



July 20, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Der Zweck dieses Artikels besteht darin, den Leser darüber aufzuklären, wie die Preisgestaltung für Large Language Models (LLM) funktioniert. Dies ist auf unsere Gespräche mit mehreren Unternehmen zurückzuführen, die LLMs kommerziell einsetzen. In diesen Gesprächen wurde uns klar, dass die LLM-Ökonomie oft missverstanden wird, sodass ein enormer Optimierungsspielraum bleibt.
Ist dir klar, dass du das machst? Dieselbe Aufgabe kann entweder 3500$ für ein Modell oder 1.260.000$ für ein anderes Modell kosten? Dies hat zwar den Preis eines Leistungsunterschieds, lässt aber in der Mitte viel Spielraum, um darüber nachzudenken, was der Kompromiss zwischen Kosten und Leistung ist? Ist die Aufgabe so, dass ich etwas verwenden kann, das billiger ist?
Wir haben immer wieder festgestellt, dass Unternehmen ihre Ausgaben für Large Language Models über- oder unterschätzen. An dieser Stelle würden wir also versuchen, die Kosten für den Betrieb einiger der beliebten Large Language Models zu verstehen und zu verstehen, wie ihre Preisgestaltung funktioniert.
ℹ️
Der Zweck dieses Blogs besteht nicht darin, den Leser über LLMs oder deren Leistungen aufzuklären. Dies ist ein mathematikintensiver Blog, der sich auf das Verständnis der LLM-Preisgestaltung konzentriert. Der Einfachheit halber würden wir die Leistung dieser Modelle nicht vergleichen.
Das Beispiel für die PreisanalyseUm zu verstehen, wie die Preise für LLMs funktionieren, würden wir die Kosten vergleichen, die für dieselbe Aufgabe anfallen, d. h. Wikipedia auf die Hälfte ihrer Größe zusammenfassen.
Wir würden einige Näherungen verwenden, um die Berechnungen zu vereinfachen und leicht verständlich zu machen
❓
Tokens sind Unterteile von Wörtern, die nicht genau vom Anfang oder Ende von Wörtern abhängen. Es ist die Einheit, in der die OpenAI-APIs die Eingabe in Token aufteilen, bevor sie verarbeitet werden. Token können Leerzeichen und sogar Unterwörter enthalten.
Bei dieser Aufgabe gehen wir der Einfachheit halber davon aus, dass jeder Artikel gerade auf die Hälfte seiner Größe komprimiert wird. Daher werden die Ergebnisse, die wir erwarten, wie folgt aussehen:

Vergleich der Kosten, die die Verwendung verschiedener Modelle für diese Aufgabe kosten würde
OpenAI und andere APIs von Drittanbietern berechnen normalerweise auf der Grundlage von zwei Hebeln; wenn Sie anhand ihrer APIs ableiten möchten
Diese Kosten hängen von der Anzahl der Token (oben erklärt) ab, die als Kontext/Eingabeaufforderung/Anweisung an die API übergeben werden.
Die Kosten basieren auf der Anzahl der Token, die die API als Antwort zurückgibt.
Da Sie bei einer Aufgabe wie einer Zusammenfassung das gesamte Dokument oder den Auszug zur Zusammenfassung an das Modell übergeben müssen, kann die Anzahl der Token, die Teil der Aufforderung sind, erheblich werden, daher die Eingabekosten.
Bei selbst gehosteten Modellen muss der Benutzer die Maschine verwalten/bereitstellen, die für die Ausführung des Modells benötigt wird. Zwar können darin die Kosten für die Verwaltung dieser Ressourcen enthalten sein, doch die Preisgestaltung ist relativ leicht nachzuvollziehen, da sie lediglich auf den Betriebskosten der Maschine basiert (in der Regel den Kosten, die von den Cloud-Anbietern in Rechnung gestellt werden, es sei denn, Sie haben einen eigenen lokalen Cluster)
Kosten für die Bereitstellung der erforderlichen Maschine zum Ausführen/Hosten des Modells. Da die meisten dieser größeren Modelle größer sind als das, was auf einem Laptop oder einem einzelnen lokalen Gerät ausgeführt werden kann, wird für diese Maschinen am häufigsten ein Cloud-Anbieter verwendet.
Cloud-Anbieter geben diese Instanzen heraus, obwohl Benutzer möglicherweise Probleme mit der GPU-Verfügbarkeit haben, da für diese Modelle eine GPU erforderlich ist.
Kosten der Google Cloud-Instanz
Kosten für Microsoft Azure-Instances
Cloud-Anbieter geben ihre freien Kapazitäten zu einem Preis an, der 40-90% günstiger ist als bei On-Demand-Instances
Kosten = Nein. Anzahl der Tokens (pro 1000 Artikel) X Anzahl der Artikel (in Tausenden) X Stückkosten (pro 1 Million Tokens)
Kosten der Eingabe
1.000 (Token/Artikel) X 6.000K (Artikel) X 30$ (/Mio. Tokens) = 180.000$
Produktionskosten
0,5 K (Token/Artikel) X 6.000K (Artikel) X 60$ (/Mio. Token) = 180.000$
Gesamtkosten
Inputkosten + Outputkosten
Eingabekosten (/Mio. Tokens) Ausgabekosten (/Mio. Tokens) $60$120
Kosten = Nein. Anzahl der Tokens (pro 1000 Artikel) X Anzahl der Artikel (in Tausenden) X Stückkosten (pro 1 Million Tokens)
Kosten der Eingabe
1.000 (Token/Artikel) X 6.000K (Artikel) X 60$ (/Mio. Tokens) = 360.000$
Produktionskosten
0,5 K (Token/Artikel) X 6.000K (Artikel) X 120$ (/Mio. Token) = 360.000$
Gesamtkosten
Inputkosten + Outputkosten
Kosten = Anzahl der Tokens (pro 1000 Artikel) X Anzahl der Artikel (in 1000) X Stückkosten (pro 1 Million Tokens)
Kosten der Eingabe
1.000 (Token/Artikel) X 6.000K (Artikel) X 11$ (/Mio. Tokens) = 66.000$
Produktionskosten
0,5 K (Token/Artikel) X 6.000K (Artikel) X 60$ (/Mio. Token) = 96.000$
Gesamtkosten
Inputkosten + Outputkosten
Kosten = Nein. Anzahl der Tokens (pro 1000 Artikel) X Anzahl der Artikel (in Tausenden) X Stückkosten (pro 1 Million Tokens)
Kosten der Eingabe
1.000 (Token/Artikel) X 6.000K (Artikel) X 20$ (/Mio. Tokens) = 120.000$
Produktionskosten
0,5 K (Token/Artikel) X 6.000K (Artikel) X 20$ (/Mio. Token) = 60.000$
Gesamtkosten
Inputkosten + Outputkosten
Kosten = Nein. Anzahl der Tokens (pro 1000 Artikel) X Anzahl der Artikel (in Tausenden) X Stückkosten (pro 1 Million Tokens)
Kosten der Eingabe
1.000 (Token/Artikel) X 6.000K (Artikel) X 2$ (/Mio. Tokens) = 12.000$
Produktionskosten
0,5 K (Token/Artikel) X 6.000K (Artikel) X 60$ (/Mio. Token) = 6.000$
Gesamtkosten
Inputkosten + Outputkosten
Kosten für den Betrieb der Maschine (/Stunde für Spot A100-80Gb) 10$
Kosten = Anzahl der Tokens (pro 1000 Artikel) X Anzahl der Artikel (in 1000) X Stückkosten (pro 1 Million Tokens)
Kosten der Eingabe
1.000 (Token/Artikel) X 6.000K (Artikel) X 30$ (/Mio. Tokens) = 180.000$
Produktionskosten
0,5 K (Token/Artikel) X 6.000K (Artikel) X 60$ (/Mio. Token) = 180.000$
Gesamtkosten
Inputkosten + Outputkosten
In den meisten Anwendungsfällen benötigen Unternehmen sie zur Feinabstimmung von Modellen, die für ihre eigenen Daten und für bestimmte Aufgaben spezifisch sind. Mehrere Unternehmen haben berichtet, dass fein abgestimmte Open-Source-Modelle bei der jeweiligen Aufgabe ebenbürtig oder manchmal sogar besser sind als APIs von Drittanbietern wie OpenAI.

Gesamtkosten
Inputkosten + Outputkosten

Gesamtkosten
Inputkosten + Outputkosten

Gesamtkosten
Inputkosten + Outputkosten
Dinge, die Sie bei der Preisgestaltung beachten sollten:
Wir verwenden den folgenden Benchmark, um die Auswirkungen der Feinabstimmung von Modellen auf die Leistung der Modelle zu analysieren. Es ist interessant festzustellen, dass:
AufgabentypBest 6B/7B OOTB Model Few-ShotMoveLM 7B Zero-ShotGPT-3.5 Turbo Zero-ShotGPT-3.5 Turbo Few-ShotGPT-4 Zero-ShotGPT-4 Few-ShotRelevance - interner Datensatz0,330,930,840,840,920,95Extraktion — strukturierte Ausgabe für Abfragen0.380,980,220.720.380.73Begründung — benutzerdefinierte Triggerung0,620,930.870.880.90.88Klassifikation - Domäne der Benutzerabfrage0,210,790.60.730.70.76Extraction — strukturierte Ausgabe aus der Entitätstypisierung0,830,870,90,890,890,89
Wir glauben an einen Zustand von Anwendungen, in dem die einfacheren Aufgaben von leichten Open-Source-LLMs erledigt werden, wohingegen komplexere Aufgaben oder solche, die besondere Funktionen erfordern (z. B. Websuche, API-Aufrufe usw.), die nur von kommerziellen Closed-LLMs angeboten werden, an sie delegiert werden können.
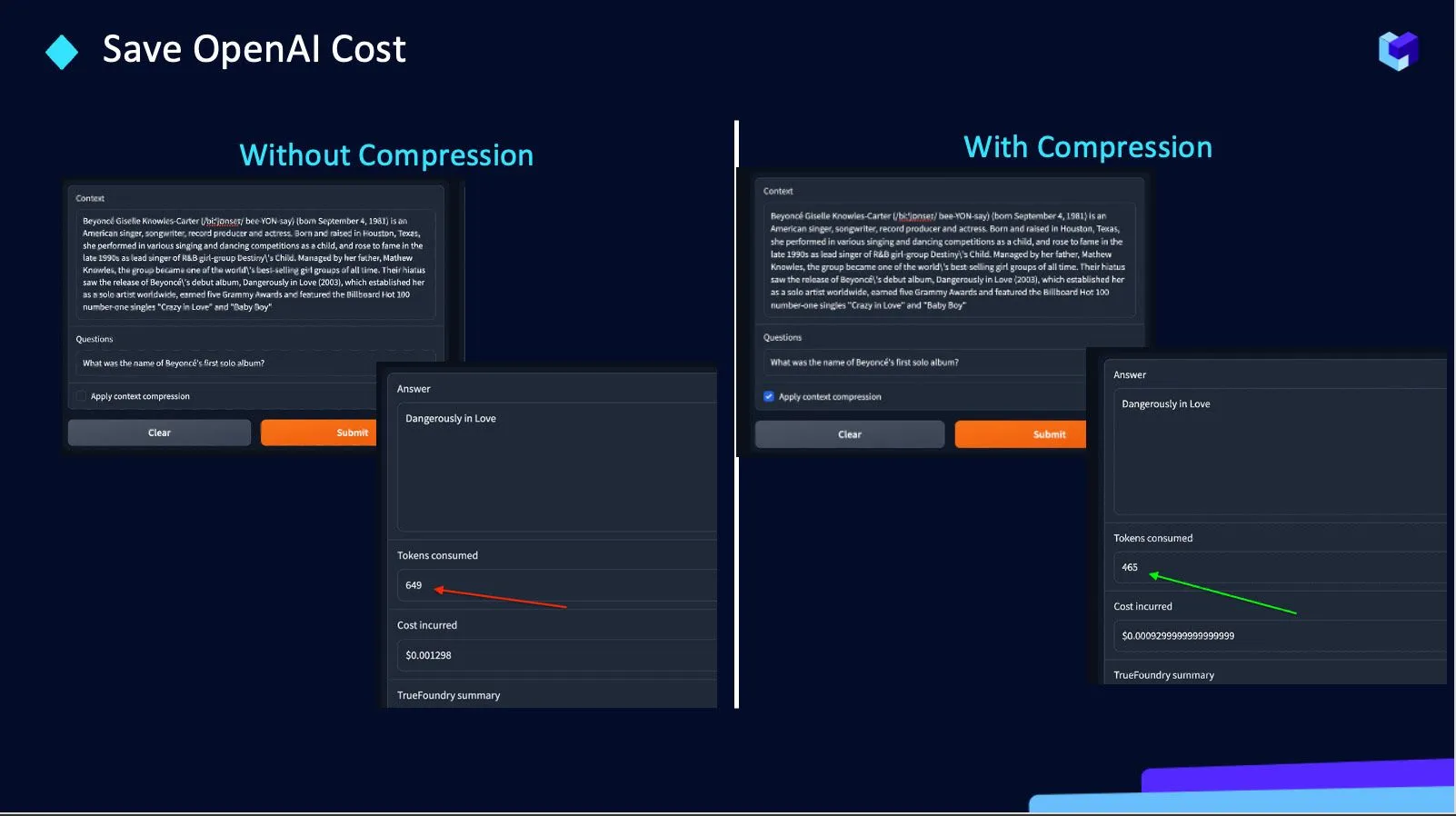
Wir helfen dabei, die Anzahl der an OpenAI-APIs gesendeten Token zu reduzieren. Warum wir uns entschieden haben, daran zu arbeiten, weil:
Daher Wahre Gießerei erstellt eine Komprimierungs-API für sparen Sie OpenAI-Kosten um ~ 30%.
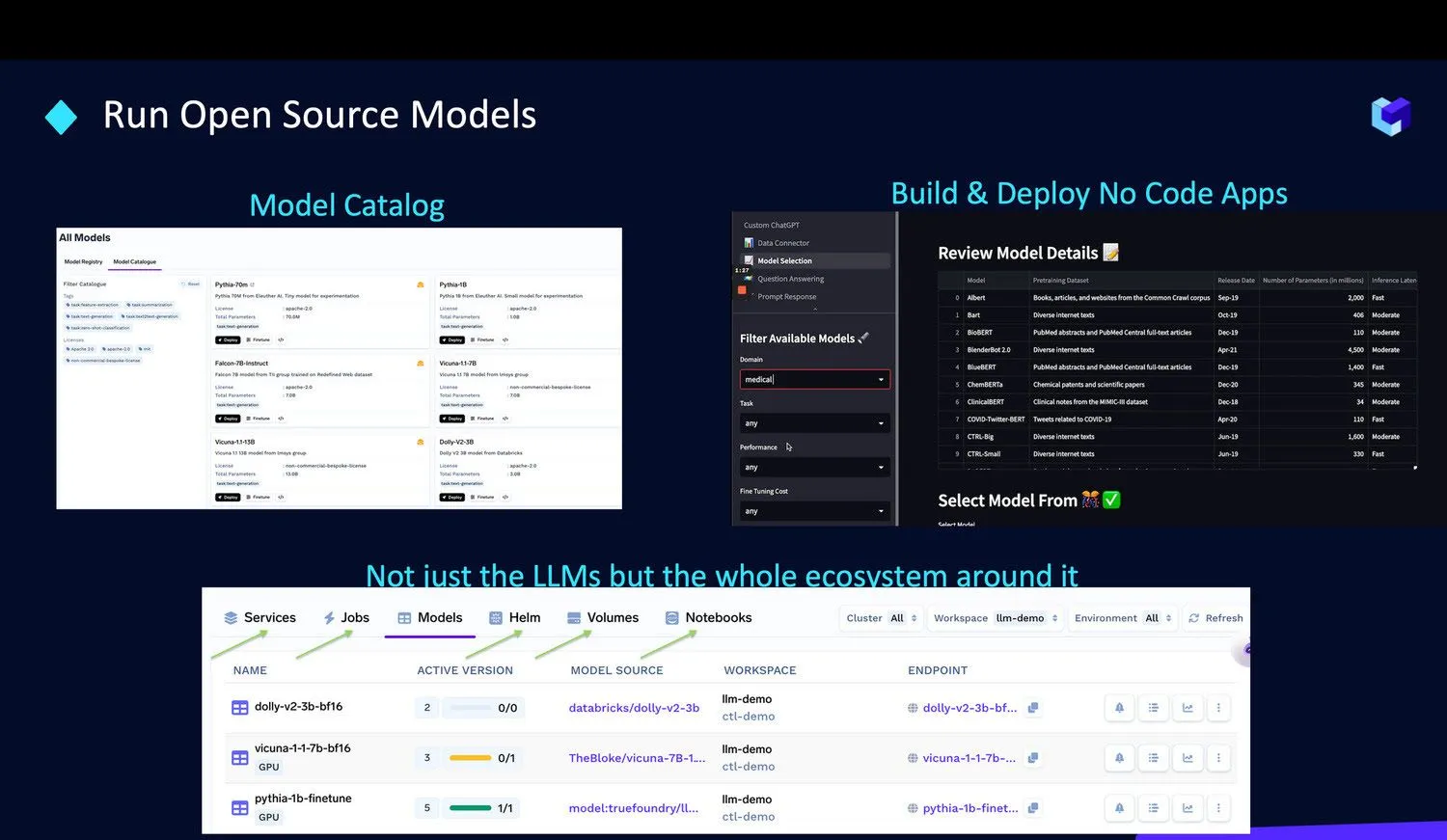
Wir vereinfachen den Betrieb dieser Modelle in Ihrer eigenen Infrastruktur durch unsere folgenden Angebote:
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




