
June 23, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: June 23, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
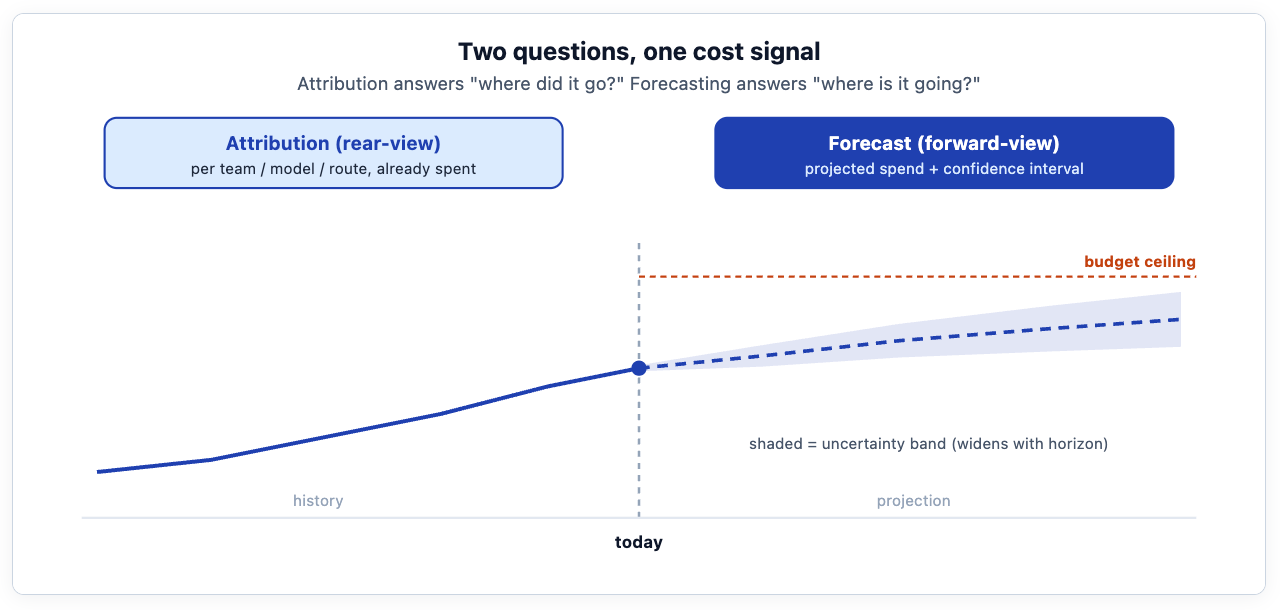
How to turn your AI Gateway's cost data into a forward-looking budget forecast — with an early-warning signal before you breach — using two well-understood time-series models, run end to end on TrueFoundry.
The tokenmaxxing trilogy made the case for attribution: you cannot govern spend you cannot see. The Field Notes follow-up on the Meta / Amazon / Uber whipsaw argued that attribution alone gives you a dial instead of a switch. But a dial still leaves one question unanswered: not "where did the money go?" — that is the rear-view mirror — but "where is it going?" When Uber was reported to have burned through its entire 2026 AI coding budget in four months, the problem was not that the spend was invisible. It was that nobody had a credible projection of when the budget would run out until it already had.
This post is about closing that gap with a forecast. We will walk a fictional but realistic company — Meridian, a mid-size fintech with about 800 engineers — from "we have attributed cost data" to "we have a weekly, self-updating projection of token spend per team, with an honest uncertainty band and an alert that fires before the budget breaks." We will use two complementary time-series models, SARIMAX and Prophet, and we will build, deploy, and re-train the whole thing on TrueFoundry — the same platform that emits the gateway cost telemetry, which also provides the ML infrastructure to train, serve, and retrain the forecaster.
Everything here depends on one precondition: clean, attributed cost data with a timestamp. That is exactly what a well-instrumented AI Gateway can produce: request-level cost — auto-priced from providers' published rates — with the metadata needed to aggregate spend by team, route, model, customer, or cost center. As covered in the trilogy and the observability overview, every request through the gateway emits that cost figure tagged by model, user, and arbitrary metadata, and exports to your warehouse or observability stack. Aggregate it to a weekly total per cost center and you have the only input a forecaster needs: a regular, labeled time series of spend.
The forecast is only as good as the tagging discipline underneath it, so this step is more operational than it looks. The gateway will faithfully record whatever metadata your applications send it — which means the time series is only as clean as that instrumentation. Before training, a team needs stable metadata keys and consistent team-to-cost-center mappings, a way to keep model prices current as providers change them, and an explicit policy for the awkward records: late or missing data, retries, fallbacks, and cached responses that cost little or nothing. Normalizing pricing, de-duplicating, and aligning timestamps to a single timezone is unglamorous, but it is the difference between a forecast and a confident-looking artifact built on noise.
That said, this is still the part teams without a gateway cannot do at all. If your spend is scattered across raw provider invoices, you can reconstruct a company-level monthly total, but you cannot get a clean weekly series per team with the causal context attached — and per-team, context-rich series are what make forecasting useful rather than decorative. The gateway is not just a cost-control point; it is the instrument that makes the spend forecastable in the first place.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.









.webp)
.webp)
.webp)
.webp)
.webp)

.webp)

.webp)

.webp)
