




July 22, 2026
|
5 min read


Obtenha acesso instantâneo a um ambiente TrueFoundry ao vivo. Implante modelos, direcione o tráfego de LLM e explore a plataforma completa — seu sandbox estará pronto em segundos, sem necessidade de cartão de crédito.









Published: June 24, 2026

Blazingly fast way to build, track and deploy your models!
When LLMs move from a pilot to production across many teams, governance stops being optional. Someone will ask who can call which model, with what budget, on whose data — and whether every call can be reconstructed for an audit. This post is the control plane that answers those questions: virtual keys that decouple access from provider credentials, RBAC and policy-as-code, budgets and quotas as governance, compliance-grade audit logs, data residency, and how these gateway controls map to obligations like the EU AI Act — framed as what they help satisfy, not as a compliance guarantee.
Quarter-end at Northwind. Mei, the platform lead, got a question from the security and compliance team she couldn't answer: which teams had sent customer data to which model providers over the last quarter, and could she produce the records. She couldn't. Every service called the model providers through one shared API key, checked into a config years ago. There was no per-team attribution, no record of which requests carried customer data, no way to revoke one team's access without rotating the key for everyone, and no audit trail beyond the providers' own opaque billing. The LLM usage had grown from one prototype to a dozen production services, and the governance had not grown with it.
Nothing had gone wrong, exactly — no breach, no overspend anyone had caught. But "we can't answer the question" is its own finding, and it's the one that turns a routine audit into a project. This post is the control plane that makes the question answerable before someone asks it.
Everything in this post — virtual keys, RBAC, budgets, rate limits, audit logs, residency rules, and guardrails as enforced policy — is something TrueFoundry's AI Gateway expresses as configuration in one control plane. Access control defines who (users, teams, virtual accounts) may call which provider accounts and models; Personal Access Tokens and Virtual Account Tokens are how applications authenticate to the gateway instead of holding raw provider keys; rate-limit and budget configs apply per user, team, virtual account, model, or any custom metadata key; and guardrails — including Cedar and OPA as policy-as-code at the MCP-tool boundary — run as enforced rules at four lifecycle hooks.
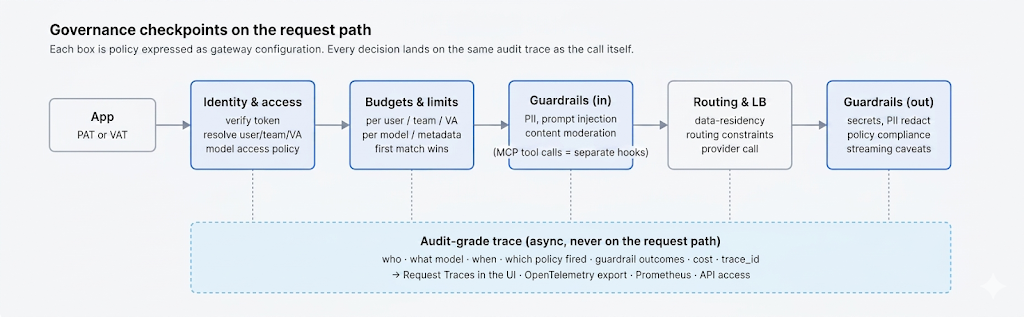
Every request crosses the same path: authenticate, resolve the calling identity, evaluate access policy and per-key budgets, evaluate rate-limit rules in order (first match wins), run input guardrails, route to a provider, emit an audit-grade trace, then run output guardrails. The same view becomes the record an auditor needs: who called what, when, against which policy, with which guardrail outcomes. Request Traces and OpenTelemetry export let the trail land in your SIEM rather than a vendor dashboard you cannot query.
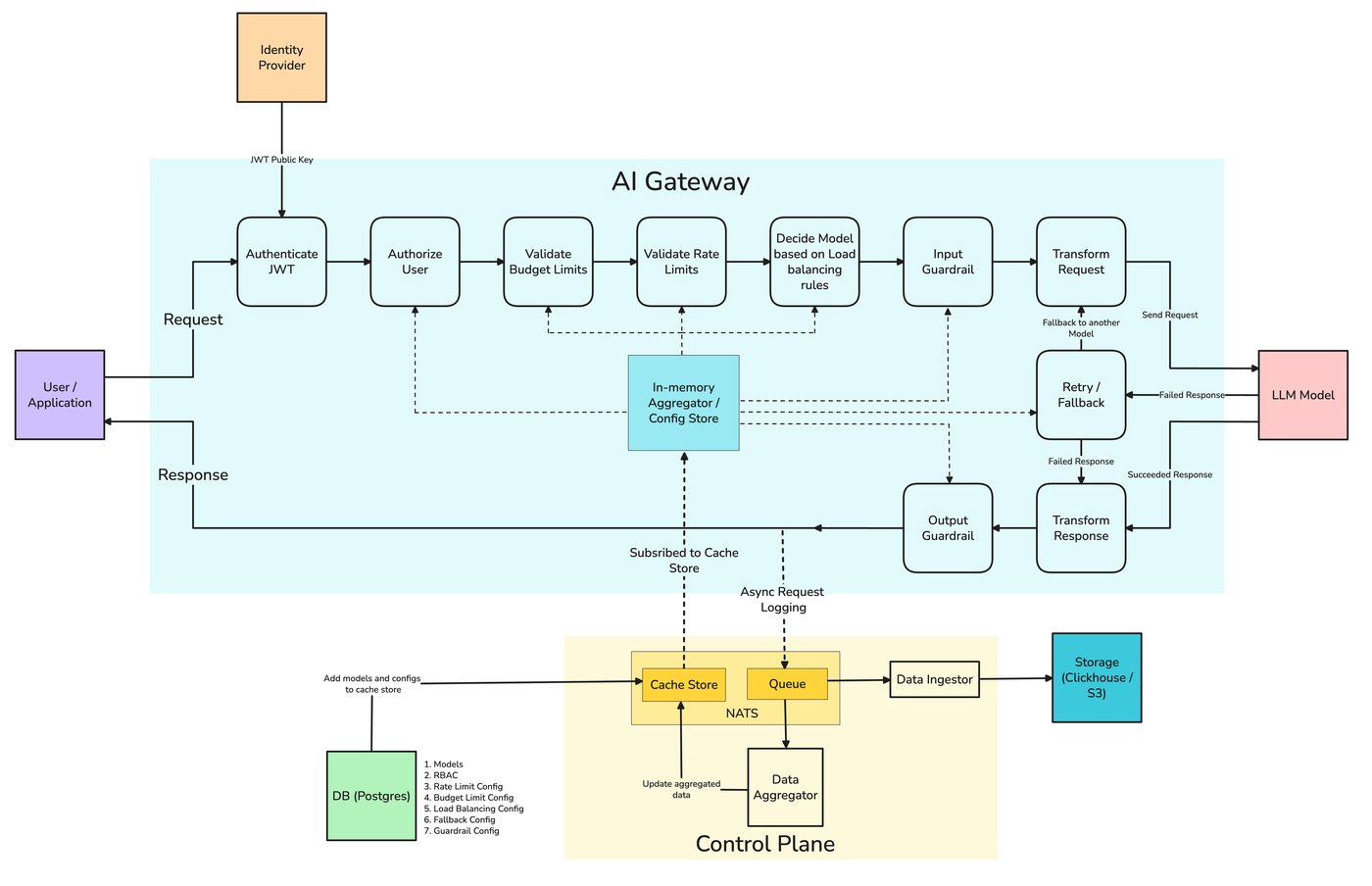
The application code is unchanged from any OpenAI-style call — the governance is in the bearer token and the metadata header, not in client logic. A Personal Access Token resolves to a user; a Virtual Account Token resolves to a non-human identity for production services. The X-TFY-METADATA header carries the structured fields (team, project, cost_center, environment) that policies, budgets, and audit logs match against:
Calling the gateway with an identity and audit metadata (Python, OpenAI-compatible)
from openai import OpenAI
client = OpenAI(
base_url="https://<your-truefoundry-gateway-url>", # your gateway endpoint
api_key="<your-virtual-account-token>", # VAT for production; PAT in dev
)
resp = client.chat.completions.create(
model="openai-main/gpt-5.5",
messages=[{"role": "user", "content": "Summarize this document."}],
extra_headers={
# Structured identity for audit, attribution, and policy matching.
"X-TFY-METADATA": '{"team":"support-ai","project":"helpdesk","cost_center":"cc-203","environment":"production"}',
},
)
print(resp.choices[0].message.content)A single prototype calling one model on one key needs no governance. A dozen services across several teams, calling several providers, on data of varying sensitivity, needs a control plane — because the failure modes are no longer hypothetical. A shared key means no usage attribution, so you can't tell finance which team is driving spend or tell security which team touched customer data. No spend limits means one runaway agent (recall the routing post's silent escalation) can burn the budget before anyone notices. No audit trail means you can't reconstruct what happened for an incident or an auditor. And no access control means shadow AI: teams wiring up models without anyone tracking it.
On top of the operational pressure sits regulatory pressure. The EU AI Act is phasing in obligations around record-keeping, transparency, and human oversight (section 7), and sector regimes — SOC 2, HIPAA, financial rules — have long expected access control and audit. The common thread is that they all assume you can answer Mei's question. Governance is the work of being able to.

The root cause of Mei's problem is the shared provider key. A virtual key fixes it: instead of handing teams the real provider credential, you issue each team or app its own gateway-managed key that maps to the underlying provider key at the gateway. The application authenticates with its virtual key; the gateway holds the real one.
That one indirection buys most of governance. Usage attributes to the virtual key, so spend and data access can be reported per team (the cost-attribution post builds on exactly this). Revocation is local — disable one team's virtual key without rotating the provider key for everyone else. And access is scopable — a virtual key can be limited to certain models, routes, or data classes. The provider credentials live in one place, the gateway, rather than scattered across a dozen service configs where they can't be tracked or rotated cleanly. In TrueFoundry's AI Gateway, virtual keys are the unit that ties usage, budgets, and access policy to a team or application rather than to an opaque shared credential.
Virtual keys establish identity; RBAC and policy decide what that identity may do. The questions are concrete: which teams may use the expensive frontier model, which may reach a given provider, which may call which tools (in an MCP setting), and which data classes may be sent where. Encoding these as policy-as-code — with an engine like Cedar or OPA — makes the rules explicit, reviewable, and versioned, rather than living as tribal knowledge or scattered conditionals.
Illustrative access policy (conceptual — exact schema is gateway-specific)# Only the research team may call the frontier model.allow if principal.team == "research" and resource.model == "gpt-5.5"# Customer-data requests must stay on an EU-resident model.deny if request.data_class == "customer_pii" and resource.region != "eu"# Finance team may not call external providers at all — self-hosted only.allow if principal.team == "finance" and resource.kind == "self_hosted"
The value of policy-as-code is that it turns "who can call what" into something you can review in a pull request, test, and prove to an auditor — the same governance discipline applied to MCP tool access in TrueFoundry's MCP security work, where Cedar and OPA gate which tools an agent may invoke. The gateway is the enforcement point because it's the one place every request crosses before reaching a provider or a tool.
Budgets and rate limits are usually framed as protection against abuse or runaway cost. In a governance context they're also fairness and accountability controls: each team gets a defined share, overruns are visible, and no single team can quietly consume the org's entire model budget. The mechanics are hard and soft limits per team or virtual key, alerting as a limit approaches, and enforcement — typically a 429 — when it's exceeded, the same enforcement path described in the cost-attribution post.
The governance framing changes how you set them. A soft limit with alerting is an accountability tool — it tells a budget owner their team is trending over, without breaking production. A hard limit is a guardrail against the runaway case, like the silently-escalating cascade from the routing post. Rate limits per key also double as a fairness mechanism in a shared-capacity setting, keeping one team's batch job from starving another team's interactive traffic. Setting these at TrueFoundry's AI Gateway means they apply per virtual key, consistently, rather than being reimplemented per service.
The schema is intentionally rule-based so a policy reads the way you'd describe it to an auditor: who (subjects: users, teams, virtual accounts, or any custom metadata key), what (models), how much (limit and unit — requests or tokens per minute, hour, or day), and scoped how (one shared limit, or a separate limit per user / per model / per metadata value via rate_limit_applies_per). Rules evaluate in order and the first match wins, so specific rules sit above broader fallbacks:
gateway-rate-limiting-config (real schema from TrueFoundry docs)
name: ratelimiting-config
type: gateway-rate-limiting-config
rules:
# 1. Specific override: bob's runaway script gets a hard 1k requests/day on gpt4
- id: "bob-gpt4-day-cap"
when:
subjects: ["user:bob@example.com"]
models: ["openai-main/gpt4"]
limit_to: 1000
unit: requests_per_day
# 2. Team-level token cap on a costly model
- id: "backend-team-gpt4-tpm"
when:
subjects: ["team:backend"]
models: ["openai-main/gpt4"]
limit_to: 20000
unit: tokens_per_minute
# 3. Fairness floor: every user gets their own 1M-token/day budget on any model
- id: "user-daily-token-cap"
when: {}
limit_to: 1000000
unit: tokens_per_day
rate_limit_applies_per: ["user"]
# 4. Project-level cap based on metadata in the request header
- id: "project-hourly-cap"
when: {}
limit_to: 50000
unit: tokens_per_hour
rate_limit_applies_per: ["metadata.project_id"]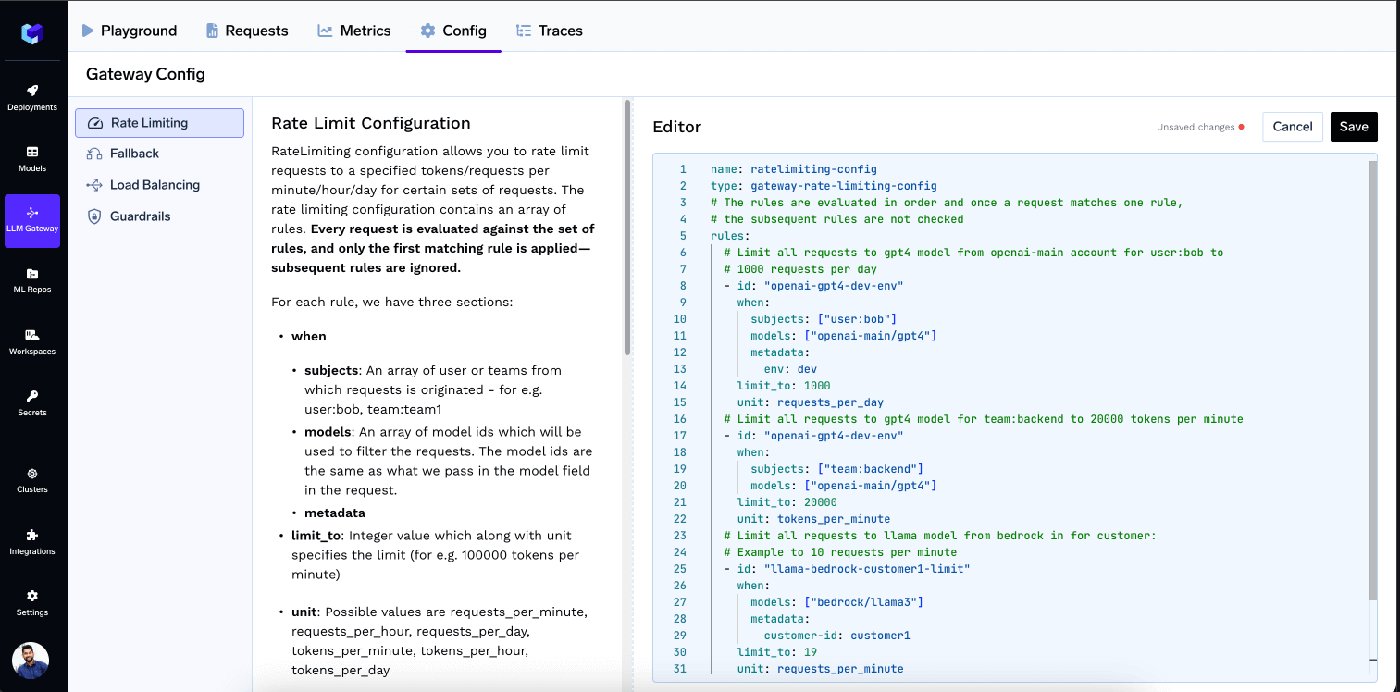
TrueFoundry AI Gateway delivers ~3–4 ms latency, handles 350+ RPS on 1 vCPU, scales horizontally with ease, and is production-ready, while LiteLLM suffers from high latency, struggles beyond moderate RPS, lacks built-in scaling, and is best for light or prototype workloads.








As últimas notícias, artigos e recursos enviados para sua caixa de entrada







.png)

.webp)
.webp)
.webp)




