

July 1, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Large Language Models (LLMs) sind weit über experimentelle Chatbots und öffentliche Demos hinausgegangen; sie unterstützen jetzt unternehmenskritische Workflows im Unternehmen. Von der Automatisierung der internen Wissenssuche über die Generierung von Berichten bis hin zur Verbesserung des Kundensupports und der Sicherstellung der Einhaltung gesetzlicher Vorschriften verändern LLMs die Art und Weise, wie moderne Unternehmen arbeiten. Die Bereitstellung von LLMs in Unternehmensumgebungen ist jedoch nicht so einfach wie das Anschließen an eine API. Es erfordert Governance, Beobachtbarkeit, Datenschutzmaßnahmen und eine maßgeschneiderte Infrastruktur. In diesem Leitfaden wird die sich entwickelnde Landschaft der LLMs in Unternehmen untersucht. Dabei werden die wichtigsten Herausforderungen, Bereitstellungsmodelle, bewährte Methoden für die Überwachung und die Frage behandelt, wie Plattformen wie TrueFoundry die sichere, skalierbare Einführung von LLMs in allen Branchen ermöglichen.
Der Hype um LLMs hat eine Welle der Akzeptanz ausgelöst, aber für Unternehmen besteht die eigentliche Herausforderung nicht darin, auffällige Reaktionen hervorzurufen. Es geht darum, diese Modelle intelligent und verantwortungsbewusst einzusetzen. Ein echtes Enterprise LLM ist nicht nur ChatGPT mit einem Business Wrapper. Es ist ein System, das auf Ihren firmeneigenen Daten basiert, für Ihre Workflows optimiert ist und unter Berücksichtigung Ihrer Compliance-, Kosten- und Kontrollanforderungen eingesetzt wird.
Die meisten öffentlichen LLMs werden mit offenen Internetdaten geschult. Das macht sie leistungsstark im allgemeinen sprachlichen Denken, aber unzuverlässig, wenn sie in unternehmensspezifischen Kontexten angewendet werden, insbesondere wenn es auf Genauigkeit, Rückverfolgbarkeit und Sicherheit ankommt. Beispielsweise kann sich ein Finanzdienstleistungsunternehmen keine halluzinierten Fakten, vage Haftungsausschlüsse oder unvorhersehbare Reaktionen leisten. Was sie brauchen, ist ein Modell, das domänenspezifisch, überprüfbar und hinter Firewalls einsetzbar ist. Dies wird häufig mit Retrieval-Augmented Generation (RAG) kombiniert, sodass das System interne Dokumente analysieren kann und nicht nur das, wofür es vorab trainiert wurde.
LLMs für Unternehmen entwickeln sich zu internen Copiloten. Rechtsteams verwenden sie, um Verträge zu entwerfen, HR-Teams, um Mitarbeiteranfragen zu beantworten, Entwickler, um den Code zu beschleunigen, und Support-Teams, um Tickets schneller zusammenzufassen und zu lösen. Diese Ergebnisse sind jedoch nur möglich, wenn das LLM gut integriert ist, in der Produktion überwacht und auf die Datengrenzen des Unternehmens abgestimmt ist.
Dieser Wandel signalisiert auch eine philosophische Entwicklung. Wir betrachten LLMs nicht mehr als magische Blackboxen, sondern als modulare KI-Systeme, bei denen Orchestrierung, Grounding, Beobachtbarkeit und Feedback-Schleifen genauso wichtig sind wie das Basismodell selbst.
Erfolgreich implementieren LLM im Unternehmen geht es nicht nur um KI-Fähigkeiten. Es geht um die Hebelwirkung der Unternehmen. Und das erfordert ein Denken, das weit über das Modell hinausgeht und die Architektur, die Infrastruktur und das organisatorische Vertrauen berücksichtigt, von denen es abhängt.
Das Potenzial von Enterprise LLMs ist zwar enorm, aber ihr Einsatz in einer realen Geschäftsumgebung ist mit kritischen Herausforderungen verbunden, denen sich Unternehmen vom ersten Tag an stellen müssen.
Datenschutz und Sicherheit: LLMs für Unternehmen arbeiten häufig mit sensiblen internen Daten, Verträgen, Kundendatensätzen, Quellcode und Finanzdaten. Dies wirft ernsthafte Bedenken hinsichtlich Datenlecks, unbefugtem Zugriff und Nichteinhaltung gesetzlicher Vorschriften auf. Ohne strenge Zugriffskontrollen, Verschlüsselung und sofortige Bereinigung können LLM-Ausgaben unbeabsichtigt vertrauliche Informationen preisgeben.
Halluzinationen und Zuverlässigkeit: LLMs neigen dazu, selbstbewusste, aber falsche Antworten zu generieren, die auch als Halluzinationen bezeichnet werden. In einem Unternehmensumfeld kann dies zu Betriebsfehlern, rechtlichen Risiken und Vertrauensverlust führen. Aus diesem Grund ist es unerlässlich, das Modell mithilfe von RAG-Pipelines in internen Dokumenten zu verankern, um die sachliche Richtigkeit sicherzustellen.
Prompte Injektion und gegnerische Eingaben: Unternehmen müssen sich vor böswilligen oder manipulativen Eingabeaufforderungen schützen, die Filter umgehen oder unbeabsichtigte Daten extrahieren. Ohne eine angemessene Überprüfung der Eingaben und ohne entsprechende Schutzmaßnahmen können Modelle zu Vektoren für Social Engineering oder Datenlecks werden.
Kosten und Infrastrukturgemeinkosten: Die Ausführung großer Modelle auf GPUs in großem Maßstab verursacht hohe Inferenzkosten. Das ist wo LLM-Inferenz Die Strategie wird entscheidend, da Modellgröße, Batching und Hardwareauswahl direkt die Latenz und Kosteneffizienz des Unternehmens bestimmen. Unternehmen müssen Latenz, Durchsatz und Skalierung verwalten und gleichzeitig die Cloud-Ausgaben unter Kontrolle halten. Die Wahl der richtigen Modellgröße und die Optimierung von Batching, Caching und Quantisierung sind entscheidend.
Überwachung und Versionskontrolle: Im Gegensatz zu herkömmlicher Software kann das LLM-Verhalten im Laufe der Zeit subtil abweichen. Unternehmen benötigen Tools, um Eingabeaufforderungen, Ergebnisse, Antwortqualität und Nutzungstrends zu verfolgen. Mangelnde Beobachtbarkeit kann zu Modellmissbrauch, unzureichender Leistung oder Nichteinhaltung von SLAs führen.
Komplexität der Bewertung: Die Bewertung von LLMs ist nicht trivial. Es erfordert benutzerdefinierte Benchmarks, Feedback-Schleifen und aufgabenspezifische Metriken wie Relevanz, Kohärenz und Faktizität.
Jede dieser Herausforderungen erfordert einen strukturierten Ansatz, um Risiken zu minimieren und Skalierbarkeit zu ermöglichen. Ohne sie bleiben LLM-Initiativen im Prototypenmodus stecken und erreichen nie die wahre Unternehmensreife.
Unternehmen aller Branchen gehen über das Experimentieren hinaus und beginnen, LLMs in Produktionsumgebungen einzusetzen. Diese Implementierungen konzentrieren sich auf wichtige interne Anwendungsfälle, die einen messbaren ROI erzielen und gleichzeitig das Risiko minimieren können.
Wissensabruf und interne Suche
Eine der häufigsten Anwendungen ist Enterprise Search. Durch die Kombination von LLMs mit Abfragesystemen wie Vektordatenbanken ermöglichen Unternehmen ihren Mitarbeitern, interne Dokumentationen in natürlicher Sprache abzufragen. Dies verbessert den Wissenszugriff für Personal-, Rechts-, Compliance- und IT-Teams.
Automatisierung des Kundensupports
Unternehmen integrieren LLMs in die Workflows des Kundensupports. Die Modelle helfen bei der Zusammenfassung von Tickets, der E-Mail-Generierung und der Weiterleitung von Absichten. In Kombination mit historischen Supportdaten können LLMs die Reaktionszeiten erheblich verkürzen und die Kundenzufriedenheit verbessern.
Zusammenfassung und Klassifizierung von Dokumenten
LLMs werden verwendet, um lange Berichte, Verträge oder Transkripte zu analysieren und zusammenzufassen. Unternehmen in den Bereichen Recht, Finanzen und Gesundheitswesen profitieren von der automatisierten Dokumentenverarbeitung, die den Zeitaufwand für die manuelle Überprüfung reduziert und die Entscheidungsfindung beschleunigt.
Produktivität von Entwicklern
Technische Teams setzen codeorientierte LLMs ein, um die Softwareentwicklung zu beschleunigen. Interne Copiloten schlagen Codefragmente vor, identifizieren Fehler und generieren die Dokumentation auf der Grundlage interner Repositorys. Dies erhöht die Geschwindigkeit der Entwicklung, ohne die Sicherheit zu gefährden.
Domänenspezifische Assistenten
Einige Organisationen entwickeln LLM-basierte Assistenten, die auf bestimmte Arbeitsabläufe zugeschnitten sind. Versicherungsunternehmen verwenden beispielsweise Modelle, die anhand von Schadensdaten trainiert wurden, um Auffälligkeiten zu kennzeichnen oder Formulare vorab auszufüllen. Beratungsunternehmen verwenden LLMs, um Forschungsberichte auf der Grundlage ihrer firmeneigenen Datenbanken zu erstellen.
Beispiele aus der Praxis sind die interne Nutzung von StarCoder durch VMware für technische Zwecke, der Enterprise LLM Workspace der US Army für den Zugriff auf Dokumente und die KI-gestützte Unternehmenssuchplattform von Glean.
Was erfolgreiche Implementierungen vereint, ist nicht nur das Modell, sondern auch die Integration mit internen Daten, Tools und Governance-Praktiken. Dies sind keine Lösungen von der Stange. Es handelt sich um maßgeschneiderte Systeme, die speziell für Unternehmen entwickelt wurden.
Eine der wichtigsten architektonischen Entscheidungen für jede LLM-Initiative in Unternehmen ist, wo das Modell eingesetzt werden soll. Sowohl lokale als auch cloudbasierte Bereitstellungen bieten je nach den Prioritäten, Einschränkungen und regulatorischen Rahmenbedingungen des Unternehmens unterschiedliche Vorteile.
Bereitstellung vor Ort
Unternehmen mit strikter Datenverwaltung, z. B. im Gesundheitswesen, im Finanzwesen oder in Behörden, entscheiden sich häufig für Bereitstellungen vor Ort. Diese gewährleisten die volle Kontrolle über sensible Daten und ermöglichen die Einhaltung interner Richtlinien und externer Vorschriften. Lokale Setups reduzieren auch die Abhängigkeit von der Infrastruktur von Drittanbietern und ermöglichen eine Leistungsoptimierung auf Hardwareebene. Sie erfordern jedoch erhebliche Investitionen in GPUs, DevOps-Fachwissen und laufende Wartung. Modellaktualisierungen, Patches und Skalieren werden zu internen Verantwortlichkeiten, die Innovationen verlangsamen können, wenn nicht ausreichend Ressourcen zur Verfügung stehen.
Cloud-Bereitstellung
Cloud-basierte LLMs lassen sich schneller einführen und einfacher skalieren. Anbieter wie OpenAI, AWS Bedrock, Google Cloud und Azure bieten verwaltete APIs mit sofortigem Zugriff auf modernste Modelle. Diese Dienste reduzieren den betrieblichen Aufwand und beschleunigen die Amortisierungszeit, insbesondere in frühen Testphasen. Sie sind jedoch mit Bedenken hinsichtlich des Datenschutzes, der Anbieterbindung und der wiederkehrenden Kosten verbunden. Für viele Unternehmen ist das Senden proprietärer Daten an externe Endgeräte ein Kinderspiel, es sei denn, es werden strenge Verschlüsselungs-, Anonymisierungs- und Zugriffsrichtlinien durchgesetzt.
Hybrid- und VPC-Lösungen
Ein wachsender Trend ist die hybride Bereitstellung, bei der Inferenz in einer Virtual Private Cloud (VPC) -Umgebung ausgeführt wird. Dadurch wird die Flexibilität der Cloud mit der Sicherheit einer isolierten Infrastruktur in Einklang gebracht. Plattformen wie TrueFoundry und Hugging Face unterstützen das private Hosting von Open-Source-Modellen in vom Unternehmen kontrollierten Umgebungen und bieten das Beste aus beiden Welten.
Die Wahl des richtigen Bereitstellungsmodells ist nicht nur eine technische Entscheidung. Es wirkt sich direkt auf die Einhaltung der Vorschriften, die Leistung und die langfristigen Kosten aus. Unternehmen müssen ihre Anwendungsfälle, ihre Risikotoleranz und den Reifegrad ihrer Infrastruktur bewerten, bevor sie sich auf einen Weg festlegen.
Die Überwachung von LLMs in Unternehmensumgebungen unterscheidet sich grundlegend von der Überwachung herkömmlicher Modelle für maschinelles Lernen. LLMs sind probabilistisch, nicht deterministisch und in hohem Maße kontextsensitiv. Ohne angemessene Beobachtbarkeit kann ihr Verhalten im Hintergrund driften, falsche Ergebnisse erzeugen oder Risiken mit sich bringen, ohne dass ein Hinweis auf einen Ausfall des Systems vorliegt.
Prompt Tracing und Versionierung: Unternehmen müssen jede Interaktion zwischen Benutzern und dem LLM verfolgen, einschließlich der genauen Struktur der Eingabeaufforderung, der Systemmeldung und des Kontextfensters. Beobachtbarkeit beginnt mit der vollständigen Rückverfolgbarkeit. Durch die Protokollierung von Vorlagen für Eingabeaufforderungen, Modellversionen, Temperatureinstellungen und Eingabe-Ausgabe-Paaren können Teams die Ergebnisse später reproduzieren und analysieren.
Bewertung der Ergebnisse und Solidität: Die Überwachung der sachlichen Richtigkeit und Relevanz der LLM-Antworten ist von entscheidender Bedeutung. Unternehmen sollten automatische Überprüfungen auf Halluzinationen einrichten, beispielsweise indem sie die Ergebnisse anhand bekannter interner Dokumente validieren oder mithilfe von RAG-Pipelines die Quellenangabe erzwingen. Die Bewertung der Ergebnisse anhand von Bewertungsrubriken wie Nützlichkeit, Richtigkeit und Vollständigkeit verleiht der Überwachung Struktur.
Latenz und Token-Nutzung: Während Infrastrukturkennzahlen an anderer Stelle behandelt werden, umfasst die Beobachtbarkeit auf der LLM-Ebene die Eingabegröße des Tracking-Tokens, die Ausgabelänge und den gesamten Token-Verbrauch. Diese Metriken wirken sich direkt auf die Reaktionszeit und die Kosten aus. Token-Spitzen können auf zeitnahe technische Probleme oder Missbrauch hinweisen.
Erkennung schädlicher oder unsicherer Ausgänge: LLMs können eine voreingenommene, beleidigende oder nicht konforme Sprache erzeugen, wenn die Leitplanken versagen. Unternehmen sollten die Ergebnisse mithilfe von Mustervergleichern oder Klassifikatoren auf sensible Begriffe, Tonverstöße oder Datenlecks überwachen. Rote Teams und kontradiktorische Tests können blinde Flecken aufdecken.
Integration der Feedback-Schleife: Das Feedback der Benutzer ist von entscheidender Bedeutung. Unternehmen müssen Korrekturen, Unzufriedenheitssignale und Bewertungen erfassen. Diese Signale fließen in die schnelle Verfeinerung, RAG-Aktualisierungen und die Feinabstimmung des Modells ein.
Ohne gezielte Beobachtbarkeit verhalten sich LLMs wie Blackboxen. Bei ordnungsgemäßer Überwachung werden sie zu transparenten Systemen, denen Unternehmen vertrauen, die sie überprüfen und kontinuierlich verbessern können.
TrueFoundry wurde speziell entwickelt, um Unternehmen bei der Bereitstellung, Verwaltung und Skalierung von LLM-Anwendungen mit der Kontrolle, Sicherheit und Leistung zu unterstützen, die Produktionsumgebungen erfordern. Im Gegensatz zu generischen KI-Plattformen konzentriert sich TrueFoundry auf eine modulare, produktionsreife KI-Infrastruktur, die in die Cloud-, lokale oder hybride Umgebung eines Unternehmens passt.
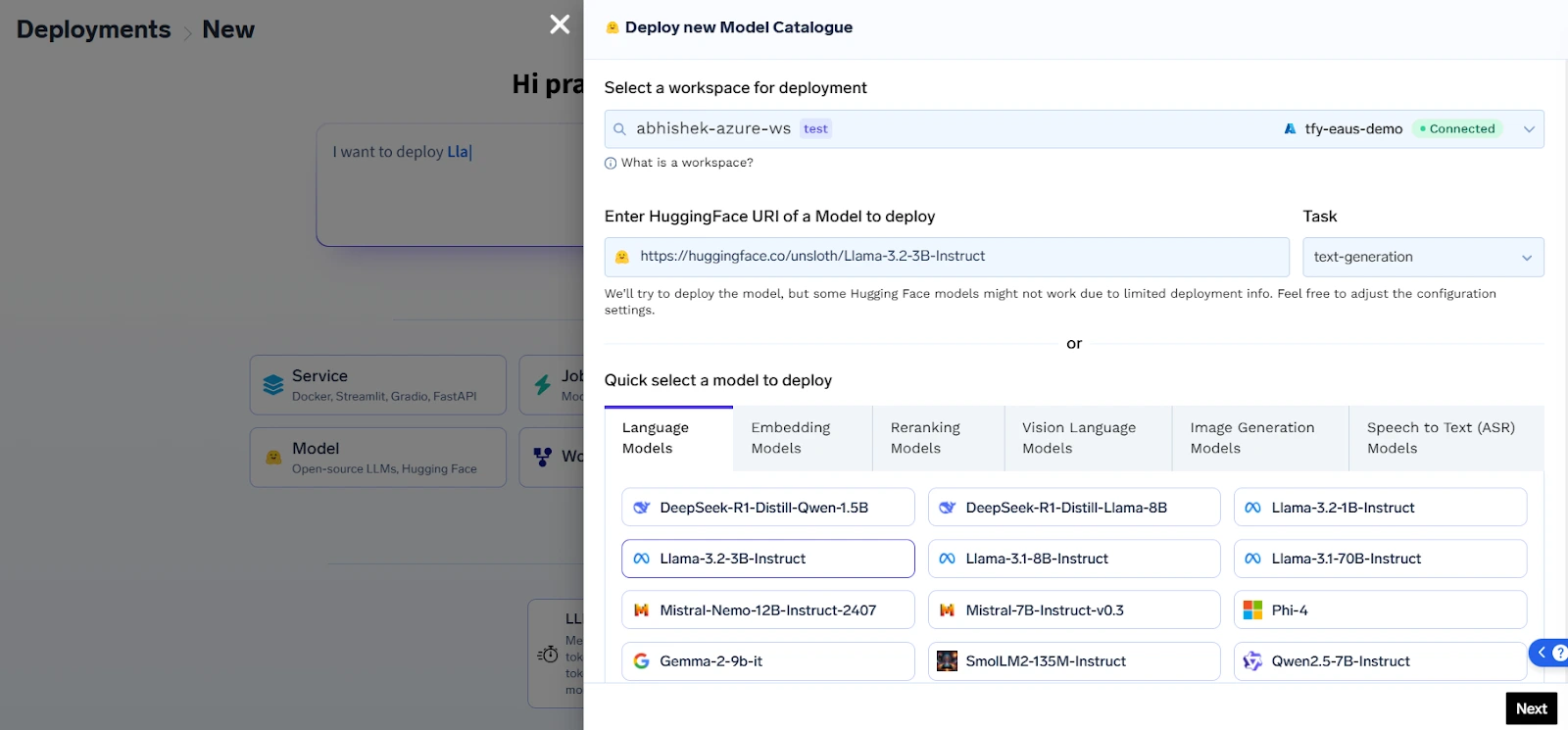
Das Herzstück des Angebots ist eine Kubernetes-native KI-Infrastrukturebene, die es Teams ermöglicht, sowohl proprietäre als auch Open-Source-LLMs wie LLama, Mistral, Falcon und GPT-J mit vollständiger Kontrolle über Hosting, Netzwerk und Sicherheit bereitzustellen. Dadurch wird sichergestellt, dass sensible Unternehmensdaten innerhalb der Unternehmensgrenzen bleiben, unabhängig davon, ob sie in einer privaten Cloud oder einem lokalen Rechenzentrum bereitgestellt werden.
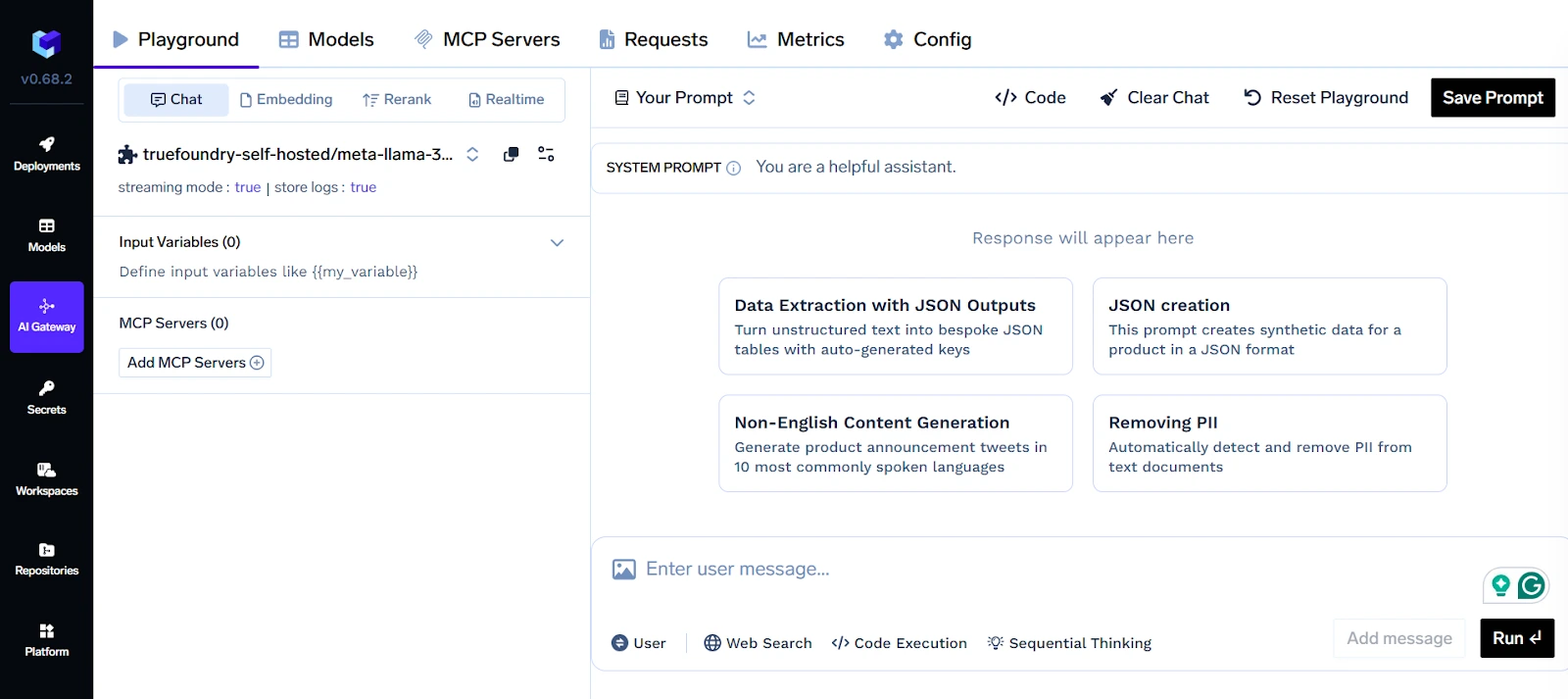
Für Unternehmen, die mehrere LLM-Anbieter verwenden (z. B. OpenAI, Anthropic, Cohere), bietet TrueFoundry ein Unified LLM Gateway. Diese Abstraktionsebene ermöglicht es Teams, zwischen Anbietern zu wechseln oder den Datenverkehr intelligent weiterzuleiten, je nach Kosten-, Latenz- oder Compliance-Anforderungen. Sie unterstützt auch Fallback- und Multimodell-Strategien, die für die Zuverlässigkeit in Produktionsumgebungen unerlässlich sind.
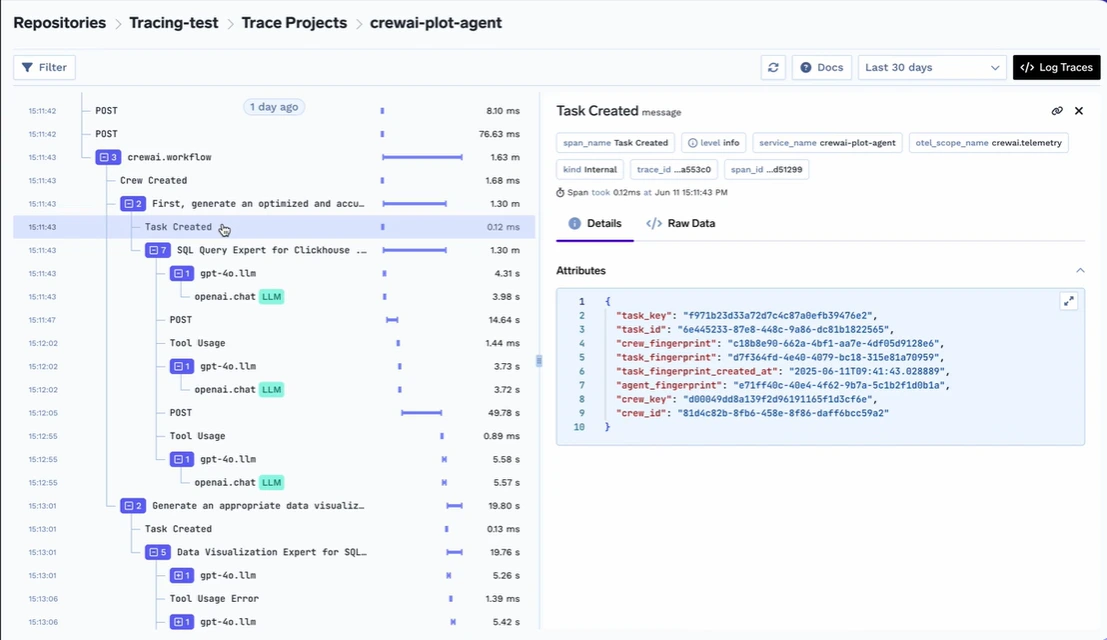
Um Vertrauen und Beobachtbarkeit zu gewährleisten, bietet TrueFoundry umfassende Überwachungs- und Analysefunktionen auf Prompt- und Reaktionsebene und fungiert als zentrale Ebene neben dem Unternehmen. LLM-Beobachtbarkeitstools. Unternehmen können verfolgen, welche Eingabeaufforderungen verwendet werden, wie sich Modelle im Laufe der Zeit verhalten und wie viel Latenz oder Kosten mit jeder Anfrage verbunden sind. Dies ist für Debugging, Compliance-Audits und Leistungsoptimierung von entscheidender Bedeutung.
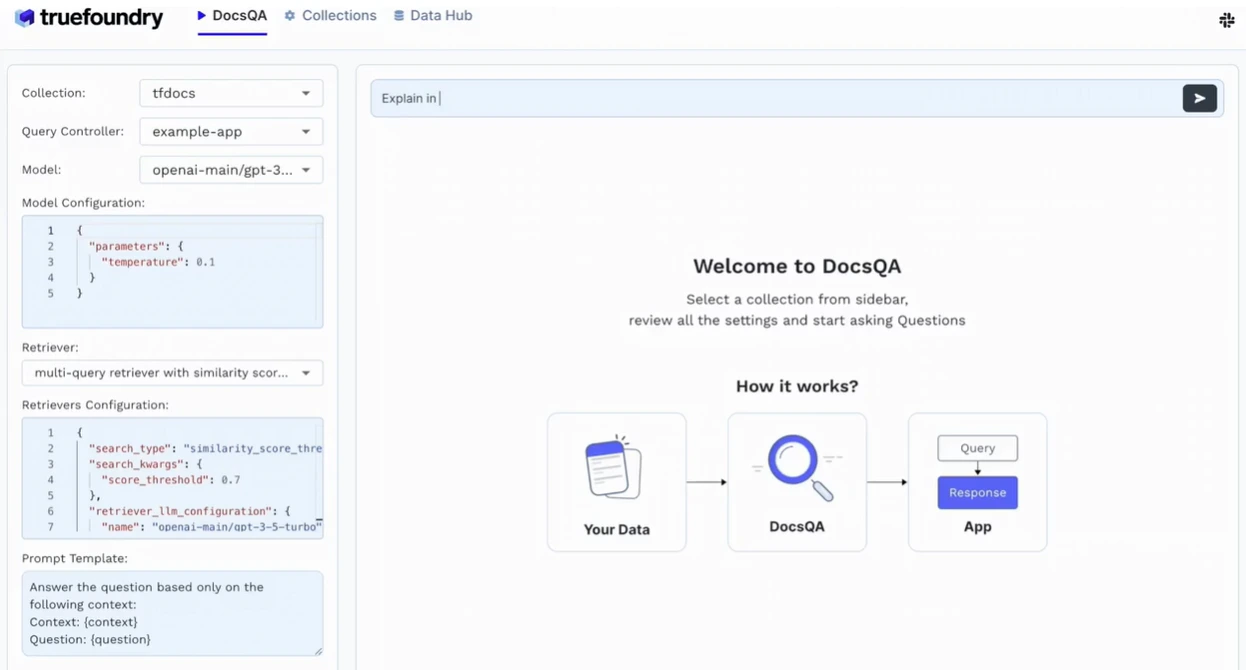
TrueFoundry unterstützt außerdem standardmäßig RAG (Retrieval-Augmented Generation), sodass Unternehmen LLM-Antworten in ihrem internen Wissen verankern können. Es lässt sich in beliebte Vektorspeicher wie Weaviate, Pinecone und Qdrant integrieren und ermöglicht so genaue, kontextsensitive Antworten, ohne die Basismodelle neu trainieren zu müssen.
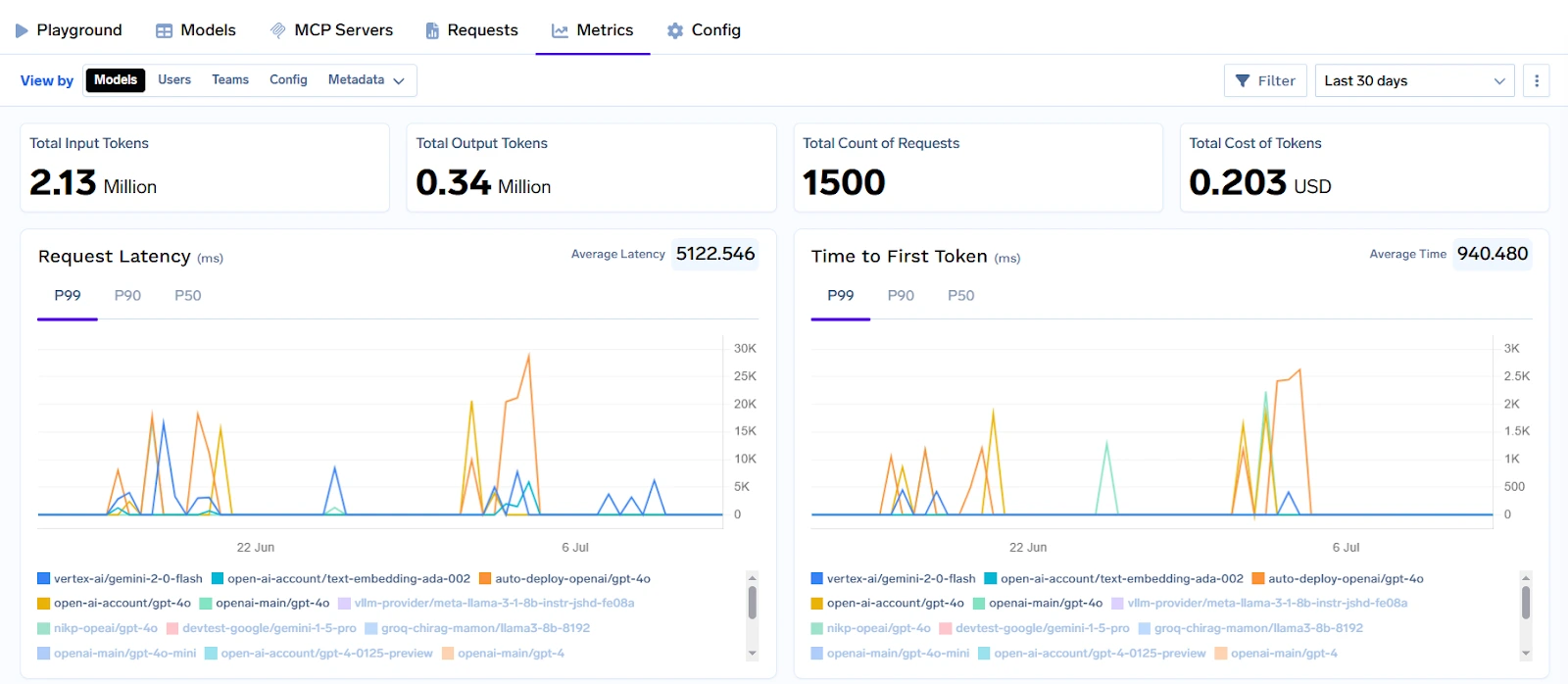
Unternehmen können auch die schnelle Versionierung, die Nachverfolgung der Token-Nutzung und die Feinabstimmung von Pipelines in sicheren Sandbox-Umgebungen nutzen. Zugriffskontrollen, API-Schlüsselverwaltung und Audit-Trails sorgen für Sicherheit und Governance auf Unternehmensebene. TrueFoundry ermöglicht Kostentransparenz und -kontrolle durch granulare Abrechnung, Ratenbegrenzung und Nutzungskontingente, sodass Ingenieur- und Finanzteams einen vollständigen Überblick über die LLM-Nutzung in großem Umfang haben.
Mit TrueFoundry setzen Unternehmen LLMs nicht nur ein, sie setzen sie auch in Betrieb. Die Plattform schließt die Lücke zwischen Experimenten und Produktion und ermöglicht die Entwicklung zuverlässiger, konformer und skalierbarer LLM-gestützter Anwendungen.
Mit zunehmender Akzeptanz von LLMs in Unternehmen verlagert sich der Schwerpunkt vom Zugriff auf Optimierung, Orchestrierung und Skalierung. Einer der wichtigsten Trends ist das Aufkommen kleiner und effizienter Open-Source-Modelle. Modelle wie Mistral, Phi-3 und DBRX zeigen, dass Größe nicht mehr der einzige Qualitätsindikator ist. Unternehmen optimieren diese kleineren Modelle zunehmend, um aufgabenspezifischen Anforderungen gerecht zu werden und gleichzeitig Kosten und Latenz zu reduzieren.
Ein weiterer Trend ist die Entwicklung hin zu Agentensystemen, bei denen LLMs nicht nur auf Eingabeaufforderungen reagieren, sondern als autonome Agenten agieren, die Aufgaben systemübergreifend planen, begründen und ausführen. Dies ermöglicht komplexere Unternehmensabläufe wie Onboarding, mehrstufige Dokumentenverarbeitung und automatisierte Analysen.
Wir sehen auch eine tiefe Integration mit Wissensgraphen und Unternehmensdatenbanken. Anstatt sich ausschließlich auf Einbettungen und Vektorspeicher zu verlassen, verbinden Unternehmen LLMs mit strukturierten Wissensquellen, um fundiertere, überprüfbare und rückverfolgbare Ergebnisse zu liefern.
Schließlich werden Governance- und Compliance-Instrumente nicht mehr verhandelbar sein. Da immer mehr geschäftskritische Workflows über LLMs abgewickelt werden, werden Unternehmen eine strenge Kontrolle über Eingabeaufforderungen, Ausgaben und Benutzerberechtigungen verlangen.
Diese Trends deuten auf eine Zukunft hin, in der LLMs zur grundlegenden Infrastruktur werden — sicher, zusammensetzbar und tief in den Unternehmensbetrieb eingebettet.
LLMs für Unternehmen sind nicht mehr experimentell; sie werden schnell zu einem Kernbestandteil der modernen Unternehmensinfrastruktur. Um ihr volles Potenzial auszuschöpfen, ist jedoch mehr als nur der Zugriff auf leistungsstarke Modelle erforderlich. Es erfordert die richtige Architektur, Bereitstellungsstrategie, Überwachungssysteme und Governance-Rahmenbedingungen. Mit Plattformen wie TrueFoundry können Unternehmen über Prototypen hinausgehen und sichere, skalierbare und ROI-gesteuerte LLM-Anwendungen entwickeln. Im Zuge der Weiterentwicklung des Ökosystems werden die Gewinner diejenigen sein, die LLMs nicht als magische Werkzeuge betrachten, sondern als verwaltete Systeme, die tief integriert sind, ständig beobachtet und auf die Geschäftsergebnisse abgestimmt sind.
Ein Enterprise LLM ist ein umfangreiches Sprachmodell, das für Unternehmensumgebungen optimiert ist und Datensicherheit, Skalierbarkeit und Integration mit internen Systemen priorisiert. Im Gegensatz zu Allzweckmodellen ist ein LLM für Unternehmen so konzipiert, dass es innerhalb der privaten Cloud oder der lokalen Infrastruktur eines Unternehmens funktioniert und sicherstellt, dass sensible Daten geschützt bleiben. Diese Modelle werden in der Regel zur Unterstützung spezialisierter Tools wie interner Wissensdatenbanken und automatisierter Workflows verwendet.
Um ein LLM für Unternehmen aufzubauen, müssen Unternehmen über einfache API-Aufrufe hinausgehen und eine produktionstaugliche Pipeline einrichten. Dazu gehören die Einrichtung einer robusten Infrastruktur für das Model-Hosting, die Implementierung von Retrieval-Augmented Generation (RAG), um das Modell auf privaten Daten zu stützen, und die Schaffung eines KI-Gateways für die zentrale Verwaltung. TrueFoundry optimiert diesen Prozess, indem es die MLOps-Tools bereitstellt, die für die Bereitstellung und Skalierung dieser Modelle erforderlich sind, während gleichzeitig die vollständige Governance gewahrt bleibt.
Zu den häufigsten LLM-Anwendungsfällen für Unternehmen gehören die Entwicklung von RAG-basierten Suchmaschinen für firmeneigene Dokumente, die Automatisierung komplexer Vertragsanalysen und der Einsatz von KI-Agenten für den technischen Support. Durch den Einsatz von LLM in Unternehmen können Unternehmen die manuelle Verarbeitungszeit erheblich reduzieren und gleichzeitig die Genauigkeit des Abrufs interner Informationen erhöhen.
Standard-Benchmarks erfassen häufig nicht die Anforderungen einer Produktionsumgebung. Für ein LLM-Unternehmen gehören zu den wichtigsten Benchmarks die Inferenzlatenz, die Token-Kosteneffizienz und Kennzahlen zur „Treue“ in den RAG-Pipelines, um sicherzustellen, dass keine Halluzinationen auftreten. Durch die Überwachung dieser Benchmarks können Teams beurteilen, ob ein bestimmtes Modell die Leistungs- und Zuverlässigkeitsstandards erfüllt, die für kundenorientierte oder unternehmenskritische Anwendungen erforderlich sind.
Die Wahl des richtigen LLM für Unternehmen zum Aufbau erfordert ein ausgewogenes Verhältnis zwischen der Modellleistung und den Anforderungen an die Datenhoheit. Viele Unternehmen verwenden eine Mischung aus proprietären Modellen für komplexe Überlegungen und Open-Source-Modellen für umfangreiche, datenschutzsensible Aufgaben. Eine flexible Plattform wie TrueFoundry ermöglicht es Ihnen, eine Anbieterbindung zu vermeiden, indem sie eine einheitliche Oberfläche bietet, über die Sie je nach den spezifischen Kosten und Sicherheitsanforderungen jedes Projekts zwischen verschiedenen Modellen wechseln können.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.




.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




