Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.
9,9
Avaliação de Desempenho do Gateway LLM da TrueFoundry: é incrivelmente rápido ⚡
O TrueFoundry LLM Gateway oferece uma interface unificada compatível com OpenAI para vários provedores de LLM, como Anthropic, OpenAI, Bedrock, Gemini e muitos outros
O TrueFoundry LLM Gateway escala perfeitamente para 350 RPS em uma única réplica de 1 unidade de CPU, utilizando 270 MB de memória. Comparamos com outro produto de gateway, o LiteLLM, em uma configuração semelhante, e o LiteLLM não conseguiu escalar além de 50 RPS.
O TrueFoundry LLM Gateway adiciona apenas uma latência extra de 3-5 ms, enquanto o LiteLLM adiciona entre 15-30 ms por solicitação.
Por que sua organização precisa de um LLM Gateway?
Um LLM Gateway oferece uma interface unificada para gerenciar o uso de LLM da sua organização:
API Unificada: Acesse vários provedores de LLM através de uma única compatível com OpenAI interface, sem necessidade de alterações no código
Segurança da Chave de API: Gerenciamento seguro e centralizado de credenciais
Governança e Controle: Defina limites, controles de acesso e filtragem de conteúdo
Limitação de Taxa: Evite abusos e garanta o uso justo
Observabilidade: Monitore o uso, custos, latência e desempenho
Balanceamento de Carga: Encaminhe solicitações entre provedores automaticamente
Gestão de Custos: Monitore gastos e defina alertas de orçamento
Trilhas de Auditoria: Registre todas as interações de LLM para conformidade
Qual a velocidade do TrueFoundry LLM Gateway?
Configuração do Teste de Carga
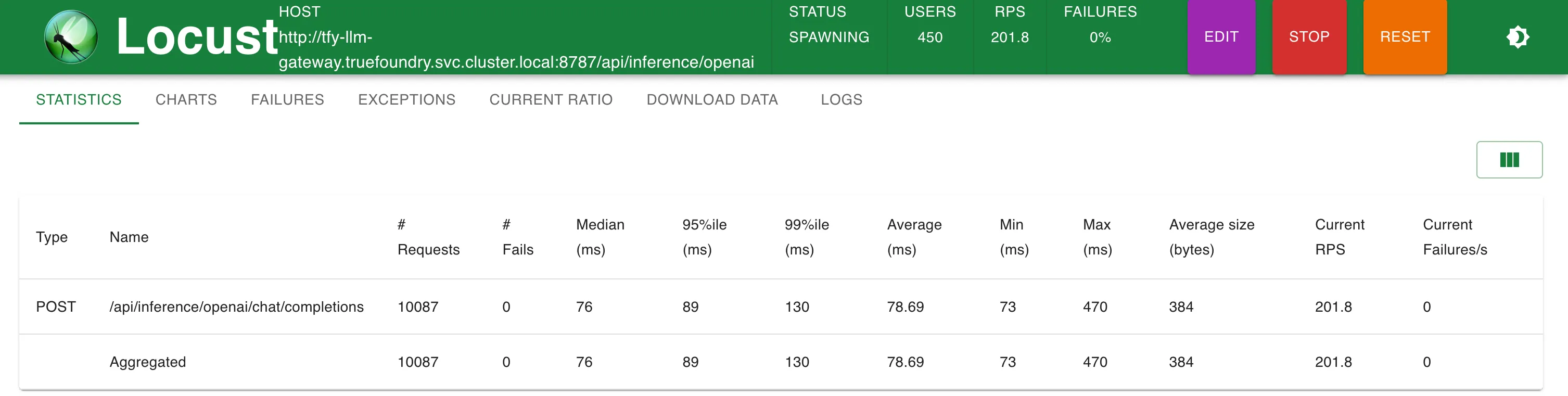
Para o nosso experimento de teste de carga, configuramos e implantamos este serviço de endpoint falso do OpenAI usando TrueFoundry. O serviço simularia o formato de solicitação e resposta do OpenAI sem realmente produzir tokens.
Também implantamos o TrueFoundry LLM Gateway e o LiteLLM Proxy Server, ambos rodando em uma única réplica com 1 unidade de CPU e 1 GB de memória.
Adicionamos nosso provedor OpenAI falso aos gateways TrueFoundry e LiteLLM. Durante o teste de carga, fizemos solicitações ao servidor OpenAI falso de 3 maneiras diferentes:
Configuração 1: Diretamente, sem usar nenhum proxy ou gateway
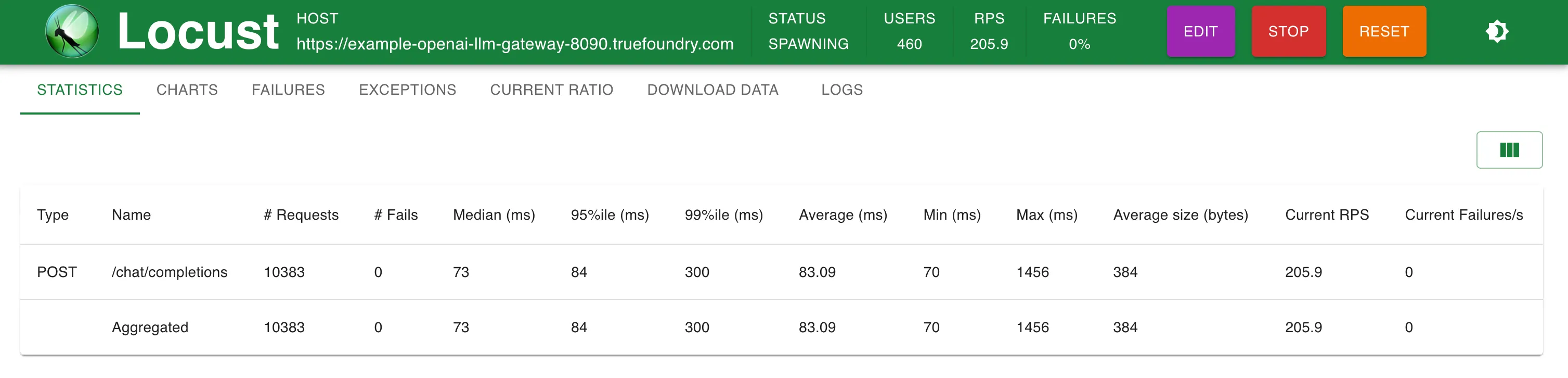
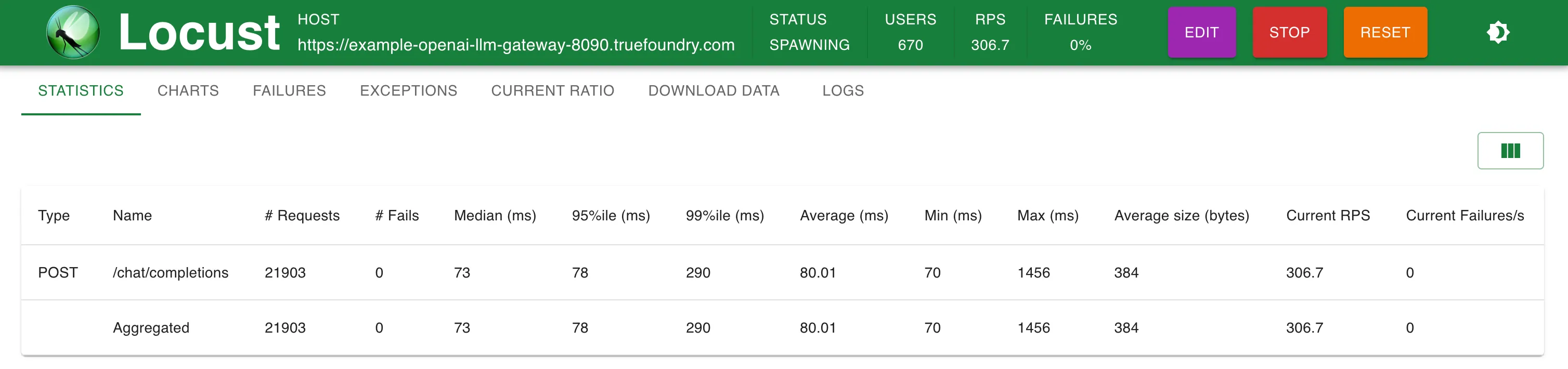
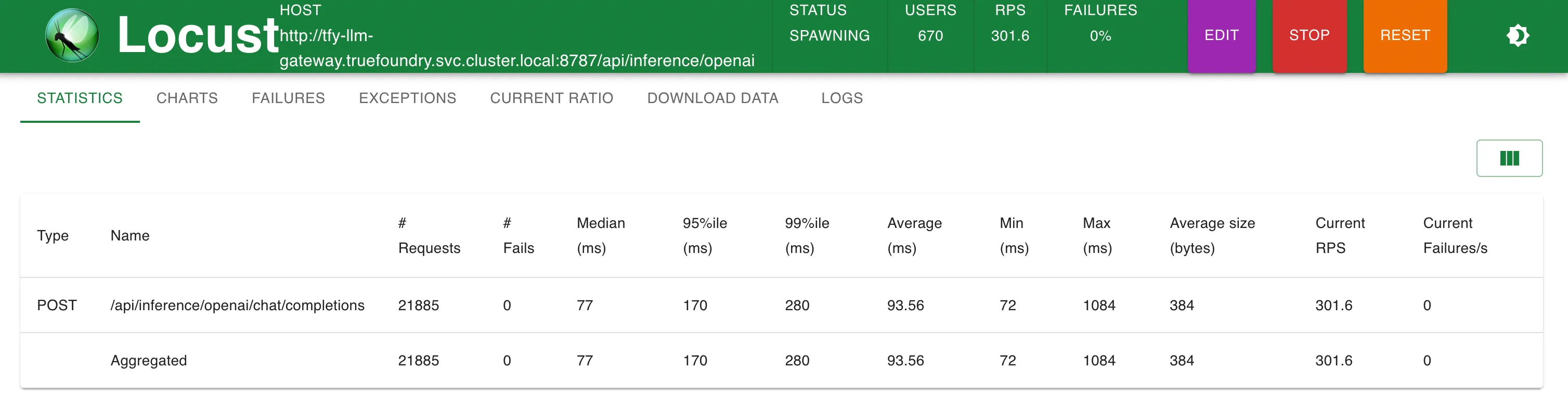
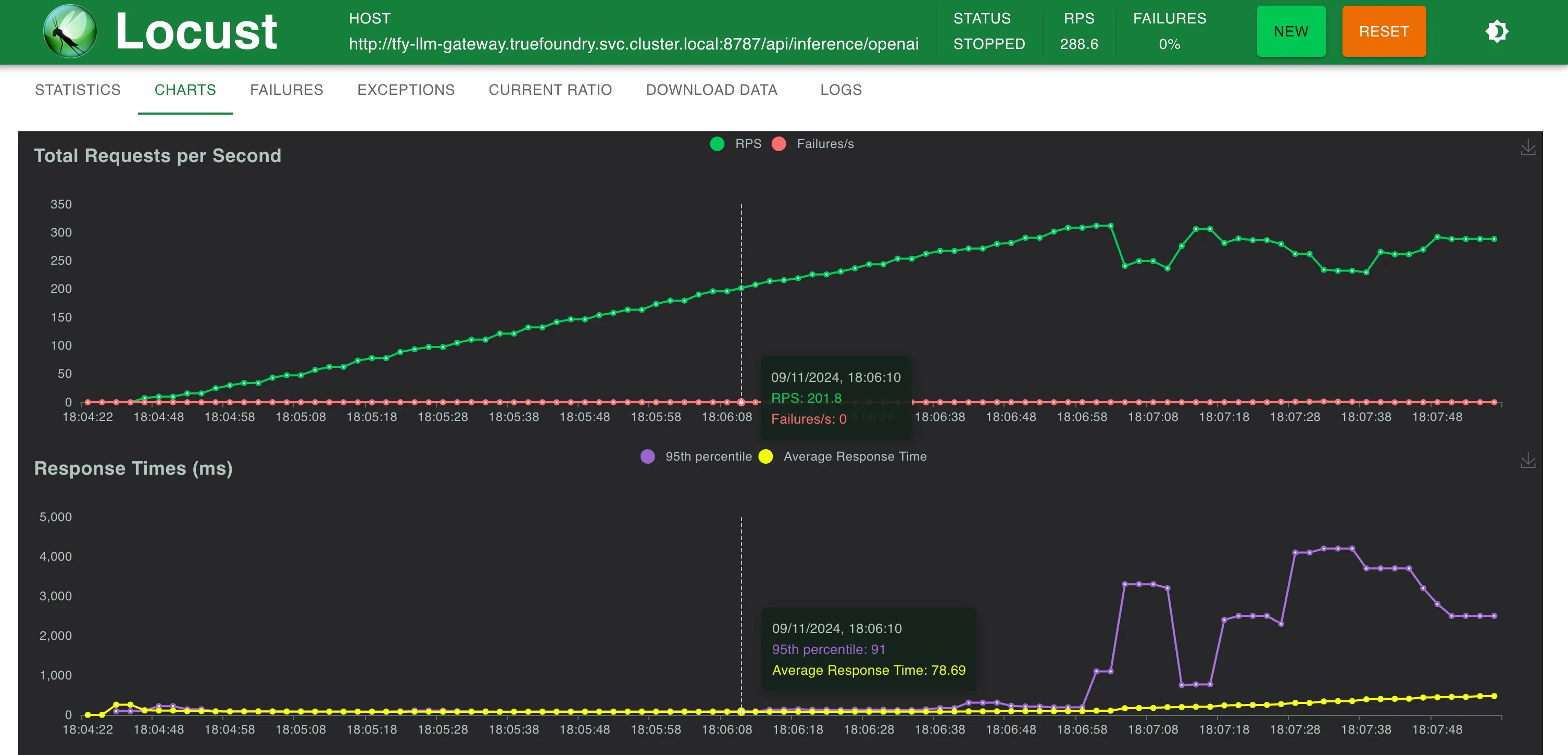
Configuração 2: Através do TrueFoundry LLM Gateway implantado com 1 unidade de CPU e 1 GB de memória
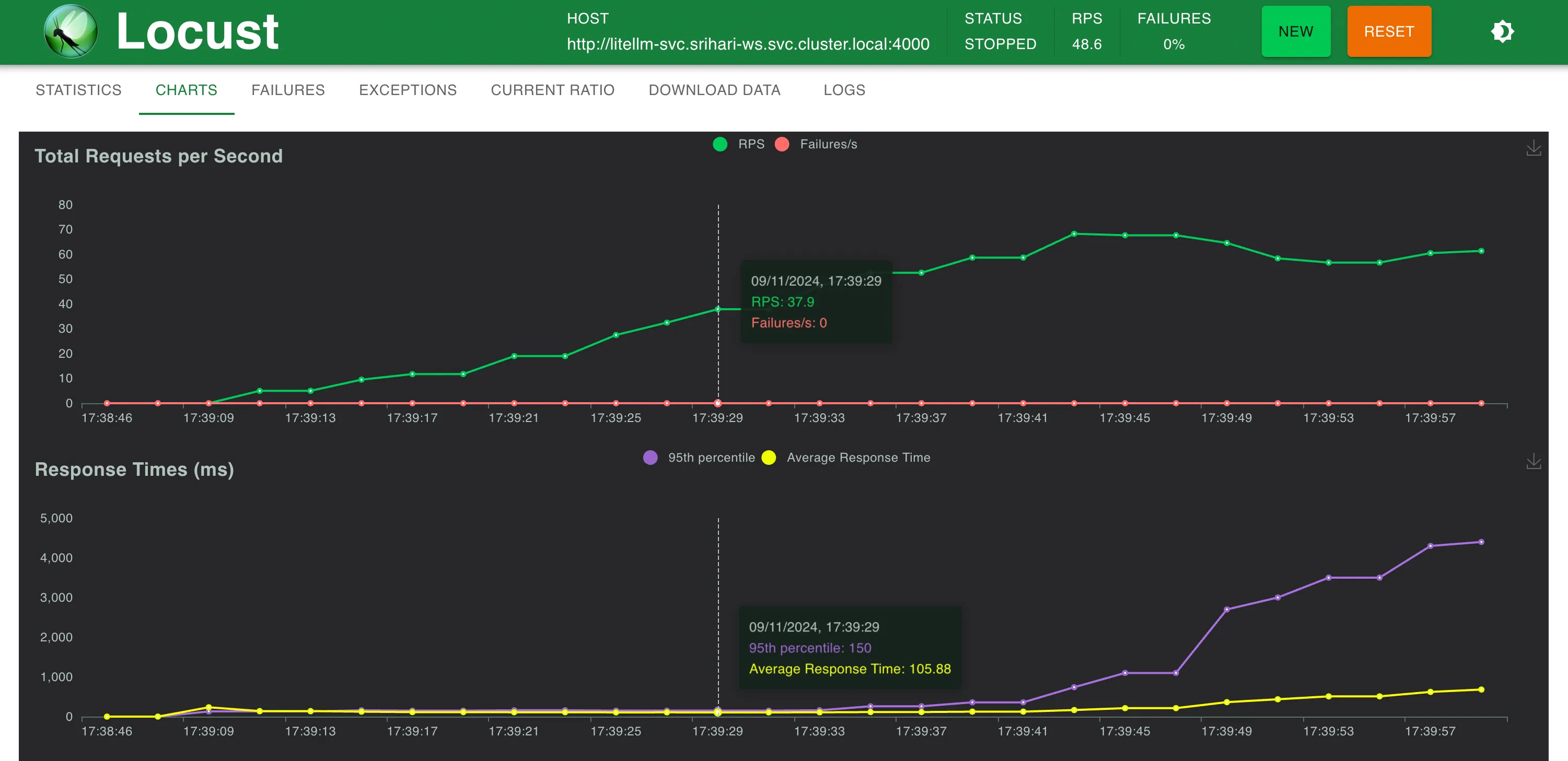
Configuração 3: Através do LiteLLM Proxy Server implantado com 1 unidade de CPU e 1 GB de memória
RPS
10 RPS
50 RPS
200 RPS
300 RPS
OpenAI direct (Setup 1)
73 ms
73 ms
73 ms
73 ms
TrueFoundry LLM Gateway (Setup 2)
76 ms (+3 ms)
76 ms (+3 ms)
76 ms (+3 ms)
77 ms (+4 ms)
LiteLLM Proxy (Setup 3)
88 ms (+15 ms)
99 ms (+26 ms)
Could not scale to 200 RPS
Could not scale to 300 RPS
Observações
O TrueFoundry Gateway adiciona apenas 3 ms extras de latência até 250 RPS e 4 ms para RPS > 300
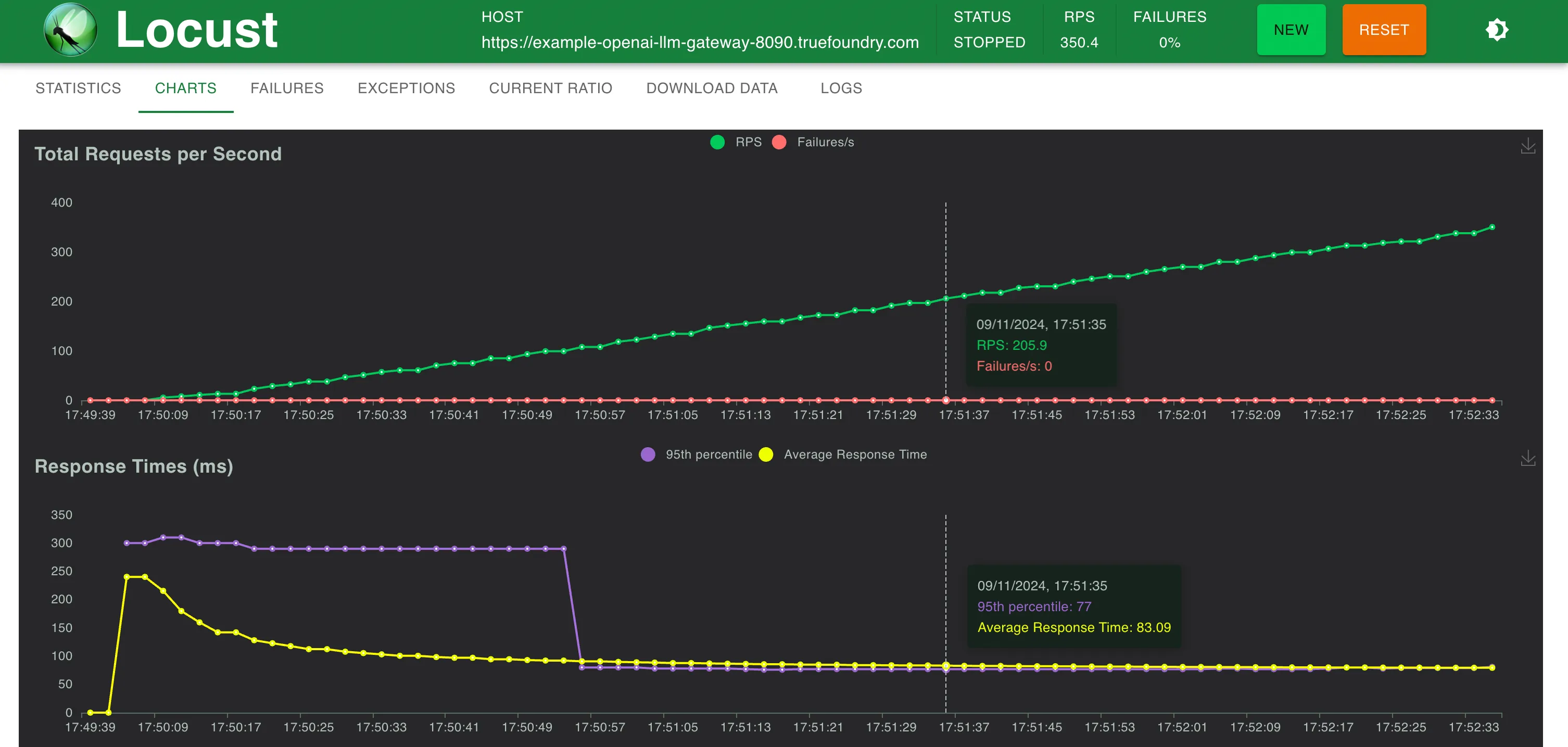
O TrueFoundry LLM Gateway conseguiu escalar sem qualquer degradação de desempenho até aproximadamente 350 RPS (máquina de 1 vCPU, 1 GB) antes que a utilização da CPU atingisse 100% e as latências começassem a ser afetadas. Com mais CPU ou mais réplicas, o LLM Gateway pode escalar para dezenas de milhares de solicitações por segundo.
LiteLLM na mesma máquina não conseguiu escalar além de 40-50 RPS antes de atingir o limite da CPU
Mais métricas
Configuração 1: Chamada direta ao endpoint da OpenAI
Estatísticas a 200 RPS
Estatísticas a 300 RPS
Tempo de Resposta vs. RPS
Configuração 2: Gateway LLM TrueFoundry
Estatísticas a 200 RPS
Estatísticas a 300 RPS
Tempo de Resposta vs. RPS
Configuração 3: LiteLLM
Estatísticas a ~58 RPS
Tempos de resposta vs. RPS
Recursos de velocidade do Gateway LLM
Sobrecarga Quase Zero: Apenas 3-5 ms de latência adicionada
Backend Otimizado: Construído com framework Node.js de alto desempenho
Cache de Configuração: A configuração é armazenada em memória para consulta rápida
Roteamento Inteligente: Sobrecarga mínima de processamento
Pronto para Edge: Implante próximo aos seus aplicativos
Alta Capacidade: Uma t2.2xlarge instância AWS (43$ por mês no spot) pode escalar até ~3000 RPS sem problemas.
Implantação Edge do Gateway LLM da TrueFoundry
Provedores Suportados
Abaixo está uma lista abrangente de provedores LLM populares que são suportados pelo Gateway LLM da TrueFoundry:
Provider
Streaming Supported
GCP
✅
AWS
✅
Azure OpenAI
✅
Self Hosted Models on TrueFoundry
✅
OpenAI
✅
Cohere
✅
AI21
✅
Anthropic
✅
Anyscale
✅
Together AI
✅
DeepInfra
✅
Ollama
✅
Palm
✅
Perplexity AI
✅
Mistral AI
✅
Groq
✅
Nomic
✅
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.


































.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




