

October 5, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
In unserer Blogserie zu Kubernetes haben wir über Gebäude gesprochen skalierbare MLOps auf Kubernetes, Architektur für MLOps, und Lösung der Anwendungsentwicklung. In diesem Blog werden wir über das Hosten eines GRPC-Dienstes auf einem AWS EKS-Cluster sprechen. Der Vorgang wird für jeden Kubernetes-Cluster ungefähr der gleiche sein. Wir mussten jedoch einige spezifische Einstellungen am AWS Load Balancer vornehmen, damit dies funktioniert.
gRPC ist ein Open-Source-RPC-Framework, das in jeder Umgebung ausgeführt werden kann. Es ist in der Lage, Dienste innerhalb und zwischen Rechenzentren effizient zu verbinden und bietet zusätzlich Unterstützung für Lastenausgleich, Tracing, Integritätsprüfung und Authentifizierung.
Unser Anwendungsfall: Hosten von Tensorflow-Modellen als APIs, die eine Nutzlast von etwa 100 MB akzeptierten. GRPC schneidet bei größeren Nutzlasten viel besser ab. Deshalb haben wir den GRPC-Port auf Port 5000 verfügbar gemacht.
Wir haben den Dienst auf Kubernetes mit dem folgenden Deployment YAML gehostet:
API-Version: Apps/v1
Art: Einsatz
Metadaten:
Name: ml-api
Namensraum: ml-services
spezifikation:
Repliken: 1
Selektor:
Labels abgleichen:
truefoundry.com/component: ml-api
schablone:
Metadaten:
Beschriftungen:
truefoundry.com/application: ml-api
spezifikation:
Behälter:
- Name: ml-api
bild: >-
XXXX.dkr. ecr.us-east-1.amazonaws.com /ml-services-ml-api:latest
Anschlüsse:
- Name: port-8500
Containerhafen: 8500
Protokoll: TCP
Ressourcen:
Grenzwerte:
Zentralprozessor: '4'
kurzlebiger Speicher: 2G
Speicher: 4G
Anfragen:
Zentralprozessor: '1'
kurzlebiger Speicher: 1 G
Speicher: 500M
ImagePullPolicy: Wenn nicht vorhanden
Neustartrichtlinie: Immer
Nachfrist bei Beendigung (Sekunden): 30
DNS-Richtlinie: ClusterFirst
Sicherheitskontext: {}
Bild Pull Secrets:
- Name: ml-api-image-pull-secret
SchedulerName: Standard-Scheduler
Strategie:
Typ: RollingUpdate
Laufendes Update:
Max. nicht verfügbar: 25%
Max. Überspannung: 0
Dadurch wird die Kapsel hochgefahren. Wir müssen das Service-Objekt mit der folgenden YAML erstellen:
API-Version: networking.istio.io/v1alpha3
Art: Gateway
Metadaten:
Beschriftungen:
argocd.argoproj.io/instance: tfy-istio-ingress
Name: tfy-wildcard
Namensraum: istio-system
spezifikation:
Selektor:
Site: tfy-istio-ingress
Server:
- Gastgeber:
- 'ml.example.com'
Hafen:
Name: http-tfy-Wildcard
nummer: 80
Protokoll: HTTP
tls:
HttpsRedirect: wahr
- Gastgeber:
- 'ml.example.com'
Hafen:
Name: https-tfy-wildcard
nummer: 443
Protokoll: HTTP
Wir verwenden Istio als Ingress-Layer in Kubernetes. Istio stellt einen Load Balancer bereit, wenn der Istio-Ingress installiert ist. Die Load Balancer-Konfiguration kann mithilfe von Anmerkungen auf dem Istio-Gateway angepasst werden. Die Spezifikation für die Erstellung des Istio Gateways lautet wie folgt:
API-Version: networking.istio.io/v1alpha3
Art: Gateway
Metadaten:
Beschriftungen:
argocd.argoproj.io/instance: tfy-istio-ingress
Name: tfy-wildcard
Namensraum: istio-system
spezifikation:
Selektor:
Site: tfy-istio-ingress
Server:
- Gastgeber:
- 'ml.example.com'
Hafen:
Name: http-tfy-Wildcard
nummer: 80
Protokoll: HTTP
tls:
HttpsRedirect: wahr
- Gastgeber:
- 'ml.example.com'
Hafen:
Name: https-tfy-wildcard
nummer: 443
Protokoll: HTTP
Wir führen die SSL-Terminierung auf dem AWS Load Balancer durch. Dazu müssen wir das Zertifikat an den Load Balancer anhängen. Dies kann mithilfe der Anmerkungen unten zum Istio-Gateway-Diagramm (https://istio-release.storage.googleapis.com/charts) erreicht werden.
„service.beta.kubernetes.io/aws-load-balancer-type“: „nlb“
„service.beta.kubernetes.io/aws-load-balancer-backend-protocol“: „tcp“
<certificate-arn>„service.beta.kubernetes.io/aws-load-balancer-ssl-cert“: "“
„service.beta.kubernetes.io/aws-load-balancer-ssl-ports“: „https“
„service.beta.kubernetes.io/aws-load-balancer-alpn-policy“: „Http2-bevorzugt“
Es ist wichtig, die alpn-Policy anzugeben, um GRPC-Verkehr zuzulassen. Unser Dienst ml-api kann verfügbar gemacht werden, indem ein VirtualService erstellt wird, der auf den Kubernetes-Dienst verweist. Die YAML für den virtuellen Dienst lautet wie folgt:
API-Version: networking.istio.io/v1alpha3
Art: VirtualService
Metadaten:
Beschriftungen:
argocd.argoproj.io/instance: ml-services_ml-api
Name: ml-apiport-8500-vs
Namensraum: ml-services
spezifikation:
Gateways:
- istio-system/tfy-wildcard
Gastgeber:
- ml.example.com
http:
- Route:
- Reiseziel:
Gastgeber: ml-api
Hafen:
nummer: 8500
Sobald der virtuelle Dienst verfügbar ist, können wir Anfragen an unseren Dienst unter ml.example.com stellen. Dann wollten wir der API eine Authentifizierung hinzufügen, damit nicht jeder die API aufrufen kann. Wir hätten die Authentifizierung im Code hinzufügen können, aber wir haben beschlossen, sie auf der Istio-Ebene hinzuzufügen, damit sie eine einheitliche Ebene für alle Dienste darstellt.
Um die Authentifizierung auf der Istio-Ingress-Ebene hinzuzufügen, haben wir uns für eine entschieden IstioWASM-Plugin. Das Yaml für das Plugin sieht ungefähr so aus:
API-Version: extensions.istio.io/v1alpha1
Art: WASM-Plugin
Metadaten:
Name: ml-services-ml-api-0
Namensraum: istio-system
spezifikation:
Phase: AUTHN
Plugin-Konfiguration:
grundlegende Authentifizierungsregeln:
- Referenzen:
- Benutzername:Passwort
Gastgeber:
- ml.example.com
Präfix:/
Anforderungsmethoden:
- BEKOMMEN
- SETZEN
- BEITRAG
- AUFNÄHER
- LÖSCHEN
Selektor:
Labels abgleichen:
Site: tfy-istio-ingress
url: oci: //ghcr.io/istio-ecosystem/wasm-extensions/basic_auth:1.12.0
Sobald Sie die obige Spezifikation auf den Cluster angewendet haben, fragt die App nach dem Benutzernamen und dem Passwort, sobald Sie sie im Browser öffnen.
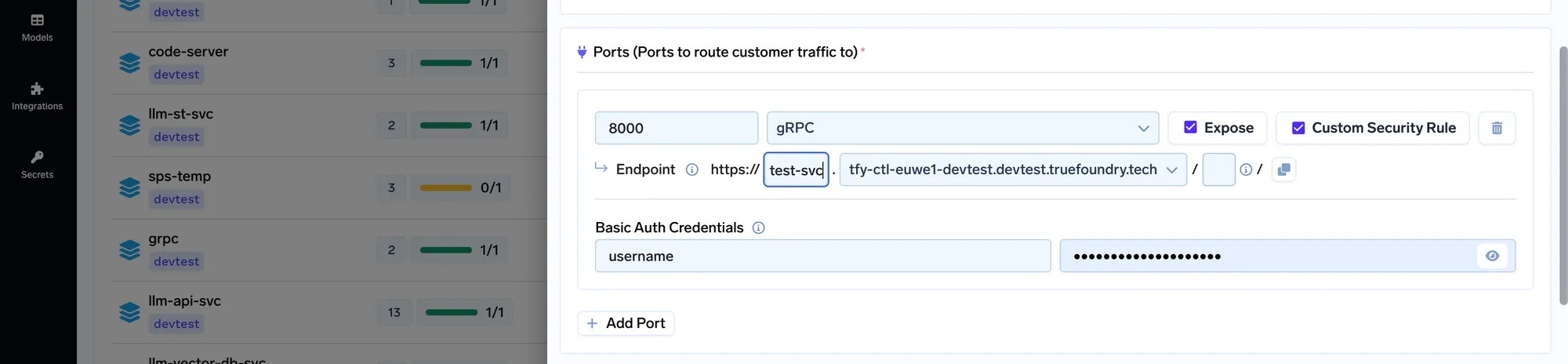
Um den oben genannten Prozess erheblich zu vereinfachen, beschließen wir, es auf der Echte Gießerei plattform.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.








.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




