Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.
9,9
GenAI als Service für Unternehmen
Published: April 22, 2026
Auf Geschwindigkeit ausgelegt: ~ 10 ms Latenz, auch unter Last
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Verarbeitet mehr als 350 RPS auf nur 1 vCPU — kein Tuning erforderlich
Für Plattformingenieure bedeutet GenAI as a Service den Aufbau eines Systems, das es verschiedenen Teams — Datenwissenschaftlern, Anwendungsentwicklern und Geschäftsanwendern — ermöglicht, nahtlos auf KI-Modelle zuzugreifen, diese bereitzustellen und mit ihnen zu experimentieren, ohne sich Gedanken über Infrastruktur- und Betriebsengpässe machen zu müssen.
Die Idee von GenAI klingt zwar aufregend, aber die Realität ist, dass Plattformteams unter immensem Druck stehen, eine skalierbare, kosteneffiziente und sichere KI-Infrastruktur bereitzustellen. Sie stehen vor engen Fristen, sich ändernden Unternehmensanforderungen und sich schnell ändernden KI-Modellen, was den Einsatz von GENai zu einem ständig wechselnden Ziel macht.
Die zentrale Herausforderung: Modellvielfalt und Infrastrukturkomplexität
Eines der größten Probleme für Plattformteams ist, dass Modelle zur Standardware werden. Alle paar Wochen werden neue und verbesserte LLMs, Einbettungsmodelle und Reranker usw. veröffentlicht. Geschäftsteams wollen sie sofort integrieren, aber das ist ein Albtraum für die Infrastrukturplanung.
Wie tauscht man LLMs ein und aus, ohne bestehende Anwendungen zu unterbrechen?
Wie stellen Sie sicher, dass verschiedene Teams Zugriff auf das richtige Modell erhalten, ohne dass sich der Aufwand verdoppelt?
Wie sorgen Sie dafür, dass Modelle kostengünstig laufen, wenn die GPU-Ressourcen begrenzt sind?
Unternehmen benötigen ein zentralisiertes System, das diese Komplexität abstrahiert und es Teams ermöglicht, KI-Dienste zu nutzen, ohne die Infrastruktur zu beschädigen.
Herausforderungen bei der Operationalisierung von GenAI as a Service
Ready to Build With GenAI? Start With TrueFoundry.
TrueFoundry gives you everything you need to build, deploy, and scale generative AI applications across open and closed-source models. From a unified API layer and prompt management to full observability and self-hosted deployment, it’s the enterprise-grade GenAIaaS platform built for developers.
Die interne Bereitstellung von GenAI-Modellen ist weitaus komplexer als die Ausführung einer Standard-Softwareanwendung -
Unterstützung für verschiedene Modelle
Unterstützung für mehrere Open-Source-Modelle (z. B. Llama) und proprietäre API-Modelle (z. B. OpenAI, Anthropic).
Unternehmen müssen verschiedene Modelle wie Einbettungsmodelle, Reranker usw. für unterschiedliche Aufgaben unterstützen.
Multi-Cloud- und On-Premise-Bereitstellung: Unternehmen benötigen Flexibilität, um Modelle bei Cloud-Anbietern (AWS, GCP, Azure) oder vor Ort auf der Grundlage von Kosten, Compliance und GPU-Verfügbarkeit bereitzustellen
GPU-Orchestrierung ist nicht trivial: Kubernetes, Ray und Slurm werden häufig benötigt, um GPUs dynamisch zuzuweisen. Außerdem erfordert der Wechsel zwischen Anbietern (z. B. von AWS A100 zu GCP TPU) Maßarbeit.
Containerisierung und Orchestrierung: Ohne Containerisierung der Modelle haben Teams mit Abhängigkeiten, Softwarekonflikten und Versionsproblemen zu kämpfen. Es bot auch zusätzliche Vorteile wie Auto-Scaling, GPU-Scheduling, Fehlertoleranz usw., die in der Produktionsumgebung sehr wichtig sind.
Bereitstellung auf verschiedenen Infra-Konfigurationen: Einige Workloads erfordern eine extrem niedrige Latenz für die Produktion, während Entwicklung und Experimente höhere Latenzen tolerieren können. Beispiel: Ein Unternehmen benötigt möglicherweise zwei verschiedene LLAMA-Instanzen — eine, die aus Kostengründen effizient auf T4- oder A10G-GPUs läuft, während eine andere auf H100-GPUs für latenzempfindliche Anwendungen mit hoher Priorität ausgeführt wird.
Integration mit Modellregistern: Unternehmen führen häufig mehrere Modellregistrierungen (z. B. MLFlow, SageMaker, Hugging Face), was eine nahtlose Integration für Versionskontrolle und Prüfung erfordert.
Umgang mit fein abgestimmten Modellen: Datenwissenschaftler optimieren häufig Modelle, und Plattformteams müssen sicherstellen, dass diese Modelle effizient und sicher eingesetzt werden.
2. Ermöglicht sichere und skalierbare Inferenzen
Nach der Bereitstellung besteht die Herausforderung darin, diese Modelle für Inferenzen in verschiedenen Unternehmensanwendungen verfügbar zu machen.
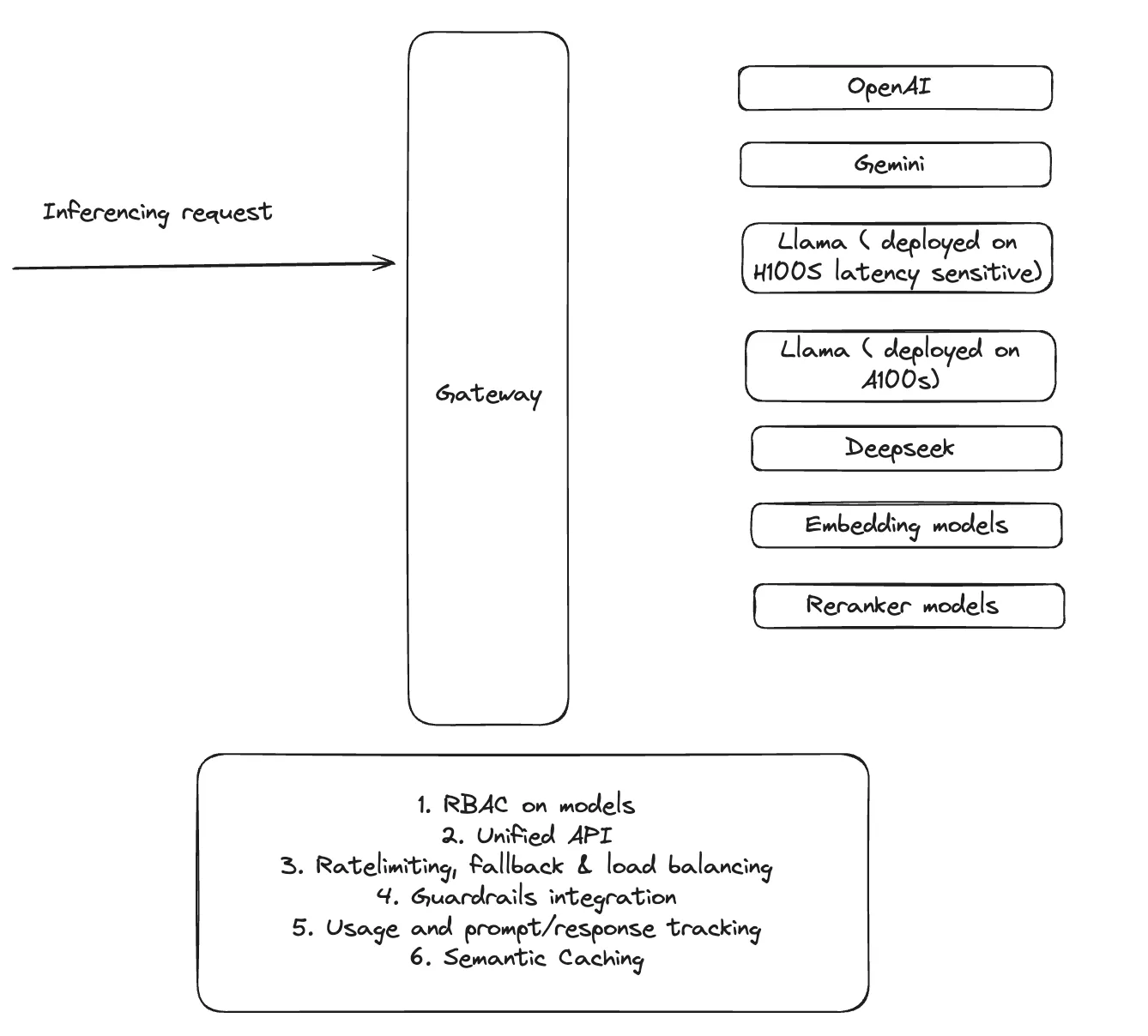
Zugriffskontrolle für Modelle: Definition von RBAC (Role-Based Access Control) zur Verwaltung des Modellzugriffs auf der Grundlage von Teams oder Benutzern
APIs und Standardisierung: Ermöglicht es Teams, auf einfache Weise Inferenzendpunkte zu erstellen und mehrere LLMs über ein Self-Service-Portal auszutauschen und auszutauschen.
Benutzerdefinierte Kontingente und Ratenbegrenzung: Definition von Quoten für die Modellnutzung auf Benutzer-, Team- oder Organisationsebene, um eine faire Ressourcenzuweisung zu gewährleisten.
Failover-Mechanismen: Implementierung von Ausweichlösungen zur Vermeidung von Produktionsausfällen, z. B. automatisches Wechseln zu einem anderen Modellanbieter (z. B. OpenAI zu einem alternativen Modell).
Semantisches Caching: Nutzung von Caching-Strategien, um sicherzustellen, dass ähnliche Abfragen keine redundanten Berechnungen erfordern, wodurch die Effizienz verbessert wird.
Beobachtbarkeit der Modellnutzung: Erfassung aller Benutzeranfragen, Modellantworten und API-Aufrufe für Governance, Debugging und Abrechnung.
3. Beobachtbarkeit und Unternehmensführung
GenAI-Modelle sind nicht statisch; sie müssen kontinuierlich evaluiert und verbessert werden. Plattformteams haben mit folgenden Problemen zu kämpfen:
Einblicke in die Verfügbarkeit und Nutzung von Grafikprozessoren: Bietet Transparenz über die GPU-Auslastung, um die Ressourcenzuweisung zu optimieren.
Loggen und Debuggen: Erfassung aller Nutzungsmetriken, einschließlich Benutzeraufforderungen und Modellausgaben, für eine bessere Nachverfolgung und Analyse.
LLM-Benchmarking: Bereitstellung empirischer Daten zur LLM-Leistung, um sicherzustellen, dass die ausgewählten Modelle die gewünschten Qualitäts- und Zuverlässigkeitsstandards des Unternehmens erfüllen.
Sicherheitsgeländer: Integration mit vordefinierten oder benutzerdefinierten Sicherheitsvorkehrungen, um die Offenlegung personenbezogener Daten und anderer vertraulicher Informationen zu vermeiden
Komplexität der Schlüsselverwaltung: Die Verwaltung von API-Schlüsseln, Geheimnissen und Authentifizierung in verschiedenen Cloud-Umgebungen erhöht die Sicherheitsrisiken und den Betriebsaufwand.
Wie TrueFoundry GenAI als Service ermöglicht
TrueFoundry bietet eine durchgängige KI-Infrastrukturplattform, die die Modellbereitstellung, Inferenz und Governance vereinfacht, sodass sich Plattformteams auf Skalierbarkeit, Effizienz und Sicherheit konzentrieren können, anstatt auf Infrastrukturengpässe.
Die All-in-One-Plattform für einheitliche Bereitstellungen
TrueFoundry bietet eine Kubernetes-native KI-Plattform, die die Modellbereitstellung und das Infrastrukturmanagement automatisiert, sodass keine manuelle Konfiguration erforderlich ist.
Cloud-übergreifender und On-Premise-Support — Mit Multi-Cloud- und On-Premise-Support können Unternehmen Modelle auf AWS, GCP, Azure oder privaten Rechenzentren ohne zusätzlichen Betriebsaufwand bereitstellen.
Unterstützt die Bereitstellung von Modellen in verschiedenen Modell-Frameworks, Typen und Servern. Unterstützt auch die Bereitstellung von Embedding- und Reanker-Modellen.
Die Plattform wählt automatisch die beste Kubernetes-Bereitstellungskonfiguration auf der Grundlage der Modellarchitektur, der GPU-Verfügbarkeit und der Durchsatzanforderungen aus.
TrueFoundry optimiert auch die Infrastruktur, indem es automatische Skalierungsfunktionen bereitstellt, die die Zeit für die Modellskalierung um das 3- bis 5-fache reduzieren und so die Verzögerungen beim Kaltstart erheblich reduzieren.
Unterstützt auch erweiterte Funktionen wie Bild-Streaming, Sticky-Routing für LLMs und intelligente GPU-Empfehlungen
Darüber hinaus ermöglicht TrueFoundry die Self-Service-Modellbereitstellung, sodass Datenwissenschaftler Modelle ohne Kubernetes-Kenntnisse bereitstellen können. Dadurch werden die Abhängigkeiten von Plattformingenieuren reduziert und die Einführung von KI in allen Teams beschleunigt.
Volle Gitops-Unterstützung, um Plattformteams das Leben zu erleichtern
Einheitliche und skalierbare Modellinferenz
TrueFoundry vereinfacht die Modellinferenz, indem es ein zentralisiertes KI-Gateway bereitstellt, das einen nahtlosen Zugriff auf Modelle in verschiedenen Cloud-Umgebungen gewährleistet.
Mit einer einzigen API können Plattformteams Open-Source-Modelle (Llama), kommerzielle Lösungen (OpenAI, Bedrock, Mistral) und fein abgestimmte Unternehmensmodelle verwalten. Diese Vereinheitlichung gewährleistet konsistente Inferenzfunktionen in allen Arbeitsabläufen.
Es unterstützt auch Ratenbegrenzungen, um Kontingente für alle Benutzer/Teams/Modelle sicherzustellen, Load Balancing und automatisiertes Failover, um Unterbrechungen zu vermeiden. Bei Serviceausfällen oder Leistungseinbußen können die Modelle ohne manuelles Eingreifen nahtlos auf alternative Anbieter zurückgreifen.
Darüber hinaus reduziert semantisches Caching redundante Berechnungen, optimiert die Reaktionszeit und senkt die Betriebskosten.
TrueFoundry integriert auch nativ Reranker- und Embedding-Modelle, wodurch es einfacher wird, RAGs (Retrieval-Augmented Generation) zu erstellen — ein häufiger Anwendungsfall.
Beobachtbarkeit, Sicherheit und Unternehmensführung
Plattformteams können die Modellnutzung in Echtzeit verfolgen, überwachen, wer welche Modelle wie oft aufruft, und die Systemleistung analysieren, um die Ressourcenzuweisung zu optimieren.
Die Plattform bietet detaillierte Protokollierungs- und Debugging-Tools, die es Ingenieuren ermöglichen, Probleme effizient zu verfolgen, Ausfallzeiten zu reduzieren und die Zuverlässigkeit zu verbessern.
Sicherheit steht im Mittelpunkt. Das zentrale API-Schlüsselmanagement verhindert unbefugten Zugriff und stellt sicher, dass Authentifizierungsprozesse in Cloud-Umgebungen sicher bleiben. TrueFoundry gewährleistet auch den Datenschutz auf Unternehmensebene, indem alle KI-Workloads innerhalb der VPC-Infrastruktur des Unternehmens bereitgestellt werden, wodurch das Risiko einer Offenlegung externer Daten ausgeschlossen wird.
Darüber hinaus lässt sich die Plattform nahtlos in Leitplanken wie Nemo-Leitplanken, Arize usw. integrieren, um PII-Daten zu erkennen usw.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.
Auf Geschwindigkeit ausgelegt: ~ 10 ms Latenz, auch unter Last






























.png)

.webp)
.webp)
.webp)



.webp)
.webp)


