

July 21, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: July 8, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Die Rechenverfügbarkeit ist der primäre Engpass für das Training von LLMs und die Skalierung von Inferenzen mit hohem Durchsatz. Wenn Sie versucht haben, eine Bereitstellung durchzuführen Amazon EC2 P5-Instanzen Bei Azure ND H100 v5-VMs sind Sie in letzter Zeit wahrscheinlich auf InsuffizientInstanceCapacity-Fehler gestoßen oder es wurde Ihnen mitgeteilt, dass Sie eine mehrjährige private Preisvereinbarung benötigen.
Diese Knappheit macht spezialisierte GPU-Anbieter wie CoreWeave, Lambda Labs und FluidStack zu brauchbaren Alternativen. Diese „Neo-Clouds“ bieten NVIDIA H100s und A100 oft zu niedrigeren On-Demand-Tarifen als die großen Drei.
Das Problem? Führen Sie AWS für Ihre Amazon S3 Ein Data Lake beim manuellen Hochfahren von Bare-Metal-Nodes in Lambda Labs führt zu fragmentierten Workflows. Wir lösen dieses Problem, indem wir spezialisierte Clouds als Standard behandeln Kubernetes Cluster innerhalb einer einheitlichen Kontrollebene.
TrueFoundry verwendet eine Split-Plane-Architektur. Die Steuerungsebene übernimmt die Arbeitsplanung und die Versuchsverfolgung, während die Rechenebene in Ihrer Umgebung bleibt. Da die meisten spezialisierten Clouds eine verwaltete Kubernetes Service oder Erlaube dir die Bereitstellung K3s, wir fügen sie über einen Standardagenten hinzu.
Wir abstrahieren die Speicherung und den Eingang. Unabhängig davon, ob der Anbieter Vast Data oder lokales NVMe-RAID verwendet, ordnen wir es einem zu Anhaltender Volumenanspruch. Das hält deine Docker Container, die anbieterübergreifend portabel sind.
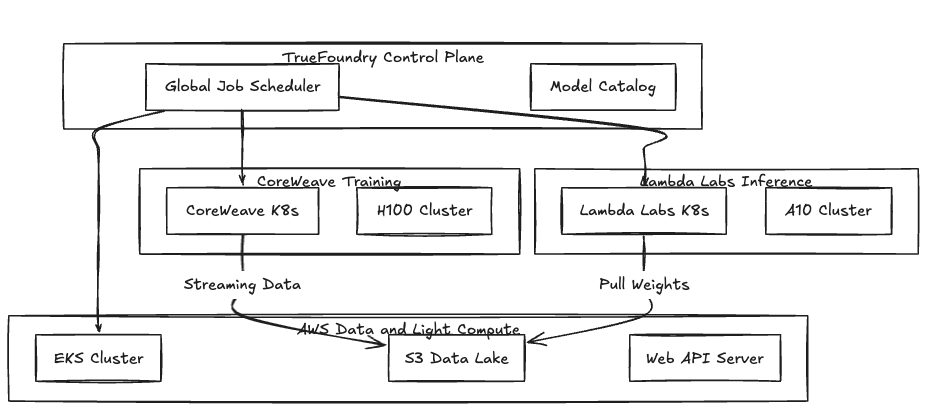
Abbildung 1: Hybridtopologie, die AWS für Datenpersistenz und spezialisierte Clouds für GPU-intensive Workloads nutzt.
Die H100-Preise auf Abruf variieren erheblich. Wir verwenden TrueFoundry, um priorisierte Warteschlangen einzurichten. Sie können zunächst günstige, unterbrechbare Kapazitäten in speziellen Clouds ins Visier nehmen. Wenn der Anbieter die Instance verhindert oder die Kapazität verschwindet, kann der Scheduler automatisch einen Failover auf eine reservierte Instanz durchführen Amazon EC2 Instanz.
Wenn Sie sich auf proprietäre KI-Plattformen verlassen, sind Sie oft an den Speicher und das IAM-Ökosystem einer bestimmten Cloud gebunden. Wir verpacken Schulungsjobs als Standardcontainer. TrueFoundry kümmert sich um Kubernetes CSI-Treiber für S3-Montage und konfiguriert den NVIDIA-Container-Toolkit Umgebungsvariablen automatisch. Sie verschieben einen Job von AWS nach CoreWeave, indem Sie den cluster_name in Ihrer Bereitstellungsspezifikation aktualisieren.
Multi-Cloud-Setups unterbrechen normalerweise die Protokollierung. Wir aggregieren Prometheus Metriken und Grafana Dashboards in allen Clustern. Wenn ein Trainingsjob auf einem Lambda Labs-Knoten gestartet wird, werden die GPU-Auslastung und die Systemprotokolle in derselben Benutzeroberfläche angezeigt, die Sie für Ihre EKS-Produktionsumgebung verwenden.
Folgen Sie diesem Lebenszyklus, um spezielle Kapazitäten hinzuzufügen:
helm repo add truefoundry https://truefoundry.github.io/infra-charts/
helm install tfy-agent truefoundry/tfy-agent \
--set tenantName=my-org \
--set clusterName=lambda-h100-pool \
--set apiKey=<YOUR_API_KEY>
Vergleich von Infrastrukturmodellen
Für wachstumsstarke Entwicklungsteams ist es keine praktikable Strategie mehr, sich für LLM-Computing auf eine einzige Cloud zu verlassen. Indem Sie die Workload-Definition vom Ausführungsort entkoppeln, können Sie GPUs wie eine Handelsware behandeln. Leiten Sie Ihre intensiven Schulungen aus Effizienzgründen an spezialisierte Clouds weiter, während Ihre Kerndaten und -dienste in Ihrer primären Hyperscale-Region bleiben.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


