

July 21, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026
.webp)
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Ein vortrainiertes Modell wird anhand eines kleineren, spezifischen Datensatzes, der auf eine bestimmte Aufgabe zugeschnitten ist, weiter trainiert oder „abgestimmt“.
Angenommen, Sie entwickeln ein Modell, das technische Handbücher für Elektronik mithilfe von GPT-3 (einem großen Sprachmodell mit 175 Milliarden Parametern) generiert, aber die generische Ausgabe von GPT-3 erfüllt nicht die erforderliche technische Genauigkeit und den erforderlichen Ton.
In diesem Fall können Sie sich vorstellen, das Modell für Ihren speziellen Anwendungsfall neu zu trainieren, aber ein Modell wie GPT-3 direkt von Grund auf neu zu trainieren, um diese Nischenaufgabe zu lösen, ist aufgrund des Rechenressourcenbedarfs und der speziellen Daten nicht praktikabel.
Hier kommt die Feinabstimmung ins Spiel.
Feinabstimmung ist, als würde man GPT-3 einen neuen Trick beibringen. Dank seiner Schulung an zahlreichen Texten, von Büchern bis hin zu Websites, weiß es bereits viel über Sprachen. Ihre Aufgabe ist es, es anhand eines bestimmten Datensatzes weiterzubilden — in diesem Fall eines Korpus vorhandener technischer Handbücher und Dokumentationen, die speziell für die Elektronik entwickelt wurden.
Einige grundlegende Methoden der Feinabstimmung:
Die parametereffiziente Feinabstimmung (PEFT) ist eine Technik, die darauf abzielt, die Anzahl zusätzlicher Parameter zu minimieren, die bei der Feinabstimmung vortrainierter neuronaler Netzwerkmodelle erforderlich sind.
Dies hilft, den Rechenaufwand und den Speicherverbrauch zu senken und gleichzeitig die Leistung beizubehalten oder sogar zu verbessern. PEFT erreicht dies, indem es Prompt-Einbettungen als zusätzliche Modellparameter hinzufügt und nur eine kleine Anzahl zusätzlicher Parameter optimiert.
PEFT erfordert im Vergleich zur herkömmlichen Feinabstimmung auch einen viel kleineren Datensatz.
Laden Sie Ihr ausgewähltes Modell mithilfe eines Frameworks für maschinelles Lernen wie TensorFlow, PyTorch oder der Transformers-Bibliothek von Hugging Face. Diese Frameworks bieten APIs zum einfachen Herunterladen und Laden vortrainierter Modelle.
Hier ist ein Beispielcode:
Vor der Feinabstimmung müssen Sie mit verschiedenen Eingabeaufforderungen experimentieren, die als Richtschnur für die Antworten des Modells dienen. Testen Sie verschiedene Eingabeaufforderungen mit dem vortrainierten Modell, um zu sehen, wie sie sich auf die Ausgabe auswirken, und wählen Sie die am besten geeignete aus. Sie können auch verschiedene Parameter wie max_length, temperature usw. ändern.
Es ist, als ob Sie herausfinden, wie Sie Ihre Frage am besten stellen können, damit das Model versteht, was Sie wollen.
Ein Datensatz für die Feinabstimmung besteht normalerweise aus zwei Teilen: Prompt (Input) und Answer (Output). Die Aufforderung ist wie eine Frage oder ein Ausgangspunkt, und die Antwort ist das, was das Modell als Antwort auf diese Frage generieren soll. Sie kann in Form von Spalten oder einer Folge von Texteinträgen (häufiger) vorliegen.
Der beste Prompt, der im letzten Schritt identifiziert wurde, wird hier verwendet und die Antwort wird genau das sein, was das Modell produzieren soll, wenn es diesen Prompt erhält.
Hier bringen Sie dem Modell bei, um Ihre Aufgabe besser zu bewältigen. Sie verwenden den Datensatz, um das „Wissen“ des Modells leicht anzupassen.
Hier finden Sie eine vereinfachte Übersicht über die Einrichtung und Ausführung des Feinabstimmungsprozesses mit PyTorch:
Vorbereitung für das Training:
Trainingsschleife:
Bei der Erforschung von Tools für schnelles Engineering ist es hilfreich, sie in zwei Hauptbereiche zu unterteilen: Code-Plattformen und No-Code-Plattformen. Diese Unterscheidung vereinfacht das Auswahlverfahren
Codeplattformen beziehen sich auf Plattformen, die virtuelle Maschinen bereitstellen, mit denen Sie Ihr benutzerdefiniertes Python-Skript zur Feinabstimmung wie das zuvor erwähnte ausführen können. In der Zwischenzeit beziehen sich No-Code-Plattformen auf Tools, für deren Ausführung ein einfaches oder kein Python-Skript erforderlich ist. Es hat eine spezielle Benutzeroberfläche, auf der Sie mit wenigen Klicks mit dem Training beginnen können.
Codeplattformen sind für Benutzer mit soliden Programmierkenntnissen konzipiert. Diese Plattformen bieten virtuelle Maschinen, auf denen benutzerdefinierte Python-Skripte für Aufgaben wie die Feinabstimmung ausgeführt werden können. Diese Plattformen eignen sich perfekt für Projekte, die eine hohe Anpassungsfähigkeit und eine komplizierte Kontrolle der Schulungs- und Bereitstellungsphasen erfordern.
Amazon SageMaker ist ein vollständig verwalteter Service, der Entwicklern und Datenwissenschaftlern die Möglichkeit bietet, Modelle für maschinelles Lernen schnell zu erstellen, zu trainieren und bereitzustellen.
Amazon SageMaker verfügt nicht über eine spezielle, integrierte „Feinabstimmung“ -Funktion, die speziell als solche für große Sprachmodelle gekennzeichnet ist. Stattdessen bietet es eine leistungsstarke und flexible Plattform, auf der Sie benutzerdefinierte Python-Skripte ausführen können, um Feinabstimmungsaufgaben zu erledigen.
Hier ist ein einfaches Beispiel dafür, wie Sie mit Hugging Face auf SageMaker eine Feinabstimmung für ein Sprachmodell starten könnten. Dies setzt voraus, dass Sie bereits ein AWS-Konto eingerichtet und die AWS-CLI konfiguriert haben. (Sie können TensorFlow oder PyTorch direkt auf Amazon SageMaker für Feinabstimmungsaufgaben verwenden)
Normalerweise schreiben Sie ein Feinabstimmungsskript (train.py), das Sie an den Schätzer übergeben. Dieses Skript sollte die Logik für das Laden, die Feinabstimmung und das Speichern Ihres Modells beinhalten.
Google Colab ist ein beliebter Cloud-basierter Jupyter-Notebook-Service, der freien Zugriff auf Computerressourcen wie GPUs und TPUs bietet und damit eine hervorragende Plattform für die Feinabstimmung großer Sprachmodelle (LLMs) ist
Es ist besonders anfängerfreundlich. Colab-Notebooks werden in der Cloud direkt von Ihrem Browser aus ausgeführt, ohne dass eine lokale Einrichtung erforderlich ist.
Hier ist der einfache Codeausschnitt zur Feinabstimmung eines Transformer-Modells mit Hugging Face Transformers und PyTorch in Google Colab
Paperspace Gradient ist eine Suite von Tools, die entwickelt wurden, um den Prozess der Entwicklung, Schulung und Bereitstellung von Modellen für maschinelles Lernen in der Cloud zu vereinfachen.
Gradient ist aufgrund seiner skalierbaren Infrastruktur und der Unterstützung von Containern besonders effektiv für Aufgaben wie die Feinabstimmung großer Sprachmodelle (LLMs), was es zu einer guten Wahl für Datenwissenschaftler und ML-Praktiker macht.
Hier ist ein Beispiel für die Feinabstimmung eines Transformer-Modells mit PyTorch auf Paperspace Gradient.
Run.AI ist eine Plattform, die entwickelt wurde, um GPU-Ressourcen für maschinelles Lernen zu optimieren und es Datenwissenschaftlern und KI-Forschern zu erleichtern, komplexe KI-Modelle auszuführen und zu verwalten, einschließlich der Feinabstimmung großer Sprachmodelle (LLMs).
Es basiert auf Kubernetes, einem Tool, das Computerressourcen effizient organisiert. Es erleichtert also die Durchführung komplexer KI-Projekte und ermöglicht Teams, ihre Projekte reibungslos auszubauen.
Detaillierte Einblicke finden Sie in der Dokumentation zu Run.AI. Hier ist ein vereinfachtes Beispiel, das auf dem allgemeinen Arbeitsablauf zur Feinabstimmung eines Modells wie LLama-2 auf der Plattform Run.AI basiert.
Ihr train.py Skript sollte die Logik für das Laden von LLama-2 (oder das von Ihnen gewählte Modell), Ihren Datensatz und die Ausführung des Feinabstimmungsprozesses enthalten. Dies könnte die Verwendung von Bibliotheken wie Hugging Face Transformers zum Laden von Modellen und TensorFlow oder PyTorch für die Trainingsschleife beinhalten.
Run.AI bietet Tools, mit denen Sie die GPU-Nutzung und den Fortschritt Ihrer Trainingsjobs überwachen und Rechenressourcen effektiv verwalten können. Verwenden Sie das Dashboard oder die CLI von Run.AI, um den Status und die Leistung Ihres Jobs im Auge zu behalten.
Runai listet Jobs auf
Dieser Befehl listet alle aktuellen Jobs auf, sodass Sie den Fortschritt und den Ressourcenverbrauch Ihrer Feinabstimmungsaufgabe überwachen können.
No-Code-Plattformen sind dagegen auf Einfachheit und Benutzerfreundlichkeit zugeschnitten. Sie machen das Schreiben von Python-Skripten überflüssig und bieten eine intuitive Benutzeroberfläche, mit der das Training mit nur wenigen Klicks gestartet werden kann. Diese Domain eignet sich für Benutzer ohne Programmierkenntnisse oder für Benutzer, die einen unkomplizierten Ansatz für schnelles Engineering bevorzugen.
Die OpenAI-API bietet Zugriff auf fortschrittliche Modelle für künstliche Intelligenz, die von OpenAI entwickelt wurden, einschließlich der neuesten Versionen von GPT (Generative Pre-trained Transformer). Eine der herausragenden Funktionen der OpenAI-API ist ihre Fähigkeit, Modelle anhand benutzerdefinierter Datensätze zu optimieren.
So können Sie das Verhalten von Modellen wie GPT-3 oder neueren Versionen an bestimmte Anwendungen anpassen oder bestimmte Inhaltsstile und Präferenzen einhalten.
Da ich mich auf die API beziehe, handelt es sich nicht gerade um „No-Code“, dennoch kann man sie im Vergleich zu anderen Tools im vorherigen Abschnitt problemlos für das Training einrichten.
Beispielcode für die Feinabstimmung:
Um ein Modell zu optimieren, müssen Sie zunächst Ihren Datensatz in einem Format vorbereiten, das die OpenAI-API verstehen kann. Normalerweise müssten Sie eine JSON-Datei erstellen, die wie folgt aussieht:
Sie können den Datensatz einfach mit Open AI CLI (Command Line Interface) hochladen.
Sobald Ihr Datensatz vorbereitet und hochgeladen ist, können Sie einen Feinabstimmungsprozess einleiten. Das Folgende ist ein Beispiel, das die Python-Bibliothek von OpenAI verwendet:
Nach Abschluss des Feinabstimmungsprozesses können Sie Ihr fein abgestimmtes Modell zum Generieren von Text oder für andere Aufgaben verwenden, indem Sie die ID des fein abgestimmten Modells angeben:
Sie können Ihr fein abgestimmtes Modell auch bereitstellen.
Microsoft Azure ist eine Cloud-Computing-Plattform, die eine breite Palette von Diensten anbietet, darunter Computer, Speicher, Analysen und mehr. Es bietet Benutzern die Tools, mit denen sie Anwendungen effizient erstellen, bereitstellen und verwalten können.
Ein bemerkenswertes Merkmal ist die intuitive Benutzeroberfläche, die Anfängern die Navigation ohne umfangreiche Programmierkenntnisse erleichtert. Mit einfachen Klicks statt mit komplexer Codierung können Benutzer ihre Anwendungen optimieren, was Azure zu einem leicht zugänglichen Tool für eine stressfreie Entwicklung macht.
Hier finden Sie eine einfache Anleitung zum Einrichten eines „Jobs“ zur Feinabstimmung in Azure:
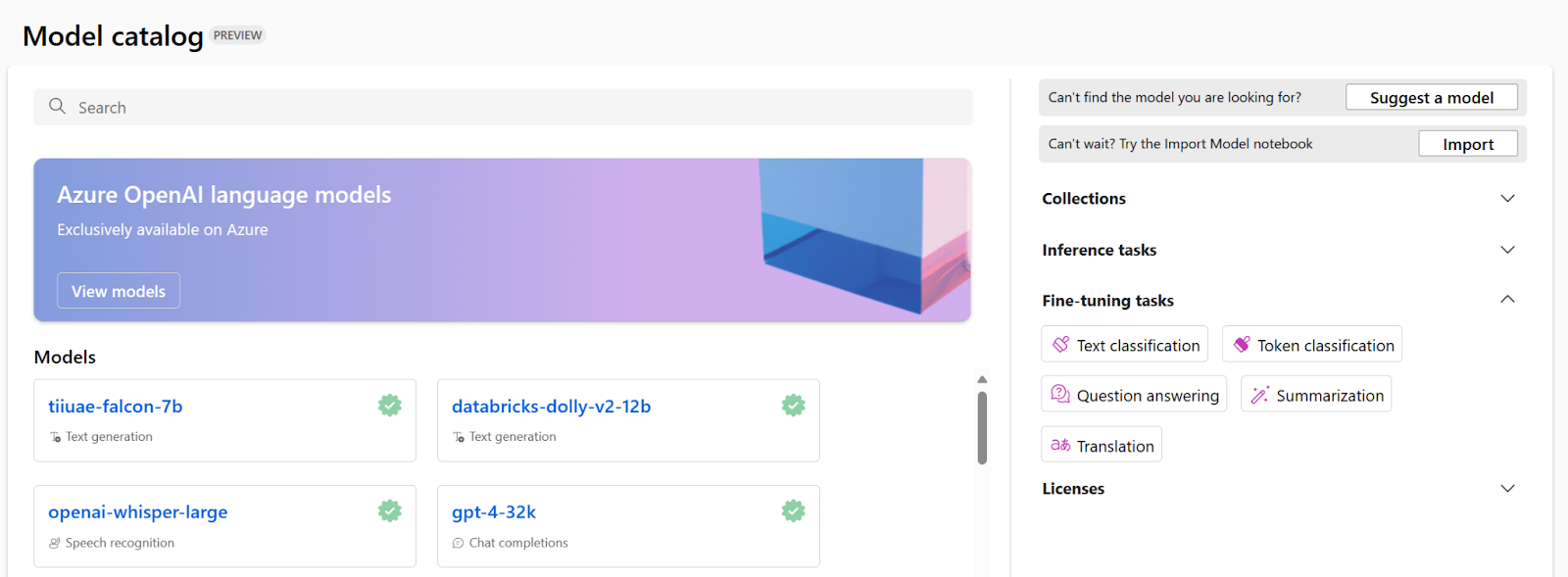
Offensichtlich ist dies die Grundvoraussetzung für alle Tools. Die Trainingsdaten können im Format JSON Lines (JSONL), CSV oder TSV vorliegen. Die Anforderungen an Ihre Daten variieren je nach der spezifischen Aufgabe, für die Sie Ihr Modell optimieren möchten.
Für die Textklassifizierung:
Zwei Spalten: Satz (Zeichenfolge) und Label (Ganzzahl/Zeichenfolge)
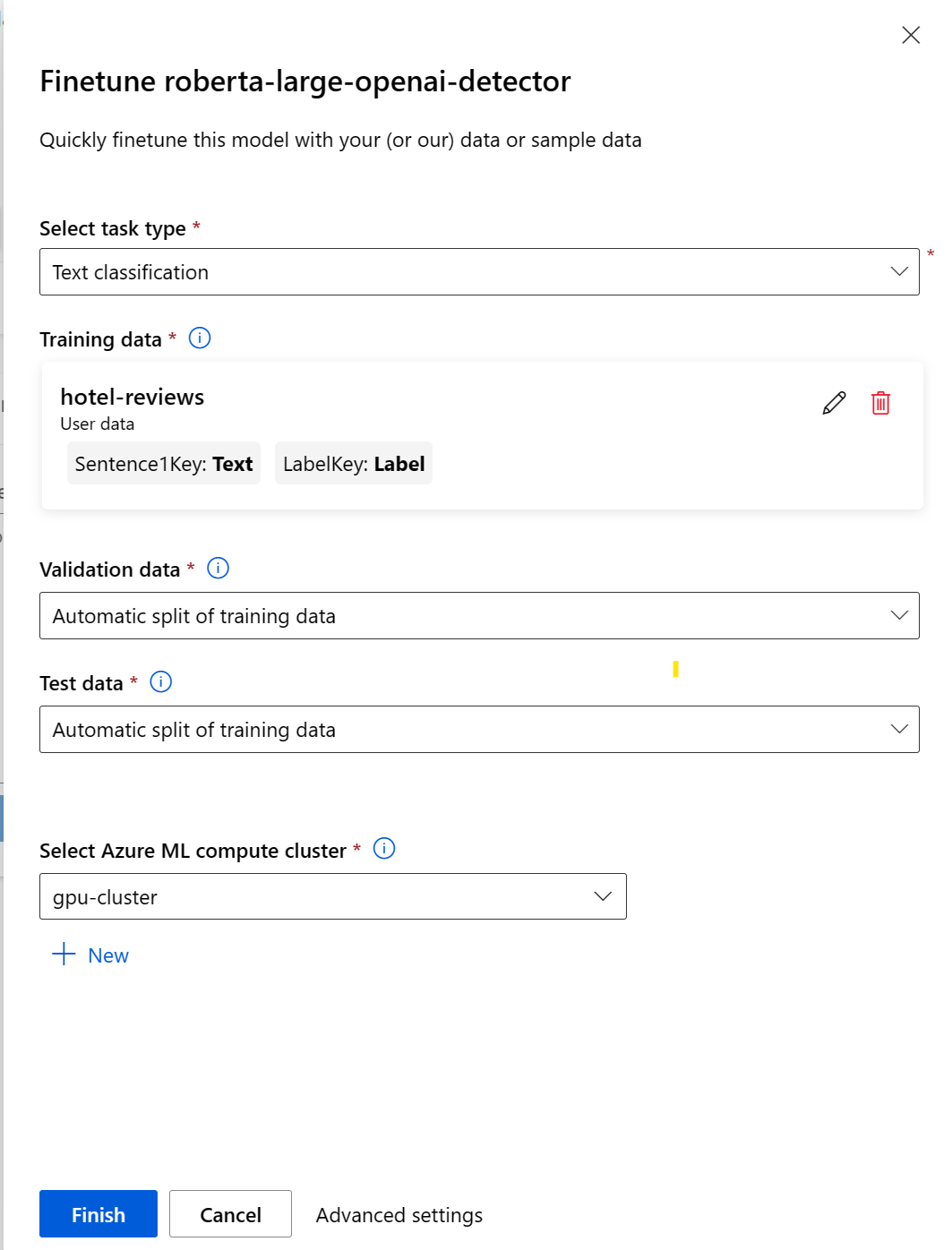
Nachdem Sie den Feinabstimmungsauftrag eingereicht haben, wird ein Pipeline-Job erstellt, um Ihr Modell zu trainieren. Sie können alle Eingaben überprüfen und das Modell anhand der Job-Ausgaben zusammenstellen.
Um zu entscheiden, ob Ihr fein abgestimmtes Modell die erwartete Leistung erbringt, können Sie die Trainings- und Bewertungsmetriken überprüfen.
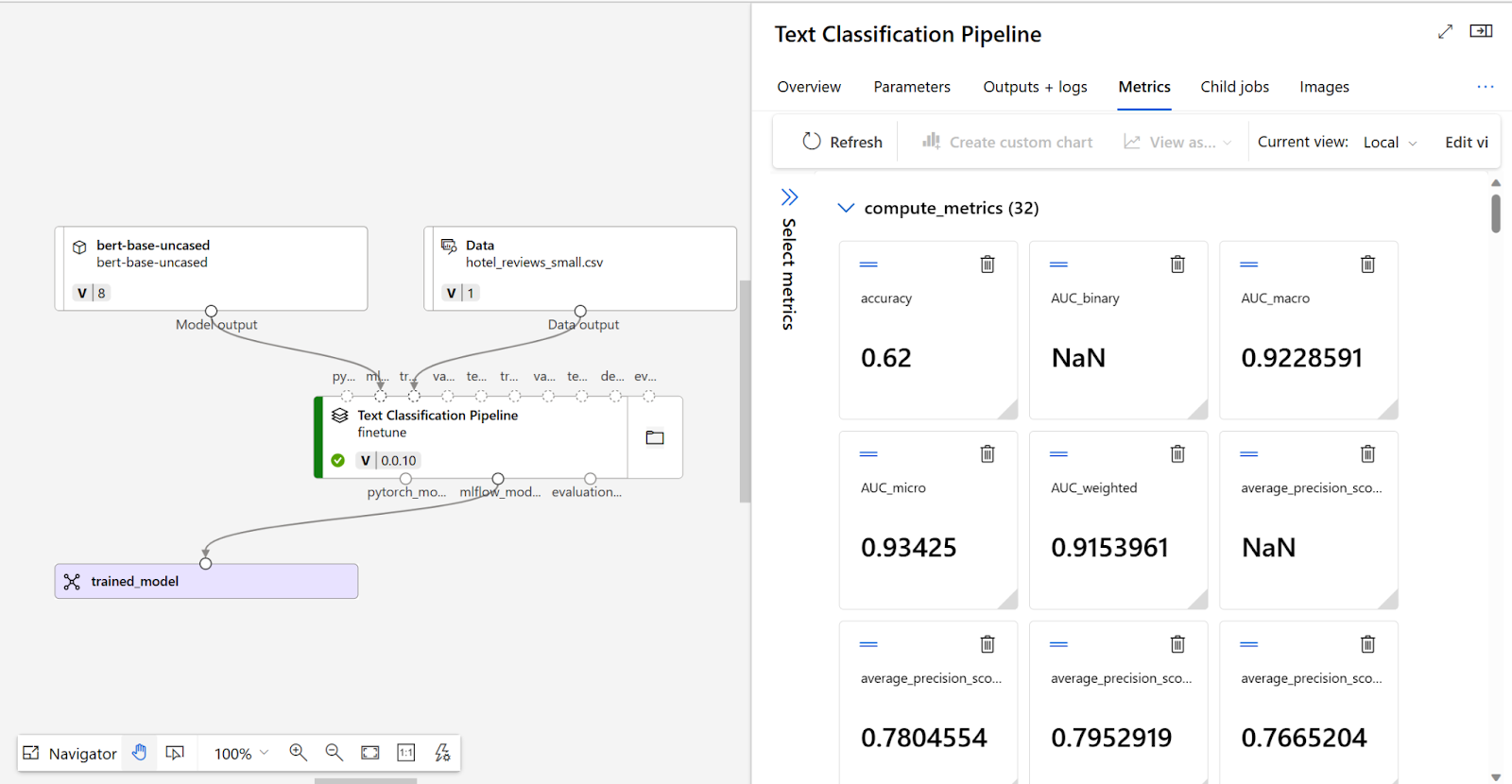
Replicate ist ein vielseitiges Tool, das für die Feinabstimmung verschiedener Aspekte von Softwareanwendungen entwickelt wurde. Zu den Anwendungen von Replicate als Tool zur Feinabstimmung gehören die Optimierung der Leistung, die Anpassung von Konfigurationen und die Erweiterung der Funktionalität mit minimalem Aufwand. Es vereinfacht den Prozess, indem es die GPU-Setup übernimmt. Ähnlich wie bei der Open AI API ist es nicht gerade „No-Code“ wie andere Tools in der Liste, dennoch kann man es im Vergleich zu anderen Tools im vorherigen Abschnitt leicht für das Training einrichten.
Schritte zur Feinabstimmung von llama-2b:
Deine Trainingsdaten müssen in einem JSONL-Format vorliegen. Im Folgenden finden Sie ein Beispiel dafür, wie Sie diese Datei strukturieren könnten:
Sie müssen Ihr Replicate-API-Token als Umgebungsvariable in Ihrem Terminal festlegen:
Sie können Ihre Daten mit curl-Befehlen in einen s3-Bucket oder direkt bei Replicate hochladen:
Sie müssen auf Replicate ein leeres Modell für Ihr trainiertes Modell erstellen. Wenn Ihr Training abgeschlossen ist, wird es als neue Version auf dieses Modell übertragen.
Sie müssen einen Trainingsjob in Ihrer IDE erstellen, wie unten gezeigt:
Um den Fortschritt programmgesteuert zu überwachen, können Sie Folgendes verwenden:
Nach Abschluss des Trainings können Sie Ihr Modell mit der API ausführen:
Bei Gen AI Studio haben Sie beide Möglichkeiten, Feinabstimmungsjobs über die API oder die Website einzurichten. Hier werde ich nur auf die API-Methode eingehen. Im Vergleich zu den oben beschriebenen Tools hat es den optimalsten Prozess.
Hier ist eine schrittweise Anleitung:
Ihr Datensatz sollte im JSONL-Format vorliegen, wobei jede Zeile ein JSON-Objekt mit den Schlüsseln „input_text“ und „output_text“ ist. Das Training kann mit nur 10 Beispielen beginnen, es werden jedoch mindestens 100 Beispiele empfohlen.
Sie müssen Ihren Datensatz in den Google Cloud Storage (GCS) -Bucket hochladen. Wenn Sie keinen haben, können Sie einen in Google Drive erstellen.
Jetzt müssen Sie Ihre Anmeldeinformationen angeben, um die Verbindung herzustellen:
Sie müssen eine Funktion für das Tuning mit den erforderlichen Parametern definieren.
Rufen Sie die zuvor angegebene Tuning-Funktion mit Ihren spezifischen Parametern auf. Der Parameter training_data kann ein GCS-URI oder ein Pandas-DataFrame sein.
Predibase ist eine spezialisierte Plattform, die entwickelt wurde, um die Feinabstimmung großer Sprachmodelle (LLMs) wie GPT-4 für bestimmte Aufgaben oder Anwendungen zu erleichtern. Sie bietet Zugriff auf die erweiterten Funktionen von LLMs, indem sie eine optimierte, benutzerfreundliche Umgebung für die Anpassung dieser Modelle an individuelle Bedürfnisse bietet.
Predibase bietet Ihnen die Möglichkeit, sowohl das Python-SDK als auch die Benutzeroberfläche für die Durchführung von Feinabstimmungsaufgaben zu verwenden.
Hier ist eine schrittweise Anleitung zur Feinabstimmung von mistral-7b-instruct:
Eröffnen Sie zunächst ein Konto bei Predibase und zahlen Sie ein, um Guthaben hinzuzufügen. Generieren Sie anschließend Ihren API-Schlüssel.
Gehen Sie zu Models und klicken Sie dann auf „New Model Repository“, wie unten gezeigt:
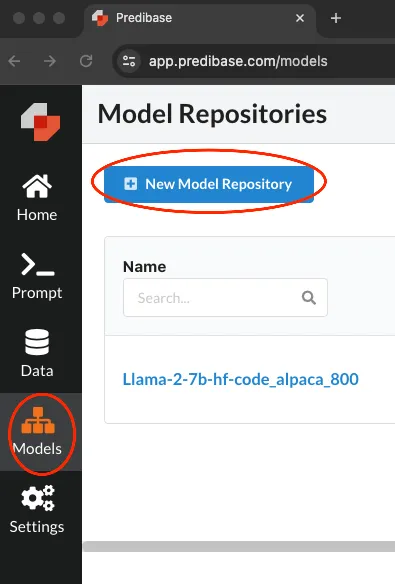
Benennen Sie nun Ihr Repository und fügen Sie eine Beschreibung hinzu.
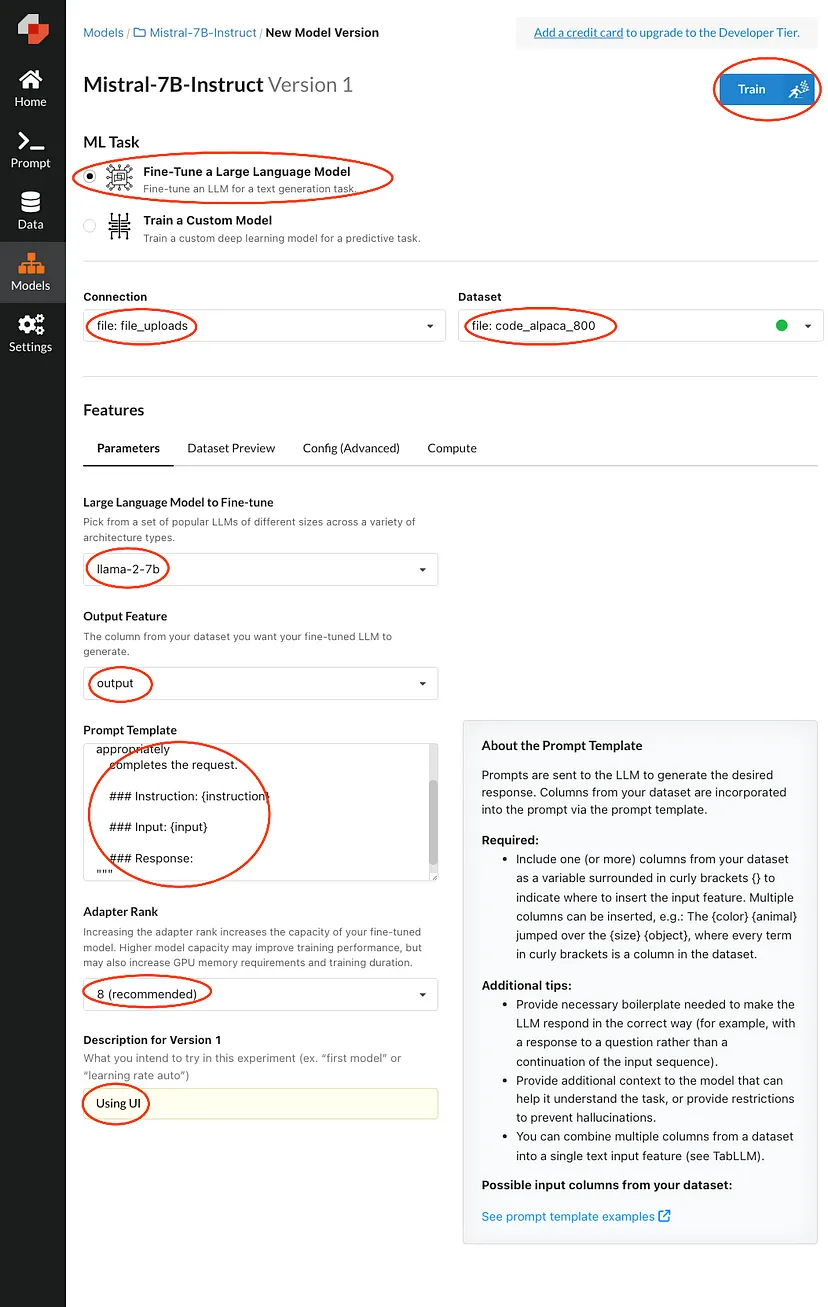
Füllen Sie die markierten Bereiche aus und drücken Sie dann Zug. Dadurch wird Ihre Anfrage in eine Warteschlange gestellt, bis ein Rechenleistung verfügbar ist.
TrueFoundry ist ein Tool, das ML-Teams dabei hilft, ihre Modelle reibungslos zum Laufen zu bringen. Es basiert auf Kubernetes, was bedeutet, dass es in verschiedenen Clouds oder sogar auf Ihren eigenen Servern ausgeführt werden kann. Dies ist wichtig für Unternehmen, die sich Sorgen um die Sicherheit ihrer Daten und die Kostenkontrolle machen
Für die Feinabstimmung ist es eines der besten Tools auf dem Markt und richtet sich sowohl an Anfänger als auch an Experten. Hier haben Sie zwei Möglichkeiten: Sie können ein Notizbuch zur Feinabstimmung zum Experimentieren bereitstellen oder eine spezielle Feinabstimmungsaufgabe starten.
Notebooks bieten ein ideales Setup für explorative und iterative Feinabstimmungen. Sie können mit einer kleinen Teilmenge von Daten experimentieren und verschiedene Hyperparameter ausprobieren, um die ideale Konfiguration für die beste Leistung zu ermitteln.
Sobald Sie die optimalen Hyperparameter und Konfigurationen durch Experimente identifiziert haben, hilft Ihnen der Übergang zu einem Bereitstellungsjob bei der Feinabstimmung des gesamten Datensatzes und ermöglicht ein schnelles und zuverlässiges Training.
Daher werden Notebooks für Explorationsarbeiten in der Anfangsphase dringend empfohlen, und Hyperparameter-Tuning- und Bereitstellungsaufgaben sind die bevorzugte Wahl für groß angelegte LLM-Feinabstimmungen, insbesondere wenn die optimale Konfiguration durch vorherige Experimente ermittelt wurde.
Hier finden Sie eine schrittweise Anleitung zur Feinabstimmung mit Notebook und Jobs:
1. Einrichtung der Trainingsdaten
Truefoundry unterstützt zwei verschiedene Datenformate:
Jede Zeile enthält einen Schlüssel namens Nachrichten. Jeder Nachrichtenschlüssel enthält eine Liste von Nachrichten, wobei jede Nachricht ein Wörterbuch mit Rollen- und Inhaltsschlüsseln ist. Der Rollenschlüssel kann entweder Benutzer, Assistent oder System sein, und der Inhaltsschlüssel enthält den Nachrichteninhalt.
2. Feinabstimmung
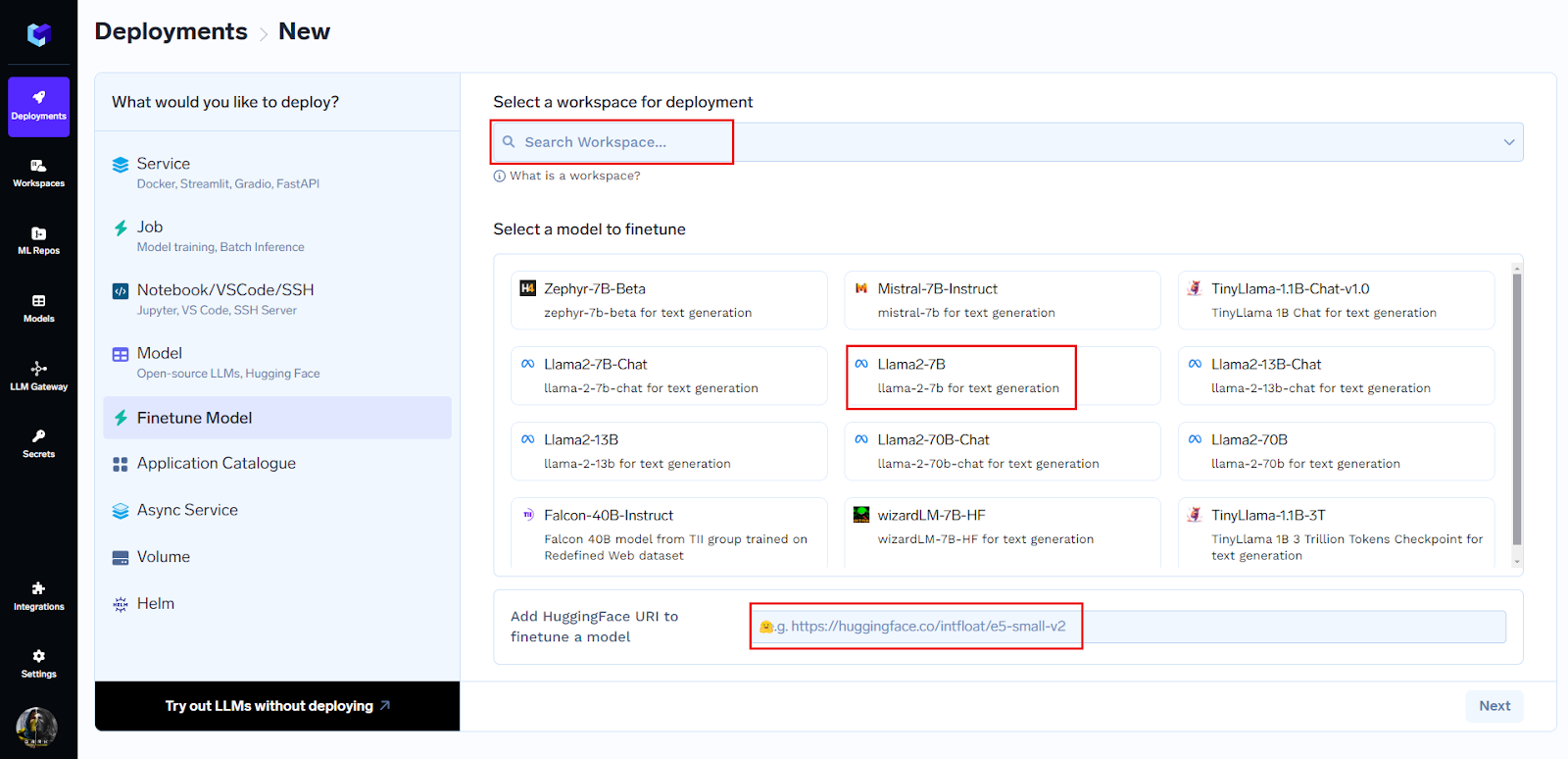
Mit nur drei Klicks können Sie mit der Feinabstimmung beginnen:
Sie können das Modell aus der umfangreichen Liste auswählen oder einfach die Huggingface-URL einfügen, um mit der Feinabstimmung zu beginnen.
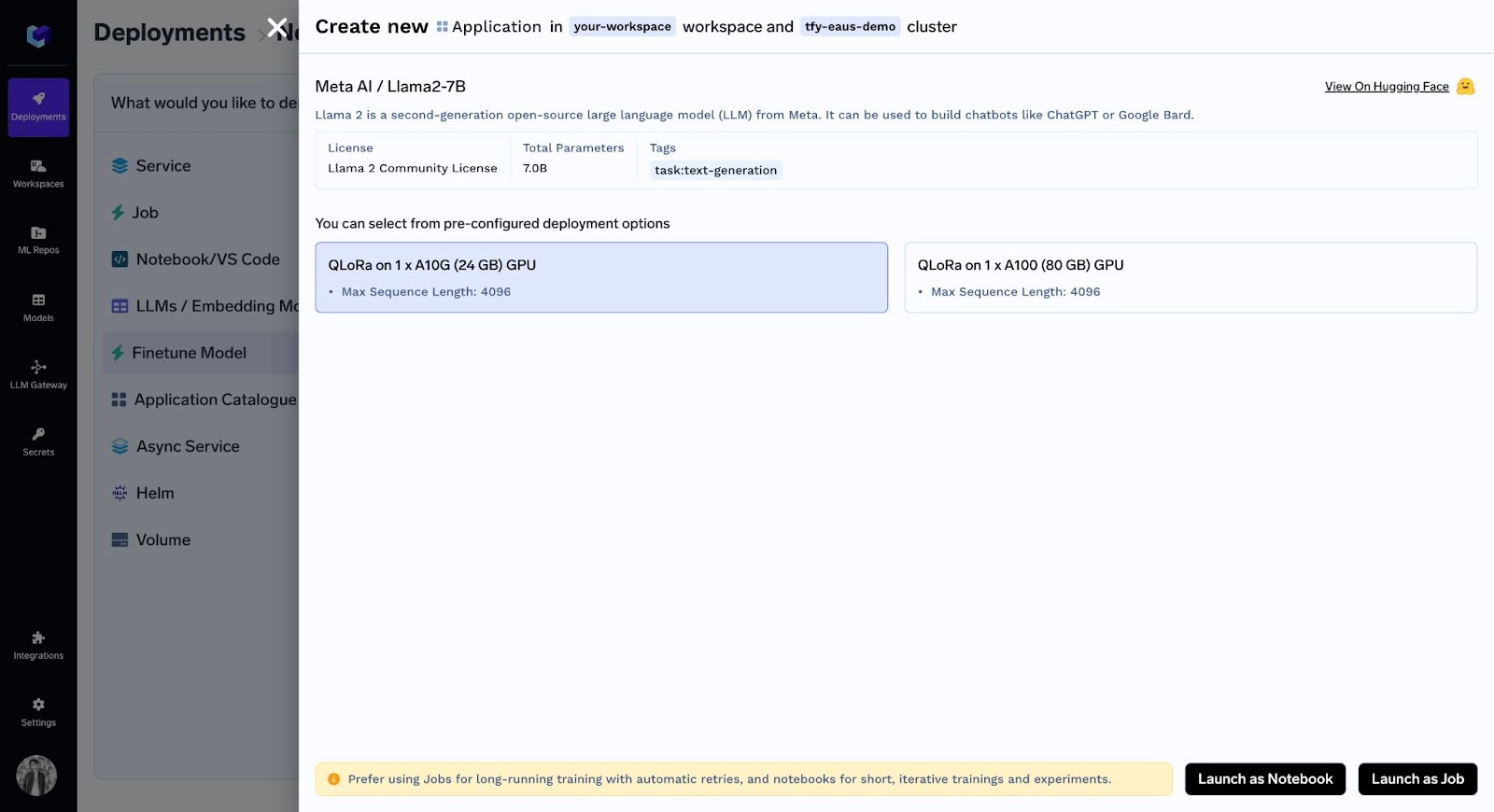
Nachdem Sie nun die gewünschte GPU ausgewählt haben, haben Sie zwei Optionen: Als Notebook ausführen oder Job.
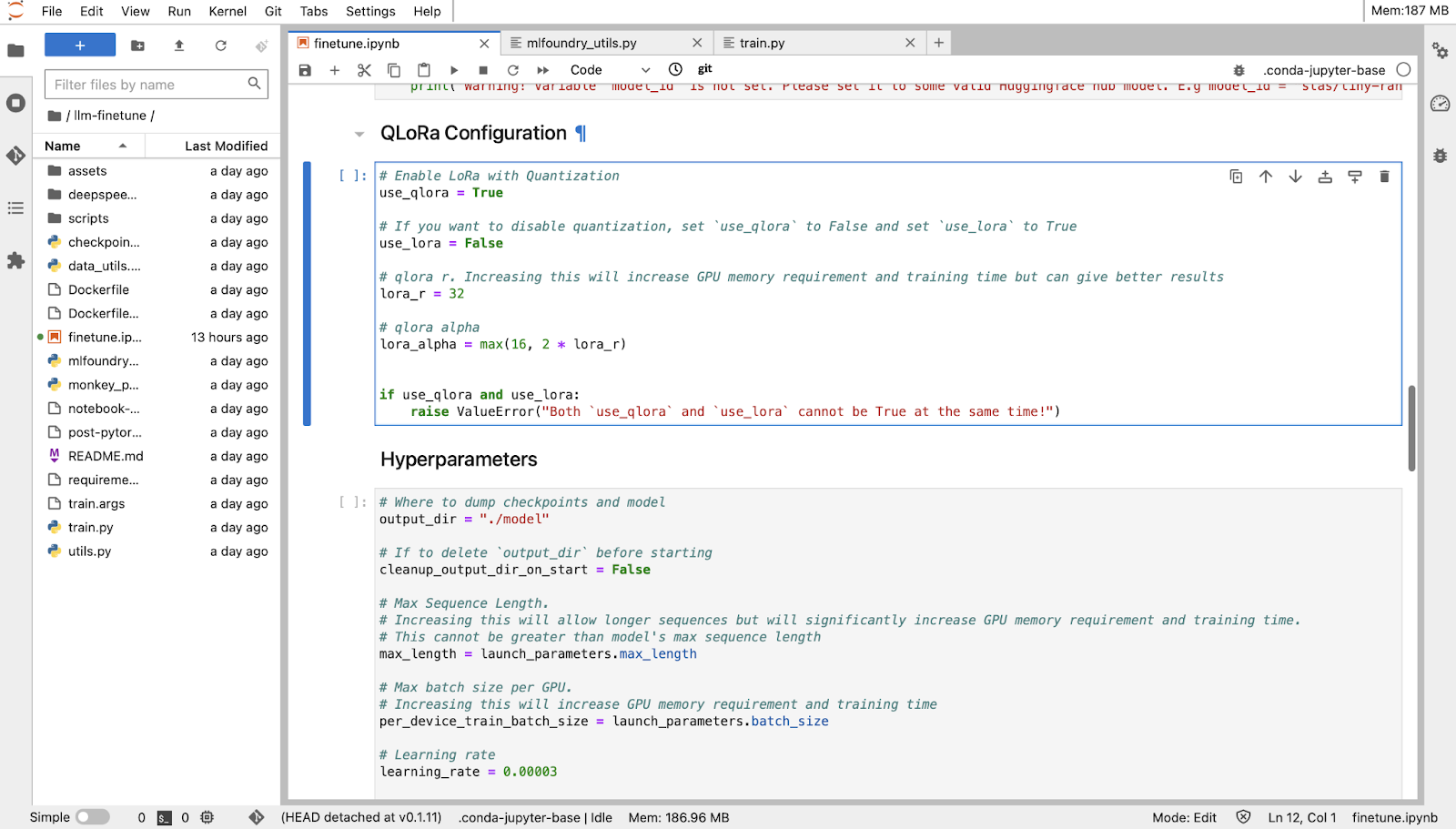
3. Feinabstimmung mit einem Notizbuch
Nachdem Sie 'Als Notizbuch starten' ausgewählt und Standardwerte für Hyperparameter ausgewählt haben, können Sie Ihr Notizbuch sehen:
4. Feinabstimmung als Beruf:
Bevor Sie beginnen, müssen Sie zunächst ein ML-Repo erstellen (dieses wird verwendet, um Ihre Trainingsmetriken und Artefakte wie Ihre Checkpoints und Modelle zu speichern) und Ihrem Workspace Zugriff auf das ML-Repo gewähren. Weitere Informationen zu ML Repos finden Sie in der Dokumentation von Truefoundry.
Jetzt müssen Sie 'Launch as Job' wählen und Standardwerte für Hyperparameter auswählen, um die Feinabstimmung zu initiieren.
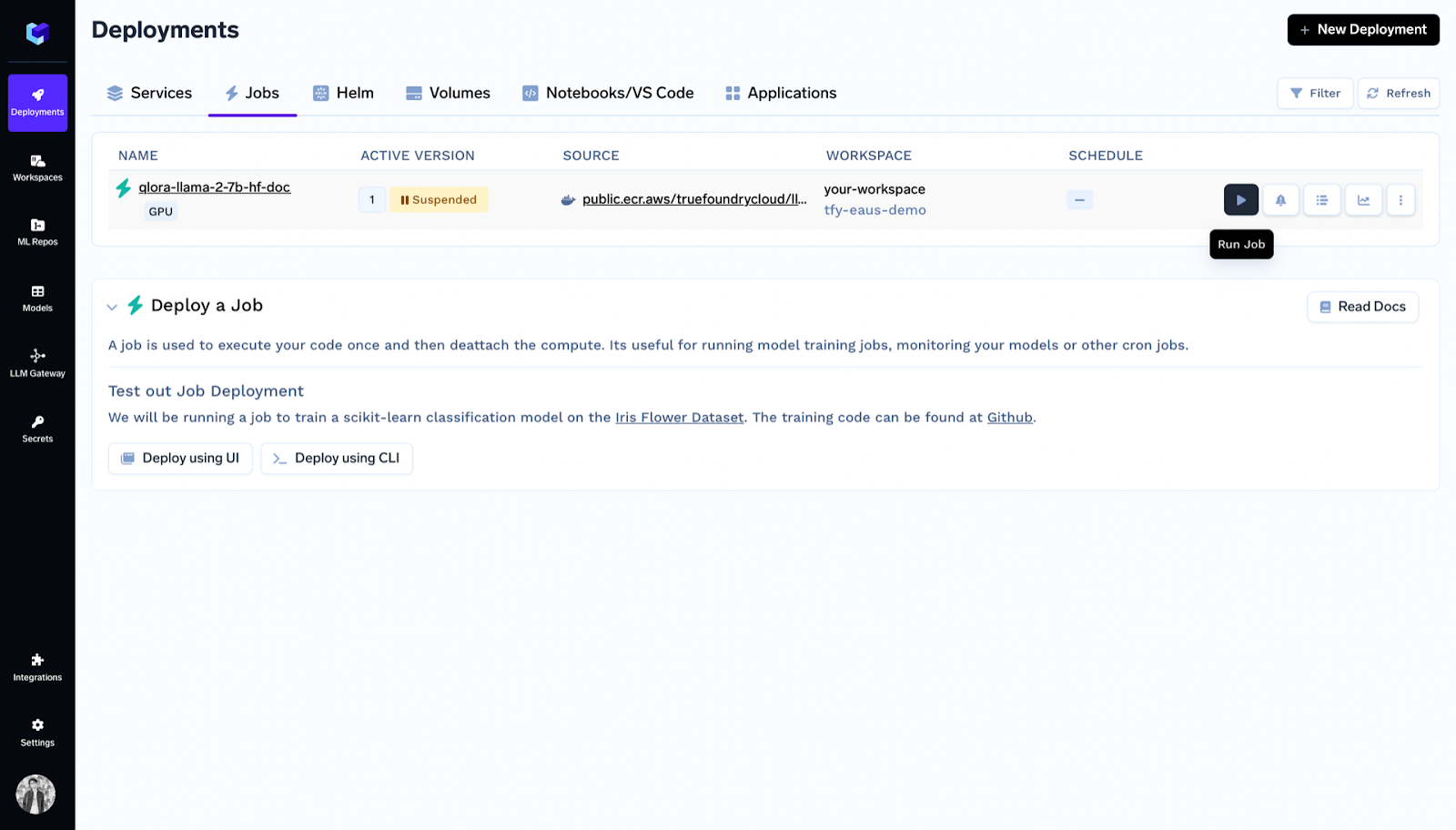
In den Bereitstellungen können Sie den Job in der Liste sehen und auf Job ausführen klicken.
Einfache Bedienung: Wählen Sie Tools aus, die einfach zu handhaben sind, insbesondere wenn Sie sich nicht mit Programmieren auskennen. Bei einigen Tools müssen Sie nicht einmal Code schreiben!
Skalierbarkeit: Stellen Sie sicher, dass das Tool mit Ihrem Projekt mitwachsen kann und größere Datensätze und komplexere Modelle reibungslos verarbeitet.
Modell- und Datensatzunterstützung: Wählen Sie Tools, die mit den spezifischen Datentypen und Modellen, die Sie verwenden, gut funktionieren.
Rechenressourcen: Suchen Sie nach Zugriff auf GPUs oder TPUs, wenn Ihr Projekt viel Rechenleistung benötigt.
Kosten: Überlegen Sie, wie viel Sie bereit sind auszugeben. Einige Tools sind kostenlos, andere richten sich nach den von Ihnen verwendeten Ressourcen.
Individualisierbarkeit und Kontrolle: Wenn Sie sich mit Code auskennen, bevorzugen Sie möglicherweise Tools, mit denen Sie alles optimieren können.
Integration: Es ist einfacher, wenn sich das Tool nahtlos in Ihren bestehenden Arbeitsablauf und Ihre Tools einfügt.
Community und Support: Eine unterstützende Community und eine gute Dokumentation können Ihnen viele Kopfschmerzen ersparen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


