

October 5, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
In meinem letzten Job haben wir Produktempfehlungssysteme für E-Commerce-Unternehmen entwickelt. Das bedeutet, dass unsere APIs auf jeder Seite ihrer Website live waren. Wir haben einen neuen Kunden bekommen, was unser erstes siebenstelliges Angebot war, und wir waren so vorsichtig, dass wir ihn im März zunächst mit regelbasierten Empfehlungen an Bord geholt haben. Wir wollten durch unsere im Entstehen begriffenen Machine-Learning-Modelle kein schlechtes Nutzererlebnis riskieren.
Später im April entwickelten wir Modelle für maschinelles Lernen und führten umfangreiche Offline-Tests und viele manuelle Qualitätssicherungen durch. Schließlich waren wir zuversichtlich, dass unser Modell eine gute Leistung erbringen wird, und dann haben wir es auf den Markt gebracht und zwei Dinge sind passiert:
Insgesamt führte dies zu vielen Brandbekämpfungsmaßnahmen, einem großen Glaubwürdigkeitsverlust und einem fast verlorenen Kunden. Bei unserer internen Rückschau später stellten wir fest, dass #1 zwar nur ein manueller Fehlschlag war, es aber fast unmöglich war, Probleme wie #2 offline zu erkennen. Seitdem haben wir uns der guten Seite der Dark Launches zugewandt!
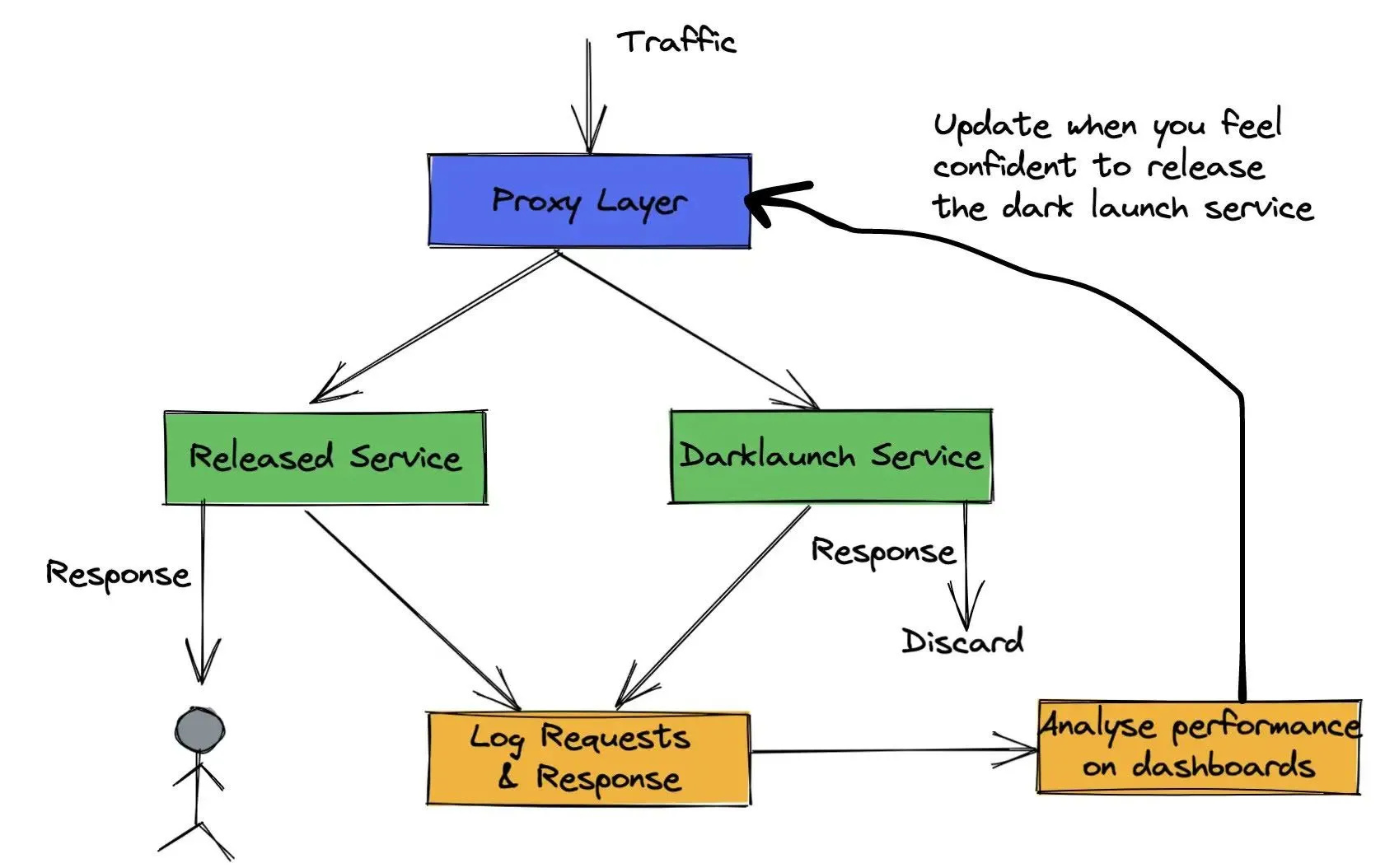
Dark Launch ist eine Bereitstellungsstrategie, mit der Sie Ihren tatsächlichen Produktionsdatenverkehr an Ihren neu bereitgestellten Dienst wiedergeben und die Antwort verwerfen können, bevor Sie sie an den Benutzer zurückgeben. Es verhält sich so, als ob der Dienst tatsächlich live wäre, hat aber keinerlei Auswirkungen auf die Benutzer. Auf diese Weise können Sie überprüfen, ob Ihr neuer Dienst keine Fehler enthält, eine vergleichbare oder bessere Leistung als Ihr alter Dienst aufweist und die Produktionslast bewältigen kann. Sobald all dies verifiziert ist, ist es fast trivial, schrittweise auf Ihren neuen Dienst umzusteigen. Also in gewisser Weise
Dark Launch ist eine einfache Methode, um Ihre Dienste zu starten.
mit sehr minimalem Nachteil und großem potenziellen Aufwärtspotenzial.
Dark Launching Ihrer Dienste ist eine der realistischen Möglichkeiten, Ihre Dienste und Modelle auf einem produktionsähnlichen System zu testen. Die Durchführung eines Dark Launchs kann jedoch in Bezug auf Entwicklung, Überwachung und Infrastruktur innerhalb des Unternehmens eine Menge Vorbereitung und Reife erfordern.
Offline-Tests ermöglichen es Ihnen, das zu überprüfen Verhalten Ihres Systems, in der Regel isoliert. Selten würde es Ihnen ermöglichen, das Komplettsystem zu testen zusammen mit dem Zustand der Umgebungssystem mit realistischen Verkehrs- und Netzwerkeinstellungen wie Produktion? 70% davon können Sie durch akribisches Loggen und sehr komplizierte Offline-Tests erreichen, aber Dark Launch stellt sich als viel einfacheres System heraus. Dies liegt daran, dass Sie sowieso die meisten der oben genannten Schritte ausführen, um einen Dienst normal zu starten und zu überwachen. Nachdem Sie einen erfolgreichen Dark-Launch durchgeführt haben, ist Ihre tatsächliche Veröffentlichung des neuen Dienstes fast trivial, sodass sich das Verhältnis von Aufwand und Belohnung lohnt.
Es gibt eine Reihe von Fällen, in denen dies praktisch schwer zu rechtfertigen sein könnte — zum Beispiel wenn Ihr Dienst statusbehaftet ist oder die Datenbank tatsächlich geändert wird dann ist ein Dark Launch viel komplizierter. Meiner persönlichen Erfahrung nach wird es so schwierig, die Richtigkeit des Systems sicherzustellen, dass es Es ist fast besser, sich einfach mit Offline-Tests gegenüber Dark Launch zufrieden zu geben!
Wenn du mehr neugierig auf Dark Launches bist oder etwas von deinen Erfahrungen teilen möchtest, melde dich bitte bei mir unter nikunj@truefoundry.com!
Wahre Gießerei ist ein ML Deployment PaaS über Kubernetes, um die Workflows von Entwicklern zu beschleunigen und ihnen gleichzeitig volle Flexibilität beim Testen und Bereitstellen von Modellen zu bieten und gleichzeitig die volle Sicherheit und Kontrolle für das Infra-Team zu gewährleisten. Über unsere Plattform ermöglichen wir Teams für maschinelles Lernen bereitstellen und überwachen Modelle innerhalb von 15 Minuten mit 100% iger Zuverlässigkeit, Skalierbarkeit und der Möglichkeit, innerhalb von Sekunden rückgängig zu machen. So können sie Kosten sparen und Modelle schneller für die Produktion freigeben, wodurch ein echter Geschäftswert erzielt wird.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.









.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




