

October 5, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
In den letzten Monaten hatten wir die Gelegenheit, mit einem schlanken Team zusammenzuarbeiten. Sie haben ein hochmodernes Deep-Learning-Modell entwickelt und Partnerschaften geschlossen, um es extrem talenten Nutzern zur Verfügung zu stellen.
Das letzte fehlende Stück in ihrer Erfolgsgeschichte war die Handhabung der Technik, um dies zu erreichen. Das Modell war rechenintensiv, und in dem Umfang, in dem sie dieses Modell seinen Endbenutzern anbieten wollten, benötigten sie einen zuverlässigen und leistungsstarken Infrastruktur-Stack, den beide verwalten konnten (1 DevOps Engineer und 1 ML Engineer).
Das Modell wurde für die Verarbeitung von Audioeingängen unterschiedlicher Größe gebaut. Da das Modell eine hohe Verarbeitungszeit hatte (durchschnittlich ~5 Sekunden), benötigte es für jede Anfrage eine asynchrone Inferenz, um diese Anfragen zu verarbeiten und zu beantworten.
Das Team hat seinen ersten Stack für die Bereitstellung des Modells auf Sagemaker erstellt. Als sie jedoch ihr erstes Pilotprojekt mit diesem Design durchführten, wurde ihnen klar, dass es mit diesem Stack schwierig sein würde, das Modell zuverlässig im gewünschten Maßstab bereitzustellen.
Selbst nach der Verwendung des Async-Setups wurde das Endbenutzererlebnis beeinträchtigt, da die Skalierung der Instanzen einige Zeit in Anspruch nahm (8 bis 10 Minuten pro Computer), als sie diese Verzögerung hinnehmen mussten.
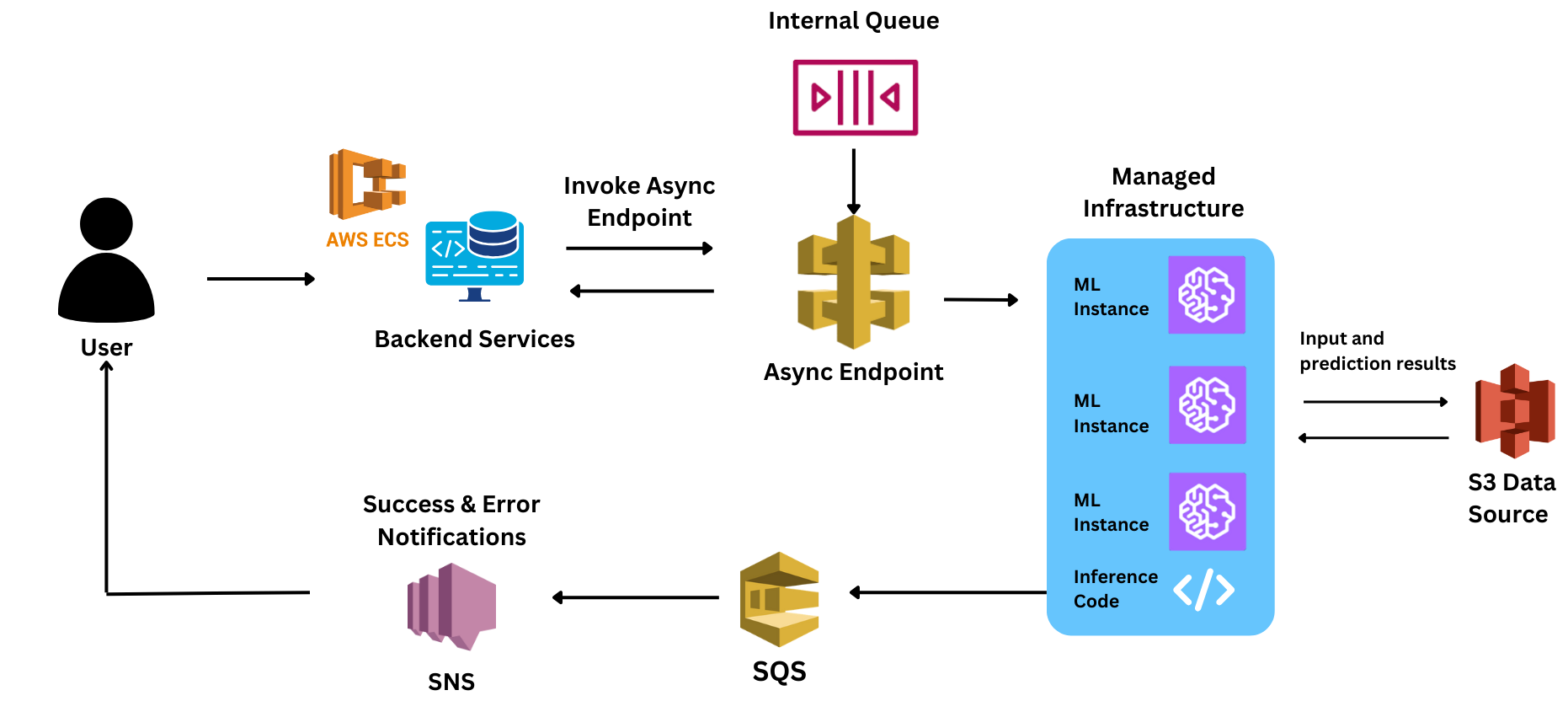
Während des PoC waren sie jedoch mit enormen Verzögerungen bei den Reaktionszeiten konfrontiert. Da sie mit vielen der SageMaker-bezogenen Steuerungen noch nicht vertraut waren, verloren sie wichtige Zeit damit, den Grund für die Verzögerungen zu finden. Einige der Herausforderungen, mit denen sie konfrontiert waren, waren:
Nach dem PoC verlor das Team das Vertrauen in Sagemaker und entschied, dass es eine Lösung benötigte, die die beiden (ein ML Engineer und ein DevOps Engineer) ihrer Zielgruppe von über 10 Millionen Benutzern anbieten konnten.
Als wir anfingen, mit dem Team in Kontakt zu treten, war ihr Pilot ~7 Tage entfernt. Wir versicherten dem Team, dass wir ihnen helfen könnten, den gesamten Stack zu migrieren und ihn mithilfe der TrueFoundry-Module in <2 Tagen neu aufzubauen, sodass sie ausreichend Zeit zum Testen haben, bevor ihr Pilotprojekt in Produktion gehen musste.
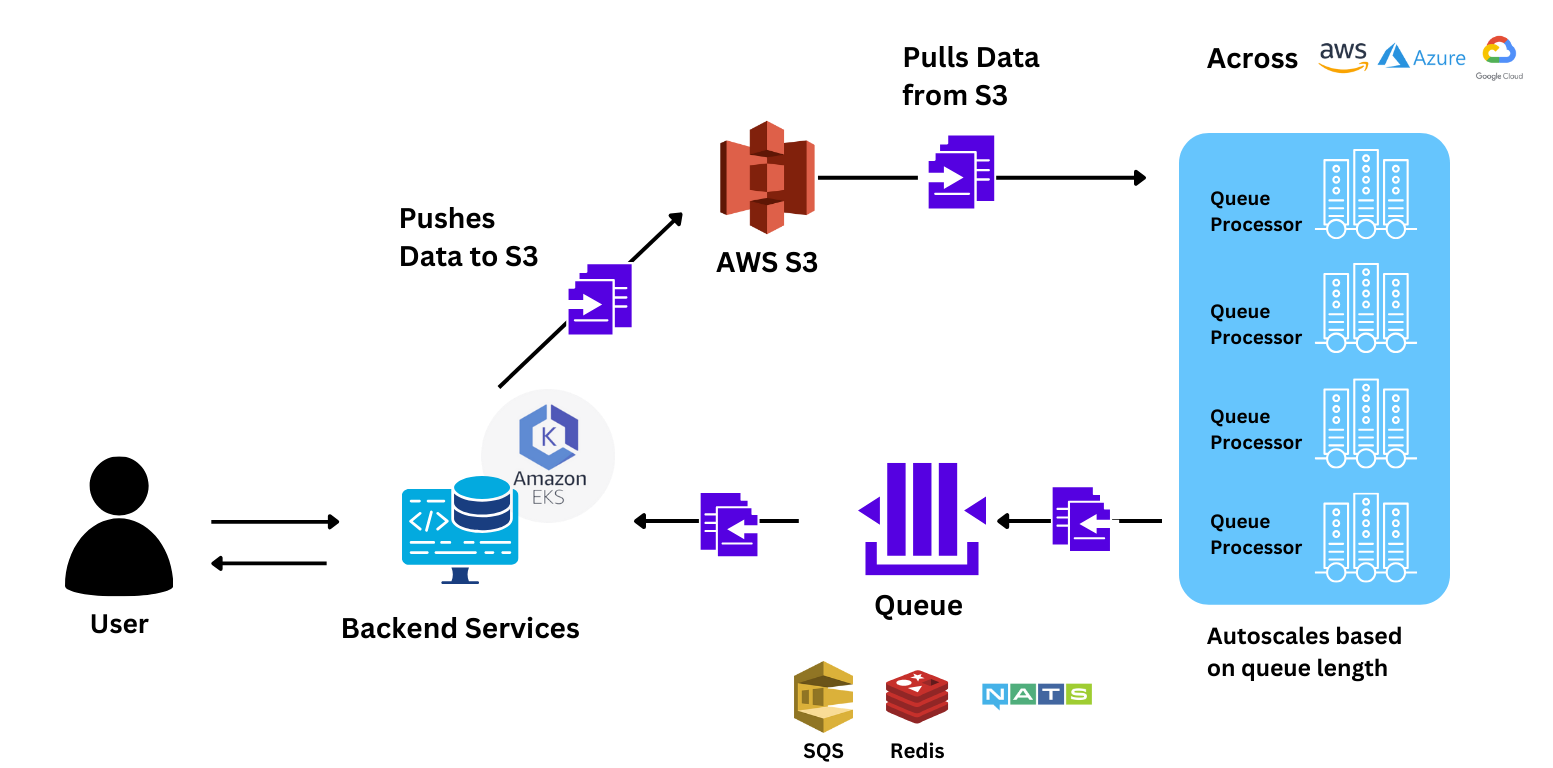
Das Team führte Benchmarks durch, indem es eine Reihe von 88 Anfragen an das Modell sendete, um die Leistung mit der von Sagemaker zu vergleichen. TrueFoundry hochskaliert 78% schneller als Sagemaker, wodurch der Benutzer viel schnellere Antworten erhält. Der Die gesamte Zeit, die für die Beantwortung der Anfrage benötigt wurde, war mit TrueFoundry um 40% schneller.
Das Team war einfach in der Lage, die Anwendung auf über 150 GPU-Knoten zu skalieren, weil:
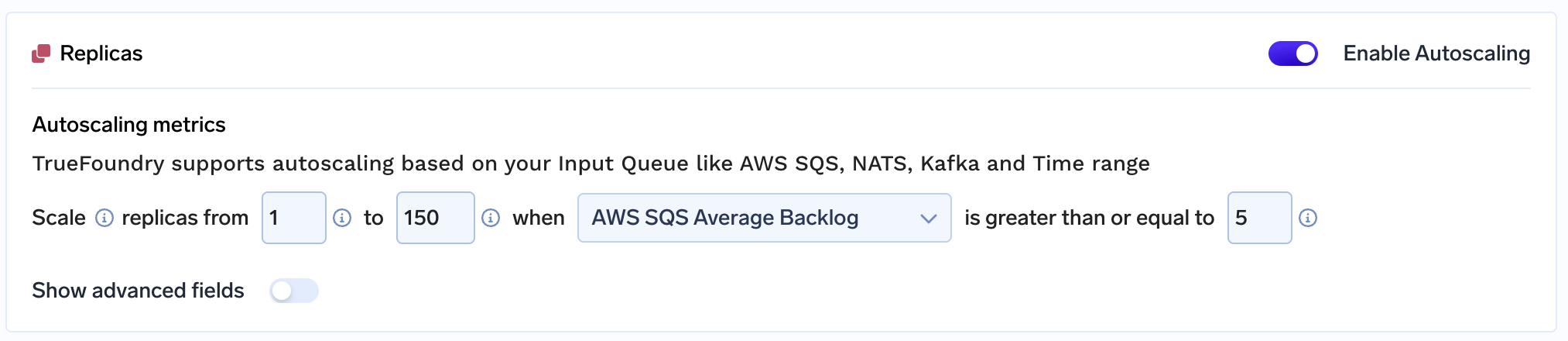

Verwenden Wahre Gießerei, das 2-köpfige Team kann seine gesamte Arbeitslast verwalten, die oft auf mehr als 150 GPU-Knoten skaliert wird!! von selbst. Während der Zusammenarbeit mit uns fielen dem Team vor allem unser Kundensupport und die niedrigen Reaktionszeiten auf. TrueFoundry investiert in den Erfolg seiner Kunden und hofft, dass alle unsere Kunden in einem ähnlichen Maßstab wie bei diesem Projekt skalieren und Wirkung erzielen können!
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.






.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




