

October 5, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026
.webp)
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Die Welt der künstlichen Intelligenz (KI) entwickelt sich rasant und geht von isolierten Modellen zu miteinander verbundenen Systemen über, die gemeinsam komplexe, facettenreiche Probleme lösen.A Zusammengesetztes KI-System ist definiert als ein System, das KI-Aufgaben mithilfe mehrerer interagierender Komponenten bewältigt, zu denen verschiedene KI-Modelle, Datenabrufmechanismen und externe Tools gehören können. Diese Komponenten arbeiten zusammen, um bestimmte Ziele zu erreichen, was einen differenzierteren und effektiveren Ansatz zur Problemlösung ermöglicht.
Zu den gängigen Beispielen für Verbundsysteme gehören:
Dieses Entwurfsprinzip, für das sich Institutionen wie das Labor von Berkeley AI Research (BAIR) einsetzen, unterstreicht die Bedeutung der Systemarchitektur bei der Bewältigung komplexer KI-Aufgaben. Anstatt sich ausschließlich auf große, monolithische Modelle zu verlassen, nutzen zusammengesetzte KI-Systeme verschiedene spezialisierte Komponenten, um Leistung, Flexibilität und Anpassungsfähigkeit zu verbessern.
Ein aktuelles Video aus Stanford skizzierte die Entwicklung der Skalierung in der KI in verschiedenen Epochen und konzentrierte sich darauf, wie sich der Schwerpunkt von der modellorientierten Entwicklung zur Integration auf Systemebene verlagert hat
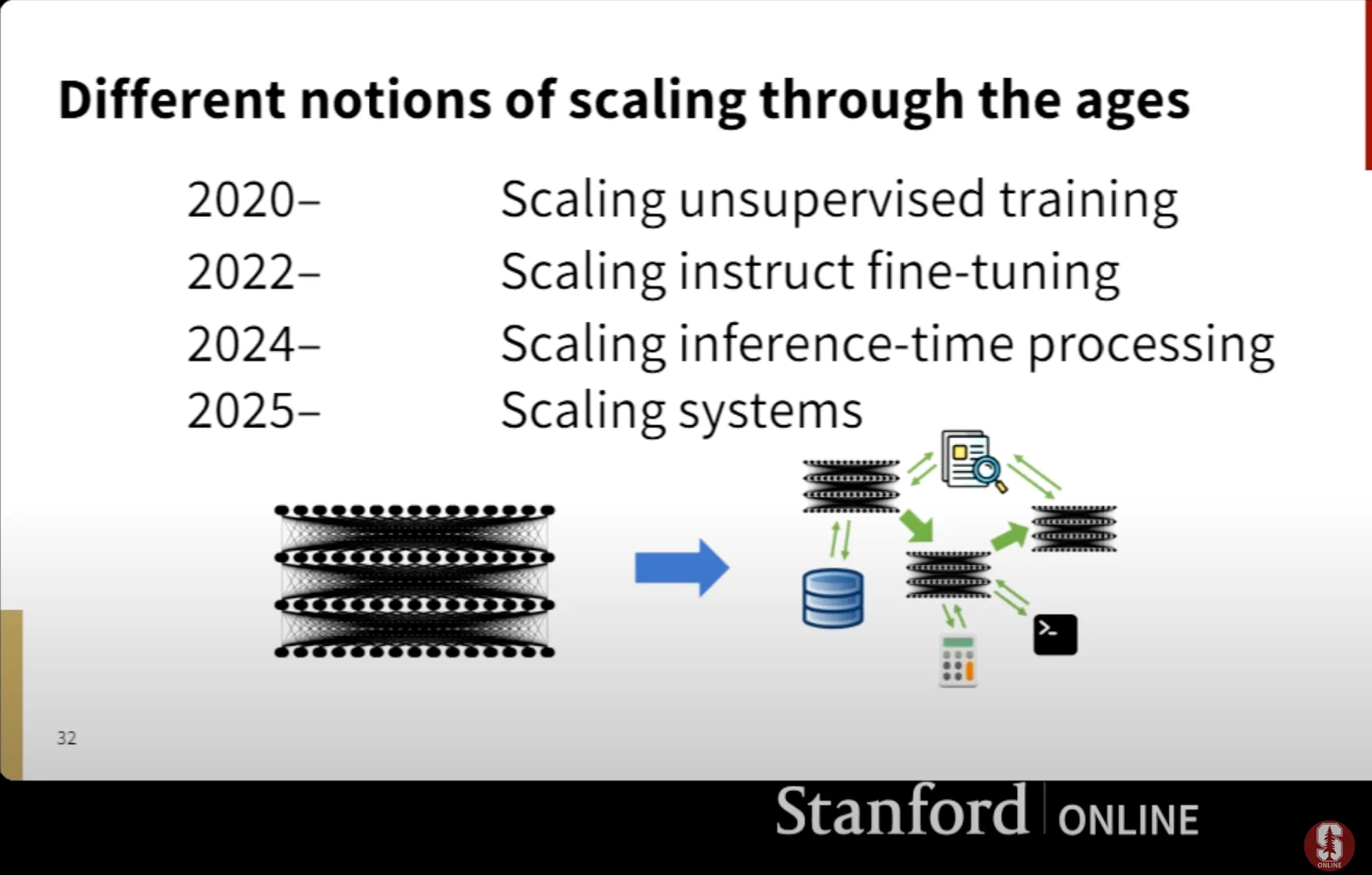
Skalierung unbeaufsichtigter Schulungen (2020—) - Dies begann mit der Veröffentlichung von GPT-3, das die Leistungsfähigkeit des groß angelegten unbeaufsichtigten Trainings demonstrierte. Beim unbeaufsichtigten Training werden Modelle riesigen Mengen unstrukturierter Daten ausgesetzt, wie z. B. Text aus dem Internet, damit sie Muster ohne spezifische Aufgabenbezeichnungen verallgemeinern können.
Feinabstimmung von Scaling Instructs (2022—) - Diese Ära war geprägt von der Einführung von Anwendungen wie ChatGPT, die Tuning von Anweisungen und Feinabstimmungstechniken. Die Feinabstimmung von Instruktionen beinhaltet die Bereitstellung von Input-Output-Paaren (z. B. Frage-Antwort-Datensätze), um vorab trainierte Modelle an bestimmte Fähigkeiten anzupassen.
Skalierung der Inferenzzeitverarbeitung (2024—) - Dies bezieht sich auf Innovationen, die darauf abzielen, die Echtzeitnutzung von KI-Modellen während der Inferenz zu optimieren. Es konzentriert sich auf die Verbesserung der Effizienz, der Reaktionszeiten und der Anpassungsfähigkeit durch mehrstufiges Denken, „Gedankenketten“, Speicheroptimierung usw
Systeme skalieren (2025—) - Wir gehen von großen Sprachmodellen (LLMs) zu zusammengesetzten Systemen über und gehen von eigenständigen Modellen zu integrierten Systemen über, die Modelle, Tools, APIs und Infrastruktur kombinieren.
Herausforderungen an die Infrastruktur
Kombinierte KI-Systeme erfordern die nahtlose Fähigkeit, je nach den spezifischen Anforderungen der einzelnen Komponenten zwischen GPUs, CPUs und anderer spezialisierter Hardware zu wechseln. Beispielsweise kann ein Vision-Modell eine GPU-Beschleunigung erfordern, während eine Datenbankabfrage von der CPU-Effizienz abhängen kann. Die Bestimmung der optimalen Ressourcenkonfigurationen für jeden Workload und die dynamische Anpassung der Infrastruktur an sich ändernde Anforderungen sind von entscheidender Bedeutung. Die regelmäßige Überwachung und Feinabstimmung der Infrastruktur stellt sicher, dass das System effizient und kostengünstig arbeitet, auch wenn sich Workloads oder Modellanforderungen ändern.
Um sicherzustellen, dass zusammengesetzte KI-Systeme effizient skaliert werden können, müssen automatische Skalierungsmechanismen implementiert werden, die Ressourcen auf der Grundlage der Workload-Anforderungen dynamisch zuweisen. Dazu gehört die Überwachung der Systemnutzung wie CPU, GPU, Arbeitsspeicher und Netzwerkbandbreite, um Änderungen in Echtzeit vorherzusagen und darauf zu reagieren.
Prohibitive Kosten
Die gleichzeitige Ausführung mehrerer KI-Modelle, insbesondere in Echtzeit, führt zu hohen Rechen-, Speicher- und Cloud-Kosten. Der Aufbau einer Infrastruktur, die die Erkennung von Ressourcenineffizienzen ermöglicht und einen nahtlosen Wechsel zwischen Konfigurationen unterstützt, ist unerlässlich. Der Einsatz von Strategien wie Spot-Computing, fraktionierten GPUs und Auto-Scaling gewährleistet die Wirtschaftlichkeit bei gleichzeitiger Aufrechterhaltung einer optimalen Leistung.
Integration in die bestehende Infrastruktur
Moderne Infrastrukturen bestehen häufig aus stark verteilten Architekturen, Multi-Cloud-Umgebungen und speziellen Tools, die auf bestimmte Workflows zugeschnitten sind. Diese Setups sind zwar fortgeschritten, bringen jedoch Komplexität mit sich, wenn neue KI-Komponenten hinzugefügt werden, die innerhalb eines bereits komplizierten Ökosystems harmonisch funktionieren müssen.
Schnelleres Experimentieren
Schnelleres Experimentieren ist eine entscheidende Voraussetzung für den Erfolg zusammengesetzter KI-Systeme. Sie ermöglichen es Teams, schnell zu iterieren, neue Ideen zu testen und die Leistung zu optimieren.
Die modulare Architektur ermöglicht es Teams, Modelle auszutauschen, Pipelines anzupassen oder neue Algorithmen mit minimaler Unterbrechung zu integrieren.Automatisierung spielt ebenfalls eine wichtige Rolle, da Tools wie CI/CD-Pipelines eine reibungslose Bereitstellung und das Testen aktualisierter Komponenten gewährleisten.
Lesen Sie unsere ausführlicher Blog zur Integration von TrueFoundry in MongoDB.
Beschleunigen Sie die Markteinführungszeit mit MongoDB Atlas
Die native Vektorsuche von MongoDB Funktionen vereinfachen die Implementierung anspruchsvoller RAG-Workflows (Retrieval-Augmented Generation), indem die Vektorsuche in eine betriebsbereite Datenbank eingebettet wird. Dadurch entfällt die Notwendigkeit separater Vektordatenbanken, was die Komplexität der Infrastruktur reduziert und eine schnellere Bereitstellung ermöglicht.
Schnelle Iteration mit Flexibilität
Das dokumentenbasierte Datenmodell von MongoDB ist von Natur aus flexibel und eignet sich daher ideal für die Speicherung multimodaler Datentypen wie Text, Bilder und Vektoreinbettungen. Entwickler können neue Datentypen ohne Ausfallzeiten oder Neugestaltung des Schemas integrieren, was eine schnellere Optimierung, Optimierung und Iteration für GENAI-gestützte Anwendungen ermöglicht.
Skalierbarkeit und Sicherheit für Unternehmen
MongoDB Atlas bietet Fehlertoleranz auf Unternehmensebene, horizontale Skalierung und standardmäßig sichere Funktionen wie abfragbare Verschlüsselung. Die vollständig verwaltete, serverlose Architektur unterstützt elastische Skalierung und verbrauchsabhängige Preisgestaltung und gewährleistet so einen kostengünstigen Betrieb selbst für die anspruchsvollsten Workloads.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.









.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




