

October 5, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
In der Welt des maschinellen Lernens (ML) ist die effiziente Erstellung von Docker-Images nicht nur ein Luxus, sondern eine Notwendigkeit. Die meisten Unternehmen verfügen über eine bestehende DevOps-Pipeline zum Erstellen und Bereitstellen von Docker-Images entweder auf einem lokalen Laptop oder über CI/CD-Pipelines. Da ML-Projekte jedoch an Komplexität zunehmen, größere Abhängigkeiten und häufigere Iterationen aufweisen, kann der traditionelle Docker-Build-Prozess zu einem erheblichen Engpass werden.
.webp)
In diesem Artikel wird hervorgehoben, wie wir die Erstellungszeit in Truefoundry im Vergleich zu Standard-CI-Pipelines um das 5- bis 15-fache reduziert haben.
ML-Projekte beinhalten in der Regel zahlreiche starke Abhängigkeiten — Deep-Learning-Frameworks (PyTorch, TensorFlow), wissenschaftliche Computerbibliotheken (NumPy, SciPy), GPU-Treiber und CUDA-Toolkits. Aufgrund dieser Abhängigkeiten können Docker-Images mehrere Gigabyte groß werden, was zu langen Build-Zeiten führt.
Die ML-Entwicklung beinhaltet häufige Codeänderungen, die implementiert werden müssen, um sie zu testen. Datenwissenschaftler verfügen oft nicht über die erforderliche Hardware, um ihren Code auf ihren lokalen Laptops auszuführen. Das bedeutet, dass der Code auf dem Remote-Cluster ausgeführt werden muss, was häufig das Erstellen von Images beinhaltet.
Unser Ziel bei Truefoundry ist es, Entwicklern die Möglichkeit zu geben, in einem schnellen Iterationstempo voranzukommen, und dafür wollten wir unsere Docker-Builds wirklich schnell machen. Um zu verstehen, was wir getan haben, um die Build-Zeiten zu optimieren, wollen wir zunächst verstehen, wie wir früher auf Truefoundry Images erstellt haben.
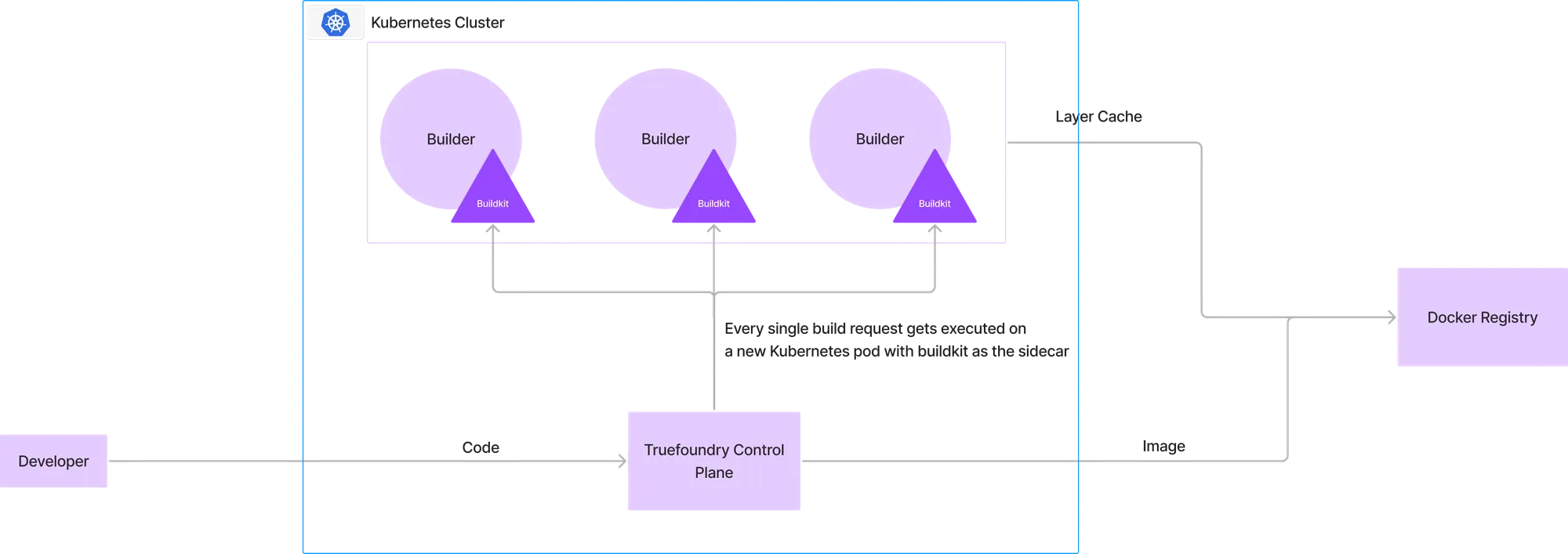
Jedes Mal, wenn ein Entwickler ein Image erstellen wollte, wurde der Code auf die Steuerungsebene hochgeladen, wobei ein neuer Pod mit der Erstellung des Images begann, wobei das Buildkit im Beiwagen lief. Die Ziel-Docker-Registry würde als Caching-Ebene dienen und das endgültige Image wird in die Docker-Registry übertragen.
Dieses Setup ist identisch mit den meisten CI-Buildern und hat dieselben Vor- und Nachteile wie aktuelle CI-Setups
Dies hatte die folgenden Vorteile:
Dieser Ansatz hatte jedoch einige Nachteile:
1. Der Buildkit-Pod benötigt eine große Anzahl von Ressourcen, was zu einer hohen Startzeit für den Build-Runner führt.
2. Das Herunterladen des Caches aus der Docker-Registry nimmt viel Zeit in Anspruch, was zu langsamen Build-Zeiten führt.
3. Der Cache wird nicht für Builds mit unterschiedlichen Workloads wiederverwendet.
Wir wollten die gleiche (und vielleicht bessere) Erfahrung beim Erstellen von Images aus der Ferne bieten als bei lokalen Builds
Wir haben beschlossen, den Buildkit-Pod zunächst als Dienst auf Kubernetes zu hosten, der von mehreren Buildern gemeinsam genutzt werden kann und lokales Festplatten-Caching bietet, sodass Docker-Builds sehr schnell sein können.
Bei diesem Ansatz gibt es jedoch einige Einschränkungen:
1. Buildkit hat eine grundlegende Einschränkung, die Das Cache-Dateisystem kann nur von einer Instanz von Buildkit verwendet werden. Das bedeutet, wenn wir mehrere Instanzen des Buildkits ausführen, um mehrere Builds parallel zu verarbeiten, hat jede von ihnen ihren eigenen Cache und der kann nicht gemeinsam genutzt werden.
2. Wenn wir mehrere Instanzen von Buildkit ausführen, wobei jede ihren eigenen Cache hat, dieselbe Arbeitslast sollte an denselben Computer weitergeleitet werden, damit der Cache effektiv genutzt werden kann. Dies erfordert eine benutzerdefinierte Routing-Logik.
3. Die automatische Skalierung der Buildkit-Pods basierend auf der Anzahl der ausgeführten Builds ist nicht trivial.. Wir können die CPU-Auslastung der Buildkit-Pods nicht als Autoscaling-Metrik verwenden, da es möglich ist, dass Kubernetes einen laufenden kleinen Build beendet, vorausgesetzt, auf diesem Computer läuft nichts.
Eine dynamische Anzahl von Buildkit-Pods zu haben, bei denen die Workloads an dieselbe Cache-Instanz weitergeleitet werden, ist ein nicht triviales Problem. Das Anhängen und Entfernen von Volumes über mehrere Pods hinweg ist in Kubernetes ziemlich langsam, was zu sehr langen Startzeiten der Builds führt.
Um die oben genannten Einschränkungen zu überwinden, haben wir einen hybriden Ansatz entwickelt, bei dem die meisten Builds sehr schnell abgeschlossen werden, während wir in einigen seltenen Fällen, in denen parallele Builds häufig parallel laufen, auf unseren früheren Ablauf zurückgreifen, bei dem Buildkit in einem Sidecar ausgeführt wurde.
In der Architektur, die in der Abbildung unten beschrieben wird, konfigurieren wir eine bestimmte Build-Parallelität, unterhalb derer alle Builds an den Buildkit-Service gehen. Um dies zu veranschaulichen, nehmen wir an, dass wir einen Computer mit 4 CPUs und 16 GB RAM für den Buildkit-Service bereitstellen. Anhand historischer Build-Daten können wir herausfinden, dass diese Maschine 2 gleichzeitige Builds unterstützen kann. Wenn also bereits ein Build läuft und ein neuer durchkommt, wird er an den Buildkit-Service weitergeleitet. Wenn jedoch ein weiterer Build eingeht, leiten wir ihn an das frühere Modell weiter, das den in der Docker-Registry gespeicherten Layer-Cache verwendet und Buildkit als Sidecar ausführt.
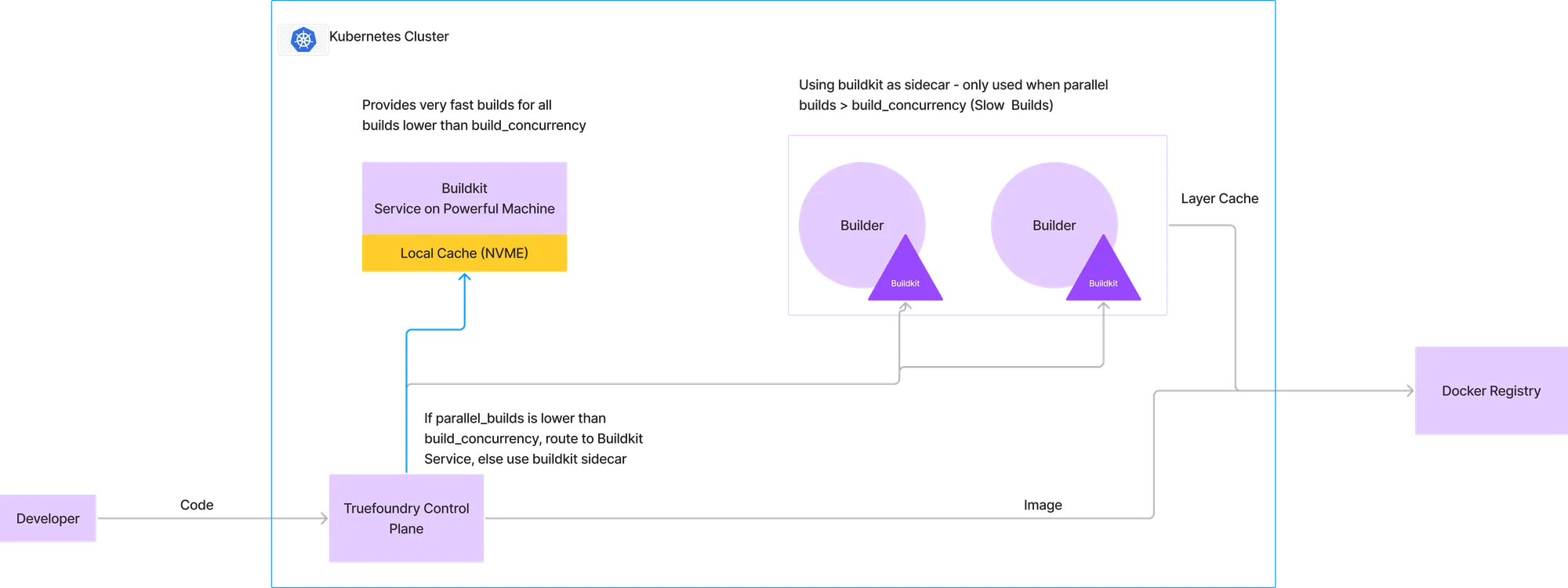
Dies ermöglicht es uns, ultraschnelle Builds für 99% der Workloads bereitzustellen, wohingegen in sehr wenigen Fällen der Build die Zeit in Anspruch nimmt, die normalerweise in Standard-CI-Pipelines benötigt wird.
Es gibt noch ein paar andere Verbesserungen, die wir im Build-Prozess vorgenommen haben, um ihn zu beschleunigen. Ein paar davon sind:
Um unsere Experimente zu vergleichen, haben wir ein Dockerfile-Beispiel verwendet, das das häufigste Szenario für ML-Workloads darstellt.
VON tfy.jfrog.io/tfy-mirror/python:3.10.2-slim
WORKDIR /app
RUN echo „Der Build wird gestartet“
KOPIEREN. /requirements.txt /app/requirements.txt
FÜHREN SIE pip install -r requirements.txt AUS
KOPIEREN. /app/
8000 AUSSETZEN
CMD ["uvicorn“, „app:app“, „--host“, „0.0.0.0", „--port“, „8000"]
Die Datei requirements.txt sieht wie folgt aus:
fastapi [Standard] ==0.109.1
huggingface-hub == 0.24.6
vllm==0.5.4
Transformatoren == 4.43.3
Wir haben den Build für 3 Szenarien verglichen:
Die Zeitangaben beinhalten die Zeit, um das Image zu erstellen und in die Registrierung zu übertragen, und die Einheit wird in Sekunden angegeben.
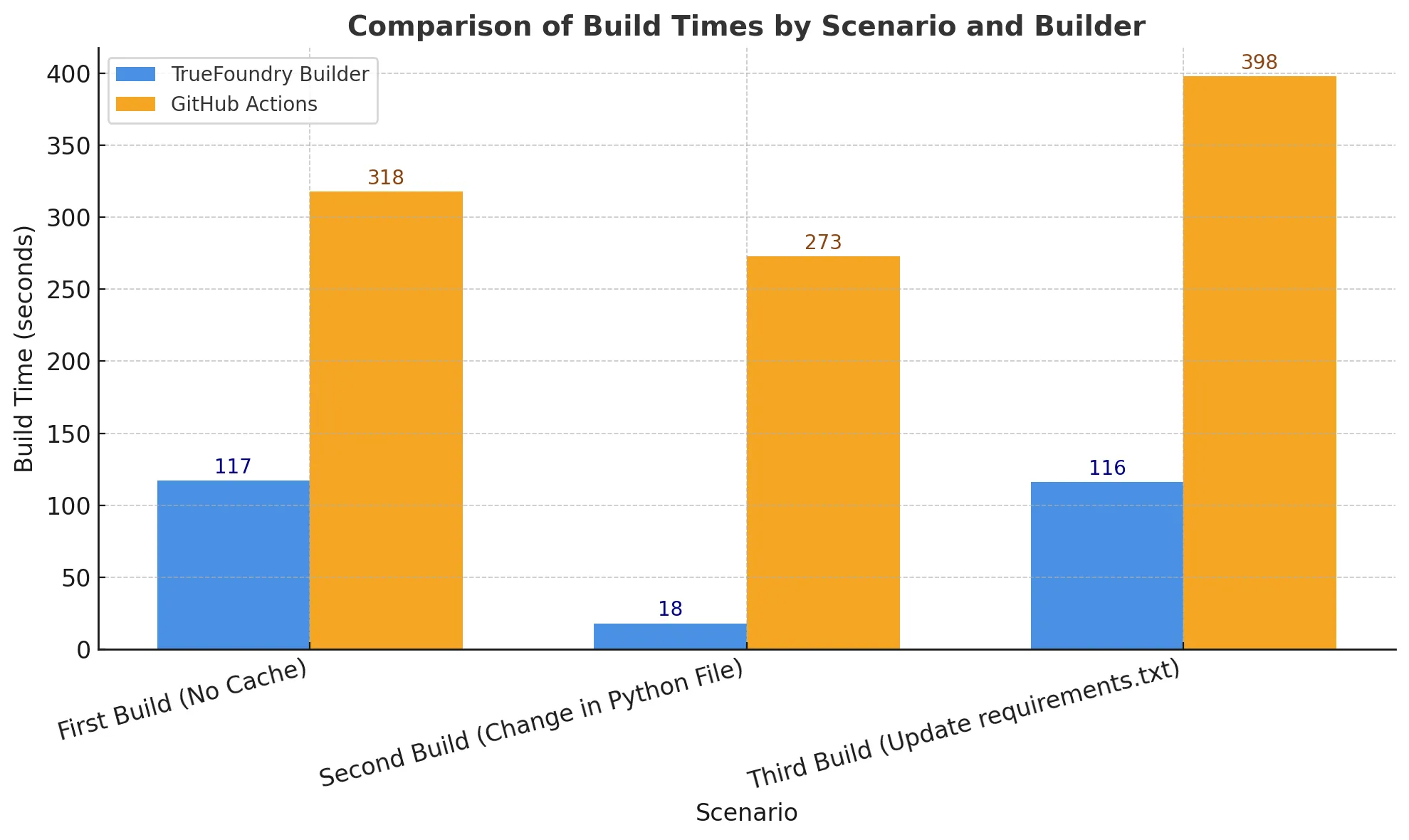
Das zweite Szenario mit nur Codeänderungen ist das häufigste Szenario, auf das Entwickler stoßen, und wie wir sehen können, ist es eine fast 15-fache Verbesserung der Build-Zeiten.
Wir haben auch ein Szenario mit einer Docker-Datei verglichen, die Triton als Basisimage enthält, was ein viel größeres Basisimage ist.
VON nvcr.io/nvidia/tritonserver:24.09-py3
WORKDIR /app
RUN echo „Der Build wird gestartet“
KOPIEREN. /requirements2.txt /app/requirements.txt
FÜHREN SIE pip install -r requirements.txt AUS
RUN echo „Der Build ist abgeschlossen“
Die Ergebnisse sind die folgenden:
.webp)
In diesem Fall sehen wir eine 3-fache Verbesserung der Build-Zeit für den ersten Build und eine 9-fache Verbesserung für nachfolgende Builds.
Die oben genannten Änderungen haben das Entwicklererlebnis erheblich verbessert und ermöglichen es ihnen, ihre Ideen sehr schnell umzusetzen und gleichzeitig die Gleichheit mit der Art und Weise aufrechtzuerhalten, wie die Dinge letztendlich in der Produktion eingesetzt werden.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.








.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




