

October 5, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: June 23, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Jupyter-Notebooks sind ein leistungsstarkes und beliebtes Tool, das eine interaktive Computerumgebung bietet und Code, Datenvisualisierung und erklärenden Text kombiniert, um die Arbeit mit Daten und den Austausch von Erkenntnissen zu erleichtern. Datenwissenschaftler verwenden Jupyter-Notebooks für verschiedene Aufgaben während des gesamten Lebenszyklus der Datenanalyse und des maschinellen Lernens, wie z. B. explorative Datenanalyse (EDA), Datenvorverarbeitung, Visualisierung, Modellentwicklung, Bewertung und Validierung usw. Für viele dieser Anwendungsfälle gilt Installation von Jupyter Notebook auf Ihrem Laptop reicht aus, um loszulegen. Für viele Unternehmen und Organisationen ist dies jedoch keine Option, und wir benötigen gehostete Jupyter-Notebooks.
Hier sind die Optionen, die ein Unternehmen heute haben kann, um seinen Ingenieuren Zugriff auf Jupyter Notebook zu gewähren:
DS/MLES können die Umgebung einrichten und einen Jupyter-Server auf einer VM ausführen, die für die Ausführung der Workloads verwendet werden kann. Hier ist eine einfache Anleitung, wie Sie führen Sie jupyterlab auf einer ec2-Instanz aus.
👍 Vorteile:
- Ermöglicht die volle Kontrolle über die Maschine in der Hand eines DS
- Die gesamte Umgebung ist persistent. Die VM kann im gleichen Zustand gestoppt und neu gestartet werden.
👎 Nachteile:
- Hohe Cloud-Computing-Kosten - Es wird keine automatische Stop-Funktion geben. DS kann eine virtuelle Maschine starten und diese für einen Großteil der Zeit ungenutzt lassen, wodurch sich die Kosten erhöhen.
- Es ist schwierig, eine große Anzahl von VMs zentral zu verwalten und zu verfolgen.
- DS muss eine Menge Dinge einrichten, um die Werkbank für den Beginn der Experimente einzurichten.
- Schwierigkeiten bei der Reproduzierbarkeit - DS hat möglicherweise eine Reihe von Paketen installiert, die nicht mehr verfolgt werden, und es nimmt viel Zeit in Anspruch, den Code, der auf dieser VM läuft, in Produktion zu bringen.
Eine andere Option kann die Verwendung einer verwalteten Lösung wie AWS Sagemaker, Vertex AI Notebooks oder Azure ML Notebooks sein. Jede dieser Methoden hat zwar Vorteile, hier sind jedoch einige Vor- und Nachteile dieser Methoden im Allgemeinen aufgeführt.
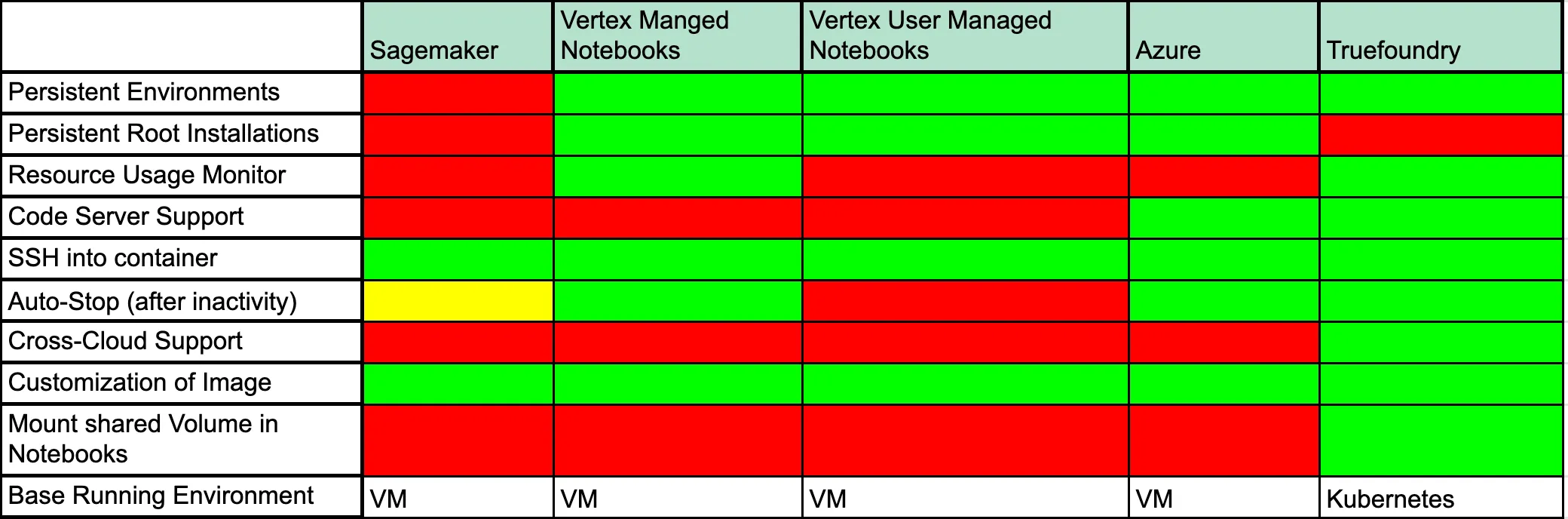
Lassen Sie uns besprechen, was jedes dieser Felder bedeutet:
Eine weitere Option kann das Hosten von Notebooks über Kubernetes sein, aber das bringt seine eigenen Herausforderungen mit sich, da Datenwissenschaftler nicht direkt mit Kubernetes interagieren können und dazwischen Software benötigen, die eine einfache Oberfläche zum Starten von Jupyter-Notebooks bietet. Schauen wir uns an, welche Optionen dabei zur Verfügung stehen:
Kubeflow Notebook-Betreiber:
Kubeflow hilft dabei, die Bereitstellung von Workflows für maschinelles Lernen (ML) auf Kubernetes einfach, portabel und skalierbar zu machen. Es hat eine Notebook Funktion, mit der Notebooks einfach verwaltet und ausgeführt werden können.
Kubeflow ist zwar ein großes Open-Source-Projekt, das viele Funktionen für Anwendungsfälle des maschinellen Lernens bietet, aber es ist sehr schwierig, Kubeflow selbst zu installieren und zu verwalten.
👍 Vorteile:
- Einfach zu startende und zu verwaltende Notebooks für DS
- Persistentes Home-Verzeichnis, das von einer Festplatte unterstützt wird
- Option für vordefinierte Images für sklearn, pytorch und tensorflow, die alle installierten Abhängigkeiten enthält.
- Open-Source-Codebasis
- Holen Sie sich eine Funktion zum Ausblenden, die Notizbücher nach einiger Zeit der Inaktivität stoppt.
👎 Nachteile:
- Es ist schwierig, Kubeflow einzurichten auf Kubernetes. Die Installation und Wartung von Kubeflow nimmt viel Zeit in Anspruch
- Für die Bereitstellung von Notebooks in mehreren Regionen müssen verschiedene Kubernetes-Cluster erstellt werden und Kubeflow muss auf jedem einzelnen Cluster installiert werden - was zu hohen Infrastruktur- und Wartungskosten führt.
- Python-Pakete sind standardmäßig nicht persistent, was bedeutet, dass Sie bei jedem Neustart Pakete installieren müssen
- Keine direkte Möglichkeit, Root-Zugriff zu erhalten zum Container [kann für mehrere Anwendungsfälle nützlich sein]
- Das Stoppen von Notebooks kann nicht auf Notebook-Ebene konfiguriert werden und ist ein globales Umfeld.
Hosten Sie JupyterHub auf Kubernetes:
JupyterHub ist ein großartiges Setup für Mehrbenutzer-Anwendungsfälle, das bei der optimalen Nutzung von Ressourcen hilft. Die Bereitstellung von JupyterHub auf Kubernetes kann mit einem Open-Source-Projekt namens erfolgen Zero zu JupyterHub mit Kubernetes:
👍 Vorteile:
- Dank der Authentifizierungsunterstützung können mehrere Benutzer problemlos zusammenarbeiten
- Einfache Einrichtung des Auto-Stop für Notebooks
- Einfache Verwaltung von Umgebungen
👎 Nachteile:
- Schwer einzurichten und zu verwalten. Wir müssen Networking, persistente Volumes, Skalierung und Load Balancing konfigurieren, damit JupyterHub ordnungsgemäß funktioniert.
- Es ist schwierig, GPU-Workloads auf verschiedenen GPU-Typen auf Jupyterhub auszuführen. Lesen Sie zum Beispiel diese.
- Umgebungen sind nicht persistent
Derzeit sind zwar viele Lösungen verfügbar, aber jede Lösung hat ihre eigenen Einschränkungen. Bei Truefoundry haben wir versucht, diese Lücke zu schließen und eine Notebook-Lösung zu entwickeln, die alle Anforderungen eines DS erfüllt und auch die Kosten unter Kontrolle hält. Im nächsten Abschnitt werden wir unseren Ansatz zur Entwicklung der Notebook-Lösung und die Herausforderungen beschreiben, mit denen wir bei der Herstellung derselben konfrontiert waren.
Echte Gießerei ist eine Entwicklerplattform für ML-Teams, die bei der Bereitstellung von Models, Services, Jobs und jetzt auch Notebooks auf Kubernetes hilft. Sie können mehr darüber lesen, was wir tun hier. Unsere Motivation für die Entwicklung einer Notebook-Lösung bestand darin, das Experimentieren und Entwickeln auf unserer Plattform zu ermöglichen. Nachdem wir alle verfügbaren Lösungen untersucht hatten, beschlossen wir, die Schwachstellen und fehlenden Funktionen auf den anderen Plattformen zu lösen, damit Datenwissenschaftler die beste Erfahrung machen können, ohne dass ihnen hohe Kosten entstehen. Ein paar Dinge, die wir ermöglichen wollten, sind:
Kubeflow unterstützt das Ausführen von Notebooks auf Kubernetes. Es bietet eine Reihe von Funktionen für Notebooks, die sofort einsatzbereit sind. Wir wollten jedoch die oben genannten Probleme in Kubeflow Notebooks angehen und Datenwissenschaftlern und Entwicklern ein nahtloses Erlebnis bieten.
Also mussten wir Änderungen am Notebook-Controller vornehmen, ihn in das Backend von Truefoundry integrieren und die Notebooks auf unserer Benutzeroberfläche anzeigen.
Wir haben den Notebook-Controller installiert, sind aber auf einige Probleme gestoßen, weshalb wir Änderungen am Kubeflow-Notebook-Controller vornehmen mussten:
Wir haben die beiden oben genannten Probleme gelöst und die gestartet tfy-Notebookcontroller
und veröffentlichte es als Helmchart Truefoundry's Public Charts Repository. Sie können das Diagramm finden hier.
Wir haben eine leicht verständliche Benutzeroberfläche für Datenwissenschaftler zum Starten von Notebooks erstellt. Der Benutzer kann das Leerlauf-Timeout (Zeit der Inaktivität, nach der das Notebook gestoppt wird), die Größe des persistenten Volumes (Größe der Festplatte, auf der der Datensatz und die Codedateien gespeichert sind), die Ressourcen (CPU-, Speicher- und GPU-Anforderungen) anpassen und das Notebook hochfahren!
Mit all diesen Änderungen starteten wir die v0 unserer Notizbücher.
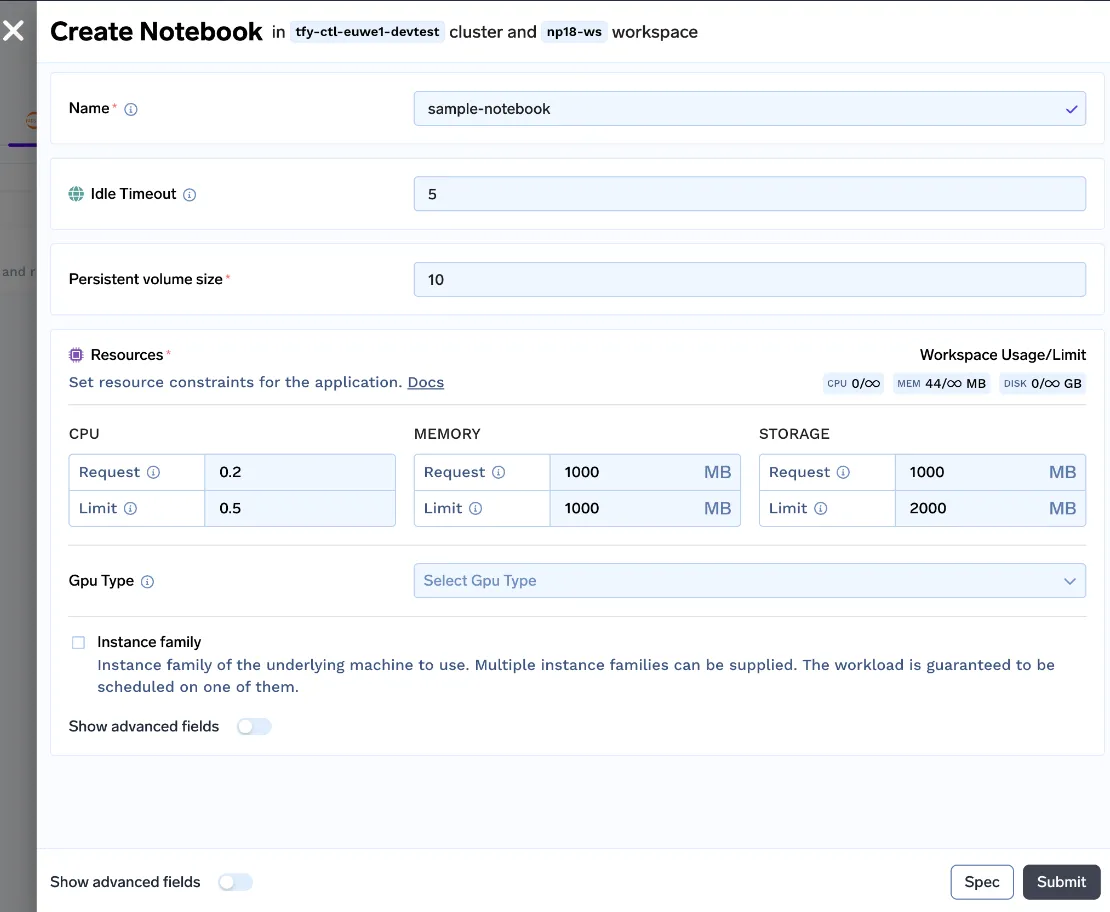
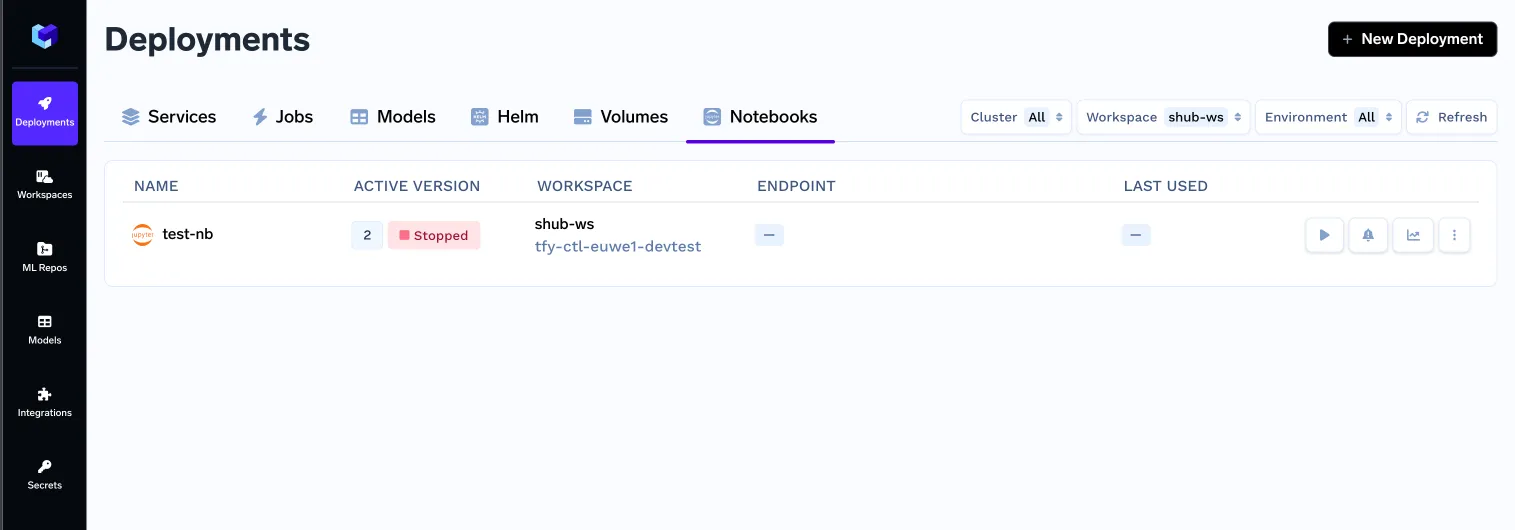
Dennoch sind wir weit von einer guten Benutzererfahrung entfernt. Lassen Sie uns die Vor- und Nachteile dieses Ansatzes erkennen:
👍 Vorteile:
- Persistentes Home-Verzeichnis [alle Dateien und Pakete werden persistiert]
- Inaktivitäts-Timeout (Cull Timeout) pro Notebook kann konfiguriert werden
- Starten Sie das Notebook mit wenigen Klicks
- Einfaches Starten eines Notebooks mit GPUs
👎 Einschränkungen:
- Die Python-Umgebung ist nicht persistent (alle installierten Pakete verschwinden beim Pod-Neustart)
- Keine Möglichkeit, Pakete zu installieren, die Root-Zugriff benötigen
- Keine richtige Methode, um mehrere Umgebungen für Experimente zu verwalten
- Es kann kein Endpunkt für das Notebook konfiguriert werden [in der nächsten Version hinzugefügt]
Jetzt gilt es, diese Einschränkungen zu lösen, da sie viele Data Scientist-Workflows blockieren, die so einfach sein können wie die Installation von 'Apt-Paketen' wie ffmpeg.
Bis zu diesem Zeitpunkt nutzten wir die vorgefertigte Bilder für Jupyterlab bereitgestellt von Kubeflow. Aber da wir das Problem der nicht persistenten Umgebungen lösen müssen, müssen wir Root-Zugriff zulassen und Apt-Pakete installieren. Wir brauchen unsere eigenen Docker-Images.
Schauen wir uns also an, wie wir diese Probleme gelöst haben!
- Das Init-Skript des Docker-Images wurde geändert und die Basis-Conda-Umgebung in das Home-Verzeichnis geklont und benannt Jupiter-Basis
- Füge eine.condarc-Datei hinzu und setze $HOME Verzeichnis als Standardumgebungspfad
- Ändern Sie die .bashrc-Datei, um die zu aktivieren Jupiter-Basis Umgebung standardmäßig
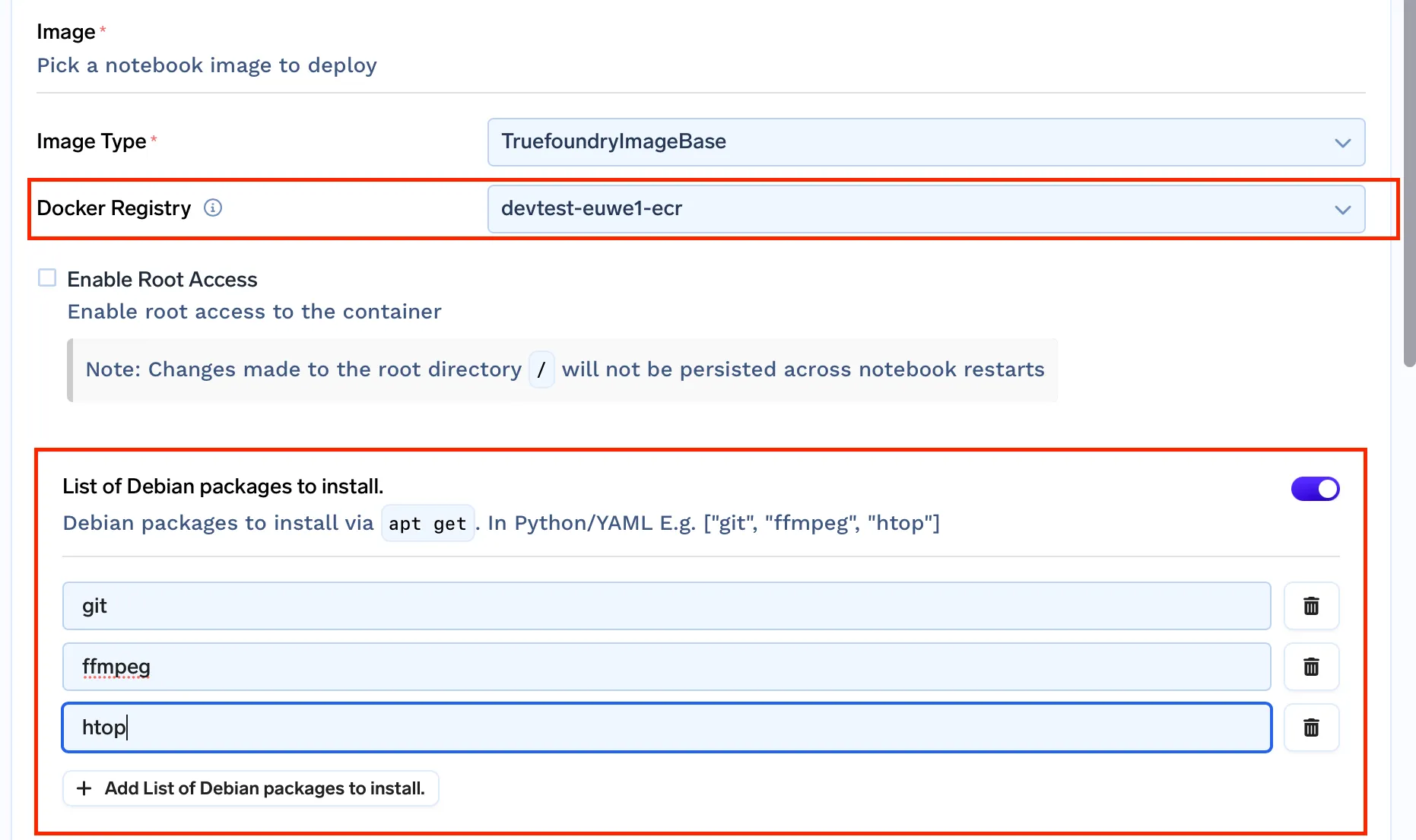
truefoundrycloud/jupyter: aktuell und truefoundrycloud/jupyter: latest-sudo. Wobei die Bilder mit Sudo dem Benutzer Sudo-Zugriff ohne Passwort gewähren.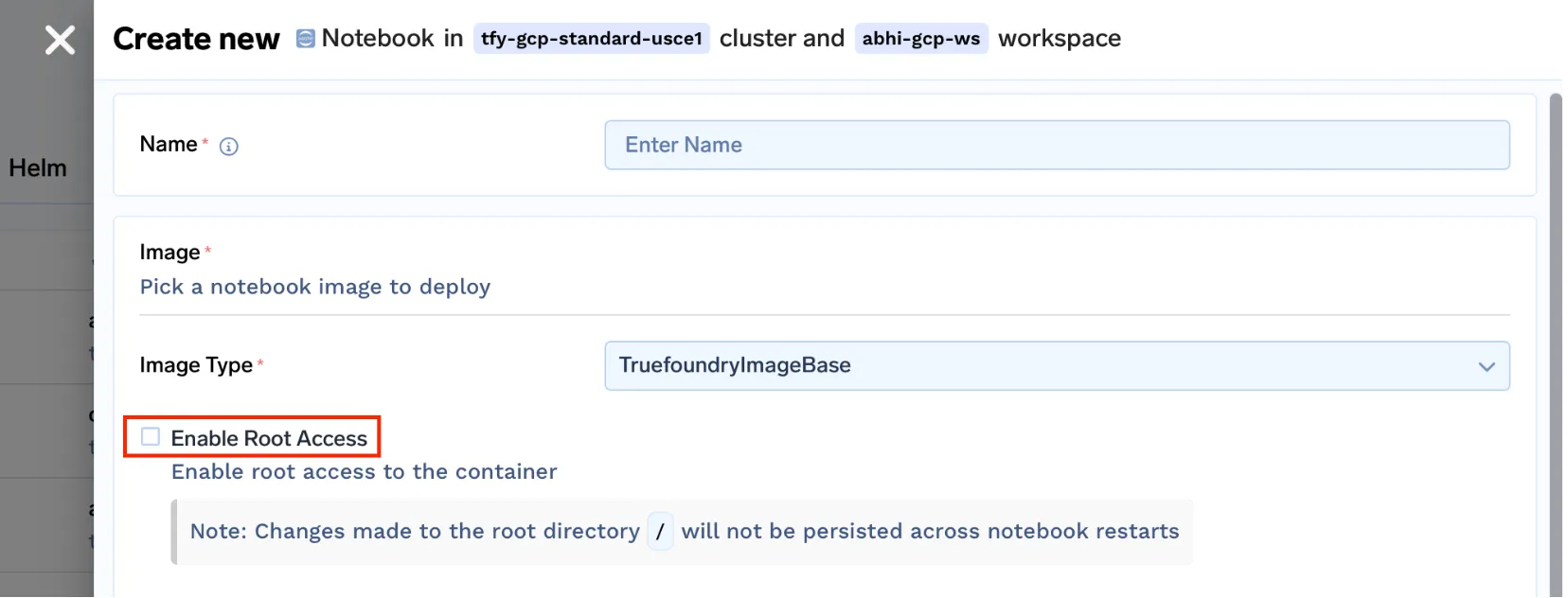
Hinweis: Da wir Notebooks auf Kubernetes mit gemountetem Home-Verzeichnis ausführen, ist nur das Home-Verzeichnis persistent. Die Installationen der Root-Pakete bleiben bei Pod-Neustarts nicht persistent. Bitte lesen Sie diese um dasselbe besser zu verstehen.
Durch die Lösung dieser Probleme haben wir die meisten Probleme gelöst, mit denen ein Benutzer konfrontiert war, und bieten ein anständiges Notebook-Erlebnis. Mit der Zeit stellten wir jedoch fest, dass die Benutzer vor einigen Herausforderungen standen, die wir im nächsten Abschnitt beschreiben werden.
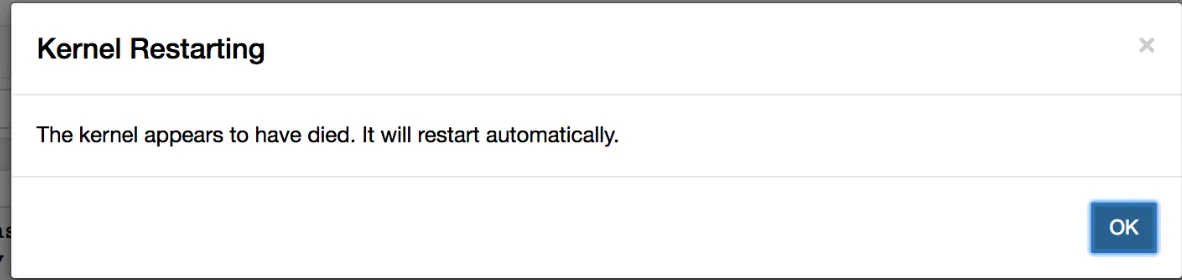
Jupiter Lab das Paket. Da die Umgebung persistent ist, kann das Notebook nicht gestartet werden (sobald das aktuelle Notebook gestoppt wird)Kernelspezifikation und stellen Sie sicher, dass Kernelspezifikation ist korrekt konfiguriert, was zu Problemen führen kann.
Hinzufügen von Metriken zur Ressourcennutzung zum Notizbuch:
Wir haben die Metriken zur Ressourcennutzung zum Notizbuch hinzugefügt, indem wir die Erweiterung installiert haben Jupyterlab-Systemmonitor==0.8.0 und konfigurierte seine Einstellungen im Init-Skript, indem beim Starten des Jupyterlab-Servers Argumente übergeben wurden.
...
Jupyter-Labor\
...
--resourceUseDisplay.MEM_LIMIT=$ {mem_limit}\
--resourceUseDisplay.cpu_limit=$ {cpu_limit}\
--resourceUseDisplay.TRACK_CPU_PERCENT=Wahr\
--resourceUseDisplay.MEM_WARNING_THRESHOLD=0.8
So sieht es auf der Benutzeroberfläche aus:
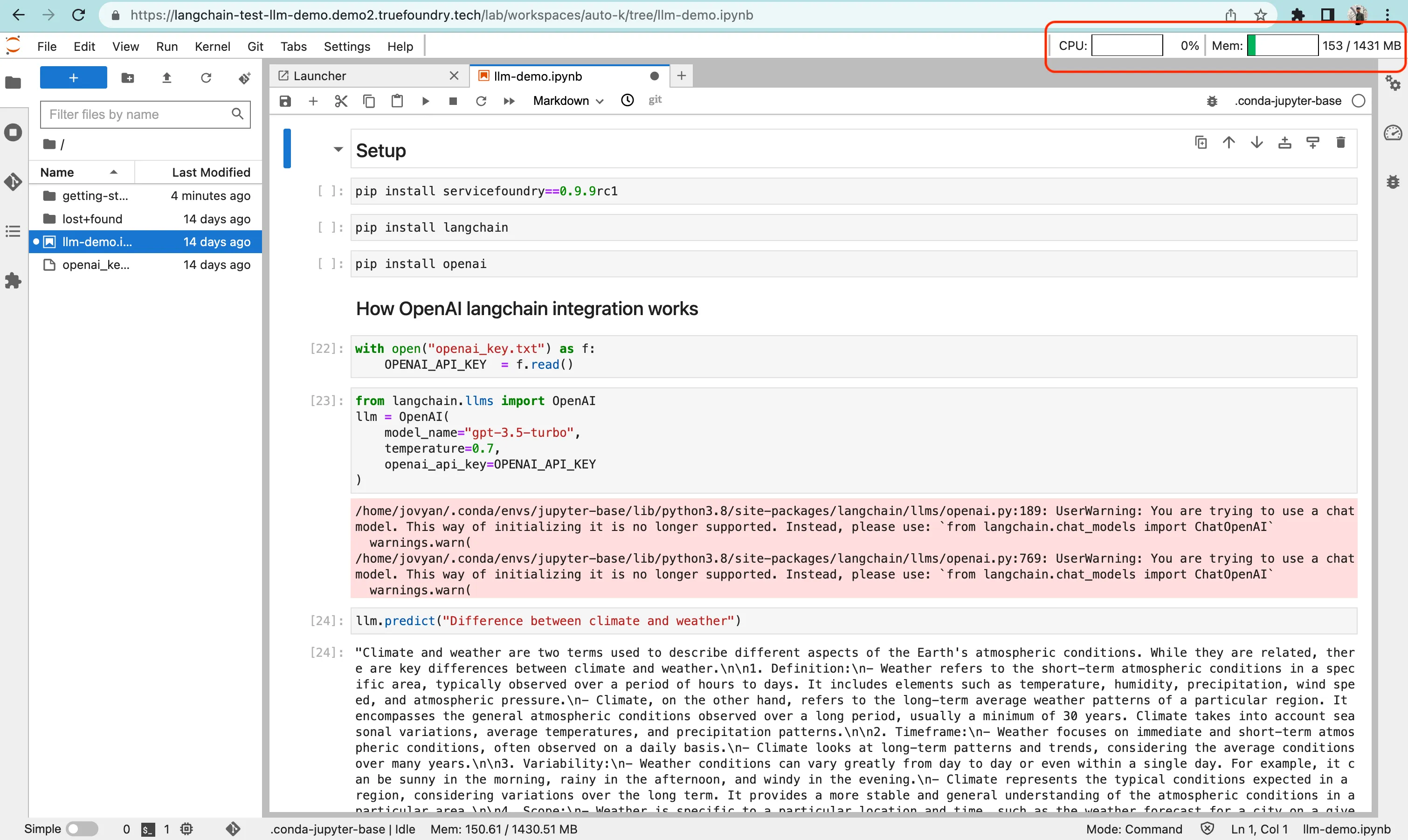
Den Kernel, auf dem der Jupyterlab-Server ausgeführt wird, vom Ausführungskernel trennen
Wir müssen sicherstellen, dass das Notebook unabhängig von den Änderungen, die der Benutzer im Home-Verzeichnis vornimmt, immer ohne Probleme neu gestartet wird. Dafür haben wir die Anaconda-Basisumgebung von verwendet /opt/conda das Verzeichnis, um den Jupyterlab-Server zu starten.
Gleichzeitig haben wir eine separate Umgebung in der $HOME Verzeichnis, aber das fügt einen Kernel von Basis Conda-Umgebung für Kernel-Listen.
Um das zu lösen, haben wir installiert nb_conda_kernels um Jupyter-Kernel zu verwalten. Wir haben das Init-Skript konfiguriert, um sicherzustellen, dass nur die persistenten Python-Umgebungen in der Kernel-Liste angezeigt werden.
Jupyter-Labor\
...
--condakernelspecmanager.conda_only=Wahr\
--condakernelSpecManager.name_format= {Umgebung}\
--condakernelspecmanager.env_filter=/opt/conda/*“
Dadurch erhalten wir die Garantie, dass der Notebook-Server immer mit den Änderungen beginnt, die ein Benutzer am Notebook vornimmt.
Es erleichtert auch die Verwaltung mehrerer Kernel. Sie müssen lediglich mit dem Befehl eine neue Conda-Umgebung erstellen conda create -n myenv und es beginnt in der Kernel-Liste aufzutauchen.
Jupyter-Notebooks lösen zwar eine Reihe von Problemen. Es gibt eine Reihe von Aufgaben, bei denen es nicht mehr hilft:
In Anbetracht dieser Einschränkungen haben wir uns entschlossen, dasselbe zu lösen. Wir haben Code-Server-Unterstützung hinzugefügt, um den Benutzern im Browser ein vollständiges IDE-Erlebnis zu bieten.
Durch das Hinzufügen von VS Code-Unterstützung ermöglichen wir Benutzern, die folgenden Dinge zu tun:
lokaler Host: 8000 kann zur Verfügung gestellt werden unter $ {NOTEBOOK_URL} /proxy/8000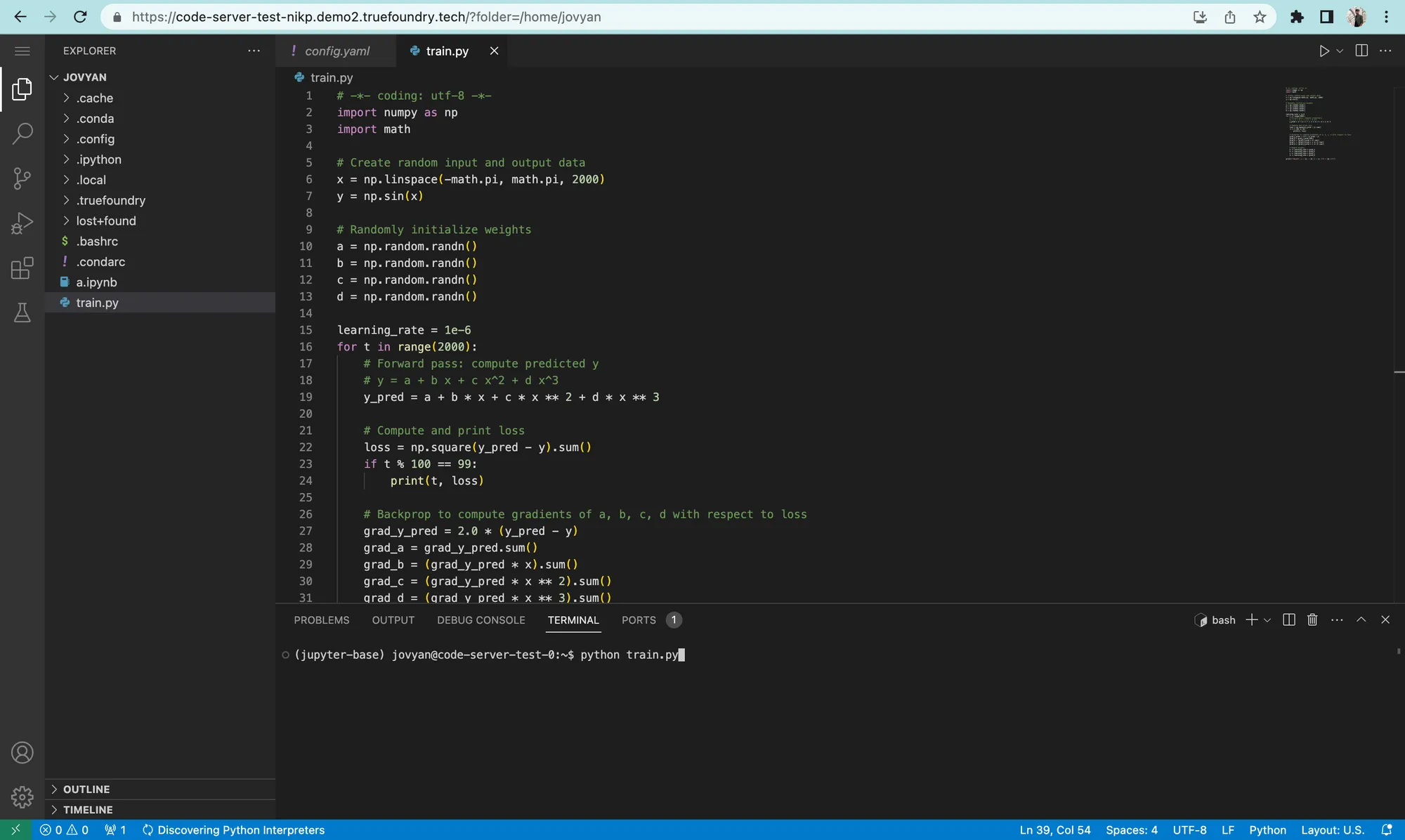
Dies wurde durch Hinzufügen eines weiteren Docker-Images erreicht. Hier ist ein Diagramm, das die Docker-Images von Truefoundry zeigt.
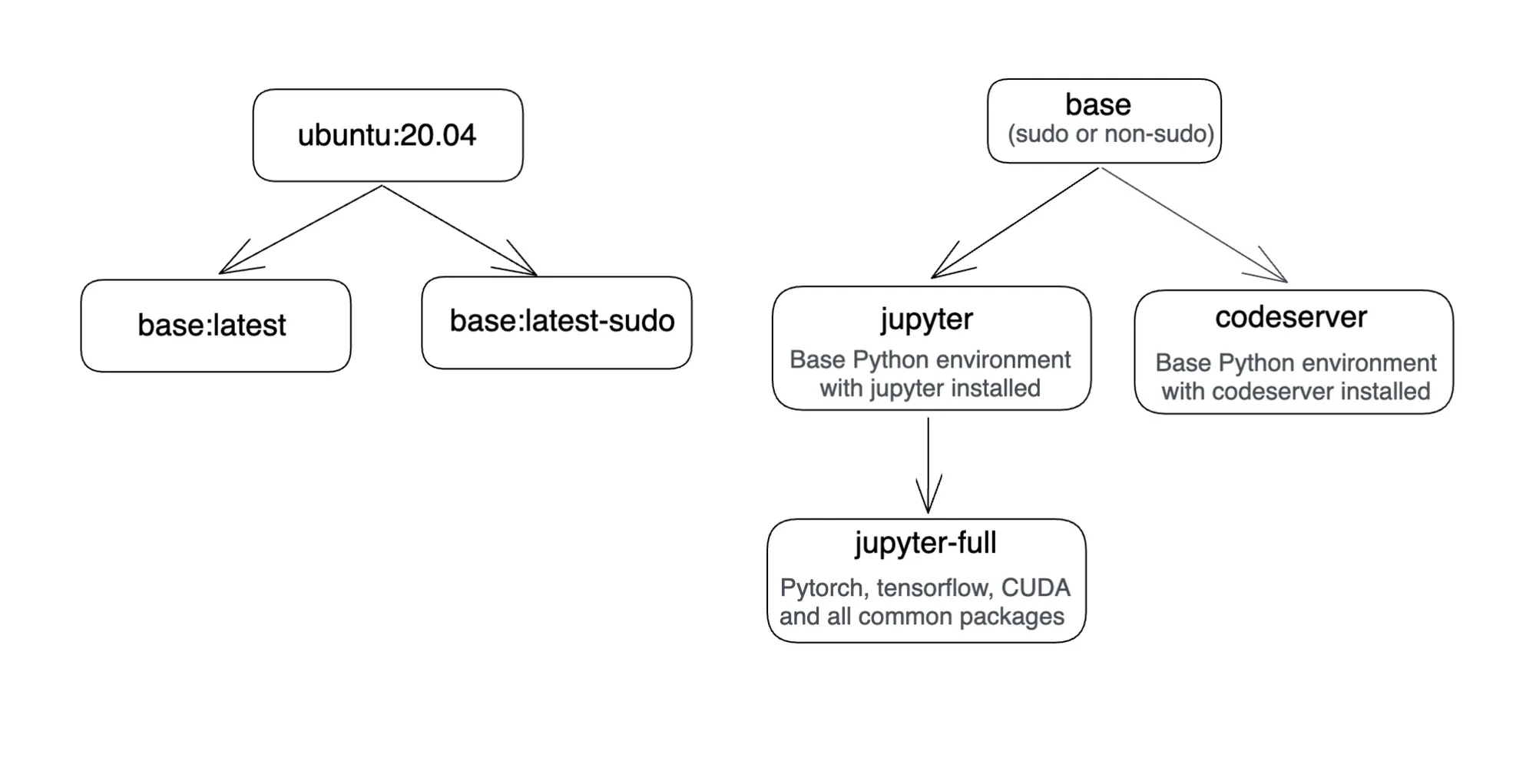
SSH-Zugriff auf dein Notebook/VSCode:
In den meisten Fällen kann Hosted VS Code das Problem lösen. Es kann jedoch Fälle geben (insbesondere bei Jupyter Notebooks), in denen der Benutzer nicht weiterkommt und direkten Zugriff auf den Container benötigt, auf dem sein Jupyter Notebook/ VS Code Server ausgeführt wird.
Wir haben das vereinfacht, indem wir in jedem der Notebooks einen SSH-Server installiert haben. Um eine Verbindung zu Ihrem Container herzustellen, müssen Sie einen einfachen Befehl ausführen und Ihr Passwort eingeben:
ssh -p 2222 jovyan@test-notebook.ctl.truefoundry.tech

Die Leistungsfähigkeit dieses Tools kann mit Ihrer VS Code Extender erweitert werden Entfernter Explorer wo Sie alle Dateien in Ihrem VS Code direkt öffnen können!
Klicken Sie hier um mehr darüber zu lesen
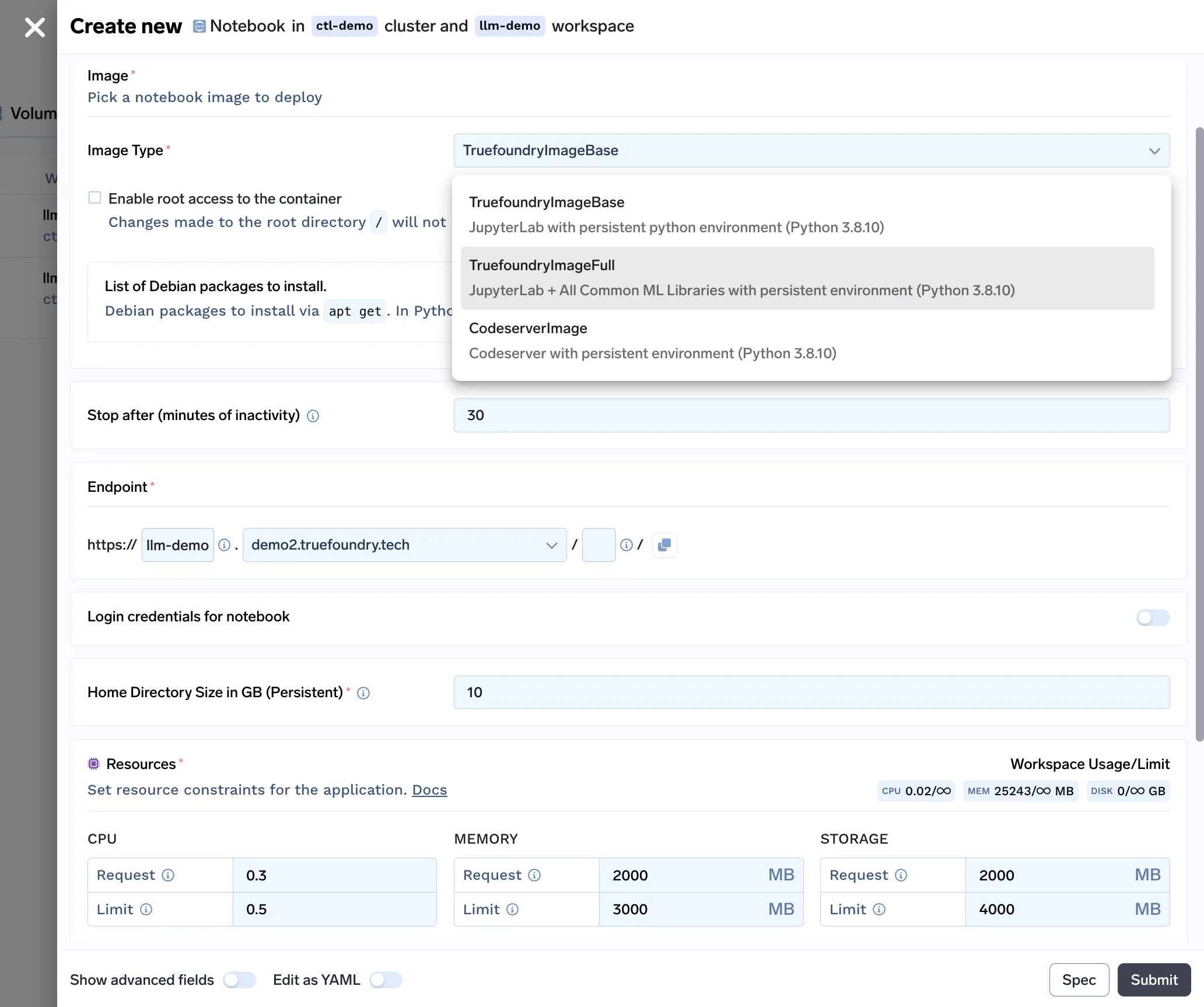
Mit all den Funktionen, die in unserer Notebook-Lösung enthalten sind, sieht unser Bereitstellungsformular für Notebooks wie folgt aus:
Lassen Sie uns abschließend die Preise der einzelnen verwalteten Lösungen mit Truefoundry vergleichen.
Da Truefoundry die Bereitstellung in der Cloud des Kunden durchführt, indem dessen Kubernetes-Cluster verbunden wird, finden Sie hier die Preise für Truefoundry, das auf verschiedenen Cloud-Anbietern läuft.
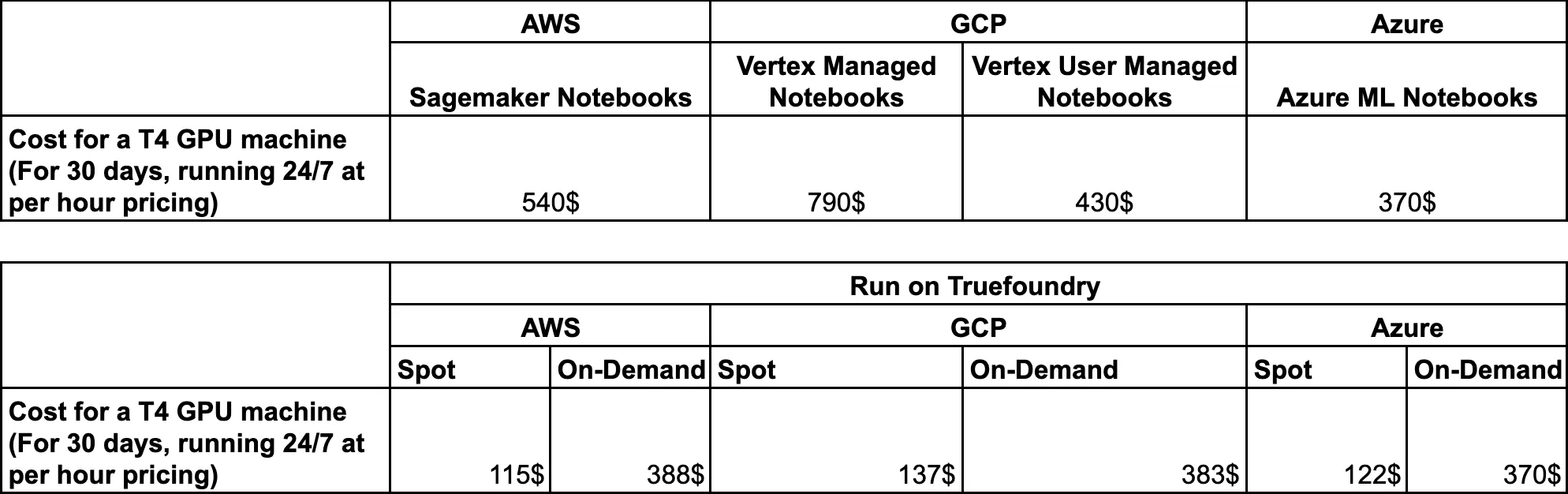
Im Fall von Truefoundry können Sie tatsächlich eine Menge Kosten sparen, da:
Dies war ein kurzer Überblick über unsere Bemühungen beim Aufbau der Notebook-Lösung. Sie können sich unseren anschließen Freunde von Truefoundry Slack-Channel, wenn du ausführlich über unseren Ansatz diskutieren möchtest oder Vorschläge hast.
Wenn Sie unsere Plattform ausprobieren möchten, können Sie sich registrieren hier!
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.









.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




