

October 5, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Ein Modell zu entwickeln, um einen Geschäftsanwendungsfall zu lösen, klingt für uns alle nach einer großartigen Idee. Es scheint intuitiv, dass, wenn wir das Engagement durch Personalisierung auf einer bestimmten Website mithilfe von ML um 5% steigern können, der Umsatz um einige Prozent steigen wird.
Was jedoch oft übersehen wird, sind zwei Faktoren, die dieses Projekt gefährden können:
Nun, sollte es nicht einfach sein, die 2 Dinge auszuprobieren? Nun, lassen Sie uns näher darauf eingehen, was es braucht, um von der Idee, ein Modell zu bauen, bis das Modell schließlich in Produktion geht und die Auswirkungen auf das Geschäft bewertet werden. Betrachten wir den Fall, dass in einer App für die Lieferung von Lebensmitteln die voraussichtliche Lieferzeit angezeigt werden soll, sobald ein Kunde eine Bestellung in der App aufgibt. Da wir die Lieferzeit nicht im Voraus kennen, müssen wir ein ML-Modell erstellen, das die Vorhersage auf der Grundlage bestimmter Faktoren wie Stadt, Restaurant, Tageszeit, Entfernung vom Kunden zum Restaurant usw. durchführen kann.
Zeigen Sie dem Benutzer die geschätzte Lieferzeit für eine App zur Lieferung von Lebensmitteln an
An dem Arbeitsablauf zur Herausgabe dieses Modells werden die folgenden Teams beteiligt sein:
Der Produktmanager wird das Projekt ausarbeiten, um die Lieferzeit abzuschätzen. Es wird erwartet, dass, wenn die Lieferzeit angemessen genau ist, den Benutzern ein besseres Erlebnis bietet. Es wird weniger Anfragen von Kunden zu Lieferzeiten geben, und die allgemeine Kundenzufriedenheit dürfte steigen. Das Geschäftsteam wird dann das Data-Science-Team bitten, dieses Modell zu entwickeln.
Datenwissenschaftler beginnen mit der Erfassung der historischen Daten aller getätigten Bestellungen und ihrer Lieferzeiten.
Der Datenwissenschaftler wird dann Analysieren Sie die Daten, um zu sehen, ob alles korrekt aussieht - keine Null- oder falschen Werte und ob alle erforderlichen Daten vorhanden sind. Sehr oft - der DS entdeckt ein paar Fehler im Datensatz - oder vielleicht gibt es ein paar Tage lang schlechte Daten aufgrund einiger vorübergehender Fehler. Wir müssen die falschen Daten aussortieren, da nur dann ein gutes Modell gebaut werden kann. Dies kann zu einigen Iterationen mit dem Produkt- und Datenentwicklungsteam führen.
Sobald die Daten gut aussehen, möchten Datenwissenschaftler in einigen Fällen eine Pipeline für die Berechnung von Merkmalen und das Speichern der Merkmale haben, damit es nicht zu einer für das Training erforderlichen Verzerrung kommt und es einfacher ist, die Merkmalswerte während der Inferenz zu ermitteln.
Dies ist jedoch ein optionaler Schritt und wird übersprungen, wenn die Daten oder die Anzahl der Modelle, die auf demselben Datensatz basieren, gering ist. Falls sich ein Team für das Feature-Engineering entscheidet, benötigen wir ein Pipeline-Orchestrierungssystem wie Airflow, Prefect und eine Datenbank bzw. einen Cache, um die Funktionen für den Abruf zu speichern (z. B. Feast). Der Aufbau eines Feature Stores ist an sich schon ein riesiges Unterfangen und erfordert erheblichen Aufwand.
Sobald alle Daten bereit sind, experimentiert der Datenwissenschaftler nun mit verschiedenen Algorithmen, Funktionen und Modellen, um herauszufinden, welches die beste Leistung erbringt. Sie würden alle Metriken, Parameter und Modelle protokollieren wollen, damit sie später darauf zurückgreifen oder sie mit anderen Teammitgliedern teilen können. Hier kommen ein Experiment-Tracking und ein Modell-Metadatenspeicher ins Spiel..
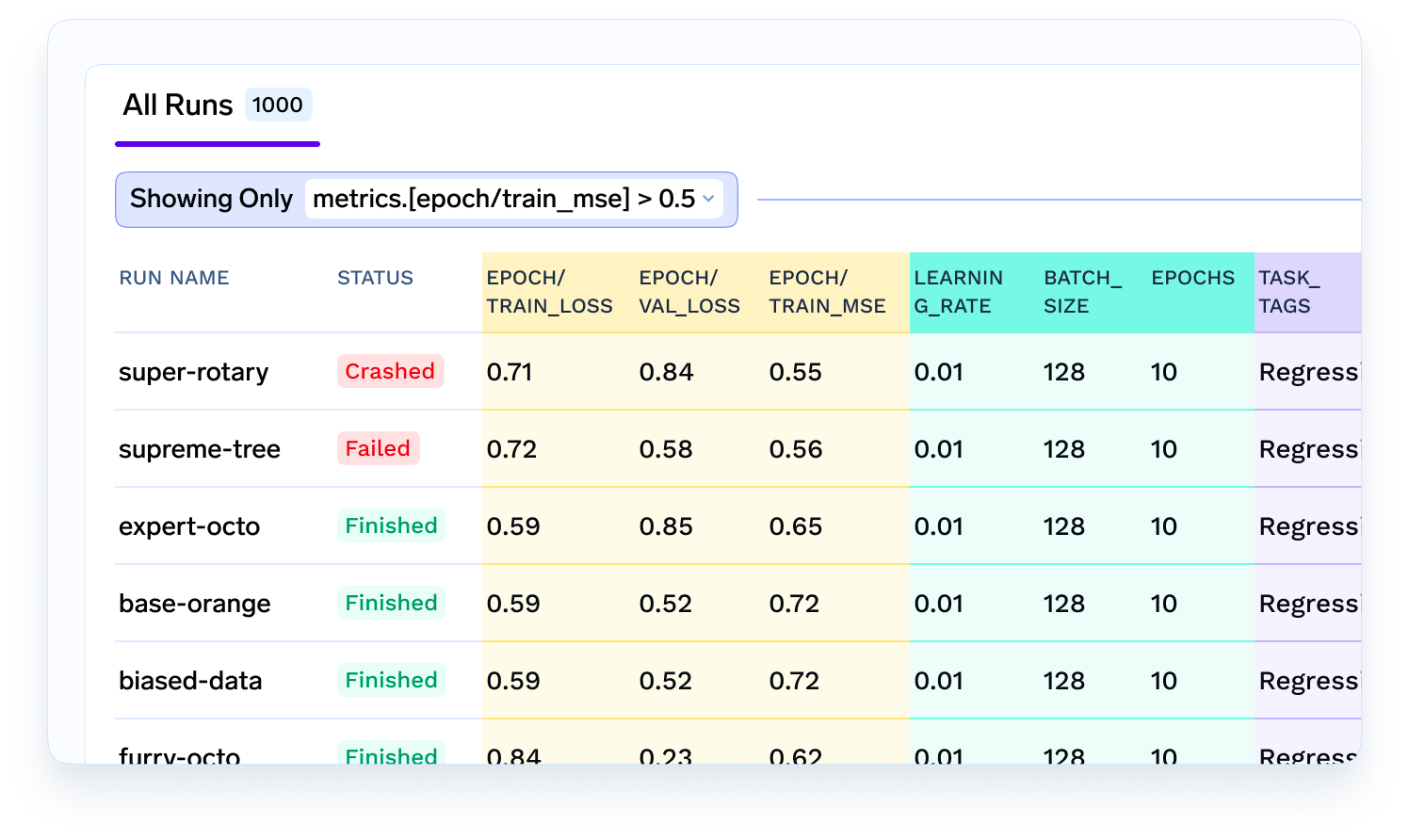
Sobald das Modell erstellt ist, muss es als Microservice oder als Batch-Inferenz-Job gehostet werden. In unserem Fall der Lieferzeitprognose muss es sich um einen Online-Dienst in Echtzeit handeln. Daher ist es wahrscheinlich sinnvoll, ihn als Autoscaling-Service bereitzustellen. In diesem Fall springt ein ML-Ingenieur ein, der das Modell nimmt, es in einen Flask- oder FastAPI-Dienst verpackt und das Docker-Image erstellt. Dann wird der ML-Ingenieur es zusammen mit Hilfe des Devops-Teams als Microservice auf der Infrastruktur bereitstellen.
Sobald die Modell-API gehostet ist, muss das Produkt- oder Backend-Team die API in ihrem Code aufrufen, um die vorhergesagte Lieferzeit zu nutzen und sie in der App anzuzeigen. Dies erfordert die Zusammenarbeit zwischen den Teams Data Scientist, Product und ML Engineering. Während dieser Zeit möchte der Produktmanager möglicherweise die Vorhersagen testen, und es wäre toll, wenn er das Modell schnell anhand einiger Beispieleingaben testen kann. Dazu muss möglicherweise eine kurze Modelldemo erstellt werden.
Sobald das Modell bereitgestellt ist und im Produkt verwendet wird, benötigen wir Metriken für das bereitgestellte Modell.
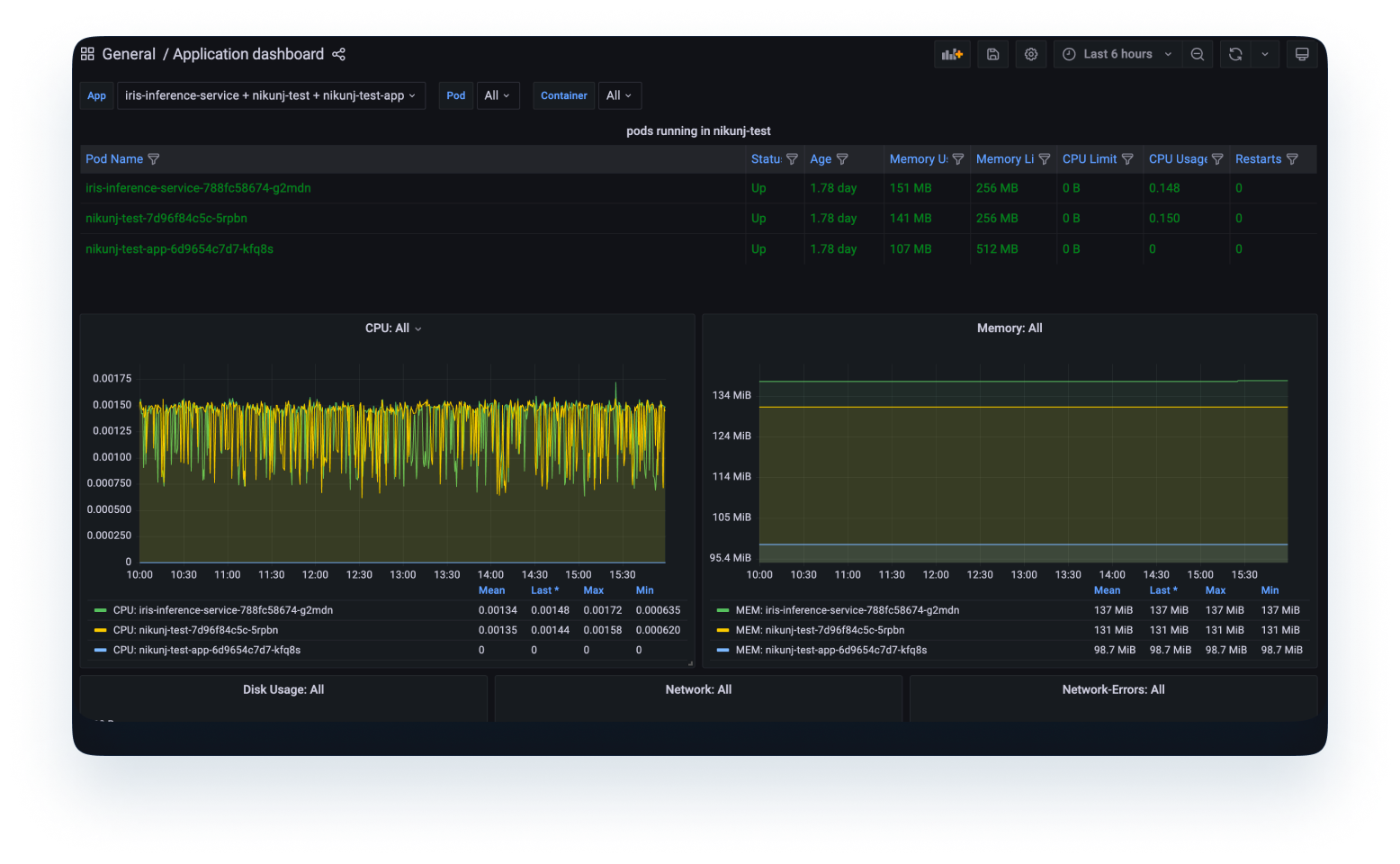
2. Überwachung des Modells: Dies schließt die Metriken ein, die sich auf die Modellprognose der eingehenden Produktionsdaten beziehen. Dies sind Daten, an denen der Data Scientist in erster Linie interessiert sein wird. Dazu gehören Metriken wie Modellgenauigkeit, Merkmalsdrift, Prognosedrift usw. Dies hilft dem Datenwissenschaftler bei der Entscheidung, ob sich das Modell ähnlich verhält wie beim Training, die Verteilung der externen Eingabedaten hat sich nicht geändert und ob es an keiner anderen Stelle im System Fehler gibt.

Um eine vollständige Überwachung des Modells zu erreichen, sind erhebliche Anstrengungen der DataScience-, Engineering- und DevOps-Teams erforderlich.
Sobald die gesamte Überwachung abgeschlossen ist, möchte der Datenwissenschaftler idealerweise die gesamte Umschulungsschleife automatisieren. Dazu ist ein Framework zur Pipeline-Orchestrierung wie Kubeflow oder Airflow erforderlich.
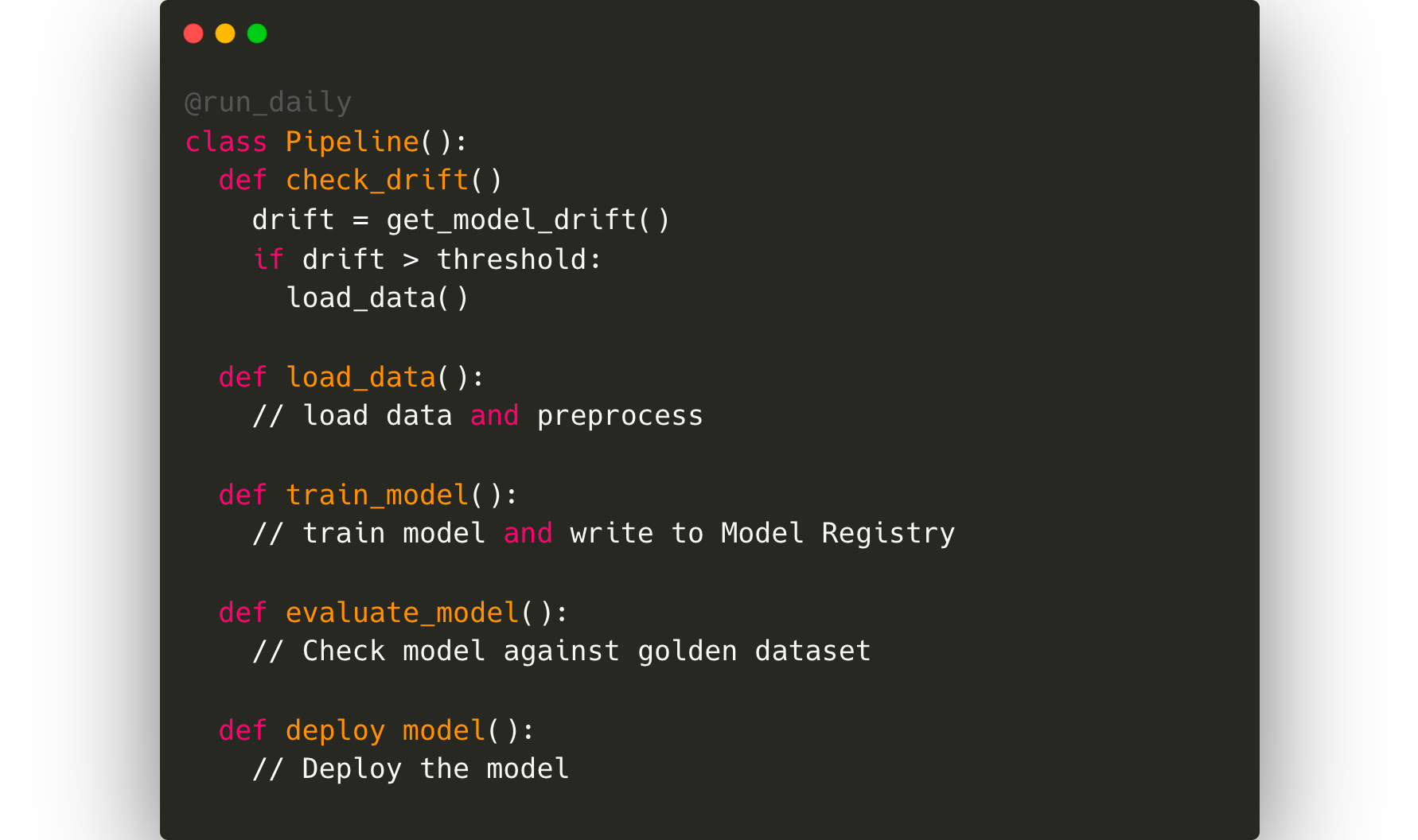
Anschließend müssen wir auch die Auswirkungen dieses Modells auf die tatsächlichen Kennzahlen zur Nutzerzufriedenheit abschätzen. Ein paar Proxy-Metriken sind in diesem Fall die Anzahl der Kundenanfragen im Zusammenhang mit den Lieferzeiten und die Gesamtzufriedenheit der Kunden mit einer Bestellung. Die Geschäftskennzahlen müssen mit den Modellkennzahlen verknüpft werden, und das Data Engineering-Team wird wahrscheinlich eine ETL-Pipeline schreiben, um diese Daten abzurufen und sie in einem internen Dashboard-Tool darzustellen, damit die Unternehmensleiter sie beobachten können.
Um es grob zusammenzufassen, betrifft dies 5 Interessengruppen:

Der gesamte Prozess dauert in jedem Unternehmen leicht über 2-3 Monate und kann bei den ersten Modellen manchmal bis zu 6 Monate dauern. Aufgrund der Tatsache, dass mehrere Interessengruppen beteiligt sind und mehrere Fähigkeiten involviert sind, erfordert es so viel Zeit und anfängliche Vorabinvestitionen, um ML wirksam zu machen.
Wir haben noch nicht über einige der Skalierbarkeits- und Zuverlässigkeitsaspekte des Prozesses gesprochen. Wir hoffen, einige der folgenden Aspekte in einem zukünftigen Artikel behandeln zu können.
Die Lösung besteht darin, die Teile zu automatisieren, die automatisiert werden können, und dem Datenwissenschaftler/ML-Ingenieur die Autonomie zu geben, die meisten Schritte auszuführen, ohne alle beteiligten Tools zu erlernen. In diesem Bereich wird viel gearbeitet und hoffentlich wird die Erstellung eines wirkungsvollen ML-Modells in ein paar Jahren so einfach sein, wie heute eine Landingpage zu erstellen!
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.









.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




