

July 1, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: May 20, 2026
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Gateways werden zur operativen Steuerungsebene von GenAI-Systemen. Sie vereinheitlichen den Datenverkehr für APIs von Drittanbietern (OpenAI, Anthropic, Mistral, Bedrock) und selbst gehostete Modelle, setzen Richtlinien durch und bieten eine zentrale Oberfläche für Latenz, Fehler, Tokenverbrauch und Ausgaben. Derselbe Engpass ist der ideale Ort, um Traces zu erfassen, Analysen auf Modell- und Benutzerebene zu berechnen und Leitplanken und Warnmeldungen auszulösen — ohne den Anforderungspfad zu verlängern.
Echte Organisationen haben das auf die harte Tour gelernt. Stellen Sie sich einen Support-Co-Piloten vor, der Tausende von Agenten betreut. Eines Nachmittags erhöht ein harmloses Prompt-Update die Länge der Ausgabe um ~ 40%. Die Zufriedenheit der Agenten sinkt, wenn die Antworten verzögert werden; die Finanzabteilung bemerkt die Rechnung. Mit der Gateway-Observability würden Sie beobachten, wie die Latenz und die Output-Token für die betroffene Route steigen, diese mit der Bereitstellungs- oder Prompt-Version korrelieren und ein Rollback durchführen — idealerweise mit einer automatischen Warnmeldung, die den Fehler beim nächsten Mal abfängt.
Dieser Beitrag fasst zusammen, was ein KI-Gateway ist, warum Observability so wichtig ist und welche konkreten Metriken, Dashboards und Workflows Teams einrichten sollten. Wir zeigen auch, wie das AI Gateway von TrueFoundry den Observability-Stack sofort einsatzbereit macht: vereinheitlichte Analysen (Latenz, TTFT/ITL, Fehler), detaillierte Kostenverfolgung, Aufschlüsselungen auf Kunden-/Benutzerebene, Sichtbarkeit von funktionieren/ausgefallenen Routings und skalierbare, in die Architektur integrierte Erfassung mit geringem Aufwand.
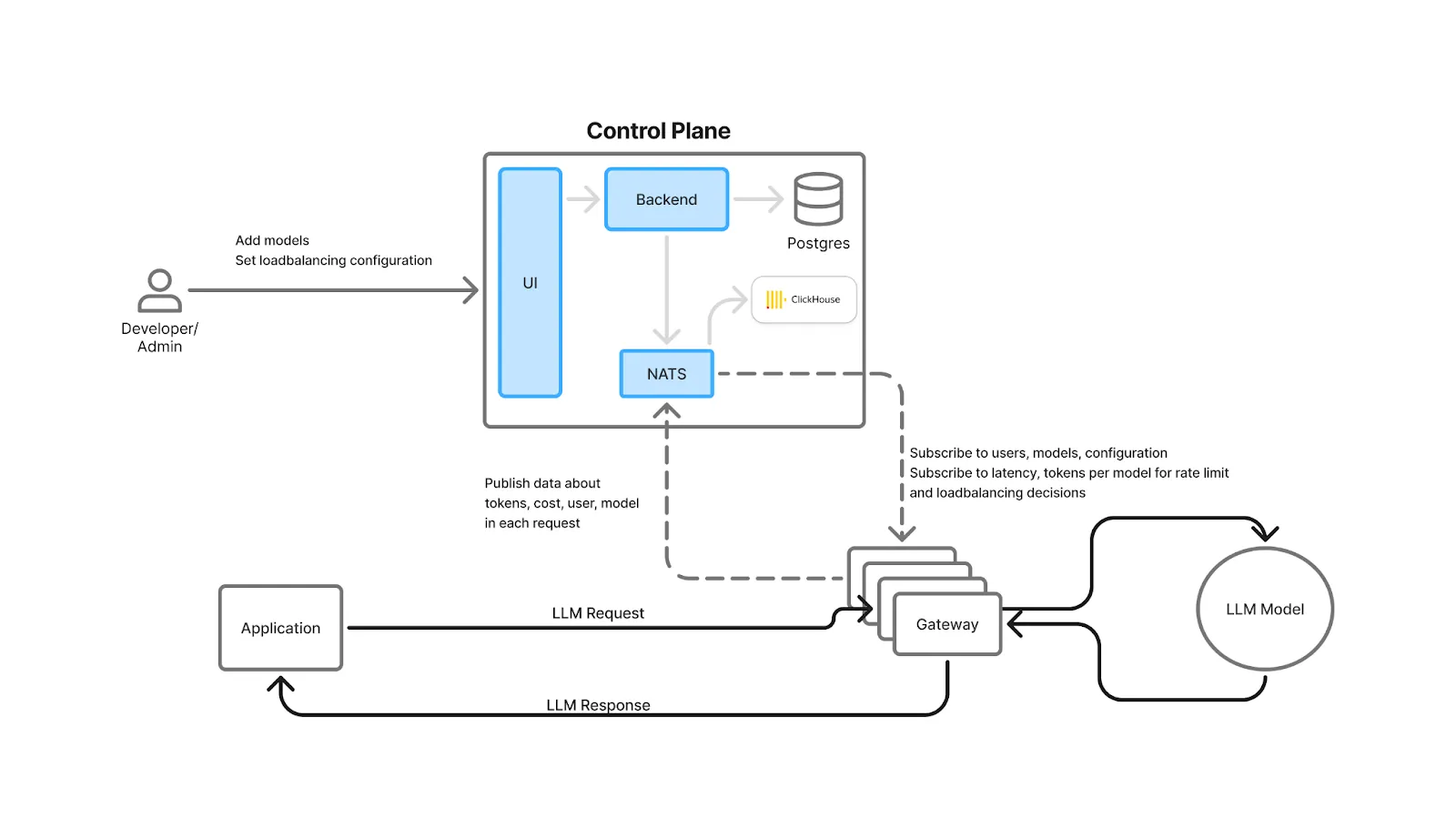
Ein KI-Gateway ist eine dünne, leistungsstarke Ebene, die Anwendungsanfragen an einen oder mehrere LLM-Anbieter oder selbst gehostete Modelle weiterleitet. Sie vereinheitlicht APIs, zentralisiert die Authentifizierung und RBAC (Rollenbasierte Zugriffskontrolle) , wendet Ratenlimits an und Leitplanken, führt Lastenausgleich und Failover und erfasst Beobachtbarkeits- und Kostendaten für jede Anfrage. Stellen Sie sich das als die Ebene „Ingress + Policy + Telemetrie“ für GENai vor.
In betrieblicher Hinsicht unterstützen moderne Gateways gewichtetes und latenzbasiertes Routing, Integritätsprüfungen und automatische Fallbacks, wenn ein Modell oder eine Region nicht mehr richtig funktionieren. So laufen Anfragen auch dann weiter, wenn der Anbieter Probleme hat. Da jede Anfrage das Gateway durchläuft, können Teams Anbieter anhand von Latenz und Kosten vergleichen und so OpenRouter gegen KI-Gateway eine praktische Bewertung bei der Entscheidung, wie Routing, Beobachtbarkeit und Kontrolle in großem Maßstab verwaltet werden sollen.
True Foundry's Die Architektur ist so konzipiert, dass diese Steuerelemente und Metriken nur minimalen Aufwand verursachen: prüft auf Authentifizierung, Ratenbegrenzung, und der Lastausgleich erfolgt im Arbeitsspeicher; Logs/Metriken werden asynchron in eine Warteschlange geschrieben; und der Anforderungspfad vermeidet externe Aufrufe (sofern Sie sich nicht für das Caching entscheiden). Das Gateway ist horizontal skalierbar und CPU-gebunden, sodass der Overhead der End-to-End-Latenz im einstelligen Millisekundenbereich liegt.
Die LLM-Latenz ist multimodal: Es gibt die Zeit bis zum ersten Token (TTFT), die Inter-Token-Latenz (ITL) für das Streaming und die gesamte Anforderungslatenz. Jeder wirkt sich unterschiedlich auf die wahrgenommene Nutzererfahrung aus. Gateways, die alle drei Faktoren verfolgen, helfen Ihnen bei der Diagnose, ob Verzögerungen auf Provider-Warteschlangen, Modellrechnungen, Netzwerk oder die Länge von Eingabeaufforderungen zurückzuführen sind — und die beste Routing-Strategie auszuwählen.
Tokens sind die neuen CPU-Zyklen. Eine einzige Aufforderung kann sich auf mehrere Tools oder Abrufschritte erstrecken, und die Kosten fallen bei allen Anbietern an. Observability muss die Ausgaben nach Modell, Anbieter, Umgebung, Anwendung, Mieter und Benutzer aufschlüsseln und stets auf dem neuesten Stand der öffentlichen Preisgestaltung der Anbieter sein, um manuelle Tabellenkalkulationen zu vermeiden.
Produktionsanwendungen benötigen Schutzmaßnahmen gegen Anbieterausfälle, Drosselung und Modellregressionen. Mithilfe von Integritätsprüfungen, Codeausfällen im 4xx/5xx-Format, Wiederholungs-/Fallback-Raten und der Nutzung von Ratenlimits können Sie SLOs durchsetzen und bei Leistungseinbußen automatisch einen Failover durchführen.
Unternehmen benötigen vollständige Anfrage-/Antwortprotokolle mit Zugriffskontrollen und Richtlinien zur Moderation personenbezogener Daten und Inhalte. Ein Gateway zentralisiert diese Durchsetzung und Protokollierung, sodass Teams nachweisen können, wer welches Modell mit welchen Daten aufgerufen hat und was zurückgegeben wurde — ohne die API-Schlüssel der Anbieter allgemein weitergeben zu müssen.
Modellqualität, Preisgestaltung und Quoten ändern sich häufig. Unternehmen, die Gateways bewerten, können Anbieter direkt miteinander vergleichen und den Traffic auf der Grundlage neuer Latenz-, Kosten- und Fehlerdaten verlagern. So bleiben Leistung und Margen erhalten, wenn sich der Markt weiterentwickelt.
Externe Leitlinien spiegeln diese Anforderungen wider: Branchenführer legen Wert auf KI-Beobachtbarkeit, um schnell auf Abweichungen, Ausfälle und Kostenspitzen reagieren zu können. OpenAI und Azure empfehlen eine strukturierte Protokollierung und exponentielles Backoff für Ratenlimits, die ein Gateway appübergreifend standardisieren kann.
Im Folgenden finden Sie Funktionen, die Sie von einem KI-Gateway in Produktionsqualität erwarten sollten — und die TrueFoundry von Haus aus bietet.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

So integriert TrueFoundry Observability in den zentralen Anforderungspfad und liefert sofort einen vollständigen Analytics-Stack aus, ohne den Produktionsdatenverkehr zu verlangsamen.
.webp)
Das Analytics-Dashboard zeigt: Anforderungslatenz (p50/p95/p99), Time to First Token (TTFT/TTFS), Inter-Token-Latenz (ITL), Kosten pro Modell/Anbieter, Eingabe-/Ausgabe-Tokens, Fehlercodes und Richtlinienaktivitäten (Ratenlimit, Lastenausgleich, Fallbacks, Leitplanken, Budgets). Ansichten sind nach Modell, Benutzer, Team, Rule-ID und benutzerdefinierten Metadaten unterteilt. Sie können auch Roh-CSVs herunterladen.
Aktiviere Public Cost, um die Preise pro Token automatisch anhand der veröffentlichten Tarife der Anbieter (OpenAI, Anthropic, Bedrock usw.) auszufüllen. Lege für verhandelte oder fein abgestimmte Modelle Private Cost mit benutzerdefinierten Input-/Output-Token-Preisen fest. Beide fließen in die Analyse der Kosten pro Anfrage und der Gesamtkosten ein.
Fügen Sie den Geschäftskontext (Kunde, Funktion, Umgebung) hinzu und unterteilen Sie Token, Latenz und Ausgaben nach beliebigen Dimensionen — ideal für Rückbuchungen, die Erkennung lauter Nachbarn und die Priorisierung von Optimierungen.
.webp)
Definieren Sie Kontingente nach Token oder Anfragen pro Minute/Stunde/Tag, bezogen auf Benutzer, Modelle oder Segmente, die über Metadaten identifiziert wurden. Dashboards zeigen Auslastung und Drosselungen an, sodass Sie die Grenzwerte richtig einschätzen und gemeinsam genutzte Kapazitäten schützen können.
Verwenden Sie gewichtsbasierte Splits für Experimente oder latenzbasiertes Routing für Steady-State. Zustandsprüfungen kennzeichnen Backends bei Fehler-/Latenzschwellenwerten als fehlerhaft und schließen sie automatisch aus. Fallback-Ketten versuchen es bei einem Ausfall erneut mit Spannweiten und Kennzahlen, die Aufschluss darüber geben, welcher Weg eingeschlagen wurde und welche Auswirkungen dies auf Latenz und Kosten hat.
Zentralisieren Sie Provider-Schlüssel, stellen Sie bereichsbezogene Zugriffstoken aus, setzen Sie RBAC durch und bewahren Sie unveränderliche Anforderungs-/Antwortprotokolle zur Einhaltung der Vorschriften auf — über LLMs und MCP-Server hinweg
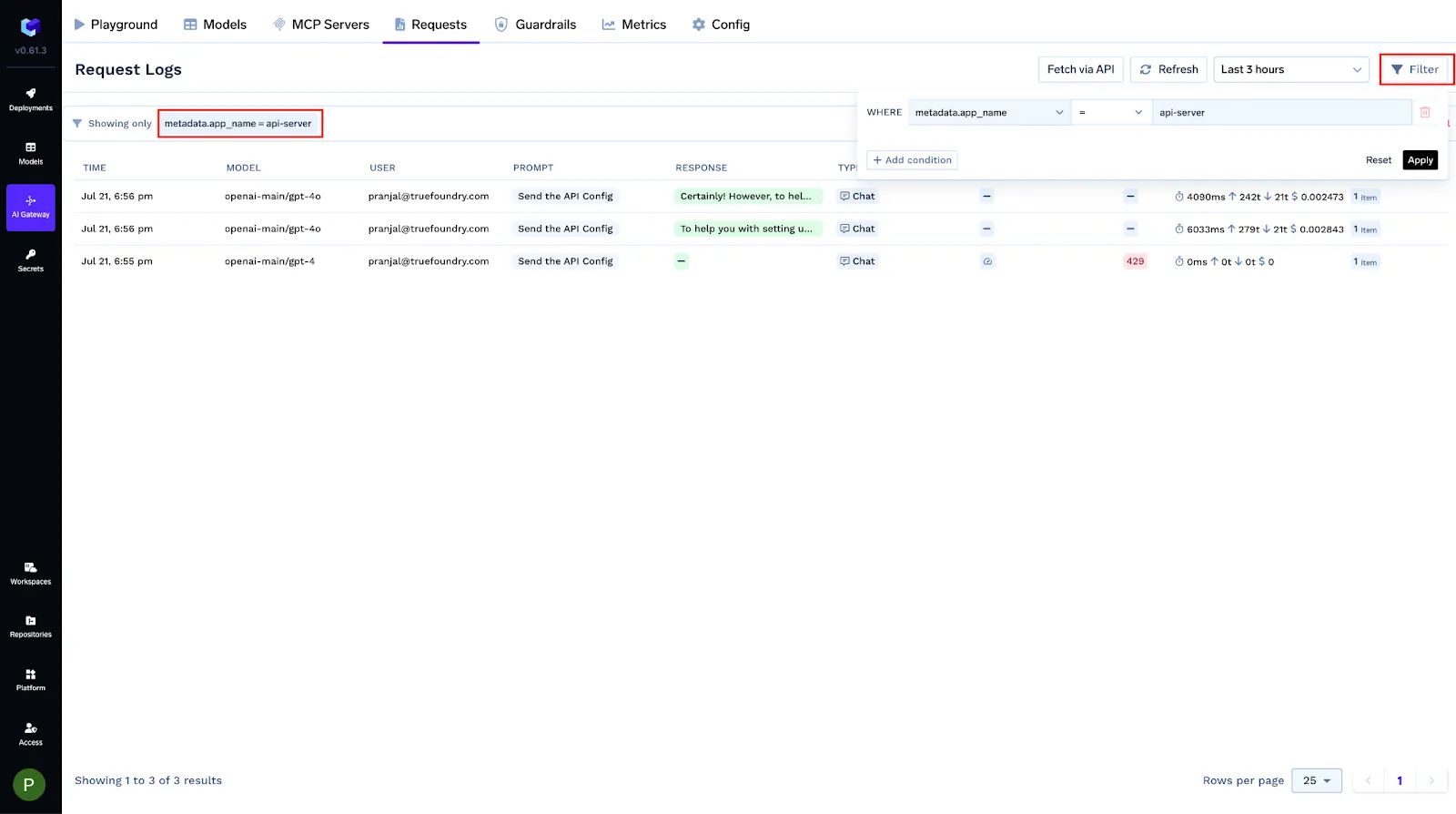
Du kannst jede Anfrage mit strukturierten Metadaten taggen über das X-TFY-METADATEN Kopfzeile. Protokollierte Schlüssel werden zu abfragbaren Filtern, Grafana-Labels und Bedingungen in Gateway-Konfigurationen (Ratenbegrenzungen, Lastausgleich, Fallbacks, Leitplanken). Werte sind Zeichenketten (≤128 Zeichen).
X-TFY-METADATA: {"tfy_log_request":"true","environment":"staging","feature":"countdown-bot","customer_id":"acme-42"}
Use this to isolate logs, group cost/latency by tenant or feature, and roll out policy changes safely to a subset of traffic.
Example — rate‑limit by metadata
name: ratelimiting-config
type: gateway-rate-limiting-config
rules:
- id: openai-gpt4-dev-env
when:
models: ["openai-main/gpt4"]
metadata:
env: dev
limit_to: 1000
unit: requests_per_day
Das Gleiche gilt, wenn das Metadatenmuster für Load Balancing- und Fallback-Regeln gilt
Das Gateway ist OpenTelemetry‑konform. Schalten Sie den OTLP-Export ein und senden Sie Traces an ein beliebiges Backend (Tempo, Jaeger, Datadog/New Relic via Collector, TrueFoundry Tracing). Zu den Spannweiten gehören Genai-Attribute — Modell, Tokens, TTFT, ITL, Parameter, Tool-Aufrufe, Fehler — und detaillierte Spannweiten für Ratenbegrenzung, Lastverteilung, Fallbacks und MCP-Server-/Tool-Aufrufe, sodass Sie das Verhalten des Anbieters mit den Spans auf App-Ebene korrelieren können.
Tracing aktivieren
ENABLE_OTEL_TRACING="true"
OTEL_SERVICE_NAME=<your_service>
OTEL_EXPORTER_OTLP_TRACES_ENDPOINT="https://<otel-collector>/v1/traces"
OTEL_EXPORTER_OTLP_TRACES_HEADERS="Authorization=Bearer <token>"Repräsentative Spannweiten
.webp)
Expose /metrics for Prometheus or push OTEL metrics by setting:
ENABLE_OTEL_METRICS="true"
OTEL_EXPORTER_OTLP_METRICS_ENDPOINT="https://<otlp-endpoint>/v1/metrics"
OTEL_EXPORTER_OTLP_METRICS_HEADERS="Authorization=Bearer <token>"
LLM_GATEWAY_METADATA_LOGGING_KEYS='["customer_id","request_type"]'
Metadata keys listed in LLM_GATEWAY_METADATA_LOGGING_KEYS become Prometheus labels llm_gateway_metadata_<key>, enabling per‑customer/per‑feature cost and latency charts. (Truefoundry Docs)<key>In LLM_GATEWAY_METADATA_LOGGING_KEYS aufgeführte Metadatenschlüssel werden zu den Prometheus-Labels llm_gateway_metadata_, wodurch Kosten- und Latenzdiagramme pro Kunde/pro Funktion ermöglicht werden. (Truefoundry-Dokumente)
Wichtige Kennzahlenfamilien (Teilmenge)
Tokens & cost: llm_gateway_input_tokens, llm_gateway_output_tokens, llm_gateway_request_cost.
Latency: llm_gateway_request_processing_ms, llm_gateway_first_token_latency_ms, llm_gateway_inter_token_latency_ms.
Errors: llm_gateway_request_model_inference_failure, llm_gateway_config_parsing_failures.
Policy activity: llm_gateway_rate_limit_requests_total, llm_gateway_load_balanced_requests_total, llm_gateway_fallback_requests_total, llm_gateway_budget_requests_total, llm_gateway_guardrails_requests_total.
Agent/MCP: llm_gateway_agent_request_duration_ms, llm_gateway_agent_llm_latency_ms, llm_gateway_agent_tool_latency_ms, llm_gateway_agent_tool_calls_total, llm_gateway_agent_mcp_connect_latency_ms, llm_gateway_agent_request_iteration_limit_reached_total. EIN vorgefertigtes Grafana-Dashboard JSON wird von TrueFoundry veröffentlicht, organisiert in Modell, Nutzer, Konfig, und MCP-Aufruf Ansichten. Fügen Sie Variablen für Ihre benutzerdefinierten Metadaten hinzu, z. B.:
label_values(llm_gateway_input_tokens, llm_gateway_metadata_customer_id).webp)
Das Model Context Protocol (MCP) von Anthropic, das am 25. November 2024 angekündigt wurde, standardisiert, wie Assistenten mit Tools, Eingabeaufforderungen und Ressourcen verbunden sind. Das Ökosystem hat sich bis 2025 durch viele vorgefertigte Server (GitHub, Slack, Google Maps, Puppeteer usw.) beschleunigt.
TrueFoundry integriert MCP nativ:
Dadurch wird das Gateway zur operativen Kontrollebene für agentische Workloads. Es vereinheitlicht Richtlinien, Authentifizierung, Routing und durchgängige Transparenz sowohl bei LLM-Aufrufen als auch bei der Ausführung von Tools.
Nachfolgend finden Sie eine praktische Checkliste. Jede Metrik beinhaltet, was sie Ihnen sagt, wie sie verwendet wird und wie TrueFoundry sie darstellt.
Eine zeitnahe Änderung erhöht die Ausführlichkeit der Ausgabe für Unternehmenskunden. Symptome: steigende Output-Tokens, höhere p95-Latenz und tägliche Ausgaben. Aktion mit TrueFoundry: Analysen zeigen einen Anstieg der Output-Token für die „Support‑Prod“ -Umgebung und einen Kostenanstieg für das primäre Modell. Du vergleichst einen alternativen Anbieter, der niedrigere TTFT-Werte und günstigere Output-Token anbietet. Du verlagerst 30% des Traffics über gewichtetes Routing und stellst eine Warnung für „Kosten pro Konversation“ ein.
Um 10:00 UHR IST stiegen die Fehlerraten auf 429 Sekunden. Aktion mit TrueFoundry: Dashboards zur Ratenbegrenzung bestätigen Drosselungen vom Upstream. Fallback-Ketten setzen ein und das Routing verlagert sich hin zu einem gesünderen Backend. Sie sorgen für eine stabile Benutzererfahrung und passen später Token-Kontingente und Backoff-Parameter an.
Benutzer berichten, dass „die Antwort schnell beginnt, dann aber crawlt“. Aktion mit TrueFoundry: TTFT ist in Ordnung, aber ITL ist beim Primärmodell erhöht. Latenzbasiertes Routing bevorzugt automatisch einen Anbieter mit besserem Streaming-Durchsatz. Außerdem haben Sie eine Warnung für ITL p95 eingerichtet.
Der Batch-Job eines Kunden verschlingen Tokens und verlangsamt alle anderen. Aktion mit TrueFoundry: Tokenbasierte Ratenbegrenzungen der Kunden setzen Fair‑Share durch und schützen SLOs. Analysen verifizieren die Auslastung und die Anzahl abgelehnter Ablehnungen, sodass du höhere Quoten weiterverkaufen kannst.
LLM-Anwendungen sind dynamische Systeme. Modelle entwickeln sich weiter, Anbieter ändern Kontingente und Preise, Eingabeaufforderungen verändern sich und das Nutzerverhalten überrascht Sie. Mit dem AI Gateway können Sie all das beobachten, steuern und optimieren — vorausgesetzt, Sie sammeln die richtigen Signale und setzen sie in Aktionen um.
Das AI Gateway von TrueFoundry bietet Ihnen diese operative Kommandozentrale. Es erfasst Latenz (TTFT/ITL), Tokens, Kosten und Fehler mit geringem Aufwand, setzt Token-fähige Ratenbegrenzungen, RBAC und Guerdrails durch und bietet einen Überblick über Routing, Zustand und Fallback, sodass Sie für schnelle, zuverlässige und kosteneffiziente Erlebnisse sorgen können. Mithilfe detaillierter Kunden-/Benutzeranalysen und automatisierter, aktueller Kostenzuweisung können Teams von der reaktiven Brandbekämpfung zur proaktiven Optimierung übergehen.
Wenn Sie Ihren GENAI-Stack zentralisieren oder eine Vielzahl einmaliger Integrationen entwirren möchten, leiten Sie zunächst den Datenverkehr durch das Gateway, schalten Sie die Dashboards oben ein und richten Sie einige SLO-orientierte Warnmeldungen ein. Sie erhalten die Transparenz, um schneller zu versenden, die Kosten einzudämmen und Ihre Agenten und Benutzer zufrieden zu stellen.
Observability in AI Gateway hilft dabei, komplexe, mehrstufige Überlegungen und Tool-Aufrufe nachzuvollziehen, die ansonsten undurchsichtig sind. Die Überwachung der Ausführungspfade der Agenten hilft dabei, Endlosschleifen, Halluzinationen und ineffiziente Werkzeugnutzung in Echtzeit zu erkennen. Diese Transparenz stellt sicher, dass autonome Agenten zuverlässig, vorhersehbar und im Rahmen des Budgets bleiben, während sie mit verschiedenen externen Systemen und APIs interagieren.
Die KI-Gateway-Observability optimiert die LLM-Leistung, indem Latenz, Durchsatz und Fehlerraten verschiedener Modellanbieter in Echtzeit verfolgt werden. Durch die Erfassung granularer Kennzahlen wie Time to First Token (TTFT) und Inter-Token-Latency (ITL) können Teams spezifische Engpässe in der Inferenzkette lokalisieren. Diese Erkenntnisse ermöglichen es Entwicklern, Modellgeschwindigkeiten objektiv zu vergleichen und intelligentes Routing zu implementieren, um Endbenutzern eine Hochgeschwindigkeitsleistung zu gewährleisten.
Die Observability des KI-Gateways reduziert die Kosten, indem sie einen detaillierten Einblick in den Token-Verbrauch zwischen Modellen, Teams und Benutzern bietet. Die Nachverfolgung der Ausgaben pro Anfrage und Arbeitsbereich ermöglicht es Teams, außer Kontrolle geratene Aufforderungen oder ineffiziente Arbeitsabläufe sofort zu erkennen. Diese Daten unterstützen automatisierte Strategien zur Kosteneinsparung wie semantisches Caching, Token-basierte Ratenbegrenzung und die Weiterleitung von Abfragen an günstigere Modelle ohne manuelles Eingreifen.
Die KI-Gateway-Observability unterstützt die Compliance-Prüfung, indem ein zentralisiertes, unveränderliches Protokoll jeder Anfrage und Antwort geführt wird. Moderne Systeme zeichnen detaillierte Prüfprotokolle auf, einschließlich Benutzer-IDs, Zeitstempeln und Maskierungsereignissen von personenbezogenen Daten, um sensible Daten zu schützen. Diese Protokolle stellen sicher, dass Unternehmen regulatorische Standards wie die DSGVO und SOC 2 einhalten, indem sie vollständige Transparenz der Modellinteraktionen bieten, wobei häufig die gesamte Telemetrie in der sicheren Cloud-Umgebung des Unternehmens gespeichert wird.
TrueFoundry vereinfacht das KI-Infrastrukturmanagement, indem mehrere Modellanbieter durch Beobachtbarkeit in KI-Gateways auf einer einzigen Steuerungsebene vereint werden. TrueFoundry korreliert Telemetrie auf Anforderungsebene mit der GPU- und CPU-Auslastung, um die Ressourcenzuweisung zu optimieren und Verschwendung zu reduzieren. Dieser integrierte Ansatz ermöglicht es Plattformteams, Bereitstellungen, Skalierung und Sicherheitsrichtlinien in verschiedenen Umgebungen nativ in ihren AWS-, GCP- oder Azure-Konten zu verwalten.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.




.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




