

July 21, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Es ist der interne KI-Hackathon Ihres Unternehmens, und der Programmieragent eines Teilnehmers steckt in einer ungewollten Wiederholungsschleife fest. Es sendet stundenlang Anfragen mit langem Kontext an ein teures Modell.
Da die Organisatoren jedem Teilnehmer die unformatierten Anbieterschlüssel aushändigten, gibt es keine Kontrolle über Ausgaben oder die Geschwindigkeit der Anfragen auf Teamebene. Am Montagmorgen hatte ein außer Kontrolle geratener Workflow einen großen Teil des gemeinsamen LLM-Budgets aufgebraucht und das Unternehmen in Schwierigkeiten mit der Ratenbegrenzung gebracht.
Diese Geschichte landet, weil sie plausibel ist. Die eigentliche Lektion ist jedoch umfassender: Das richtige Unternehmensmuster für einen Hackathon besteht nicht darin, rohe Anbieterdaten zu verteilen und zu hoffen, dass sich die Teams verhalten. Es leitet jede Anfrage über ein kontrolliertes Gateway weiter, das Teams trennen, Richtlinien an Metadaten anhängen und Experimente in einem kontrollierten Betriebsmodell ablaufen lassen kann.
TrueFoundry passt hervorragend zu diesem Muster, da es Kubernetes-native Workspace-Grenzen, geheime Umleitung, metadatenorientierte Richtlinienkontrollen, Agentenleitlinien und eine Gateway-native Spielwiese kombiniert. Die genauere Behauptung ist nicht, dass es bei jedem Burst-Pattern „Null Lecks“ oder eine perfekte Hard-Stop Accounting garantiert. Die stärkere und vertretbarere Behauptung ist, dass es den Plattformteams eine glaubwürdige Kontrollebene für die Durchführung von Hackathons gibt, ohne dass sie zu unkontrollierbaren Kosten- und Sicherheitsereignissen werden.

Die erste Regel eines sicheren Hackathons ist einfach: Die Teilnehmer sollten niemals die rohen API-Schlüssel des Anbieters sehen müssen. Sobald ein Schlüssel in Notebooks, lokale Umgebungen oder Agentenkonfigurationsdateien kopiert wird, wird dies sowohl zu einem Sicherheitsproblem als auch zu einem Abrechnungsproblem.
Das Workspace-Modell von TrueFoundry hilft hier, da die Workspace-Isolation den Kubernetes-Namespace-Grenzen zugeordnet ist. In der Praxis bedeutet das, dass Workloads für einen Workspace in einem anderen Namespace ausgeführt werden als Workloads in einem anderen Workspace, und Anbieter-Anmeldeinformationen können über geheime Gruppen und geheime FQNs offengelegt werden, anstatt sie direkt in App-Manifeste oder Quelldateien einzufügen.
Das ist die richtige Architektur für Hackathon-Teams. Geben Sie jedem Team einen Arbeitsbereich, geben Sie Workloads nur Zugriff auf die geheimen Gruppen, die sie benötigen, und behalten Sie die eigentlichen Anbieter-Anmeldeinformationen die ganze Zeit über unter der Kontrolle der Plattform. Die Benutzererfahrung ist immer noch einfach, aber der Explosionsradius ist kleiner und überprüfbar.
Die wichtigste operative Frage bei einem KI-Hackathon ist nicht, ob Sie Ausgaben im Nachhinein sehen können. Es geht darum, ob die Plattform die Richtlinien auf dem Anforderungspfad evaluieren kann, bevor ein außer Kontrolle geratener Workload teuer wird.
Die Gateway-Ebene von TrueFoundry bewertet Authentifizierung, Routing, Leitplanken, Ratenbegrenzungen und Budgetrichtlinien auf dem Hot-Path mithilfe des In-Memory-Status, der eine Durchsetzung mit niedriger Latenz vor dem Modellaufruf ermöglicht. Das ist wesentlich besser als ein Design, bei dem die einzig zuverlässige Kostenübersicht erst nach der Weiterverarbeitung der Protokolle vorliegt.
Der besonders nützliche Teil für Hackathons ist das Metadaten-Scoping. Anstatt eine Regel pro Team von Hand zu erstellen, können Sie die Teamidentität in x-tfy-metadata anhängen und Richtlinien mithilfe von Feldern wie metadata.project_id dynamisch anwenden. Das bedeutet, dass sich eine Budgetregel und eine Regel für Ratenlimits in einzelne Zähler und Ausgabenumschläge pro Team aufsummieren können.
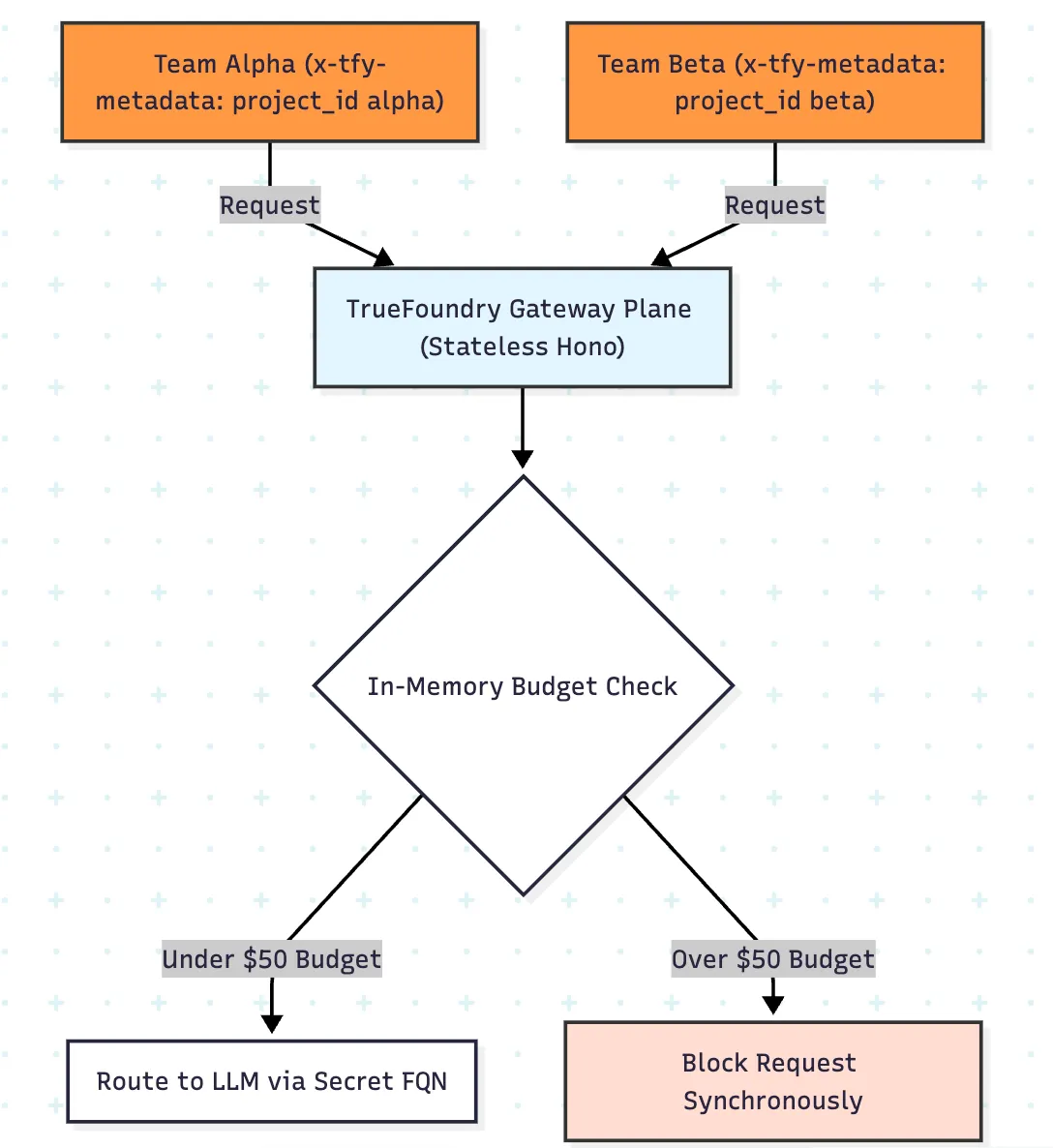
Bei Hackathons probieren Teams MCP-Server, Tool-Calling-Agenten, Datenbankkonnektoren und interne APIs aus. Genau an dieser Stelle beginnt ein herkömmliches LLM-Sicherheitsmodell zu versagen.
Das Guardrail-Modell von TrueFoundry ist hier besonders relevant, da es vier Ausführungspunkte verfügbar macht: LLM-Eingabe, LLM-Ausgabe, MCP-Pre-Tool und MCP-Post-Tool. Dadurch erhalten Plattformteams eine operativere Möglichkeit, Agenten zu steuern, als sich auf einen einzigen generischen Filter vor dem Modell zu verlassen.
Der nützliche Unterschied besteht darin, dass verschiedene Risiken in verschiedenen Phasen auftreten. Während des Eintritts kann es zu einer sofortigen Injektion kommen. Unsichere Werkzeugargumente werden vor der Ausführung angezeigt. Vertrauliche Datensätze werden möglicherweise erst angezeigt, nachdem das Tool zurückgekehrt ist. Bei einem Modell mit vier Haken können Sie das richtige Steuerelement an der richtigen Stelle im Fluss platzieren.
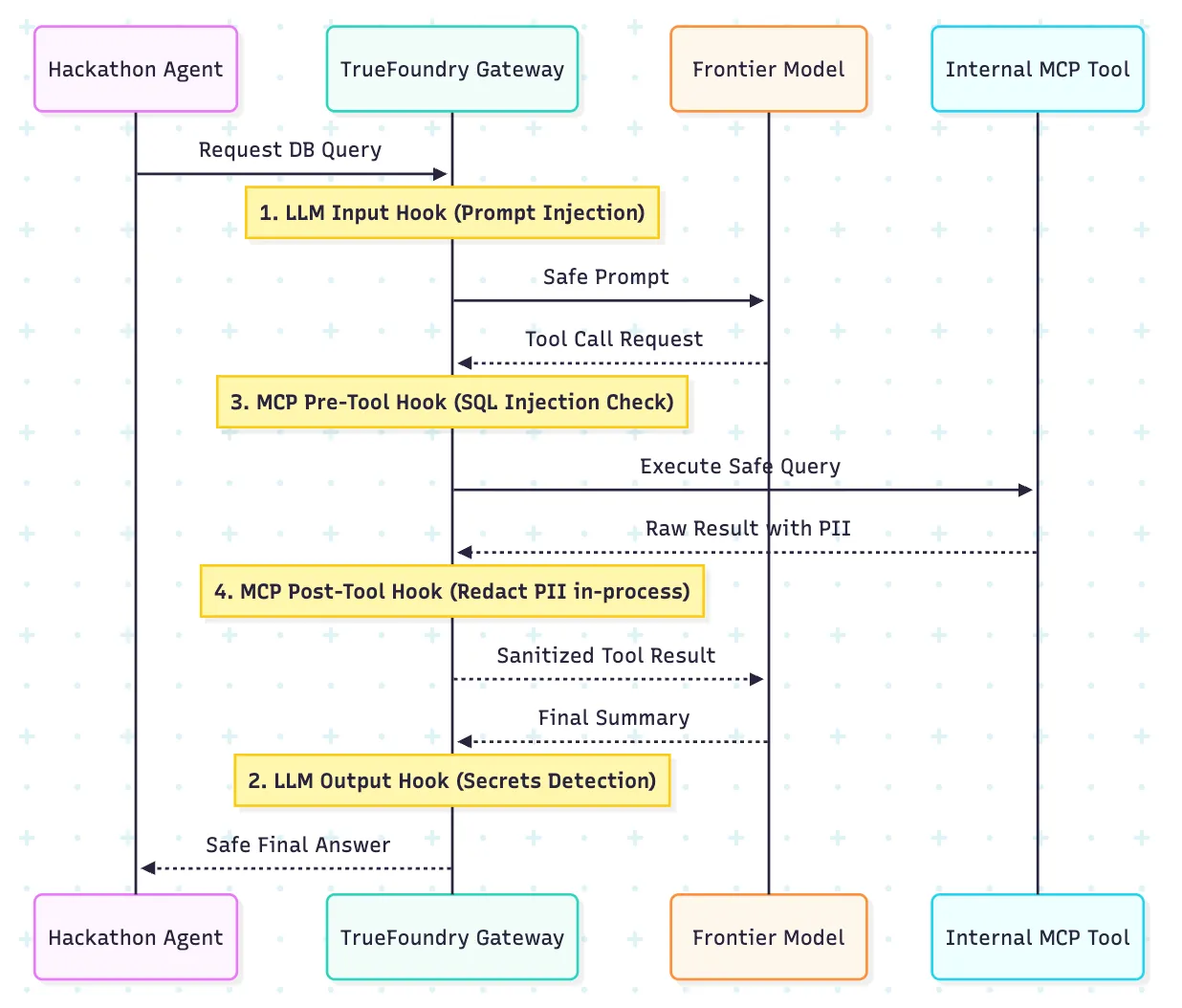
Hier kommt es auch auf die prozessinterne Erkennung an. Wenn geheime Scans und zugehörige Prüfungen innerhalb des Gateway-Pfads ausgeführt werden können, ohne dass eine zusätzliche Abhängigkeit von ausgehenden Daten besteht, ist es einfacher, während einer Live-Veranstaltung über das Kontrollmodell nachzudenken. Sorgen Sie dafür, dass die grundlegenden Leitplanken für alle Teams gleich sind, und legen Sie dann strengere Richtlinien für Teams fest, die vertrauliche Tools oder Datensätze verwenden.
Ein sicherer Hackathon muss sich trotzdem schnell anfühlen. Wenn Teams jedes Mal, wenn sie einen Prompt ausprobieren wollen, ein Ticket benötigen, werden sie über die Plattform weitergeleitet. Die Antwort lautet nicht weniger Kontrolle. Die Antwort lautet, den kontrollierten Pfad zum einfachsten Weg zu machen.
Hier kommt es auf den Gateway-Native-Spielplatz an. Der nützliche architektonische Vorteil besteht darin, dass der Testdatenverkehr dieselbe Gateway-Ebene passieren kann, die für Produktionsrichtlinien verwendet wird. So können Teams Eingabeaufforderungen, Routing und Leitplanken im Loop überprüfen, anstatt das Verhalten der Richtlinien erst nach der Bereitstellung zu erkennen.
Das Entwicklererlebnis wird auch besser, wenn die Plattform Debugging-Signale auf Antwortebene verfügbar macht. Header wie x-tfy-resolved-model und x-tfy-applied-configurations sowie Server-Timing-Aufschlüsselungen helfen Teams zu verstehen, was bei einer Testanfrage tatsächlich passiert ist, anstatt zu erraten, ob ein Fallback, eine Leitplanke oder eine Routing-Regel ausgelöst wurde.
Leser aus Unternehmen werden sofort zurücktreten, wenn ein Beitrag zu viel verspricht, was die Datenspeicherung angeht. Das sollten sie. Die nützliche Behauptung ist nicht, dass jeder Einsatz auf magische Weise „durch Luftspalten“ erfolgt. Das Split-Plane-Design ermöglicht es den Teams, die Gateway-Ebene auf ihrer eigenen Infrastruktur zu betreiben und gleichzeitig den Hot-Pfad für Inferenzen, Policy-Checks und Modellzugriff unter strengerer operativer Kontrolle zu halten.
Die andere Hälfte der Geschichte ist Beobachtbarkeit. Ein Hackathon ist einfacher zu organisieren, wenn das Plattformteam die Spuren, die Latenz und das Verhalten der Richtlinien schnell erkennen kann. Observability ist aber auch eine Oberfläche zur Datenverwaltung. Wenn Prompt- oder Response-Daten für Analysen exportiert werden, muss dies eine bewusste Entscheidung mit den richtigen Aufbewahrungs- und Zielkontrollen sein.
Die Geschichte der Residency wird noch stärker, wenn Sie den Bereitstellungsmodus, das Protokollierungsverhalten und die Exportpfade explizit beschreiben. Das schafft mehr Vertrauen, als wenn man sagt, dass es kein Durchsickern gibt und man hofft, dass der Leser keine weiteren Fragen stellt.
Ja — es ist eine gute Idee, einen expliziten Eigentümer-Workflow hinzuzufügen. Es macht aus dem Beitrag aus einem Architekturkommentar eine Anleitung zur Ausführung.
1. Eine Woche vor der Veranstaltung: Definieren Sie das Kontrollmodell
Erstelle einen Workspace pro Team oder pro Wettkampfstrecke. Lege fest, welche Models erlaubt sind, welche Anbieter standardmäßig verwendet werden, wie hoch das Budget pro Team ist, wie hoch das Preislimit pro Team ist und welche Teams MCP-Tools oder sensible interne Daten verwenden dürfen.
2. Vor dem Anpfiff: Laden Sie den sicheren Pfad vorab herunter
Veröffentlichen Sie ein kleines Starterkit für die Teilnehmer: den Gateway-Endpunkt, das erforderliche Metadaten-Shape, Beispiel-SDK-Snippets und eine kurze Anleitung zum Spielplatz. Teams sollten von dem vorgegebenen Pfad ausgehen, nicht von unformatierten Anbieter-Dashboards.
3. Bei der Registrierung: Weisen Sie jedem Team eine project_id zu
Machen Sie project_id vom ersten Tag an zum erforderlichen Metadatenfeld. Dadurch erhalten Sie eine saubere Ausgabensegmentierung, eine klarere Rückverfolgung, eine klarere Überprüfung von Vorfällen und weniger spätere manuelle Kartografie.
4. Während der Bauzeit: Überwachen Sie das Ereignis wie ein Live-System
Beobachten Sie die Ausgaben auf Teamebene, den Druck bei der Ratenbegrenzung und ungewöhnliche Ablaufmuster. Ziel ist es, Teams frühzeitig zu retten und nicht nur Ausfälle später zu analysieren.
5. Für Agententeams: Vor dem allgemeinen Zugriff müssen die Tools überprüft werden
Wenn ein Team Datenbankzugriff, MCP-Server oder interne APIs wünscht, verschieben Sie es auf ein strengeres Leitplankenprofil, bevor Sie diese Tools aktivieren. Experimente mit Agenten sollten in mehr Vertrauen münden und nicht dort beginnen.
6. Vor den Demos: Erzwingen Sie einen letzten Playground-Pass
Lass jedes Team seinen finalen Spielfluss auf dem Spielplatz oder auf der offiziellen Testoberfläche überprüfen. Dadurch werden fehlende Metadaten, unerwartetes Routing und Überraschungen vor Beginn der Demo erkannt.
7. Nach der Veranstaltung: Machen Sie Beobachtungen zu Standardwerten der Plattform
Prüfen Sie die Spuren, Budgetprobleme, blockierten Anrufe und Support-Fragen. Wandeln Sie dann die Best Practices in standardmäßige Workspace-Vorlagen, Codefragmente und Richtlinien-Grundzüge für den nächsten Hackathon um.
Die Kernthese des ursprünglichen Beitrags funktioniert immer noch: Wenn Sie einen KI-Hackathon für Unternehmen durchführen, ist es am sichersten, keine rohen Anbieterschlüssel zu verteilen. Es leitet Anfragen über ein Gateway weiter, das Teams trennen, Ausgaben messen, den Durchsatz kontrollieren und die Arbeitsabläufe der Agenten steuern kann.
Was die überarbeitete Version besser macht, ist, dass sie dies auf eine Weise sagt, die ein skeptischer Käufer glauben kann. TrueFoundrys stärkste Hackathon-Geschichte ist kein vages Versprechen absoluter Sicherheit. Es handelt sich um eine praktische Kombination aus Workspace-Isolierung, geheimer Indirektion, metadatenspezifischen Richtlinien, gesteuerten Agenten-Hooks, Kontrollen des Anforderungspfads und einer Spielwiese, auf der Teams dieselbe Policy-Oberfläche testen können, durch die sie versenden werden.
Das ist genug. Ihre Hacker können immer noch die Zukunft gestalten. Ihre Plattform-, Sicherheits- und Finanzteams müssen dabei einfach kein Wochenende verlieren.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


