

July 2, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: May 29, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Die Einführung von KI in Unternehmen hat den Risikoschwerpunkt verändert. Die kritischen Entscheidungen beschränken sich nicht mehr auf die Modellauswahl oder Feinabstimmung. In Produktionssystemen werden Risiken eingeführt und entweder kontrolliert oder verstärkt AI-Gateway-Ebene. Hier werden Inferenzen weitergeleitet, Modelle ausgewählt, Agenten führen Workflows aus, Tools werden aufgerufen und Beobachtbarkeitsdaten werden ausgegeben.
Das Ergebnis sind seit langem bestehende Konzepte wie Datenresidenz und Datensouveränität kann nicht länger als statische Infrastrukturprobleme behandelt werden. In KI-Systemen sind sie Laufzeiteigenschaften, die vom Gateway durchgesetzt (oder verletzt) wurde.
Viele Unternehmen glauben, dass sie sich mit der Datenverwaltung befasst haben, indem sie Modelle in einer bestimmten Cloud-Region eingesetzt haben. Diese Annahme scheitert, sobald KI-Gateways Folgendes einführen:
Verstehen Datensouveränität versus Datenresidenz im Kontext von KI-Gateways ist daher von grundlegender Bedeutung für den Betrieb konformer, produktionsfähiger KI.
Herkömmliche Anwendungen hatten relativ vorhersehbare Datenpfade. Anfragen gingen von Benutzern über Dienste bis hin zu Datenbanken weiter, oft innerhalb einer einzigen Region. KI-Gateways ändern dieses Modell grundlegend.
Ein AI-Gateway kann für eine einzige Anfrage:
Jede dieser Aktionen kann Folgendes einführen implizite regionsübergreifende Datenverschiebung oder -zugriff, auch wenn die Anwendung selbst lokal erscheint.
Aus diesem Grund werden KI-Gateways zu De-facto-Datenkontrollebene.
Wenn die Beschränkungen des Wohnsitzes und der Souveränität am Gateway nicht durchgesetzt werden:
Mit anderen Worten, Fehler bei der Datenverwaltung in KI-Systemen sind in der Regel Gateway-Ausfälle, keine Modellfehler.
Dies ist auch der Grund, warum generische Versicherungen wie „Wir setzen Modelle in der Region ein“ sind unzureichend. Ohne Durchsetzung auf Gateway-Ebene können Unternehmen nicht garantieren, dass:
Der Rest dieses Blogs untersucht, wie Datenresidenz und Datensouveränität unterscheiden sich, warum KI-Gateways beides durchsetzen müssen und wie Plattformen wie TrueFoundry ihre Gateways so gestalten, dass diese Garantien durchsetzbar und nicht erstrebenswert sind.
Datenresidenz definiert wo Daten physisch verarbeitet und gespeichert werden.
In KI-Systemen wird diese Frage nicht allein durch das Modell beantwortet, sondern durch die KI-Gateway das orchestriert die Laufzeitausführung.
Aus Sicht von AI Gateway gilt Datenresidenz für:
Entscheidend ist, dass der Wohnsitz durchgesetzt oder verletzt wird zur Laufzeit.
In KI-Systemen wird die Datenresidenz nicht durch eine einzige Einstellung erzwungen. Sie wird durch eine erzwungen Satz von Laufzeit-Primitiven im AI Gateway die gemeinsam einschränken, wo die Ausführung erfolgen kann.
Auf Plattformen wie TrueFoundry funktionieren diese Primitiven vor und während der Ausführung der Anfrageund stellt sicher, dass die Residenzgarantien auch bei Wiederholungen, Ausfällen und dynamischem Routing gelten.
Zu den wichtigsten Grundprinzipien der Durchsetzung gehören:
Modellendpunkte mit regionsbezogenem Geltungsbereich
Modelle werden registriert und dem AI Gateway mit expliziter Regionenaffinität ausgesetzt. Das Gateway kann Anfragen nur an Modellendpunkte weiterleiten, die zur zulässigen Region gehören. Dies verhindert die versehentliche Verwendung global gehosteter oder regionsübergreifender Modelle, selbst wenn mehrere Modelle für dieselbe Arbeitslast konfiguriert sind.
Regional gesperrte Wiederholungs- und Failover-Pools
Wiederholungsversuche und Ausweichversuche sind eine der häufigsten Ursachen für stille Aufenthaltsverstöße. Ein AI-Gateway, das den Wohnsitz erkennt, schränkt die Wiederholungslogik so ein, dass:
Dadurch wird sichergestellt, dass das Verhalten bei hoher Verfügbarkeit niemals die Absicht zur Einhaltung von Vorschriften außer Kraft setzt.
Residency-sensitive Routing-Tabellen
Routing-Entscheidungen im Gateway werden zur Laufzeit anhand von Regionsbeschränkungen bewertet. Selbst wenn das Routing richtliniengesteuert ist (aus Kosten-, Leistungs- oder Modellauswahl), erzwingt das Gateway die Residenzpflicht als harte Einschränkung, keine Präferenz.
Dies ist besonders wichtig bei Setups mit mehreren Modellen, bei denen verschiedene Modelle in verschiedenen Regionen verfügbar sein können.
Exporteure mit eingeschränktem Wohnsitz für Beobachtbarkeit
Inferenzprotokolle, Eingabeaufforderungen, Antworten und Traces enthalten häufig regulierte Daten. Ein KI-Gateway, das den Wohnsitz berücksichtigt, stellt sicher, dass:
Dadurch wird eine häufig auftretende Compliance-Lücke geschlossen, bei der Inferenz lokal erfolgt, Metadaten jedoch nicht.
Während Data Residency antwortet woher Daten werden verarbeitet, Datensouveränität Antworten wer kontrolliert letztendlich die Daten und unter welcher rechtlichen Zuständigkeit.
Für KI-Gateways wird die Souveränität bestimmt durch:
Eine wichtige, aber oft übersehene Realität ist folgende: Daten können in einem Land gespeichert sein, während sie in einem anderen Land souverän sind.
KI-Gateways interagieren häufig mit:
Selbst wenn die Inferenz lokal erfolgt, kann die Souveränität beeinträchtigt werden, wenn:
Für regulierte Unternehmen ist Souveränität daher eine Frage von architektonische Kontrolle, nicht Geografie.
Ein KI-Gateway, das Unternehmen nicht vollständig kontrollieren, kann die Souveränität nicht garantieren, unabhängig davon, wo es betrieben wird.
Auf der AI Gateway-Ebene ist der Unterschied zwischen Datenresidenz und Datensouveränität wird operativ sichtbar. Beide müssen zur Laufzeit durchgesetzt werden, lösen jedoch unterschiedliche Risiken.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Dies sind wiederkehrende Fehlermuster, die auftreten, wenn KI-Gateways ohne Berücksichtigung der Souveränität bewertet werden.
Unternehmen stellen Modelle in einer lokalen Cloud-Region bereit und gehen davon aus, dass die Einhaltung der Vorschriften gewährleistet wird. In Wirklichkeit kann das AI Gateway immer noch:
Gateways versuchen es oft erneut oder führen automatisch einen Failover durch. Ohne ausdrückliche Einschränkungen:
Selbst wenn die Inferenz lokal ist, können Agenten über das Gateway Tools aufrufen, die:
Eingabeaufforderungen, Antworten und Traces enthalten häufig regulierte Daten.
Wenn das AI Gateway Telemetrie außerhalb der genehmigten Grenzen exportiert, wird die Souveränität stillschweigend beeinträchtigt.
Die meisten KI-Plattformen behandeln Data Governance als Bedenken hinsichtlich des Einsatzes. TrueFoundry behandelt es als Problem mit der Laufzeitdurchsetzung.
Auf Unternehmensebene werden Datenresidenz und Datensouveränität nicht dadurch garantiert, wo die Infrastruktur bereitgestellt wird, sondern durch wie die Ausführung kontrolliert wird. In modernen KI-Systemen, in denen Anfragen dynamisch über Modelle weitergeleitet werden, Agenten Tools aufrufen und Observability-Pipelines Metadaten exportieren, ist die einzige Ebene mit ausreichendem Kontext, um die Governance korrekt durchzusetzen, die KI-Gateway.
TrueFoundry basiert auf diesem Prinzip.
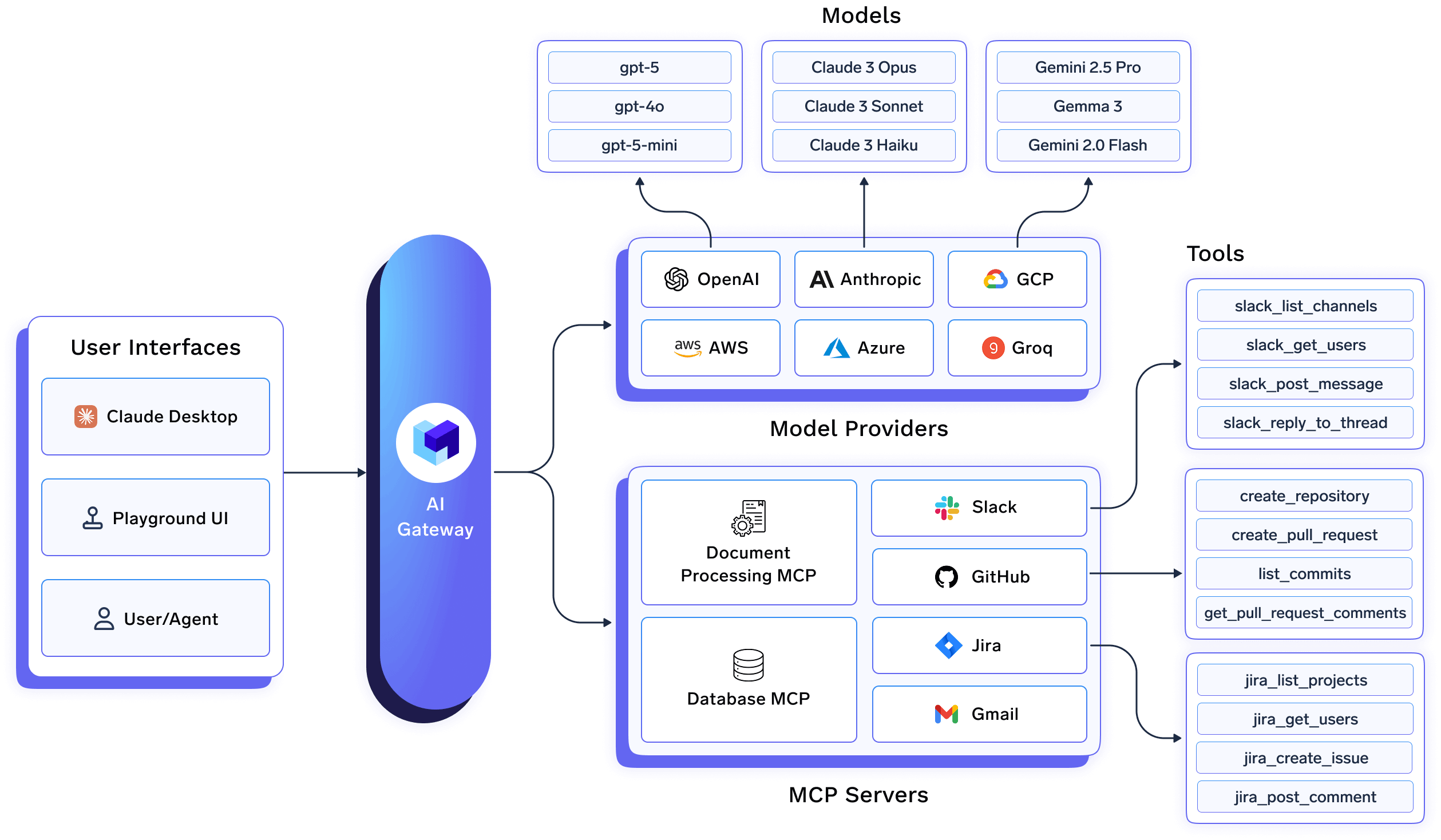
In Wahre Gießerei, das AI Gateway ist kein dünner Proxy vor Modellen. Es ist ein Steuerungsebene das befindet sich am Konvergenzpunkt von:
Da jede Anfrage diese Ebene durchläuft, kann TrueFoundry dies erzwingen sowohl Wohnsitz als auch Souveränität als erstklassige Laufzeitpolitik, keine Best-Effort-Garantien.
Diese Unterscheidung ist wichtig.
True Foundry's KI-Gateway erzwingt den Wohnsitz von Eingrenzung der Ausführungspfade, nicht indem man sich auf die statische Regionsauswahl verlässt.
Konkret heißt das:
Wenn eine Anfrage nicht innerhalb der Wohnsitzbeschränkungen erfüllt werden kann, schlägt sie fehl, geschlossen, anstatt sie stillschweigend an einen anderen Ort weiterzuleiten.
Dadurch wird einer der häufigsten Compliance-Fehler in KI-Systemen behoben: regionsübergreifende Ausführung bei Ausnahmepfaden.
Bei der Datensouveränität geht es im Wesentlichen um wer kontrolliert den Zugriff, nicht dort, wo Compute läuft.
TrueFoundry ermöglicht Souveränität, indem es sicherstellt, dass Unternehmen die Kontrolle behalten über:
Da das Gateway unter der Kontrolle des Unternehmens steht, hängt die Souveränität nicht ab von:
Dies ist ein entscheidender Unterschied zu gehosteten KI-Diensten, bei denen die Inferenz zwar lokal erfolgt, aber Kontrolle ist nicht.
Ein wesentlicher Vorteil des TrueFoundry-Ansatzes ist Konsistenz.Die Aufenthalts- und Souveränitätspolitik wird in folgenden Ländern einheitlich durchgesetzt:
Dadurch wird ein häufiger Fehlermodus verhindert, in dem:
TrueFoundry behandelt das KI-Gateway als gemeinsamen Durchsetzungspunkt und stellt so sicher, dass die Verwaltung systemweit, nicht stückweise.
In modernen KI-Systemen wird Data Governance nicht mehr dadurch definiert, wo die Infrastruktur eingesetzt wird, sondern durch wie die Ausführung zur Laufzeit gesteuert wird. Da Modelle, Agenten und Tools dynamisch interagieren, tun beide Datenresidenz und Datensouveränität muss zentral durchgesetzt werden, um sinnvoll zu bleiben.
Der Wohnsitz bestimmt woher Daten werden verarbeitet. Souveränität bestimmt wer kontrolliert es. Die Lösung des einen ohne das andere führt zu Lücken, insbesondere bei KI-Gateways, die sich um Routing, Failover, Agenten-Workflows und Beobachtbarkeit kümmern.
Weil jede Inferenzanforderung und jeder Toolaufruf sie durchläuft, KI-Gateways sind der einzige Ort, an dem diese Garantien konsistent durchgesetzt werden können. TrueFoundry behandelt das AI Gateway als eine Kontrollebene der Regierungsführung, die den Sitz und die Souveränität festlegt durchsetzbare Systemeigenschaften, keine Annahmen.
Diese Unterscheidung macht KI von einer experimentellen Fähigkeit zu einem produktionstauglichen, konformen System.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.





.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




