



July 20, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Große Sprachmodelle (LLMs) werden immer leistungsfähiger und werden für eine Vielzahl von Aufgaben verwendet, darunter Chatbots, Textgenerierung und Beantwortung von Fragen. Die Schulung von LLMs kann jedoch teuer und ressourcenintensiv sein. In diesem Blogbeitrag zeigen wir Ihnen, wie Sie ein kleineres LLM (7B) so einstellen, dass es besser abschneidet als ChatGPT.
Feinabstimmung ist ein Prozess, bei dem ein LLM an einem bestimmten Datensatz trainiert wird, um seine Leistung bei einer bestimmten Aufgabe zu verbessern. In diesem Fall nehmen wir eine Feinabstimmung eines 7B-LLM vor, um zwei Zahlen zu multiplizieren.
Beginnen wir also mit der Leistung verschiedener großer Sprachmodelle bei einer einfachen Multiplikationsaufgabe: 458*987 = 452046.
Zunächst schauen wir uns Metas kürzlich veröffentlichtes Modell Llama-2-7B an. Wir haben Lllama-2 auf TrueFoundry bereitgestellt und es mit den Langchain-Integrationen von TrueFoundry ausprobiert. Hier ist das Ergebnis für dasselbe.
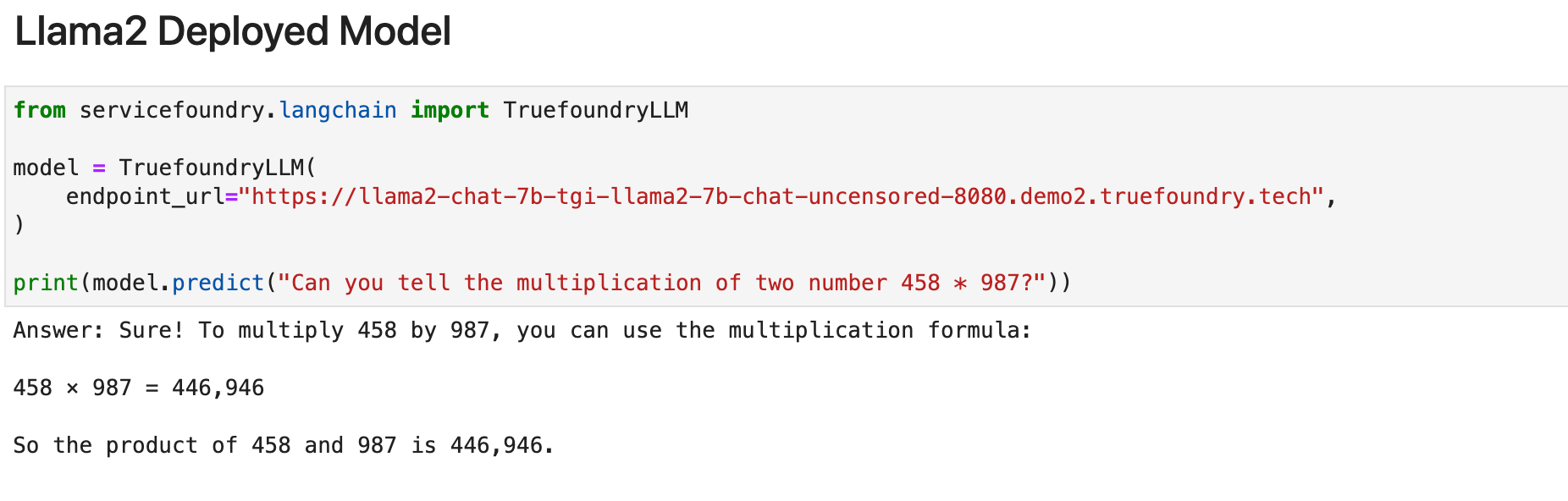
Wie wir deutlich sehen können, funktioniert das bei der Aufgabe nicht gut. (was angesichts der Größe des Modells auch erwartet wird). Lassen Sie uns sehen, wie die Modelle auf dem neuesten Stand der Technik bei derselben Aufgabe abschneiden:
Schauen wir uns das Ergebnis von ChatGPT (GPT3.5 Turbo) an:
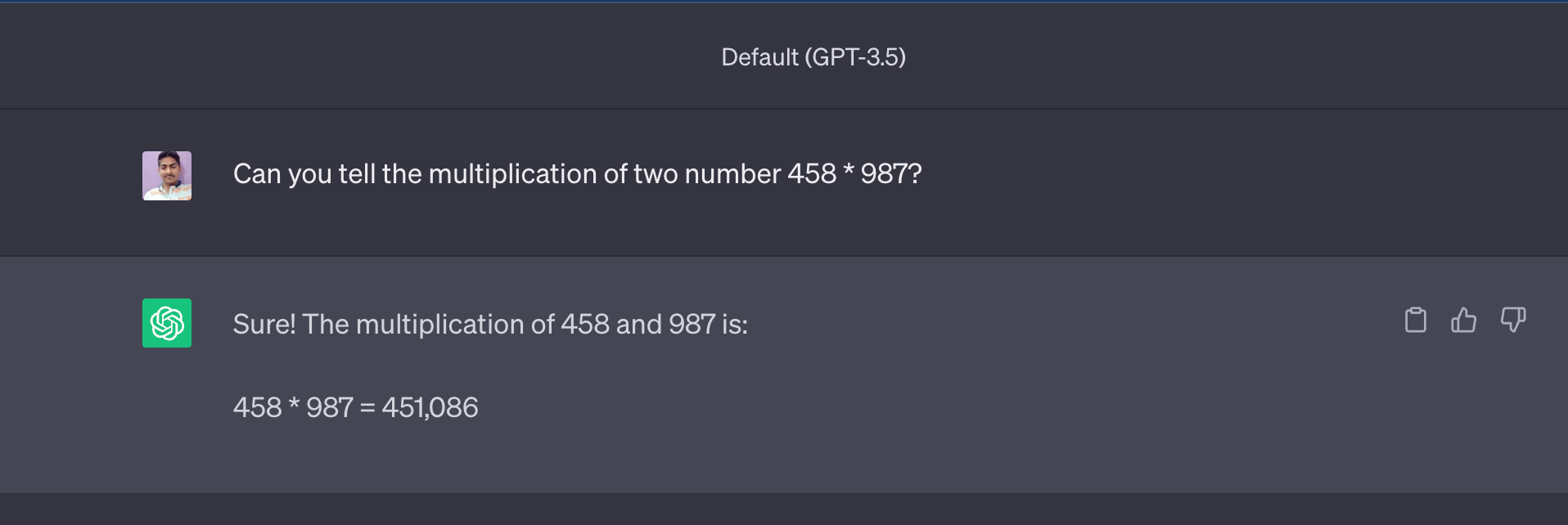
Jetzt liegt die Antwort (451.086) sehr nahe an der tatsächlichen Antwort, die 452.046 lautet, aber die Antwort ist nicht korrekt.
Versuchen wir es mit einer anderen Aufforderung (um eine schrittweise Berechnung durchzuführen und zu sehen, was sie bewirkt):
0:00 /1×
ChatGPT mit benutzerdefinierter Aufforderung zur Multiplikation
Aber auch hier kommt es zu einem falschen Ergebnis: 450.606 🤨
Lassen Sie uns abschließend den State of the Art (GPT-4) ausprobieren und überprüfen, wie er bei der Aufgabe abschneidet:

Es ist sehr nah an der richtigen Antwort (452.046) und könnte für jeden richtig aussehen. Aber die Antwort ist eindeutig falsch.
Die Antwort auf diese Frage ist sehr einfach. Sie sind nicht dafür „trainiert“.
LLMs werden mit riesigen Text- und Code-Datensätzen trainiert, aber diese Daten sind nicht immer so strukturiert, dass sie für mathematische Überlegungen hilfreich sind. Beispielsweise enthalten die Daten möglicherweise keine expliziten Darstellungen mathematischer Konzepte wie Addition, Subtraktion, Multiplikation und Division. Dies kann es für LLMs schwierig machen, zu lernen, wie diese Operationen korrekt ausgeführt werden.
Also dachten wir, ob es möglich ist, einen LLM für die Durchführung mathematischer Operationen auszubilden? Wir haben ein Experiment gemacht und die Ergebnisse waren ziemlich vielversprechend!
Zunächst haben wir einen Datensatz mit 40.000 Zeilen mit Aufforderungen und Anweisungen kuratiert. Wir haben versucht, die genauen Schritte nachzuahmen, die bei der langen Multiplikationsmethode befolgt werden. Dabei werden der Multiplikand und der Multiplikator in ihre einzelnen Ziffern zerlegt, dann jede Ziffer des Multiplikanten mit jeder Ziffer des Multiplikators multipliziert und die Ergebnisse auf der Grundlage ihrer Platzwerte an den entsprechenden Positionen platziert. Schließlich werden alle einzelnen Produkte zusammengezählt, um das Endergebnis zu erhalten.
Hier ist ein Beispiel für eine Eingabeaufforderung:
Sie sind ein hilfreicher Assistent, der detaillierte Antworten auf Multiplikationsfragen gibt. Stellen Sie sicher, dass Sie die unten angegebene mathematische Aufgabe mithilfe der langen Multiplikationsmethode gründlich erklären.
Wenn Sie die Antwort auf eine Frage nicht kennen, teilen Sie uns bitte keine falschen Informationen mit. Was ist 5244 * 1932?
Und hier ist eine Beispielantwort:
Hier sind die Schritte zum Multiplizieren von 5244 * 1932 mit der langen Multiplikationsmethode.
Schritt 1: Brechen Sie 5244 in seine einzelnen Ziffern auf: 5 (Tausenderstelle), 2 (Hundertstelle), 4 (Zehnerstelle) und 4 (Einsstelle).
Schritt 2: Teilen Sie 1932 auf ähnliche Weise in seine einzelnen Ziffern auf: 1 (Tausenderstelle), 9 (Hundertstelle), 3 (Zehnerstelle) und 2 (Einsstelle).
- 4 (ab 1 Stelle der ersten Zahl) * 2 (ab 1 Stelle der zweiten Zahl) = 8 -> Verschiebe es um 0 Stellen nach links (weil wir mit der ersten Stelle der zweiten Zahl multiplizieren), um 8 zu erhalten
- 4 (ab 1 Stelle der ersten Zahl) * 3 (ab 10 Stelle der zweiten Zahl) = 12 -> Verschiebe es um 1 Stelle nach links (weil wir mit der 10-Stelle der zweiten Zahl multiplizieren), um 120 zu erhalten
- 4 (ab 1 Stelle der ersten Zahl) * 9 (ab 100 Stelle der zweiten Zahl) = 36 -> Verschiebe es 2 Stellen nach links (weil wir mit der 100-Stelle der zweiten Zahl multiplizieren), um 3600 zu erhalten
- 4 (ab 1 Stelle der ersten Zahl) * 1 (ab 1000 Stelle der zweiten Zahl) = 4 -> Verschiebe es um 3 Stellen nach links (weil wir mit der 1000-Stelle der zweiten Zahl multiplizieren), um 4000 zu erhalten
- 4 (ab 10 Stelle der ersten Zahl) * 2 (ab 1 Stelle der zweiten Zahl) = 8 -> Verschiebe sie um 1 Stelle nach links (weil wir mit der ersten Stelle der zweiten Zahl multiplizieren), um 80 zu erhalten
- 4 (ab 10 Stelle der ersten Zahl) * 3 (ab 10 Stelle der zweiten Zahl) = 12 -> Verschiebe es 2 Stellen nach links (weil wir mit der 10-Stelle der zweiten Zahl multiplizieren), um 1200 zu erhalten
- 4 (ab 10 Stelle der ersten Zahl) * 9 (ab 100 Stelle der zweiten Zahl) = 36 -> Verschiebe es um 3 Stellen nach links (weil wir mit der 100-Stelle der zweiten Zahl multiplizieren), um 36000 zu erhalten
- 4 (ab 10 Stelle der ersten Zahl) * 1 (ab 1000 Stelle der zweiten Zahl) = 4 -> Verschiebe es um 4 Stellen nach links (weil wir mit der 1000-Stelle der zweiten Zahl multiplizieren), um 40000 zu erhalten
- 2 (ab 100 Stelle der ersten Zahl) * 2 (ab 1 Stelle der zweiten Zahl) = 4 -> Verschiebe es um 2 Stellen nach links (weil wir mit der ersten Stelle der zweiten Zahl multiplizieren), um 400 zu erhalten
- 2 (ab 100 Stelle der ersten Zahl) * 3 (ab 10 Stelle der zweiten Zahl) = 6 -> Verschiebe es um 3 Stellen nach links (weil wir mit der 10-Stelle der zweiten Zahl multiplizieren), um 6000 zu erhalten
- 2 (ab 100 Stelle der ersten Zahl) * 9 (ab 100 Stelle der zweiten Zahl) = 18 -> Verschiebe es um 4 Stellen nach links (weil wir mit der 100-Stelle der zweiten Zahl multiplizieren), um 180000 zu erhalten
- 2 (ab 100 Stelle der ersten Zahl) * 1 (ab 1000 Stelle der zweiten Zahl) = 2 -> Verschiebe sie um 5 Stellen nach links (weil wir mit der 1000-Stelle der zweiten Zahl multiplizieren), um 200000 zu erhalten
- 5 (ab 1000 Stelle der ersten Zahl) * 2 (ab 1 Stelle der zweiten Zahl) = 10 -> Verschiebe es um 3 Stellen nach links (weil wir mit der ersten Stelle der zweiten Zahl multiplizieren), um 10000 zu erhalten
- 5 (ab 1000 Stelle der ersten Zahl) * 3 (ab 10 Stelle der zweiten Zahl) = 15 -> Verschiebe es um 4 Stellen nach links (weil wir mit der 10-Stelle der zweiten Zahl multiplizieren), um 150000 zu erhalten
- 5 (ab 1000 Stelle der ersten Zahl) * 9 (ab 100 Stelle der zweiten Zahl) = 45 -> Verschiebe es um 5 Stellen nach links (weil wir mit der 100-Stelle der zweiten Zahl multiplizieren), um 4500000 zu erhalten
- 5 (ab 1000 Stelle der ersten Zahl) * 1 (ab 1000 Stelle der zweiten Zahl) = 5 -> Verschiebe es um 6 Stellen nach links (weil wir mit der 1000-Stelle der zweiten Zahl multiplizieren), um 5000000 zu erhalten
Addieren Sie nun all diese Ergebnisse zusammen:
Die Summe von 8 + 120 + 3600 + 4000 + 80 + 1200 + 36000 + 40000 + 400 + 6000 + 180000 + 200000 + 10000 + 150000 + 4500000 + 5000000 = 10131408.
Dann haben wir ein Python-Skript geschrieben, das Prompt-Response-Paare generiert, indem zwei Ziffern zufällig für die Multiplikation ausgewählt werden. Wir haben einen Datensatz mit 40.000 Zeilen kuratiert.
Sobald der Datensatz fertig ist, müssen wir das Modell verfeinern.
Wir verwenden die Meta - die fein abgestimmte Chat-Variante (7 Milliarden Parameter) von Lama-2 als Basismodell.
Wir haben die Feinabstimmung durchgeführt mit QLora Feinabstimmung mit BitsAndBytes und der Peft-Bibliothek. Hier ist die Lora-Konfiguration, die wir verwendet haben:
Lora-Konfiguration (
lora_alpha=16,
lora_dropout=0,1,
r = 64,
bias="none“,
task_type= „Causal_LM“,
Zielmodule= [
„q_proj“,
„k_proj“,
„v_proj“,
„o_proj“,
],
)
Das Training auf einem A100-GB-GPU-Computer für einen Datensatz mit 40.000 Zeilen dauerte etwa 8 Stunden.
Schließlich haben wir das fein abgestimmte Modell auf Wahre Gießerei nochmal und hier sind die Ergebnisse:
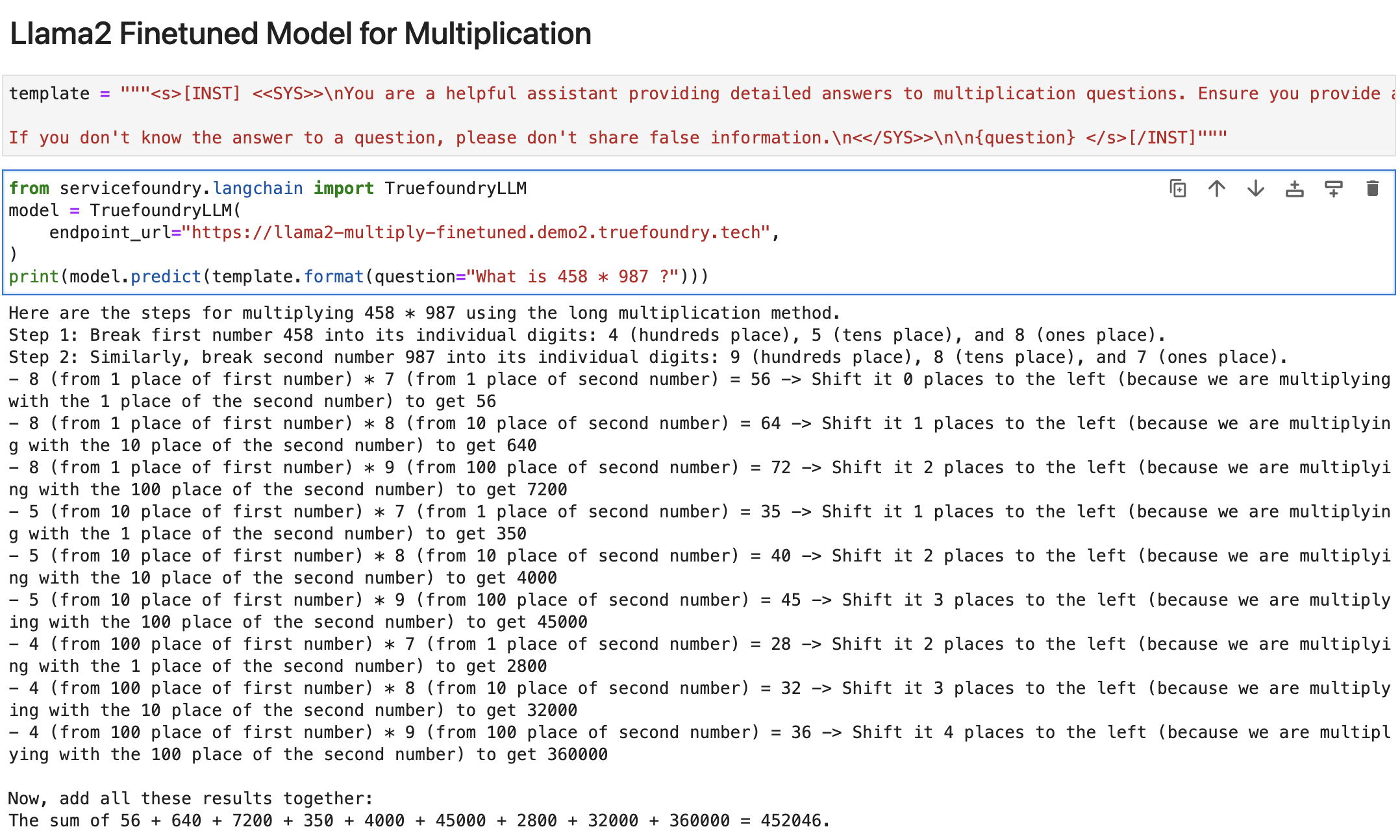
Also endlich!! Wir können sehen, dass das fein abgestimmte Modell in der Lage ist, das Ergebnis korrekt zu berechnen.
Arithmetik ist zwar keine Aufgabe, für die wir LLM verwenden werden, aber dieses Beispiel zeigt, wie ein „kleines“ LLM (7B-Parameter), das für eine bestimmte Aufgabe richtig abgestimmt ist, die „großen“ LLMs (wie GPT3.5 Turbo — 175B-Parameter und GPT-4) bei einer bestimmten Aufgabe übertreffen kann.
Die kleineren Modelle mit fein abgestimmten Modellen sind billig in der Inferenz, eignen sich besser für spezielle Aufgaben und können problemlos in Ihrer eigenen Cloud bereitgestellt werden!
Wir haben einen ausführlichen Blog über die Feinabstimmung von Llama 2 geschrieben
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.









.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




