













.webp)
July 14, 2026
|
5 min read

Published: March 16, 2026

Blazingly fast way to build, track and deploy your models!
Large Language Models (LLMs) have moved beyond experimental chatbots and public demos; they’re now powering mission-critical workflows inside the enterprise. From automating internal knowledge search to generating reports, enhancing customer support, and securing compliance, LLMs are reshaping how modern businesses operate. But deploying LLMs in enterprise environments isn’t as simple as plugging into an API. It demands governance, observability, privacy safeguards, and tailored infrastructure. This guide explores the evolving landscape of Enterprise LLMs, covering key challenges, deployment models, monitoring best practices, and how platforms like TrueFoundry are enabling secure, scalable adoption of LLMs across industries.
The hype around LLMs has triggered a wave of adoption, but for enterprises, the real challenge isn’t generating flashy responses. It’s deploying these models intelligently and responsibly. A true Enterprise LLM is not just ChatGPT with a business wrapper. It is a system grounded in your proprietary data, optimized for your workflows, and deployed with your compliance, cost, and control requirements in mind.
Most public LLMs are trained on open internet data. That makes them powerful in general language reasoning but unreliable when applied to company-specific contexts, especially where accuracy, traceability, and security matter. For example, a financial services firm cannot afford hallucinated facts, vague disclaimers, or unpredictable responses. What they need is a model that is domain-aware, auditable, and deployable behind firewalls. This is often coupled with Retrieval-Augmented Generation (RAG) so it can reason over internal documents, not just what it was pre-trained on.
Enterprise LLMs are evolving into internal copilots. Legal teams use them to draft contracts, HR teams to answer employee queries, developers to accelerate code, and support teams to summarize and resolve tickets faster. But these outcomes are only possible if the LLM is well-integrated, monitored in production, and aligned with the organization’s data boundaries.
This shift also signals a philosophical evolution. We are moving from treating LLMs as magic black boxes to viewing them as modular AI systems, where orchestration, grounding, observability, and feedback loops matter just as much as the base model itself.
Successfully implementing LLM in enterprise is not just about AI capability. They are about business leverage. And that requires thinking far beyond the model to the architecture, infrastructure, and organizational trust it depends on.
While the potential of Enterprise LLMs is vast, deploying them in a real-world business environment comes with critical challenges that organizations must address from day one.
Data Privacy and Security: Enterprise LLMs often operate on sensitive internal data, contracts, customer records, source code, and financials. This raises serious concerns around data leakage, unauthorized access, and regulatory non-compliance. Without strict access controls, encryption, and prompt sanitization, LLM outputs can unintentionally expose confidential information.
Hallucinations and Reliability: LLMs are prone to generating confident but incorrect answers, also known as hallucinations. In an enterprise setting, this can lead to operational mistakes, legal risks, and loss of trust. This makes grounding the model in internal documents via RAG pipelines essential to ensure factual accuracy.
Prompt Injection and Adversarial Inputs: Enterprises must protect against malicious or manipulative prompts that bypass filters or extract unintended data. Without proper input validation and guardrails, models may become vectors for social engineering or leakage.
Cost and Infrastructure Overheads: Running large models on GPUs at scale incurs high inference costs. This is where LLM inferencing strategy becomes critical, because model size, batching, and hardware choices directly determine enterprise latency and cost efficiency. Enterprises need to manage latency, throughput, and scaling while keeping cloud expenses under control. Choosing the right model size and optimizing batching, caching, and quantization are critical.
Monitoring and Version Control: Unlike traditional software, LLM behavior can drift subtly over time. Enterprises need tools to track prompts, outputs, response quality, and usage trends. Lack of observability can lead to model misuse, underperformance, or failure to meet SLAs.
Evaluation Complexity: Evaluating LLMs is non-trivial. It requires custom benchmarks, feedback loops, and task-specific metrics like relevance, coherence, and factuality.
Each of these challenges needs a structured approach to mitigate risk and enable scale. Without them, LLM initiatives remain stuck in prototype mode, never reaching true enterprise maturity.
Enterprises across industries are moving beyond experimentation and beginning to deploy LLMs in production environments. These deployments focus on high-impact internal use cases that can deliver measurable ROI while minimizing risk.
Knowledge Retrieval and Internal Search
One of the most common applications is enterprise search. By combining LLMs with retrieval systems like vector databases, companies enable employees to query internal documentation using natural language. This improves knowledge access for HR, legal, compliance, and IT teams.
Customer Support Automation
Enterprises are integrating LLMs into customer support workflows. The models assist in ticket summarization, email generation, and intent routing. When paired with historical support data, LLMs can significantly reduce response times and improve customer satisfaction.
Document Summarization and Classification
LLMs are being used to analyze and summarize lengthy reports, contracts, or transcripts. Enterprises in the legal, finance, and healthcare sectors benefit from automated document processing, which reduces manual review time and speeds up decision-making.
Developer Productivity
Technical teams deploy code-focused LLMs to accelerate software development. Internal copilots suggest code snippets, identify bugs, and generate documentation based on internal repositories. This boosts engineering velocity without compromising security.
Domain-Specific Assistants
Some organizations are building LLM-based assistants tailored to specific workflows. For example, insurance firms use models trained on claims data to flag anomalies or pre-fill forms. Consulting firms use LLMs to prepare research briefs grounded in their proprietary databases.
Real-world examples include VMware’s internal use of StarCoder for engineering, the US Army’s Enterprise LLM Workspace for documentation access, and Glean’s AI-driven enterprise search platform.
What unites successful deployments is not just the model, but the integration with internal data, tools, and governance practices. These are not off-the-shelf solutions. They are custom systems purpose-built for enterprise impact.
One of the most important architectural decisions for any enterprise LLM initiative is where to deploy the model. Both on-premises and cloud-based deployments offer distinct advantages, depending on the organization's priorities, constraints, and regulatory environment.
On-Prem Deployment
Enterprises with strict data governance, such as in healthcare, finance, or government, often opt for on-prem deployments. These ensure full control over sensitive data, enabling compliance with internal policies and external regulations. On-prem setups also reduce reliance on third-party infrastructure and allow for performance tuning at the hardware level. However, they require significant investment in GPUs, DevOps expertise, and ongoing maintenance. Model updates, patching, and scaling become internal responsibilities, which can slow innovation if not well-resourced.
Cloud Deployment
Cloud-based LLMs are faster to adopt and easier to scale. Providers like OpenAI, AWS Bedrock, Google Cloud, and Azure offer managed APIs with instant access to cutting-edge models. These services reduce operational burden and accelerate time-to-value, especially during early experimentation. But they come with concerns around data privacy, vendor lock-in, and recurring costs. For many enterprises, sending proprietary data to external endpoints is a non-starter unless strict encryption, anonymization, and access policies are enforced.
Hybrid and VPC Solutions
A growing trend is hybrid deployment, where inference runs in a Virtual Private Cloud (VPC) environment. This balances the flexibility of cloud with the security of isolated infrastructure. Platforms like TrueFoundry and Hugging Face support private hosting of open-source models within enterprise-controlled environments, offering the best of both worlds.
Choosing the right deployment model is not just a technical decision. It directly impacts compliance, performance, and long-term costs. Enterprises must assess their use cases, risk tolerance, and infrastructure maturity before committing to a path.
Monitoring LLMs in enterprise settings is fundamentally different from monitoring traditional machine learning models. LLMs are probabilistic, non-deterministic, and highly context-sensitive. Without proper observability, their behavior can silently drift, generate incorrect outputs, or introduce risk, without any indication of failure in the system.
Prompt Tracing and Versioning: Enterprises must track every interaction between users and the LLM, including the exact prompt structure, system message, and context window. Observability begins with full traceability. Logging prompt templates, model versions, temperature settings, and input-output pairs allows teams to reproduce and analyze outcomes later.
Output Evaluation and Groundedness: Monitoring the factual accuracy and relevance of LLM responses is crucial. Enterprises should implement automatic checks for hallucinations, such as validating outputs against known internal documents or enforcing source citation using RAG pipelines. Evaluating outputs using scoring rubrics like helpfulness, correctness, and completeness adds structure to monitoring.
Latency and Token Usage: While infrastructure metrics are handled elsewhere, observability at the LLM layer includes tracking token input size, output length, and total token consumption. These metrics directly affect response time and cost. Token spikes may indicate prompt engineering issues or misuse.
Detection of Harmful or Unsafe Outputs: LLMs may generate biased, offensive, or non-compliant language if guardrails fail. Enterprises should monitor outputs for sensitive terms, tone violations, or data leakage using pattern matchers or classifiers. Red-teaming and adversarial testing can reveal blind spots.
Feedback Loop Integration: User feedback is critical. Enterprises must capture corrections, dissatisfaction signals, and ratings. These signals feed into prompt refinement, RAG updates, and model fine-tuning.
Without targeted observability, LLMs behave like black boxes. With proper monitoring, they become transparent systems that enterprises can trust, audit, and improve continuously.
TrueFoundry is purpose-built to help enterprises deploy, manage, and scale LLM applications with the control, security, and performance that production environments demand. Unlike generic AI platforms, TrueFoundry focuses on modular, production-grade AI infrastructure that fits into an enterprise’s cloud, on-prem, or hybrid environment.
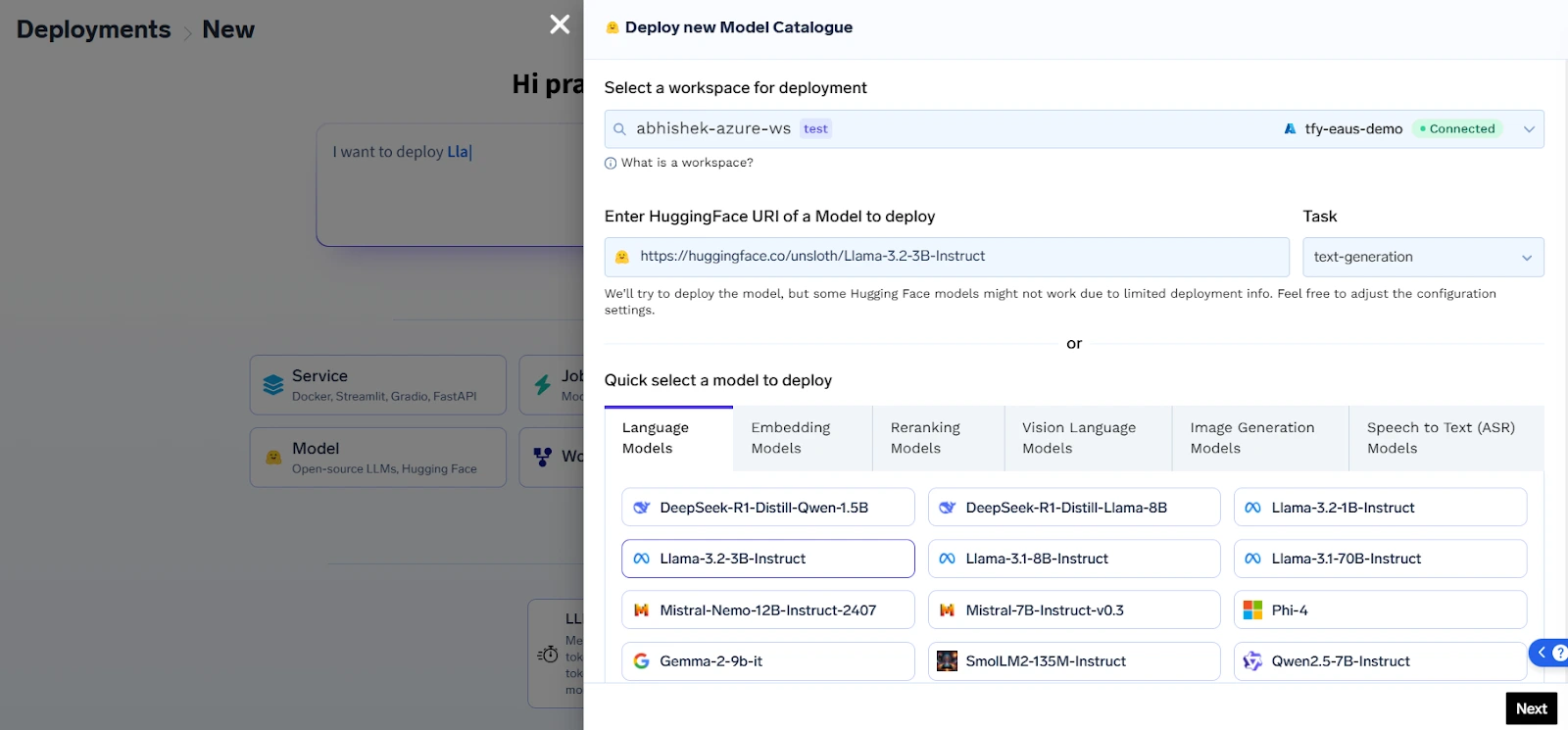
At the core of its offering is a Kubernetes-native AI infrastructure layer that enables teams to deploy both proprietary and open-source LLMs like LLaMA, Mistral, Falcon, and GPT-J with complete control over hosting, networking, and security. This ensures that sensitive enterprise data remains within the organization's boundaries, whether deployed in a private cloud or on-prem data center.
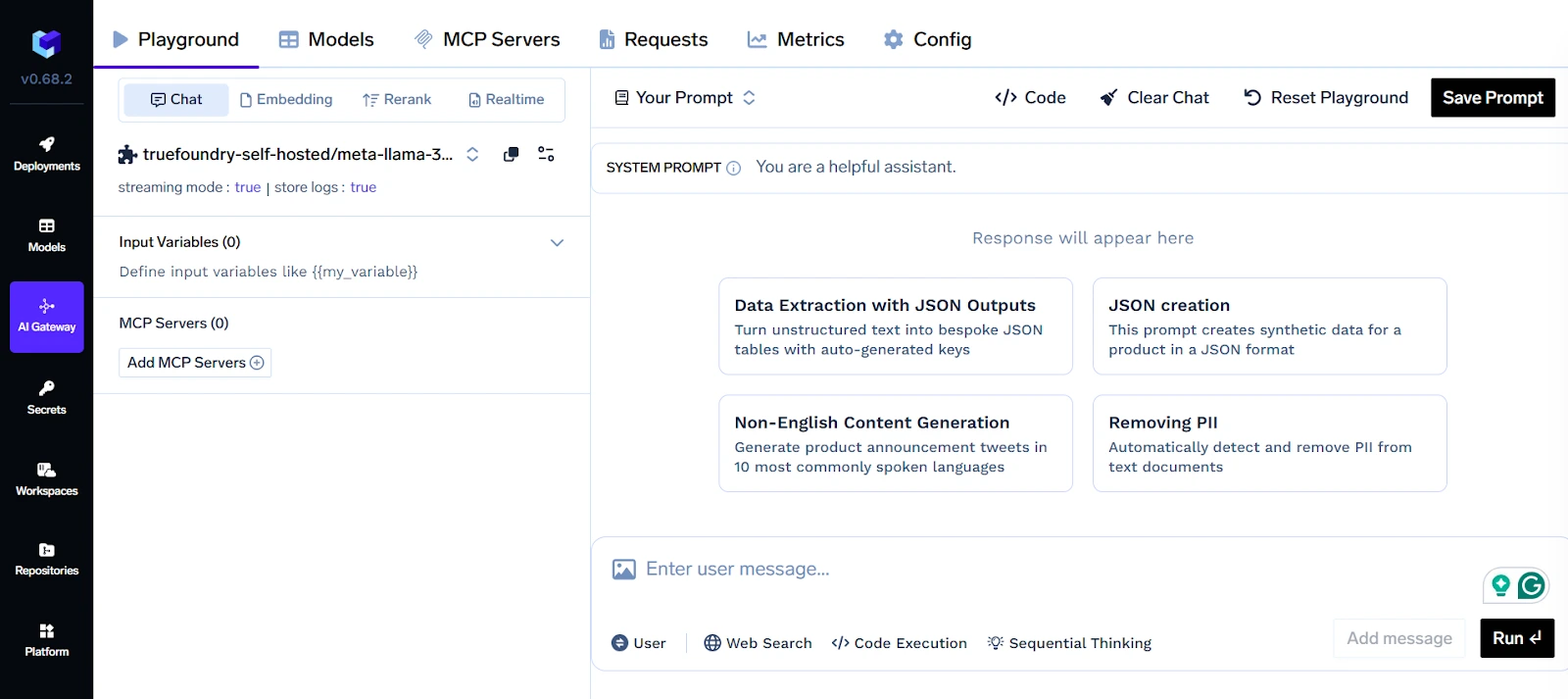
For enterprises using multiple LLM providers (e.g., OpenAI, Anthropic, Cohere), TrueFoundry offers a Unified LLM Gateway. This abstraction layer lets teams switch between providers or route traffic intelligently based on cost, latency, or compliance needs. It also supports fallback and multi-model strategies, which are essential for reliability in production environments.
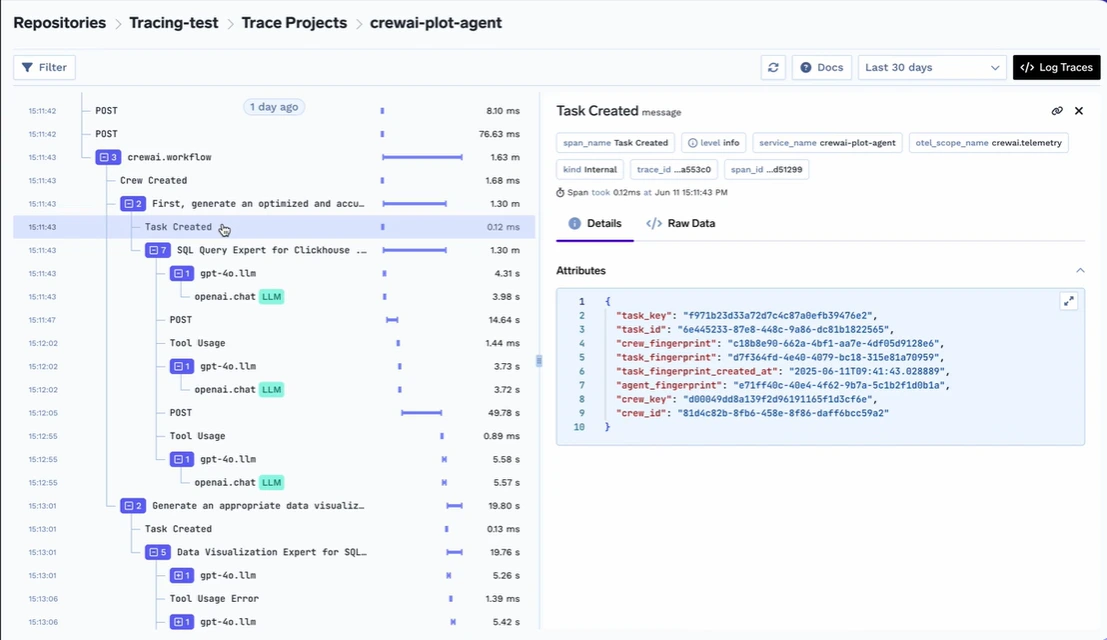
To ensure trust and observability, TrueFoundry provides deep monitoring and analytics at the prompt and response level, functioning as a core layer alongside enterprise LLM observability tools. Enterprises can track which prompts are used, how models behave over time, and how much latency or cost is associated with each request. This is critical for debugging, compliance audits, and performance tuning.
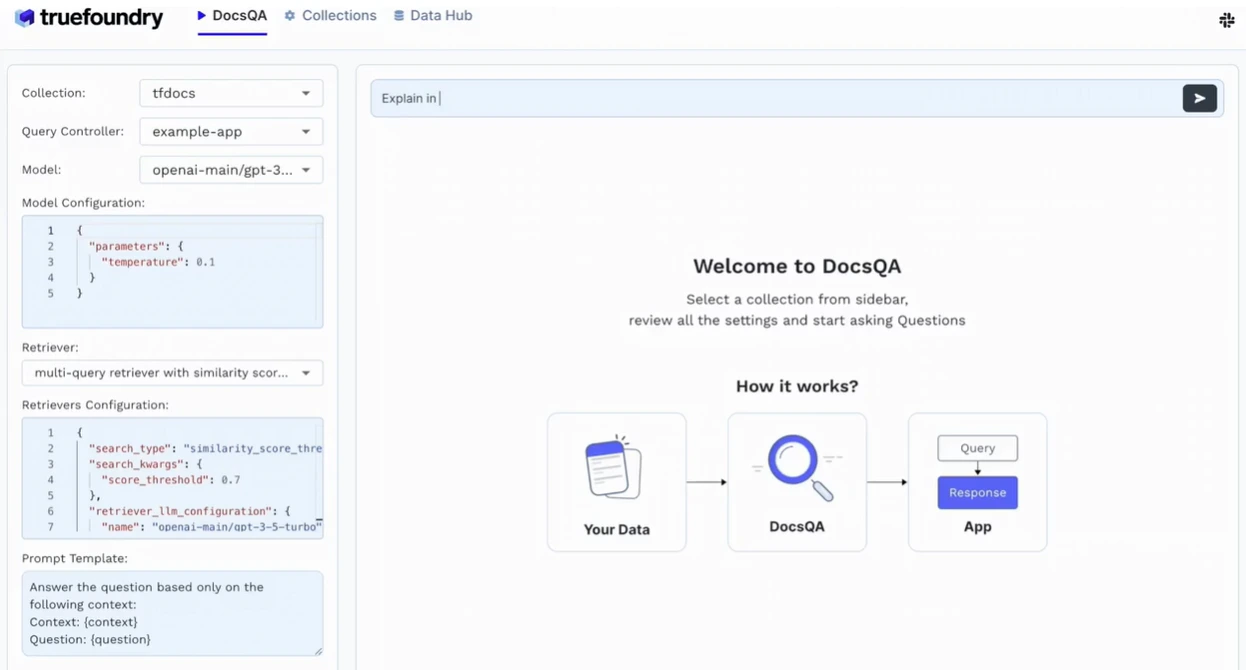
TrueFoundry also supports RAG (Retrieval-Augmented Generation) out of the box, allowing enterprises to ground LLM responses in their internal knowledge. It integrates with popular vector stores like Weaviate, Pinecone, and Qdrant, enabling accurate, context-aware responses without retraining base models.
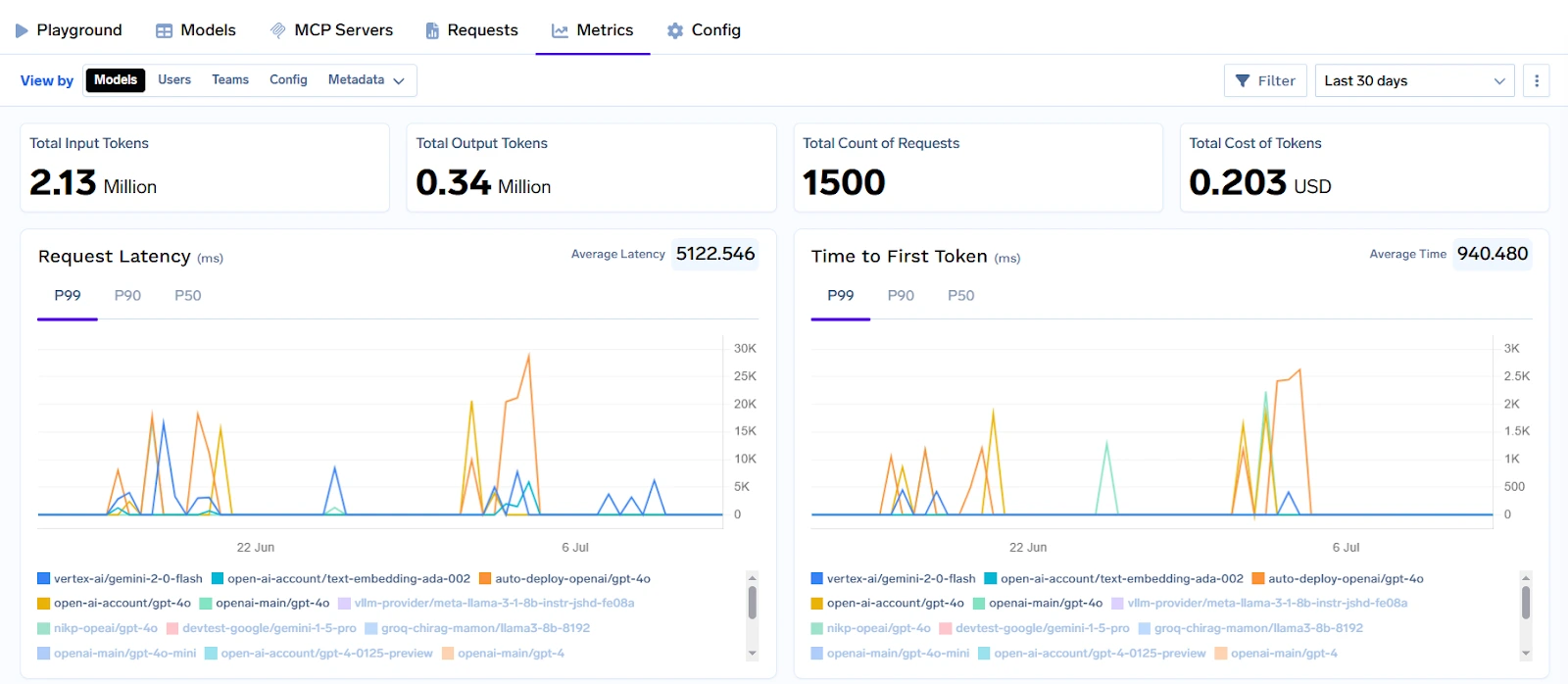
Enterprises can also leverage prompt versioning, token usage tracking, and fine-tuning pipelines with secure sandboxed environments. Access controls, API key management, and audit trails ensure enterprise-grade security and governance. TrueFoundry enables cost transparency and control through granular billing, rate limiting, and usage quotas, giving engineering and finance teams full visibility into LLM usage at scale.
With TrueFoundry, enterprises don’t just deploy LLMs; they operationalize them. The platform bridges the gap between experimentation and production, making it possible to build reliable, compliant, and scalable LLM-powered applications.
As enterprise adoption of LLMs matures, the focus is shifting from access to optimization, orchestration, and scale. One of the most significant trends is the rise of small and efficient open-source models. Models like Mistral, Phi-3, and DBRX are showing that size is no longer the only indicator of quality. Enterprises are increasingly fine-tuning these smaller models to meet task-specific needs while reducing cost and latency.
Another emerging trend is the move toward agentic systems, where LLMs don’t just respond to prompts but act as autonomous agents that plan, reason, and execute tasks across multiple systems. This allows for more complex enterprise workflows like onboarding, multi-step document processing, and automated analysis.
We’re also seeing deep integration with knowledge graphs and enterprise databases. Instead of relying solely on embeddings and vector stores, organizations are connecting LLMs to structured knowledge sources to provide more grounded, auditable, and traceable outputs.
Finally, governance and compliance tooling will become non-negotiable. As more business-critical workflows run through LLMs, enterprises will demand rigorous control over prompts, outputs, and user permissions.
These trends point to a future where LLMs become foundational infrastructure—secure, composable, and deeply embedded in enterprise operations.
Enterprise LLMs are no longer experimental; they are fast becoming a core part of modern business infrastructure. But realizing their full potential requires more than just access to powerful models. It demands the right architecture, deployment strategy, monitoring systems, and governance frameworks. With platforms like TrueFoundry, enterprises can move beyond prototypes and build secure, scalable, and ROI-driven LLM applications. As the ecosystem evolves, the winners will be those who treat LLMs not as magic tools, but as managed systems deeply integrated, constantly observed, and aligned with business outcomes.
An enterprise LLM is a large language model optimized for corporate environments, prioritizing data security, scalability, and integration with internal systems. Unlike general-purpose models, an LLM for enterprise is designed to work within a company’s private cloud or on-premise infrastructure, ensuring that sensitive data remains protected. These models are typically used to power specialized tools like internal knowledge bases and automated workflows.
To build an enterprise LLM, organizations must go beyond simple API calls and establish a production-grade pipeline. This involves setting up a robust infrastructure for model hosting, implementing Retrieval-Augmented Generation (RAG) to ground the model in private data, and creating an AI Gateway for centralized management. TrueFoundry streamlines this process by providing the MLOps tools needed to deploy and scale these models while maintaining full governance.
Common enterprise LLM use cases include building RAG-based search engines for proprietary documents, automating complex contract analysis, and deploying AI agents for technical support. By leveraging LLM in enterprise, companies can significantly reduce manual processing time while increasing the accuracy of internal information retrieval.
Standard benchmarks often fail to capture the requirements of a production environment. For an enterprise LLM, critical benchmarks include inference latency, token cost-efficiency, and "faithfulness" metrics in RAG pipelines to ensure no hallucinations occur. Monitoring these benchmarks allows teams to evaluate whether a specific model meets the performance and reliability standards required for customer-facing or mission-critical applications.
Choosing the right enterprise LLM to build requires balancing model performance with data sovereignty requirements. Many organizations use a mix of proprietary models for complex reasoning and open-source models for high-volume, privacy-sensitive tasks. A flexible platform like TrueFoundry allows you to avoid vendor lock-in by providing a unified interface to switch between different models based on the specific cost and security needs of each project.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








The latest news, articles, and resources sent to your inbox











.webp)
.webp)
.webp)


