spitzen beim Token-Verbrauch und außer Kontrolle geratene Skripte verhindert werden. Durch die Festlegung granularer Tages- oder Stundenkontingente können Unternehmen die Ausgaben für bestimmte Benutzer oder Umgebungen außerhalb der Produktion begrenzen und so sicherstellen, dass KI-Experimente innerhalb eines vorhersehbaren Budgets bleiben und gleichzeitig vor teuren Überraschungen bei der Abrechnung geschützt sind.
Die Ratenbegrenzung in LLM-Gateway-Setups ist unerlässlich, um die Infrastruktur vor Missbrauch zu schützen und eine hohe Verfügbarkeit für alle Benutzer sicherzustellen. Es verhindert, dass ein einziger „lauter Nachbar“ die Anbieterkontingente oder die GPU-Kapazität ausschöpft, was andernfalls zu einer erhöhten Latenz und häufigen 429-Fehlern nach dem Motto „Too Many Requests“ führen würde. Diese Managementebene ist entscheidend für die Einhaltung stabiler SLAs in der Produktion.
Zu den gängigen Strategien zur Ratenbegrenzung im LLM-Gateway gehören Grenzwerte für Request-Per-Minute (RPM) und Token-Per-Minute (TPM), die ein genaues Maß für die Ressourcennutzung bieten. Erweiterte Gateways unterstützen auch gestaffelte Grenzwerte, die auf Benutzerrollen oder Modelltypen basieren, sodass unternehmenskritische Aufgaben eine höhere Priorität erhalten, während Entwicklungsarbeitslasten mit niedrigerer Priorität in Zeiten der Überlastung gedrosselt werden.
Obwohl es einen winzigen Verarbeitungsschritt hinzufügt, verursacht die Ratenbegrenzung im LLM-Gateway in der Regel einen Overhead von weniger als 4 Millisekunden, was im Vergleich zu den Sekunden, die für die Modellgenerierung benötigt werden, vernachlässigbar ist. Tatsächlich verbessert es häufig die wahrgenommene Latenz, indem verhindert wird, dass die Backend-Warteschlangen überlastet werden. So wird sichergestellt, dass Anfragen reibungslos verarbeitet werden, ohne dass es zu Timeouts oder Serviceausfällen kommt.
Ja, TrueFoundry bietet eine produktionstaugliche Implementierung der Ratenbegrenzung im LLM-Gateway über eine deklarative, regelbasierte Konfiguration. Es ermöglicht Teams, mithilfe einfacher YAML-Dateien Token-basierte Grenzwerte für mehrere Modellanbieter und Mandanten durchzusetzen. Dieses System bietet Feedback in Echtzeit und detaillierte Dashboards, sodass Plattformteams KI-Workloads skalieren und gleichzeitig eine strikte Kosten- und Ressourcenkontrolle einhalten können.
Die KI-Ratenbegrenzung funktioniert, indem sie verfolgt, wie oft ein Benutzer Anfragen an eine KI-API sendet. Das System zählt Anfragen oder Token innerhalb eines Zeitfensters. Wenn der Benutzer das zulässige Limit überschreitet, blockiert die API vorübergehend neue Anfragen oder gibt einen Fehler zurück, bis das Limit zurückgesetzt wird. Dies schützt die Server vor Überlastung.
Absolut. Durch die Begrenzung der Token-Nutzung und der Anforderungsraten verhindern Gateways eine unerwartete GPU-Übernutzung oder Cloud-Ausgaben. Unternehmen können die Nutzung an den Budgets ausrichten, einen abgestuften Zugriff planen und kostspielige Überbereitstellungen reduzieren und gleichzeitig einen konsistenten Service für kritische Workloads aufrechterhalten.
Ja. Moderne KI-Gateways wie TrueFoundry ermöglichen es Teams, Regeln zur Ratenbegrenzung in Echtzeit oder über automatisierte Skripte zu aktualisieren, um sicherzustellen, dass die Infrastruktur unerwartete Überspannungen ohne Ausfallzeiten oder Leistungseinbußen bewältigen kann. Dynamische Anpassungen sorgen dafür, dass der Service schnell reagiert und gleichzeitig eine faire Nutzung durch alle Mieter gewährleistet wird.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.




.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




