




August 1, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: June 17, 2026

Blazingly fast way to build, track and deploy your models!
In June 2026, Yahoo Finance reported that Meta had told roughly 6,000 employees, in an internal memo, that it would tighten oversight of their AI token usage and introduce spending controls — weeks after pushing those same employees to use AI more. According to that coverage, Meta's internal AI use alone is on track to cost the company billions of dollars in 2026. Within weeks, Amazon was reported to have shut down its own internal AI-usage leaderboard, and Uber was reported to have burned through its entire planned 2026 AI coding budget in the first four months of the year. The press coined a name for the reversal: tokenminimizing.
This is the appendix the tokenmaxxing trilogy was always going to need. The trilogy argued — before the reaction began — that celebrating token consumption measures the wrong thing, and that an organization without a governance layer ends up with only two settings: wide open, or clamped shut. The tokenminimizing reaction is the second setting. The point of this post is not that the prediction was correct; it's that both settings are the same mistake, recent reporting across three large technology companies illustrates it within a single quarter, and there's a third option that makes the whipsaw unnecessary.
The facts here are drawn entirely from published reporting, and we attribute each claim to its source rather than asserting any of it independently. We name these companies only because their internal moves became public through that reporting; we make no independent claim about any company's internal operations beyond what these outlets published.
Meta. As Yahoo Finance reported (republishing StockTwits coverage of a memo reviewed by The Information), Meta told roughly 6,000 staff it would introduce spending controls, budgets, and usage limits, citing internal AI costs on track to run into the billions of dollars in 2026. Per that coverage, employees and teams had limited visibility into their own consumption, and the company expects to move by 2027 toward a structured framework of budgets and allocation decisions. To get there, the reporting says, Meta built a centralized dashboard it calls an "AI Gateway" to track usage and spending in one place, with automated alerts for unusual spikes. That detail is worth pausing on: a company of Meta's scale, having run the maxxing experiment, is reported to be hand-building exactly the category of system — real-time attribution, spend tracking, spike alerts, structured budgets — that this series has argued belongs in the request path from the start.
Amazon. Weeks earlier, as TheStreet and other outlets reported (citing the Financial Times, which broke the story), Amazon shut down an internal leaderboard called "KiroRank" that scored employees on AI activity on its Kiro developer platform. According to that reporting, staff had inflated their scores by running low-value tasks through AI agents to climb the rankings — the behavior the industry now calls tokenmaxxing — which drove up compute costs. The reporting notes Amazon replaced the leaderboard with a metric it calls "normalized deployments," meaning AI-assisted code that actually ships. A senior executive reportedly told staff not to use AI just for the sake of using AI. That replacement is the input-to-output correction made concrete by Amazon itself: stop counting tokens consumed, start counting work shipped.
Uber. And as noted in the same Yahoo Finance report and covered earlier by Business Insider, Uber was reported to have exhausted its entire planned 2026 AI coding budget in the first four months of the year; the same coverage notes Uber's COO said the company had not found a clear link between higher AI spending and shipped results. Three companies, three different mechanisms, one quarter, the same shape.
The labels "tokenmaxxing" and "tokenminimizing" make this sound like two trends. It is more useful to read it as one pattern with two phases, now visible at three separate companies: adoption is encouraged with no governance layer underneath it, usage becomes the visible metric, costs surprise leadership, and the only lever available is a blunt one.
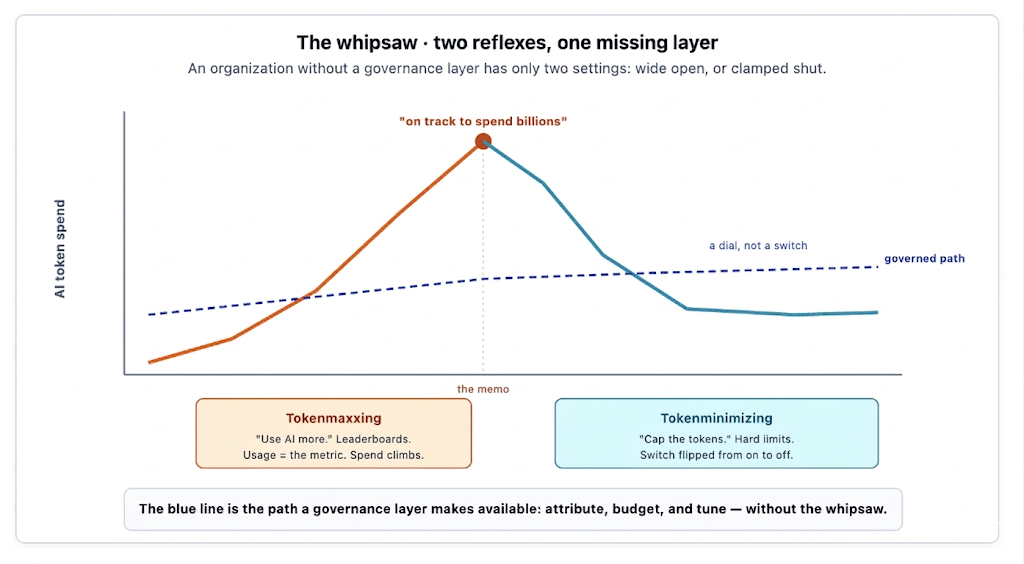
The tokenmaxxing trilogy (all links are in Reference) was not a celebration of token consumption. It was a critique of it. The central argument, made across all three parts, is the distinction between an input and an output: tokens are something you spend, and the work the tokens produce is the thing that actually matters. A leaderboard that ranks employees by tokens consumed is measuring the input and rewarding its maximization — and the moment a measure becomes a target, by Goodhart's Law, it stops being a good measure. The trilogy said this plainly while the maxxing phase was still in full swing, when the prevailing mood treated rising token graphs as unambiguous evidence of productivity.
That is the part worth being precise about, because it is easy to misread this post as a victory lap. It isn't one. The trilogy didn't predict that any specific company would send a memo in June 2026. It made a structural argument — that measuring the input would eventually force a painful correction — and the structural argument is what the reporting now illustrates, at more than one company. The remark attributed to Meta CTO Andrew Bosworth in MLQ's coverage — token usage alone is not a measure of impact — reads as the trilogy's thesis in a CTO's words, reportedly arrived at independently under the pressure of a billions-of-dollars forecast. And the Amazon case has been described in industry coverage as a textbook instance of Goodhart's Law: the moment token consumption became a leaderboard target, the reporting argues, it stopped measuring productivity and started measuring competitive anxiety. That is the trilogy's argument almost verbatim, reached independently by observers watching the same failure unfold.
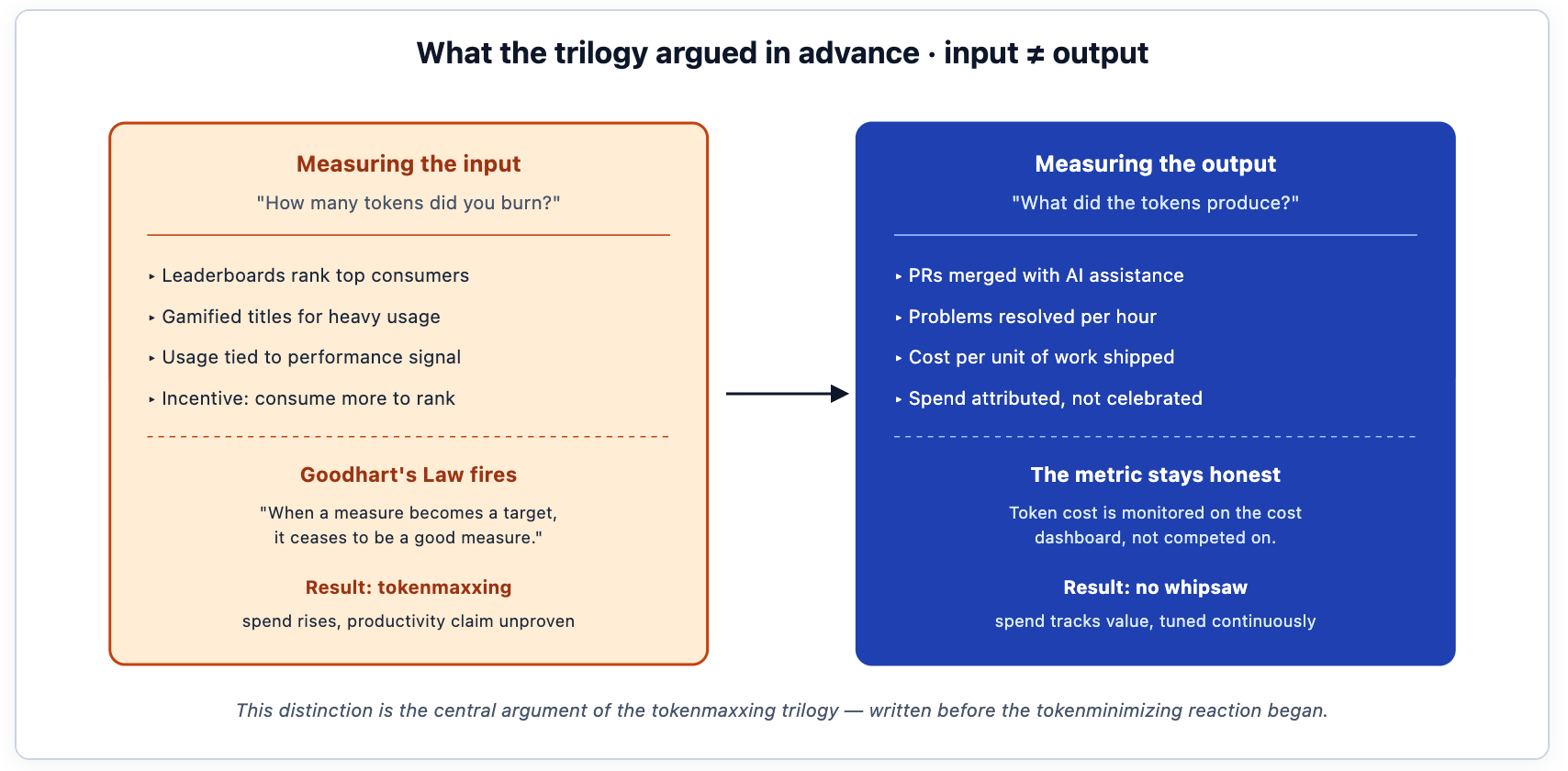
The trilogy's recommendation followed from the distinction: measure the output (work shipped, problems resolved, cost per unit of value), and keep token cost on the platform team's cost dashboard rather than on a leaderboard employees compete to top. An organization that does this never builds the incentive that produces the maxxing spike, and therefore never faces the bill that forces the minimizing clamp. The whipsaw is avoidable, but only by declining to take the first swing.
It is tempting to read the tokenminimizing reaction as the responsible correction — the adults arriving to shut down the party. That reading is wrong, or at least incomplete. A blanket token cap is not governance; it is the absence of governance wearing a responsible-looking costume. It throttles the security-review pipeline that was catching real vulnerabilities at the same rate it throttles the engineer who was gaming the leaderboard, because a blunt cap cannot tell the two apart. The organization trades one undifferentiated policy ("use AI freely") for another ("use AI less"), and neither policy can distinguish valuable spend from wasteful spend, which was the entire problem in the first place.
This is the reasonable core of the companies that burned money on tokens and are now reversing: the spend was real, the productivity questions were legitimate, and pulling back is a defensible response to a billions-of-dollars forecast with no attribution behind it. We are not critical of the decision to control cost. We are critical of the fact that, lacking a governance layer, the only available instrument is a sledgehammer. A company that swings to minimizing is making the best move available to it — given that it skipped the move that would have made a better one possible.
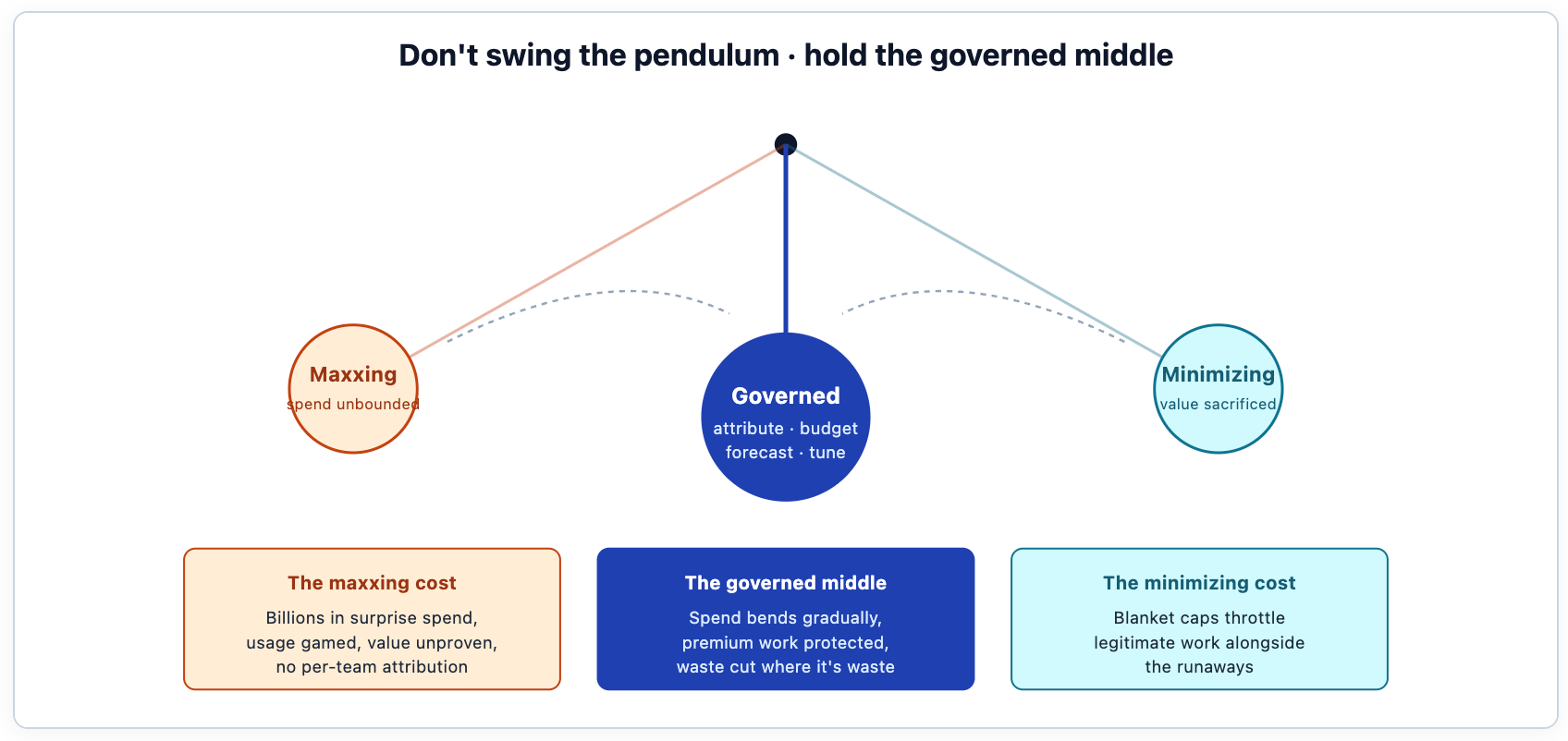
The governed middle is not a moderate compromise between maxxing and minimizing. It is a different axis entirely. The maxxing-minimizing axis runs from "spend everything" to "spend nothing." The governed axis runs from "spend blindly" to "spend with attribution, budgets, and a forecast." A team operating on the governed axis can spend aggressively on the workloads that produce value and starve the ones that don't — at the same time, because it can tell them apart.
Concretely, the layer the trilogy advocated, and that TrueFoundry's AI Gateway ships, has three parts. First, attribution: every request carries identity — team, repo, pipeline, cost center — so "who is spending" is a query, not an investigation. Second, hierarchical budgets with graduated responses: a soft alert at 75% of a cost center's cap, a constrained mode at 90% that transparently routes premium-model traffic to cheaper fallbacks so pipelines keep working, and a hard cap at 100% that fails cleanly with a descriptive error. Third, a rolling forecast that projects month-end spend with enough lead time to act before the cap fires. These are documented in TrueFoundry's Budget Limiting and Rate Limiting schemas, and they compose into a single property: the spend curve bends gradually under control instead of spiking and then collapsing.
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada






.webp)




.webp)


.webp)


