
.webp)
July 2, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 27, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Wenn Teams LLM-Anwendungen und KI-Agenten in die Produktion überführen, werden die Kosten schnell zu einem der schwierigsten Probleme, über die man nachdenken muss. Im Gegensatz zu herkömmlichen Cloud-Workloads werden die KI-Kosten durch dynamische, nicht deterministische Nutzungsmuster bestimmt, die oft hinter mehreren Abstraktionsebenen verborgen sind.
Eine einzelne Benutzeranfrage kann mehrere Modellaufrufe, Wiederholungsversuche, Tool-Aufrufe und Agenten-Schleifen auslösen. Kleine Änderungen der Eingabeaufforderungen, der Routing-Logik oder des Agentenverhaltens können die Token-Nutzung und die Kosten erheblich erhöhen, oft ohne offensichtliche Signale, bis die Abrechnungsberichte eintreffen.
Das ist der Grund Beobachtbarkeit der KI-Kosten ist in Produktionssystemen von entscheidender Bedeutung. Es geht über die Verfolgung der Anzahl der Tokens oder der Rechnungen von Anbietern hinaus. Die KI-Kostenbeobachtbarkeit konzentriert sich darauf, die Kosten den tatsächlichen Einheiten von KI-Systemen zuzuordnen, z. B. Anfragen, Aufforderungen, Agenten, Tools und Benutzern, und ermöglicht es den Teams gleichzeitig, Kostenprobleme frühzeitig zu erkennen und zu kontrollieren.
In diesem Blog erklären wir, was KI-Kostenbeobachtbarkeit in der Praxis bedeutet, warum KI-Kosten schwer nachzuverfolgen sind und wie Teams Gateway-basierte Architekturen verwenden, um LLM-Ausgaben in der Produktion zu überwachen und zu kontrollieren.
KI-Kostenbeobachtbarkeit ist die Fähigkeit die Kosten von KI-Workloads messen, zuordnen und analysieren über Modelle, Agenten und Workflows hinweg in Echtzeit.
In Produktionssystemen umfasst dies in der Regel:
In der Praxis reicht dies über einfache Abrechnungs-Dashboards hinaus bis hin zu strukturierten LLM-Lösung zur Kostenverfolgung, wo Token-Nutzung, Wiederholungsversuche, Routing-Entscheidungen und Agentenverhalten direkt mit realen Anwendungsworkflows verknüpft sind.
Im Gegensatz zur herkömmlichen Infrastrukturkostenüberwachung muss die KI-Kostenbeobachtbarkeit auf Anwendungs- und Inferenzebene erfolgen. Cloud-Abrechnungstools können Teams sagen, wie viel sie insgesamt ausgegeben haben, aber sie erklären es nicht warum die Kosten sind gestiegen oder welcher Teil des Systems hat das verursacht.
Eine effektive KI-Kostenbeobachtbarkeit bietet Teams den Kontext, den sie benötigen, um Fragen wie die folgenden zu beantworten:
Indem die Kosten auf dieser Ebene sichtbar gemacht werden, können Teams die KI-Ausgaben als betriebliche Kennzahl und nicht als Überraschungsausgabe betrachten.
KI-Kosten sind schwer nachzuverfolgen, nicht weil die Preisgestaltung undurchsichtig ist, sondern weil Kosten sind eine emergente Eigenschaft des Systemverhaltens. In Produktionsumgebungen wird die LLM-Nutzung von Routing-Logik, Wiederholungsversuchen, Agenten und Toolaufrufen geprägt, die alle auf nicht offensichtliche Weise interagieren.
Verschiedene Faktoren machen die Beobachtbarkeit der KI-Kosten für Teams zu einer Herausforderung.
Die meisten LLM-Anbieter berechnen auf der Grundlage von Tokens, aber die Token-Nutzung hängt stark vom Laufzeitverhalten ab. Kleine Änderungen der Eingabeaufforderungen, der Kontextgröße oder der Ausgabebeschränkungen können die Anzahl der Token erheblich erhöhen. Da diese Änderungen häufig auf Anwendungs- oder Eingabeaufforderungsebene vorgenommen werden, sind sie bei alleiniger Abrechnung auf Anbieterebene schwer zu erkennen.
Produktionssysteme verlassen sich selten auf ein einziges Modell. Teams leiten Anfragen an mehrere Modelle und Anbieter weiter, um Kosten, Latenz und Qualität in Einklang zu bringen. Ohne eine zentrale Ansicht sind die Kostendaten zwischen den Anbietern fragmentiert, was es schwierig macht, die Ausgaben ganzheitlich zu vergleichen oder zu optimieren.
Ausfälle sind in KI-Systemen teuer. Wiederholungen und Fallback-Logik können im Hintergrund die Kosten vervielfachen, insbesondere wenn Anfragen über mehrere Modelle hinweg kaskadieren. Ohne Beobachtbarkeit auf Anforderungsebene übersehen Teams diese versteckten Kostenmultiplikatoren oft, bis sie in den Gesamtrechnungen auftauchen.
Agentenbasierte Systeme erhöhen die Kostenkomplexität. Ein einziger Agentenlauf kann mehrere Modellaufrufe, Planungsschritte und Tool-Aufrufe umfassen. Wenn ein Agent in eine Warteschleife gerät oder Tools übermäßig nutzt, können die Kosten schnell eskalieren. Um dieses Verhalten zu verfolgen, müssen die Agenten Schritt für Schritt nachvollziehen können.
Cloud-Kostentools und Anbieter-Dashboards melden die Nutzung auf Konto- oder Projektebene. Sie führen die Kosten nicht auf Eingabeaufforderungen, Agenten, Benutzer oder Workflows zurück. Das macht es für Plattformteams schwierig, Budgets durchzusetzen, oder für Anwendungsteams, ihre eigene Nutzung zu optimieren.
In der Praxis bedeuten diese Herausforderungen, dass KI-Kostenprobleme oft erst spät erkannt und reaktiv angegangen werden. Aus diesem Grund benötigen Teams, die KI-Workloads in der Produktion ausführen, eine integrierte Kostenbeobachtbarkeit AI-Gateway und Ausführungspfad, wo alle Anfragen durchgehen.
Um die KI-Ausgaben in der Produktion zu kontrollieren, benötigen Teams mehr als eine monatliche Gesamtrechnung. Sie müssen verstehen woher kommen die Kosten und warum. Die Beobachtbarkeit der Kosten baut auf LLM-Beobachtbarkeit indem die Token-Nutzung und die Ausgaben an Eingabeaufforderungen, Agenten und Workflows gebunden werden. Effektive KI-Kostenbeobachtbarkeit unterteilt die Ausgaben nach Dimensionen, die der Art und Weise entsprechen, wie KI-Systeme tatsächlich gebaut und betrieben werden.
Zu den nützlichsten Kostendimensionen gehören die folgenden.
Das ist die Grundlage. Die Erfassung der Kosten pro Anfrage hilft Teams zu verstehen, wie teuer einzelne Benutzerinteraktionen sind und wie sich diese Kosten im Laufe der Zeit ändern. Spitzenwerte deuten hier oft auf schnelles Wachstum, Wiederholungsversuche oder Routing-Änderungen hin.
In Systemen mit mehreren Modellen haben verschiedene Modelle sehr unterschiedliche Kostenprofile. Teams benötigen einen Überblick darüber, wie viel Geld für jedes Modell und jeden Anbieter ausgegeben wird und wie sich Routing-Entscheidungen auf die Gesamtkosten auswirken. Dies ist unerlässlich, um fundierte Kompromisse zwischen Qualität, Latenz und Ausgaben eingehen zu können.
Aufforderungen wirken sich direkt auf die Token-Nutzung aus. Durch die Verfolgung der Kosten anhand der Prompt- und Prompt-Version können Teams erkennen, welche Prompts teuer sind und ob die Ausgaben durch jüngste Änderungen gestiegen oder reduziert wurden. Dies ist besonders wichtig, wenn Aufforderungen von mehreren Anwendungen oder Agenten gemeinsam genutzt werden.
In agentenbasierten Systemen muss die Kostenzuweisung über einzelne Modellabrufe hinausgehen. Die Teams müssen verstehen, wie viel ein vollständiger Agentenlauf oder ein vollständiger Arbeitsablauf von Anfang bis Ende kostet, einschließlich Planungsschritte, Tool-Aufrufe und Wiederholungsversuche. Dies hilft, ineffizientes Agentenverhalten frühzeitig zu erkennen.
Bei internen Plattformen und Unternehmensbereitstellungen ermöglicht die Zuordnung der Kosten zu Benutzern oder Teams die Rechenschaftspflicht und Budgetierung. Diese Dimension wird häufig benötigt, um Nutzungsbeschränkungen durchzusetzen oder um interne Kosten auszugleichen.
Die gemeinsame Beobachtung dieser Dimensionen ermöglicht es den Teams, von einer reaktiven Kostenanalyse zur proaktiven Kostenkontrolle überzugehen.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

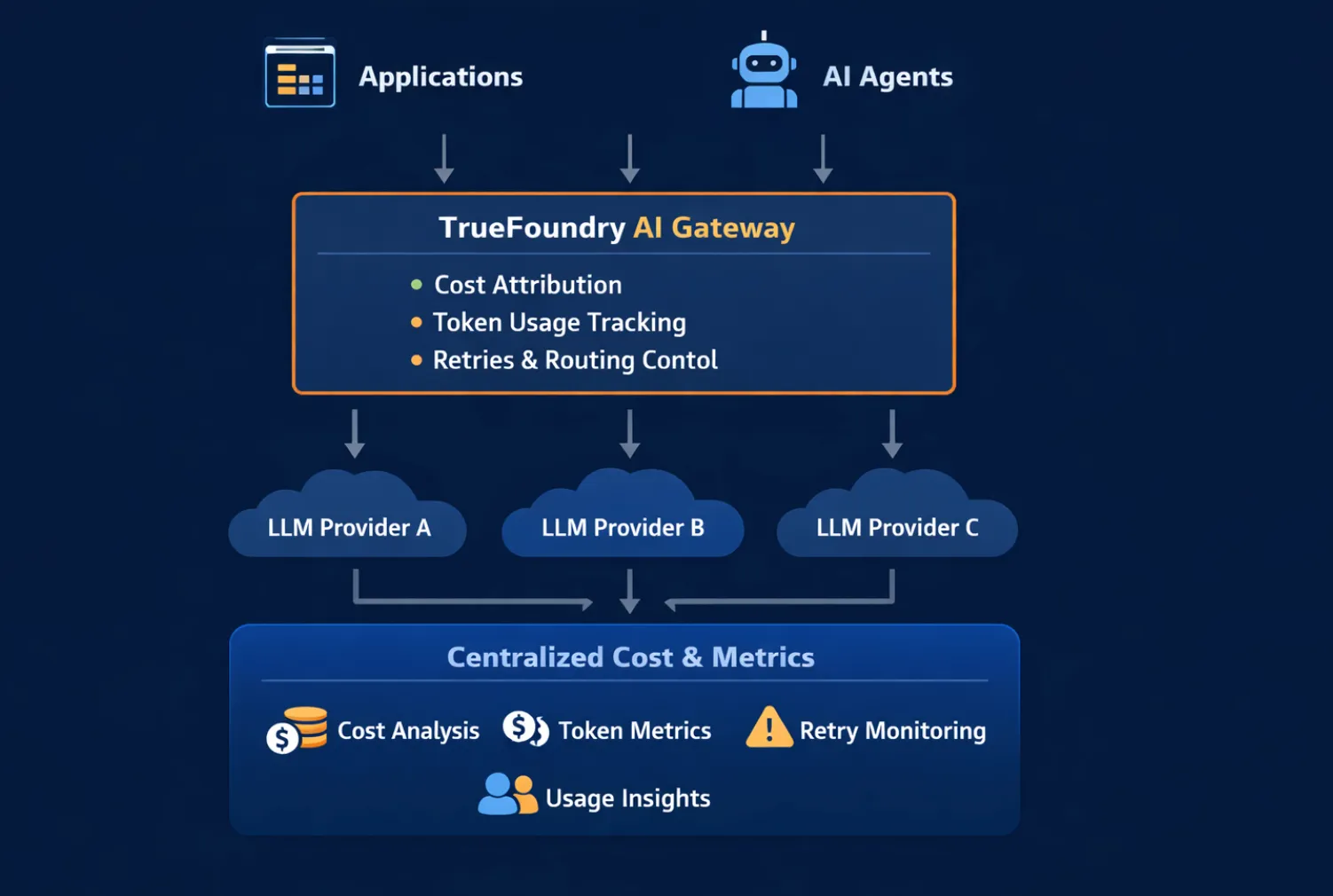
Die KI-Kostenbeobachtbarkeit funktioniert am besten, wenn sie in einem zentraler Abhörpunkt, wo alle Anfragen, Routing-Entscheidungen und Wiederholungen sichtbar sind. Aus diesem Grund spielen KI-Gateways eine entscheidende Rolle.
Ein KI-Gateway befindet sich zwischen Anwendungen oder Agenten und Modelanbietern. Da jede Anfrage durch das Gateway fließt, kann das Gateway:
Ohne ein Gateway sind die Kostendaten über SDKs, Dienste und Anbieter-Dashboards hinweg fragmentiert. Mit einem Gateway werden die Kosten zu einem erstklassigen Signal, das analysiert und umgesetzt werden kann, bevor die Ausgaben eskalieren.
In TrueFoundry ist der KI-Gateway bietet diesen zentralen Kontrollpunkt, der es ermöglicht, die KI-Kosten für Modelle, Agenten und Workflows auf einheitliche Weise zu beobachten und zu verwalten.
Agentenbasierte Systeme erhöhen sowohl die Leistung als auch die Kosten von KI-Workloads. Im Gegensatz zu Anwendungen mit nur einer Anfrage führen Agenten mehrstufige Workflows aus, die Planung, Überlegungen, Wiederholungen und den Einsatz von Tools beinhalten können. Dies macht es schwieriger, das Kostenverhalten vorherzusagen und es ist wichtiger, es genau zu überwachen.
Ein einzelner Agentenlauf kann Folgendes beinhalten:
Ohne angemessene Beobachtbarkeit können diese Interaktionen unbemerkt die Kosten vervielfachen. Agentenschleifen, schlecht begrenzte Eingabeaufforderungen oder übermäßiger Einsatz von Tools bleiben oft unbemerkt, bis die Gesamtausgaben deutlich steigen.
Die KI-Kostenbeobachtbarkeit für Agenten erfordert Sichtbarkeit auf der Ausführungsebene des Agenten, nicht nur auf Model-Call-Ebene. Die Teams müssen Folgendes verstehen:
Hier wird eine Gateway-basierte Architektur besonders wertvoll. Durch die Erfassung der Agentenanfragen am Gateway können Teams die Kosten für den gesamten Lebenszyklus eines Agentenlaufs berechnen, anstatt jeden Modellanruf isoliert zu behandeln.
In TrueFoundry sind Agentenbereitstellungen in das AI Gateway integriert, sodass Teams die Kosten in allen Agentenschritten und Arbeitsabläufen beobachten können. Auf diese Weise können Plattform- und Anwendungsteams ineffizientes Agentenverhalten frühzeitig erkennen und Einschränkungen anwenden, bevor die Kosten in die Höhe schnellen.
.svg)
In Wahre Gießerei, Die KI-Kostenbeobachtbarkeit wird direkt auf der KI-Gateway und Agentenausführungsebene, wo alle Modellanforderungen, Routing-Entscheidungen und Wiederholungen sichtbar sind. Dies bietet eine einheitliche und konsistente Ansicht der Kosten für alle Modelle, Eingabeaufforderungen, Agenten und Workflows.
Da jede Anfrage das Gateway durchläuft, kann TrueFoundry:
Dieser zentralisierte Ansatz wandelt die Kosten von einer passiven Kennzahl in eine um Betriebssignal. Teams können Warnmeldungen bei ungewöhnlichen Ausgaben einrichten, Budgets auf Routing-Ebene durchsetzen und bei der Auswahl von Modellen oder Ausweichstrategien kostenbewusste Entscheidungen treffen.
Für Teams, die KI-Workloads in der Produktion ausführen, wird dadurch sichergestellt, dass die Kosten erhalten bleiben vorhersehbar, erklärbar und kontrollierbar, auch wenn Systeme mit immer mehr Agenten, Modellen und Workflows immer komplexer werden.
Sobald LLM-Anwendungen in Produktion gehen, wird es schwierig, die KI-Kosten zu verwalten. Die Kosten werden nicht mehr durch einen einzelnen Modellaufruf bestimmt, sondern durch eine Kombination aus Aufforderungen, Routing-Entscheidungen, Wiederholungsversuchen, Agenten und der Verwendung von Tools. Ohne angemessene Transparenz entdecken Teams Kostenprobleme oft erst, wenn die Ausgaben bereits gestiegen sind.
Die KI-Kostenbeobachtbarkeit begegnet diesem Problem, indem sie die Kosten zu einem erstklassigen Signal macht. Durch die Zuordnung der Ausgaben nach Anfragen, Modellen, Aufforderungen, Agenten und Workflows können Teams nicht nur nachvollziehen, wie viel sie ausgeben, sondern auch warum. Dieses Maß an Erkenntnissen ist für den zuverlässigen Betrieb von KI-Systemen in großem Maßstab unerlässlich.
Gateway-basierte Architekturen spielen eine zentrale Rolle, um diese Sichtbarkeit zu ermöglichen. Durch die Erfassung von Anfragen an einem einzigen Kontrollpunkt können Teams die KI-Ausgaben über Anbieter und Ausführungspfade hinweg einheitlich beobachten, analysieren und kontrollieren. In TrueFoundry ermöglicht dieser Ansatz Plattform- und Anwendungsteams, Ineffizienzen frühzeitig zu erkennen, Budgets durchzusetzen und Kosten und Leistung abzuwägen, wenn die KI-Workloads zunehmen.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




