Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.
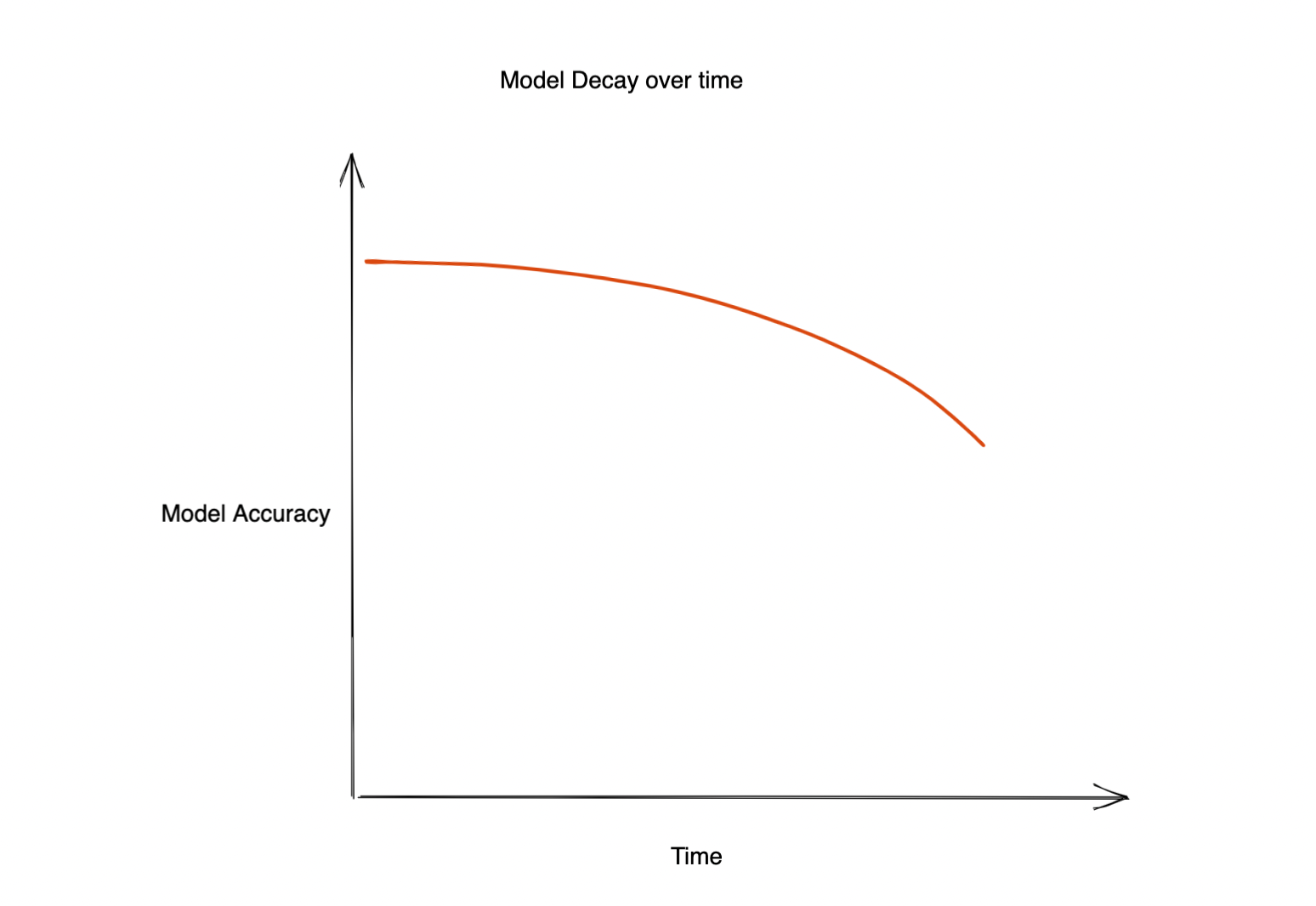
Maschinelles Lernen hat erhebliche Auswirkungen auf fast alle Aspekte des Unternehmens. Oft lässt die Genauigkeit des eingesetzten Modells jedoch nach, was zu einer schlechten Kundenerfahrung führt und sich negativ auf das Geschäft auswirkt. Die Frage ist also, warum sinkt die Genauigkeit dieses Modells? Dies kann mehrere Gründe haben. Zum Beispiel:
Ein Spam-Erkennungsmodell kann Spam-E-Mails nach einiger Zeit nicht mehr richtig erkennen, da „Spammer“ die Wörter und ihre E-Mail-Muster aktualisieren, die dem Modell „unbekannt“ sind.
Ein Empfehlungsmodell für Einkäufe kann durch wichtige Weltereignisse wie den Ausbruch von COVID-19, der die Kundenpräferenzen verändert, erheblich beeinträchtigt werden.
Ein Modell zur Vorhersage der Kundenabwanderung wird im Laufe der Zeit zerfallen, da sich das Kundenverhalten und die Ausgabenmuster im Laufe der Zeit langsam ändern.
Modellzerfall im Laufe der Zeit
Wie stellen wir also sicher, dass die Leistung unseres Modells im Laufe der Zeit nicht abnimmt? Wie können wir herausfinden, wann unser Modell neu trainiert werden muss, um einen Genauigkeitsverlust zu vermeiden?
Die Antwort lautet „Drift“. Man muss „Drift“ rechtzeitig und „genau“ erkennen und entsprechende Maßnahmen ergreifen.
Was ist Model Drift?
Model Drift bezieht sich auf die Veränderung der Verteilung von Daten über einen bestimmten Zeitraum. Im Zusammenhang mit maschinellem Lernen beziehen wir uns in der Regel auf Abweichungen von Modellmerkmalen, Vorhersagen oder tatsächlichen Werten ausgehend von einem bestimmten Ausgangswert.
Für die Driftverfolgung werden mehrere Methoden verwendet, darunter die Kolmogorov-Smirnov-Statistik, die Wasserstein-Distanz und die Kullback-Leibler-Divergenz. Diese Metriken werden häufig in Online-Lernszenarien verwendet, in denen sich das Zielsystem kontinuierlich weiterentwickelt und das Modell in Echtzeit angepasst werden muss, um seine Genauigkeit aufrechtzuerhalten. Beispielsweise kann ein Empfehlungsmodell für Filme im Laufe der Zeit variieren, wenn sich das Kundenverhalten im Laufe der Zeit ändert, und ein Modell zur Vorhersage der Kundenabwanderung kann sich mit Änderungen der wirtschaftlichen Bedingungen ändern.
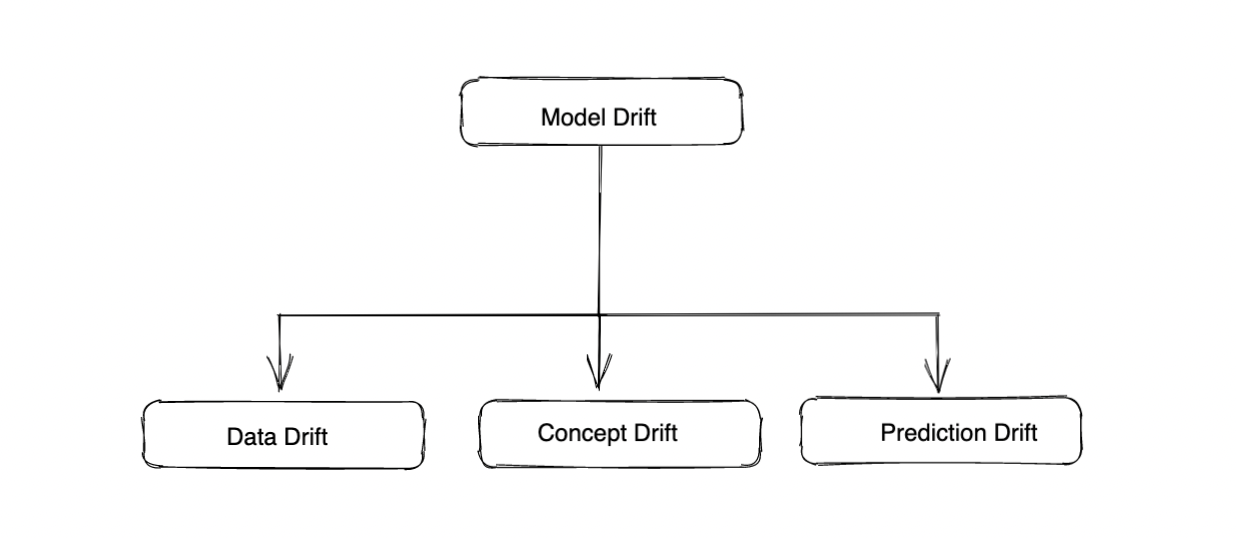
Verschiedene Arten von Modelldrift:
Datendrift: Dies bezieht sich auf die Änderung der Verteilungen verschiedener Merkmale oder auf Änderungen der Beziehungen zwischen verschiedenen Merkmalen im Laufe der Zeit. Dies kann auf Änderungen der Eingaben selbst zurückzuführen sein. Bei einem Modell beispielsweise, bei dem die Kreditwürdigkeit anhand der Daten eines Jahres trainiert wird, würde das Durchschnittseinkommen aufgrund wirtschaftlicher Veränderungen/einer Rezession schwanken.
Konzept Drift: Konzeptdrift bezieht sich auf die Abweichung der Ground-Truth-Werte des Modells. Dies deutet auf eine Änderung der Verteilung der tatsächlichen Werte hin, für die das Modell verwendet wird. Die Konzeptabweichung hängt nicht vom Modell ab, sondern nur von den Ground-Truth-Werten. Eine Abweichung der tatsächlichen Werte deutet darauf hin, dass sich die Beziehung zwischen Merkmalen und Istwerten möglicherweise ändert (im Vergleich zum Trainingsdatensatz oder zu früheren Zeitrahmen), was darauf hinweist, dass das Modell neu trainiert werden muss.
Drift bei der Vorhersage: Die Prognosedrift bezieht sich auf die Abweichung der Verteilung der vorhergesagten Werte im Vergleich zu den vorhergesagten Werten von Trainingsdaten oder Daten aus einem vergangenen Zeitraum. Eine Abweichung der Prognose deutet in der Regel auf eine Abweichung der zugrunde liegenden Daten hin, da Vorhersagen eine Funktion des Modells und der Merkmale sind und das Modell unverändert ist. Prognoseabweichungen können uns dabei helfen, Datenabweichungen und die Verringerung der Modellgenauigkeit zu erkennen.
Modell Drift
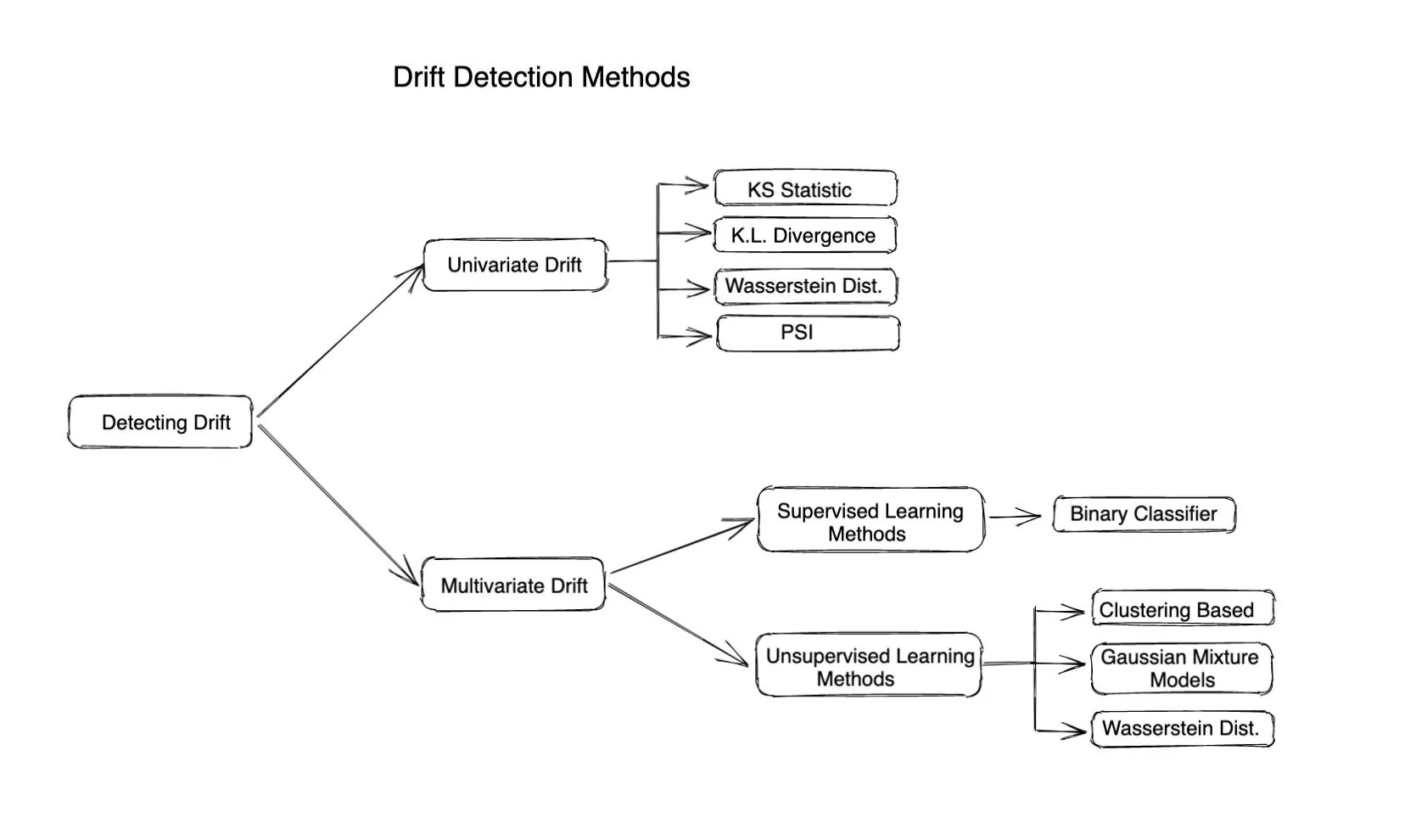
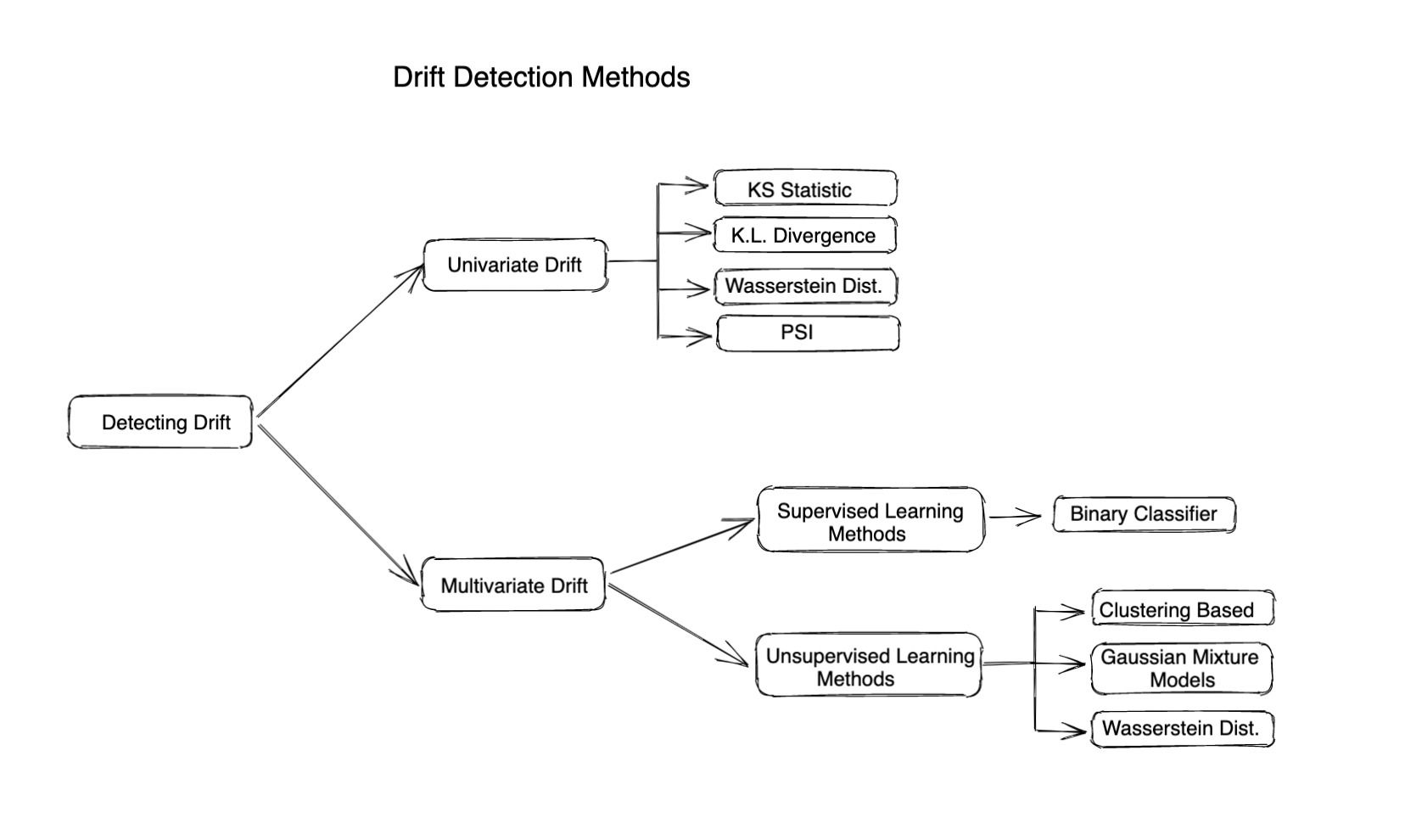
Verschiedene Methoden der Driftüberwachung
Statistische Methoden
Statistische Methoden werden verwendet, um den Unterschied zwischen der gegebenen Verteilung und der Referenzverteilung zu messen. Zur Berechnung der Abweichung eines Merkmals oder eines tatsächlichen Werts werden häufig entfernungsbasierte Metriken oder Divergenzen verwendet. Statistische Methoden eignen sich gut zur Erkennung von Ausreißern oder Verschiebungen in der Eingabeverteilung und sind sehr einfach zu berechnen und zu interpretieren. Sie berücksichtigen nicht die Änderung der Korrelation zwischen verschiedenen Merkmalen und beschreiben daher die gesamte Driftgeschichte nur, wenn die Eingabe-Features unabhängig sind.
Hier sind einige berühmte entfernungsbasierte Metriken zur Berechnung der Drift
Statistik von Kolmogorov-Smirnov: Es misst die maximale Differenz zwischen zwei kumulativen Verteilungsfunktionen. Es handelt sich um einen nichtparametrischen Test, bei dem nicht von einer bestimmten Verteilung der Daten ausgegangen wird. Aufgrund seiner Fähigkeit, Änderungen in der Datenverteilung zu erkennen, wird er häufig bei der Drifterkennung eingesetzt.
Entfernung Wasserstein: Es ist auch als Earth Mover's Distance (EMD) bekannt. Es misst den „Arbeitsaufwand“, der erforderlich ist, um eine Distribution in eine andere umzuwandeln. Es ist in der Lage, subtile Änderungen in der Verteilung der Daten zu erfassen, die mit anderen Entfernungsmetriken möglicherweise nicht erfasst werden.
Die Wasserstein-Distanz hat in letzter Zeit aufgrund ihrer Fähigkeit, hochdimensionale und verrauschte Daten zu verarbeiten, an Popularität gewonnen.
Kullback-Leibler-Divergenz: Sie ist ein Maß für den Unterschied zwischen zwei Wahrscheinlichkeitsverteilungen, auch bekannt als relative Entropie oder Informationsdivergenz. Es handelt sich um eine unsymmetrische Metrik, was bedeutet, dass die KL-Divergenz von Verteilung A zu Verteilung B nicht gleich der KL-Divergenz von Verteilung B zu Verteilung A ist.
Es ist eine der am häufigsten verwendeten Metriken für Drift-Tracking, aber die Kardinalität des Merkmals/der Vorhersage, die verfolgt werden, sollte nicht sehr hoch sein.
PSI (Bevölkerungsstabilitätsindex): PSI misst, wie stark sich eine Population im Laufe der Zeit oder zwischen zwei verschiedenen Stichproben einer Population in einer einzigen Zahl verschoben hat. Dazu werden die beiden Verteilungen in Gruppen zusammengefasst und die Prozentsätze der Elemente in den einzelnen Bereichen verglichen. Das Ergebnis ist eine einzige Zahl, anhand derer Sie verstehen können, wie unterschiedlich die Grundgesamtheiten sind. Die üblichen Interpretationen des PSI-Ergebnisses sind:
PSI < 0,1: keine signifikante Bevölkerungsveränderung
PSI < 0,2: moderater Bevölkerungswandel
PSI >= 0,2: signifikante Bevölkerungsveränderung
Man kann also Monitore für den Driftwert von Merkmalen einrichten, die sich auf die Genauigkeit des Modells auswirken, und auf dieser Grundlage entsprechende Maßnahmen ergreifen.
Drift auf Modellebene (Multivariate Drift-Erkennung)
Die multivariate Drifterkennung hilft dabei, Änderungen oder Drifts in mehreren Variablen oder Merkmalen gleichzeitig zu erkennen. Im Gegensatz zur univariaten Drift-Erkennung, bei der nur Änderungen in einer einzelnen Variablen erkannt werden, berücksichtigt die multivariate Drift-Erkennung die Beziehung zwischen mehreren Merkmalen und geht nicht davon aus, dass alle Merkmale unabhängig voneinander sind.
Somit können multivariate Drift-Erkennungsverfahren Änderungen in der Verteilung der Daten, Änderungen in der Beziehung zwischen Variablen und Änderungen in der funktionalen Beziehung zwischen Variablen erkennen. Diese Methoden sind besonders in komplexen Systemen nützlich, in denen Änderungen einer Variablen erhebliche Auswirkungen auf das Verhalten anderer Variablen haben können. Multivariate Drift hilft Benutzern also, die Änderungen der Inferenzdaten besser zu verstehen. Es ist auch einfacher zu überwachen, da nur eine Metrik verfolgt werden muss, anstatt jedes Merkmal einzeln zu verfolgen. Aber gleichzeitig ist es rechenintensiv zu berechnen und könnte für einfachere Systeme übertrieben sein.
Algorithmen zur Erkennung von multivariaten Driften hängen in der Regel von einem Modell für maschinelles Lernen ab, um die Drift zu berechnen. Diese Algorithmen können also wie folgt klassifiziert werden:
Betreute Methoden verwenden: Diese basieren in der Regel auf dem Training eines binären Klassifikatormodells, um zu erraten, ob ein Datenpunkt aus dem Basisdatenrahmen stammt. Ein höherer Genauigkeitswert des Modells weist auf eine höhere Drift hin.
Um herauszufinden, welche Merkmale sich verändert haben, wird die Merkmalsbedeutung dieses binären Klassifikationsmodells verwendet.
Methoden des unbeaufsichtigten Lernens: Hier sind ein paar Methoden: Clustering: Verwenden Sie K-Means, DBSCAN oder einen anderen Clustering-Algorithmus, um Cluster im Referenzdatensatz und im aktuellen Datensatz zu finden und dann Unterschiede zwischen den Clustern zu ermitteln, um zu beurteilen, ob die Daten driftet sind oder nicht.
Gaußsche Mischungsmodelle (GMM): GMM stellt unsere Daten als eine Mischung aus Gaußschen Verteilungen dar. GMM kann verwendet werden, um multivariate Drift zu erkennen, indem die Parameter der Gaußschen Verteilungen des aktuellen Datensatzes mit dem Referenzdatensatz verglichen werden.
Hauptkomponentenanalyse (PCA): Verwenden Sie PCA, um die Dimensionen des Datensatzes zu reduzieren, und verwenden Sie dann reguläre Algorithmen zur Erkennung univariater Abweichungen, wobei die Merkmale als einzigartig betrachtet werden.
Zusammenfassend lässt sich sagen, dass die multivariate Drifterkennung in komplexen Systemen hilfreich ist und einfacher zu überwachen ist, da nur ein KPI überwacht werden muss.
Modelldrift erkennen
Schlußfolgerung:
Die Leistung eines in der Produktion eingesetzten Modells wird irgendwann abnehmen. Die Zeit, die für diesen Zerfall benötigt wird, hängt vom Anwendungsfall ab. In einigen Fällen driften die Modelle möglicherweise erst nach einem Jahr, während bei einigen Modellen möglicherweise jede Stunde eine Umschulung erforderlich ist! Daher ist es äußerst wichtig, die Ursache dieser Verschlechterung zu verstehen und sie zu erkennen. Hier kann die „Früherkennung von Abweichungen“ helfen.
Zusammenfassend lässt sich sagen, dass Modelle in der Produktion über geeignete Mechanismen zur Driftverfolgung oder Driftüberwachung verfügen und über Umschulungspipelines verfügen sollten, um den größtmöglichen Nutzen aus einem Modell für maschinelles Lernen zu ziehen!
Wahre Gießerei ist ein ML Deployment PaaS über Kubernetes, um die Workflows von Entwicklern zu beschleunigen und ihnen gleichzeitig volle Flexibilität beim Testen und Bereitstellen von Modellen zu bieten und gleichzeitig die volle Sicherheit und Kontrolle für das Infra-Team zu gewährleisten. Über unsere Plattform ermöglichen wir Teams für maschinelles Lernen bereitstellen und überwachen Modelle innerhalb von 15 Minuten mit 100% iger Zuverlässigkeit, Skalierbarkeit und der Möglichkeit, innerhalb von Sekunden rückgängig zu machen. So können sie Kosten sparen und Modelle schneller für die Produktion freigeben, wodurch ein echter Geschäftswert erzielt wird.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.
Auf Geschwindigkeit ausgelegt: ~ 10 ms Latenz, auch unter Last

































.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




