Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.
À medida que as organizações implementam mais aplicações baseadas em LLM em suas equipes, uma nova camada de infraestrutura está emergindo como essencial: o gateway de IA. Um gateway de IA se posiciona entre suas aplicações e os serviços ou modelos de IA subjacentes, atuando como um plano de controle central para o tráfego de IA. Ele oferece acesso unificado a dezenas ou centenas de modelos, ao mesmo tempo em que impõe políticas empresariais de segurança, custo e observabilidade. Isso é cada vez mais importante à medida que o uso escala: até 2026, mais de 80% das empresas deverão usar IA generativa, e a Gartner prevê que, até 2028, 70% das equipes de engenharia que constroem aplicações multimodelos dependerão de gateways de IA para melhorar a confiabilidade e controlar os custos. Sem um gateway, cada chamada de cliente de IA deve ser gerenciada individualmente – levando a gastos de tokens não gerenciados, registro fragmentado e lacunas de segurança. Nesse ambiente, um gateway de IA bem projetado torna-se a nova camada de controle para IA empresarial, proporcionando consistência, governança e eficiência que os gateways de API tradicionais não possuem.
O Que É um Gateway de IA e Por Que Ele Importa
Um gateway de IA é uma camada de middleware especializada que gerencia o tráfego entre aplicações e modelos de IA. Ao contrário dos gateways de API convencionais, ele é construído especificamente para cargas de trabalho de IA. Ele lida com preocupações específicas de IA como limitação de taxa em nível de token, respostas de streaming e verificações de segurança de prompts, que os gateways HTTP normais não abordam. Na prática, uma aplicação submete cada requisição de IA primeiro ao gateway: o gateway então autentica a requisição, aplica quaisquer filtros de conteúdo ou guardrails, a roteia para o modelo apropriado e, finalmente, retorna a resposta (possivelmente com seu próprio pós-processamento) de volta para a aplicação. Essa camada centralizada permite recursos como orquestração de modelos (balanceamento ou failover entre diferentes provedores de IA) e faturamento unificado.
A Gartner identificou quatro tarefas fundamentais que um gateway de IA deve executar em empresas modernas: roteamento, segurança/guardrails, controle de custos, e observabilidade.
Roteamento: Ele direciona as requisições para o modelo ou provedor mais adequado com base em políticas (por exemplo, escolhendo entre modelos mais rápidos, mas caros, ou mais baratos).
Segurança: Ele impõe autenticação, gerenciamento de chaves e filtragem de conteúdo a partir de um único ponto de controle. Isso inclui a prevenção de problemas como injeção de prompt ou vazamento de dados sensíveis, aplicando salvaguardas centralizadas nas entradas e saídas.
Controle de Custos: Ele rastreia o uso de tokens por requisição e impõe orçamentos ou cotas para evitar estouros de custos. Por exemplo, ele pode armazenar em cache requisições duplicadas para economizar tokens e redirecionar requisições se um modelo exceder o orçamento.
Observabilidade: Ele registra cada chamada de IA e expõe métricas/rastreamentos para que as equipes possam monitorar o desempenho, as tendências de uso e detectar anomalias em todos os modelos e aplicações.
Ao integrar essas funções, um gateway de IA transforma o tráfego de IA em um plano de políticas programável – assim como o Kubernetes fez para contêineres. Isso resolve problemas-chave ao passar de experimentos de IA para a produção: sem um gateway, é fácil perder a visibilidade sobre o gasto de tokens, aplicar controles de segurança inconsistentes e ter dados de desempenho fragmentados. Um gateway garante que cada requisição de IA seja governada e mensurável. Como observa um guia de analistas, “sem essa camada, as organizações lutam para controlar custos, manter a segurança e monitorar o desempenho em escala”. Em suma, um gateway de IA torna o uso de IA pronto para empresas, adicionando os controles e a telemetria que grandes equipes exigem.
Quando uma Organização Precisa de um Gateway de IA?
Nem todo pequeno projeto de IA precisa de um gateway completo, mas assim que múltiplas equipes, modelos ou padrões de uso surgem, um gateway se torna valioso. Você provavelmente precisa de um gateway de IA quando:
Você usa múltiplos provedores ou modelos de IA. Quando suas aplicações chamam mais de uma API de LLM (por exemplo, combinando OpenAI, Azure ou modelos personalizados), um gateway permite acessá-las através de uma interface única e consistente. Isso evita que cada equipe reinvente a lógica de acesso e garante políticas de segurança uniformes.
O uso está a escalar ou é interequipes. Se dezenas de desenvolvedores em diferentes departamentos estão integrando LLMs, você corre o risco de ter uma “IA sombra” — uso descontrolado em várias contas. Um gateway de IA unifica esse tráfego, dando visibilidade sobre quem está chamando qual modelo. A Gartner prevê que o uso de gateways aumentará significativamente à medida que as aplicações multimodelos se espalharem.
Custos e orçamentos importam. Cada solicitação de IA consome tokens que custam dinheiro. Um único prompt pode usar milhares de tokens. À medida que o uso aumenta, torna-se fácil estourar o orçamento sem que ninguém perceba. Um gateway de IA rastreia o uso de tokens por solicitação e pode impor orçamentos por equipe ou por projeto, evitando custos descontrolados. Se sua equipe financeira ou de plataforma reclama de gastos imprevisíveis com IA, é hora de um gateway.
Segurança e conformidade são requisitos. Para indústrias regulamentadas (finanças, saúde, etc.), você precisa de auditoria centralizada das interações de IA, controles de acesso rigorosos e verificações de segurança de conteúdo. Um gateway de IA oferece exatamente isso: por exemplo, ele pode bloquear PII em saídas ou impor a sanitização de entradas. Se você precisa de conformidade com HIPAA/SOC2 ou deve integrar-se a sistemas SIEM, um gateway com segurança de nível empresarial é essencial.
Você tem cargas de trabalho multi-inquilino ou agenticas. Se várias unidades de negócios ou clientes usam a mesma infraestrutura de IA, você precisa de isolamento de carga de trabalho. O verdadeiro suporte multi-inquilino (espaços de trabalho separados, RBAC, chaves de API) vem com um gateway. Da mesma forma, se você implanta agentes de IA (que usam protocolos como MCP/Model Context Protocol), um gateway projetado para agentes pode gerenciar essas chamadas de ferramenta/modelo centralmente.
Key Metrics for Evaluating Gateway
Criteria
What should you evaluate ?
Priority
TrueFoundry
Latency
Adds <10ms p95 overhead for time-to-first-token?
Must Have
✅ Supported
Data Residency
Keeps logs within your region (EU/US)?
Depends on use case
✅ Supported
Latency-Based Routing
Automatically reroutes based on real-time latency/failures?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Evaluating an AI Gateway?
A practical guide used by platform & infra teams
Principais Recursos a Procurar em um Gateway de IA
Ao comparar soluções de gateway de IA, concentre-se em recursos que garantam escalabilidade, segurança, observabilidade, e custo-benefício. Capacidades importantes incluem:
API Multi-Modelo Unificada: O gateway deve apresentar um endpoint único e compatível com OpenAI para chamar modelos, mesmo que venham de diferentes fornecedores. Isso significa que ele pode traduzir suas solicitações para provedores como OpenAI, Azure OpenAI, Amazon Bedrock, Gemini, Groq, ou até mesmo modelos auto-hospedados usando uma interface padrão v1/chat/completions. Uma ampla cobertura de modelos é crucial: verifique o suporte para os modelos líderes prontos para uso e uma maneira fácil de integrar modelos novos ou personalizados. Idealmente, você deve ser capaz de alternar modelos via cabeçalhos ou alterações de configuração sem tocar no código da sua aplicação. Esta interface unificada simplifica o desenvolvimento e permite que você experimente diferentes modelos de forma contínua.
Alto Desempenho e Escalabilidade: Uma vez que o gateway atua como proxy para cada chamada de IA em produção, ele deve ser rápido e escalável. Procure por uma sobrecarga de latência mínima (otimamente, apenas alguns milissegundos adicionados por requisição). O gateway deve suportar um alto RPS (requisições por segundo) mesmo com recursos modestos; por exemplo, um gateway bem projetado pode lidar com centenas de RPS por núcleo de CPU. Autoscaling e implantação multi-região também são cruciais – o gateway deve ser capaz de iniciar pods ou instâncias adicionais sob demanda e operar em diferentes zonas/regiões para reduzir a latência para equipes globais. Arquitetonicamente, muitos gateways implementam verificações de limite de taxa e balanceamento de carga em memória (sem chamadas externas no caminho da requisição) para alcançar latências abaixo de 50ms. Confirme as alegações de benchmark do fornecedor (por exemplo, X RPS por pod) e teste sob sua carga esperada.
Roteamento, Balanceamento de Carga e Confiabilidade: O gateway deve distribuir o tráfego de forma inteligente. As principais características incluem balanceamento de carga ponderado ou baseado em latência entre réplicas/provedores de modelos, novas tentativas automáticas e fallbacks de modelos em caso de falha, e cache semanticamente consciente de prompts. Recursos robustos de balanceamento de carga de LLMs garantem que o tráfego seja distribuído de forma inteligente entre os provedores para manter o desempenho, reduzir picos de latência e melhorar a confiabilidade da produção. Você deve ser capaz de definir limites de taxa por usuário ou equipe para evitar abusos, e ter cotas ou orçamentos (baseados em tokens ou em dólares) por projeto. O suporte para políticas de roteamento avançadas (por exemplo, enviar tráfego de alta prioridade para modelos premium ou rotear com base em tempos limite de requisição) é um diferencial. No geral, garanta que o gateway possa servir como um proxy resiliente para que uma interrupção ou pico na API downstream não trave sua aplicação.
Observabilidade Robusta: Cada requisição através do gateway deve gerar logs e métricas detalhados. As características essenciais de observabilidade incluem rastreamento de requisições com metadados ricos (texto do prompt, modelo usado, tokens de entrada/saída, identidade do usuário, latência, etc.) e dashboards em tempo real ou históricos mostrando tendências de uso e desempenho. O gateway deve expor ganchos de integração para sua pilha de monitoramento – por exemplo, compatibilidade com OpenTelemetry e fácil exportação de logs/métricas para Grafana, Prometheus, Datadog, etc.. Perguntas chave: Você pode filtrar logs/métricas por usuário, equipe ou modelo? Você pode detalhar erros (4xx/5xx) ou eventos de fallback? Soluções empresariais verdadeiras permitem que você segmente dados de custo e uso da maneira que precisar (por modelo, por departamento, etc.) para que possa alocar orçamentos com precisão. A lista de verificação de avaliação sugere verificar se métricas de custo e métricas de desempenho (como tempo até o primeiro token) estão disponíveis em níveis granulares.
Segurança, Guardrails e Governança de Acesso: A segurança deve ser intrínseca. Procure por suporte integrado para filtragem de prompts e conteúdo (listas de palavras-chave, regras de regex, políticas sensíveis ao contexto) para prevenir saídas inseguras ou indesejadas. O gateway deve ser capaz de se integrar com filtros de conteúdo externos ou ferramentas TRiSM (por exemplo, AWS Content Moderation, provedores de guardrails de IA). Todas as requisições de API devem ser registradas com trilhas de auditoria completas, e você deve ser capaz de atribuir permissões granulares: por exemplo, limitar quais equipes ou usuários podem chamar quais modelos. O Controle de Acesso Baseado em Função (RBAC) é essencial – garanta que o gateway suporte a integração com seu SSO/IdP (SAML, OIDC, etc.) e que as funções e políticas possam ser sincronizadas a partir dele. Verifique a criptografia de dados em repouso/em trânsito e as certificações de conformidade (como SOC2, GDPR, HIPAA, se necessário) na solução SaaS ou on-premise do fornecedor.
Gestão de Custos: Além do rastreamento bruto de tokens, controles de custo avançados são cruciais. O gateway deve manter tabelas de preços (ou permitir preços personalizados) para os principais provedores, para que possa calcular o custo em dólares de cada requisição. Ele deve aplicar políticas de gastos – por exemplo, enviando alertas ou bloqueando requisições quando uma equipe atinge 80% de seu orçamento. Alguns gateways permitem predefinir taxas personalizadas para planos empresariais ou modelos auto-hospedados, e aplicá-las para calcular os custos. O cache semântico de respostas (por exemplo, via embeddings) também pode reduzir drasticamente o uso, tornando-o um recurso desejável para economia de custos. Em última análise, procure pela capacidade de gerar relatórios de custo por usuário ou projeto e de ver o gasto de tokens em tempo real.
Experiência do Desenvolvedor e Integrações: Um bom gateway oferece uma experiência fluida para os desenvolvedores. Ele deve ser compatível com frameworks e agentes de IA comuns – por exemplo, suportando LangChain, LlamaIndex ou ferramentas populares no-code (n8n, Flowise) via sua API. Verifique se ele oferece um playground de prompts unificado ou uma ferramenta de versionamento para gerenciar prompts centralmente. O suporte multimodal (lidando com texto, imagens, áudio e embeddings) através da mesma interface é valioso se seus casos de uso envolvem mais do que apenas chat. Finalmente, o gateway deve fornecer uma API REST clara ou SDKs para gerenciamento: por exemplo, criação de chaves de API, configuração de modelos, definição de orçamentos, etc. O gateway TrueFoundry, por exemplo, oferece um playground de prompts, gerenciamento de chaves de API e funciona de forma nativa com todos os principais frameworks de LLM.
Flexibilidade de Implantação: Dependendo da sua postura de segurança, você pode precisar do gateway como uma solução SaaS ou auto-hospedada. Verifique se o gateway pode ser executado na sua nuvem ou on-premises (a TrueFoundry suporta ambos) e qual infraestrutura ele requer (Kubernetes, etc.). Considere como a configuração é gerenciada – procure por suporte a Terraform/Helm e integração GitOps se você usa essas práticas. Verifique também as capacidades de implantação de borda ou regional para minimizar a latência para equipes globais. Por exemplo, o SaaS da TrueFoundry é distribuído globalmente e seu gateway on-prem pode ser colocado em qualquer região de nuvem, mantendo os tempos de resposta abaixo de ~5ms na prática.
Em resumo, sua avaliação deve cobrir roteamento/orquestração, desempenho, observabilidade, segurança, controle de custos, e implantação. Como um passo prático, use uma lista de verificação estruturada para pontuar cada gateway em relação a essas dimensões.
Abordagem da TrueFoundry para o Design de Gateways de IA
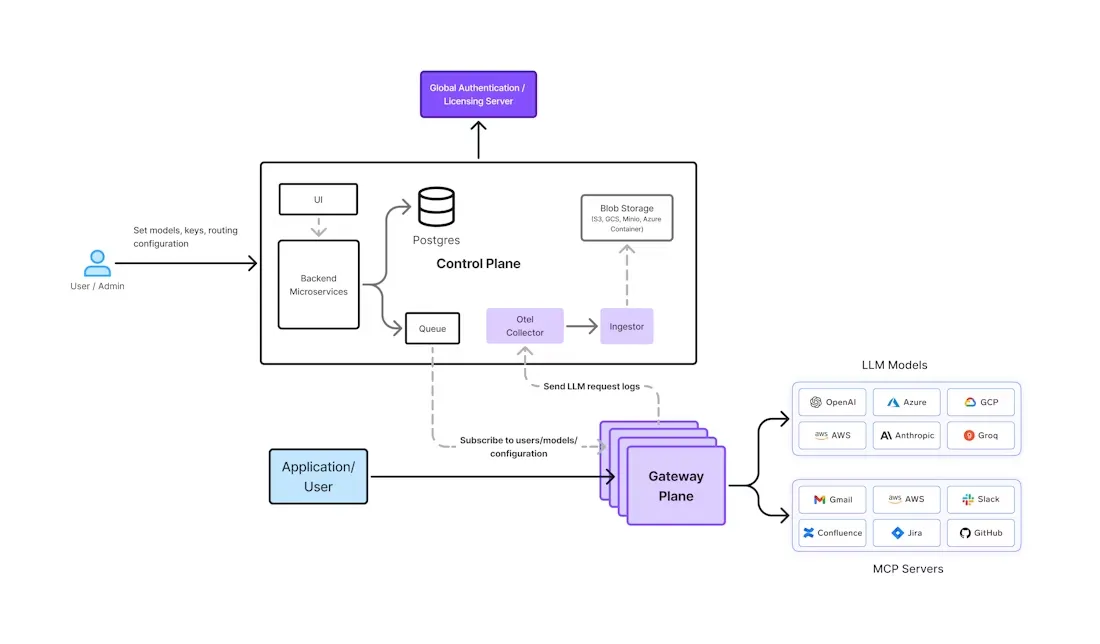
O próprio Gateway de IA da TrueFoundry foi construído do zero com esses requisitos empresariais em mente. Ele oferece uma interface unificada para mais de 1000 LLMs (OpenAI, Anthropic, Gemini, Bedrock, modelos de código aberto e mais) enquanto incorpora segurança, observabilidade e governança em sua essência. A arquitetura separa as funções do plano de controle (UI, banco de dados de políticas, etc.) dos pods de gateway sem estado que lidam com o tráfego de inferência (veja a figura abaixo).
Figura 1: Arquitetura do Gateway de IA da TrueFoundry. Um plano de controle central (esquerda) envia a configuração para pods de gateway distribuídos globalmente (direita). Todas as verificações de política (autenticação, limites de taxa, roteamento) ocorrem em memória em cada pod.
Da TrueFoundry os pods do gateway subscrevem a um fluxo de mensagens NATS do plano de controle. As alterações de política (como novas permissões de usuário, configurações de modelo ou regras de balanceamento) são publicadas no NATS e ficam imediatamente disponíveis para cada pod. Quando uma solicitação chega a um pod do gateway, todas as verificações críticas ocorrem em memória, sem saltos de rede adicionais – isso inclui autenticação JWT, verificações RBAC, aplicação de limites de taxa e decisões de balanceamento de carga de modelo. Como resultado, os testes da TrueFoundry mostram latências adicionais da ordem de apenas alguns milissegundos por solicitação. Mesmo com rastreamento completo (registrando cada prompt e contagem de tokens), hardware moderno lida com centenas de solicitações por segundo por pod, e o sistema escala linearmente adicionando mais pods.
Nos bastidores, as solicitações aprovadas são roteadas para o provedor de IA ou endpoint de modelo escolhido. Se uma resposta for bem-sucedida, ela é imediatamente enviada de volta ao cliente. Simultaneamente, metadados da solicitação e da resposta (tokens usados, latência, usuário, modelo) são publicados assincronamente na fila de mensagens. Um serviço de análise de backend ingere esses eventos no ClickHouse (via armazenamento de blobs) para calcular métricas de uso e custo. Este pipeline assíncrono significa que o registro e a análise nunca bloqueiam o caminho do tráfego em tempo real. Clientes de painel e API podem então consultar a telemetria agregada (via padrões OpenTelemetry) para rastrear o uso por modelo, equipe ou período de tempo.
A segurança é aplicada em toda a parte. O gateway da TrueFoundry usa controle granularRBAC para que as equipes vejam e invoquem apenas os modelos que lhes são permitidos usar. Todas as chaves de API e tokens podem ser gerenciados centralmente, e registros de auditoria detalhados capturam cada ação (carimbos de data/hora, IDs de usuário, modelo usado, etc.). Conteúdo personalizado guardrails podem ser definidos no portal (por exemplo, filtros de palavras-chave ou regras sensíveis ao contexto), e o gateway bloqueará ou sinalizará quaisquer respostas que violem a política. A TrueFoundry também se integra a provedores de identidade corporativos, para que você possa sincronizar funções do seu IdP (SSO via SAML/OIDC) e aplicá-las automaticamente às permissões do gateway.
Outras capacidades incluem suporte multimodal (a mesma API lida com texto, imagens, áudio e embeddings de forma transparente) e um sistema de gerenciamento de prompts integrado. O gateway oferece um Prompt Playgroundpara versionamento e teste de prompts centralizado, o que é especialmente útil para equipes que estão iterando em prompts de produção. Ele também oferece controles globais de orçamento e limite de taxa: por exemplo, você pode definir uma cota mensal em dólares por equipe ou impor orçamentos baseados em tokens por projeto. Na prática, as organizações que usam o gateway da TrueFoundry obtêm visibilidade imediata dos gastos com tokens (mesmo discriminados por provedor e modelo) e podem automaticamente interromper ou notificar os usuários quando os orçamentos são excedidos.
A flexibilidade de implantação é uma característica distintiva do design da TrueFoundry. O AI Gateway pode ser executado como um SaaS gerenciado (com nós em várias regiões de nuvem para baixa latência e alta disponibilidade) ou ser instalado em seu próprio ambiente de nuvem/on-premises. Em ambos os casos, o impacto no desempenho é mínimo – um FAQ recente observa que o SaaS da TrueFoundry adiciona menos de ~5ms de sobrecarga por solicitação. Como pode ser implantado em qualquer cluster Kubernetes (ou mesmo na borda), você pode colocar os pods do gateway perto de seus aplicativos ou fontes de dados para reduzir ainda mais o tempo de ida e volta. A TrueFoundry também suporta operação segura on-prem: os únicos dados enviados para o servidor de licenciamento na nuvem são métricas de uso anonimizadas, e a implantação completa do plano de controle pode permanecer atrás do seu firewall, se necessário.
Escolhendo o Gateway Certo para o Seu Caso de Uso
Nenhum gateway de IA único é perfeito para todos os cenários, então alinhe sua escolha com suas prioridades:
Casos de uso sensíveis ao custo: Se o controle orçamentário rigoroso é fundamental, priorize gateways com políticas de gastos integradas. Certifique-se de que ele possa aplicar preços personalizados (por exemplo, refletindo seus descontos empresariais) e acionar alertas em limites orçamentários. A TrueFoundry, por exemplo, permite pré-carregar as taxas de provedores públicos e definir taxas personalizadas para seus contratos ou modelos auto-hospedados, com notificações automáticas à medida que os limites se aproximam.
Requisitos de alta segurança/conformidade: Em setores regulamentados, procure recursos como auditabilidade completa (logs à prova de adulteração), RBAC granular e gerenciamento de chaves de criptografia. O gateway da TrueFoundry suporta fluxos de trabalho SOC2 e HIPAA prontos para uso (através de opções on-premise e armazenamento seguro de chaves) e pode se integrar com ferramentas SIEM. Recursos como detecção de PII e redação de dados podem ser decisivos se você lida com dados sensíveis.
Taxa de transferência extremamente alta/baixa latência: Para aplicações em tempo real (por exemplo, chatbots de clientes ou sistemas de negociação), o desempenho do gateway é primordial. Verifique os benchmarks do fornecedor ou execute um piloto: a arquitetura da TrueFoundry pode atender a mais de 250 RPS por pod com latência adicional mínima, e escalar facilmente para muitos milhares com mais réplicas. Se você precisa de latência ultrabaixa, implantar pods de gateway na mesma região (ou mesmo em zonas de borda) que seus usuários é importante – a opção SaaS multirregional ou on-premise da TrueFoundry permite isso.
Ambientes multi-cloud ou híbridos: Se você usa vários provedores de nuvem ou tem requisitos rigorosos de residência de dados, escolha um gateway que possa operar em todos eles. A TrueFoundry suporta implantação em qualquer nuvem ou infraestrutura on-premise, e pode sincronizar políticas globalmente. Isso significa que um único plano de controle pode gerenciar gateways implantados em diferentes regiões ou nuvens.
Aplicações multimodais ou baseadas em agentes: Se o seu caso de uso envolve agentes (ferramentas, ações) via protocolos MCP/A2A, ou se você precisa de suporte contínuo para imagens e áudio, verifique se o gateway possui essas capacidades. A TrueFoundry está estendendo ativamente seu gateway para virtualizar servidores MCP e unificar ferramentas de IA sob uma única API. Já hoje, ele oferece “servidores MCP virtuais” onde você pode combinar ferramentas e modelos de múltiplos agentes em uma única interface (em breve em GA). Para multimodal, a TrueFoundry suporta modelos de texto, imagem, áudio e embedding de forma uniforme.
Adequação para desenvolvedores e ecossistema: Considere o que suas equipes de desenvolvimento usam. Se eles dependem de LangChain ou frameworks LLM, escolha um gateway conhecido por funcionar com eles de forma nativa. A facilidade de integração (documentação da API, SDKs de cliente) é importante para a adoção. A TrueFoundry oferece APIs abertas e bibliotecas de cliente em várias linguagens, e sua API unificada significa que o código existente baseado em OpenAI geralmente funciona sem alterações. Verifique também se o gateway se integra com ferramentas de CI/CD ou de infraestrutura que você usa (por exemplo, suporte a Terraform na TrueFoundry).
Em todos os casos, mapeie esses requisitos em relação à sua lista de verificação de avaliação. Atribua pesos aos critérios com base no que é mais crítico para o seu projeto (segurança vs. custo vs. recursos). A estrutura de avaliação da TrueFoundry pode ser personalizada (está disponível como um CSV público) para que você possa pontuar fornecedores lado a lado com base nos recursos exatos de que precisa. O objetivo é escolher o gateway que não apenas atenda às necessidades atuais, mas que possa crescer com suas iniciativas de IA.
Conclusão
À medida que a adoção da IA cresce, um gateway construído para esse fim está rapidamente se tornando uma camada de controle indispensável. Ele traz ordem ao que de outra forma seria uma mistura caótica de APIs, custos e riscos de segurança. Ao lidar com roteamento, observabilidade, orçamento e conformidade em um só lugar, um gateway de IA transforma a infraestrutura de IA em uma plataforma confiável e governada. Gateway de IA da TrueFoundry é construído sobre esses princípios – oferecendo uma interface unificada para centenas de modelos com segurança de nível empresarial, monitoramento e controles de política.
Ao escolher um gateway, use uma abordagem estruturada: entenda suas cargas de trabalho, consulte a lista de verificação de avaliação e compare como cada opção se posiciona em flexibilidade de roteamento, desempenho, observabilidade, controles de custo e recursos de governança. Ao fazer isso, você pode selecionar a solução que servirá como o “plano de controle de IA” para as aplicações LLM e baseadas em agentes da sua organização. Um gateway robusto não apenas protege orçamentos e dados, mas também acelera o desenvolvimento, fornecendo uma base consistente e escalável para todos os serviços de IA. Em última análise, investir no gateway de IA certo abre caminho para levar com segurança seus casos de uso de IA do experimento à realidade em escala empresarial.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.































.webp)



.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




