

May 8, 2024
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
À une époque où les LLM alimentent les applications critiques, la visibilité de leur fonctionnement interne n'est pas négociable. L'observabilité LLM est la pratique qui consiste à capturer et à analyser des données de niveau d'inférence, notamment l'utilisation des jetons, les performances rapides, les taux d'erreur, la latence et les mesures de coût, et à les corréler avec les interactions des utilisateurs. Cela va au-delà de la surveillance traditionnelle des modèles, qui permet de suivre en grande partie les indicateurs de l'infrastructure tels que l'utilisation du processeur et les temps de réponse. La passerelle IA de TrueFoundry intègre une couche d'observabilité complète avec un versionnage rapide, une journalisation structurée, des tableaux de bord analytiques en temps réel et des alertes d'anomalies pour faire ressortir des informations exploitables, optimiser les performances et contrôler les coûts à chaque étape de votre pipeline LLM.
L'observabilité LLM est la pratique de bout en bout qui consiste à instrumenter, collecter et analyser chaque événement d'inférence dans un pipeline de modèles linguistiques. Il combine deux couches principales :
Analyses interactives
Un tableau de bord centralisé affiche des mesures en temps réel sur l'utilisation des jetons, le volume des demandes et les coûts. Vous pouvez consulter les jetons d'entrée et de sortie cumulés, le total des demandes et les coûts des jetons ainsi que les percentiles de latence (P50, P90, P99) pour chaque modèle. Les graphiques indiquent les demandes par seconde, les taux d'erreur, la consommation au niveau de l'utilisateur et la ventilation des coûts spécifiques au modèle. Les filtres vous permettent d'isoler les appels concernés par la limitation du débit, les solutions de secours ou l'équilibrage de charge et d'inspecter les règles appliquées.
Contexte piloté par les métadonnées
Chaque demande peut contenir des balises personnalisées telles que l'environnement (dev, staging, prod), le nom de la fonctionnalité, l'ID utilisateur, l'équipe ou tout autre contexte commercial via un en-tête X-TFY-METADATA. Les métadonnées permettent de :
Exportation du journal
Pour une analyse ou un archivage approfondis, TrueFoundry prend en charge les exportations JSON structurées des journaux et des traces sur demande, ce qui permet d'étudier hors ligne les performances, les coûts et les modèles d'utilisation
Ensemble, ces fonctionnalités offrent aux équipes une visibilité complète sur le comportement des modèles, les facteurs de coûts et les problèmes potentiels, garantissant ainsi des déploiements LLM fiables et optimisés.
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
L'observabilité des modèles traditionnels se concentre principalement sur la santé de l'infrastructure et les mesures de base des demandes. Vous surveillez les indicateurs au niveau du système, tels que l'utilisation du processeur et du GPU, la consommation de mémoire, les E/S disque, le débit réseau, la latence globale des demandes et les taux d'erreur. Ces mesures indiquent si votre plate-forme de service de modèles est opérationnelle et où des goulots d'étranglement peuvent survenir en termes de calcul ou de réseau. Les alertes se déclenchent en cas de dépassement de seuil, comme une charge CPU élevée ou des taux d'erreur 5xx élevés, ce qui permet aux équipes opérationnelles de provisionner des ressources ou d'enquêter sur les pannes de service.
L'observabilité du LLM, en revanche, approfondit la sémantique et l'économie de chaque inférence. Les grands modèles de langage gèrent des entrées de longueur variable et génèrent du contenu jeton par jeton. Comprendre leur comportement nécessite donc une instrumentation sensible au contenu :
Métriques des jetons par rapport au débit fixe
Les modèles traditionnels comptabilisent les demandes par seconde ; les LLM suivent les jetons d'entrée et de sortie. L'observabilité capture les volumes cumulés de jetons, les coûts des jetons et l'utilisation des jetons par modèle. Cela vous permet d'attribuer les dépenses à des utilisateurs ou à des fonctionnalités spécifiques et de détecter les demandes excessives avant que les coûts n'augmentent.
Enregistrement des réponses rapides par rapport aux prévisions en boîte noire
Les journaux d'observabilité ML standard ne demandent que les métadonnées des requêtes, telles que l'accès au point final et le code d'état. L'observabilité LLM enregistre des paires complètes de réponses rapides ainsi que des métadonnées contextuelles telles que l'environnement, les fonctionnalités et l'ID utilisateur. Cela permet de retracer les hallucinations ou les régressions de qualité jusqu'à des modèles d'invite ou des cohortes d'utilisateurs particuliers.
Percentiles de latence par rapport aux moyennes
Les configurations traditionnelles font souvent état d'une latence moyenne. Les tableaux de bord LLM indiquent les percentiles de latence P50, P90 et P99 par modèle, car la génération jeton par jeton peut entraîner des retards longs que les métriques moyennes masquent.
Effets liés à la configuration
Avec les LLM, les contrôles tels que la limitation du débit, l'équilibrage de charge et les règles de repli affectent le comportement. L'observabilité signale les demandes affectées par ces règles, par exemple les appels dont le débit a été limité, redirigés ou renvoyés vers un autre fournisseur, ce qui permet aux équipes d'affiner les politiques.
Analyses en temps réel par rapport aux journaux post-mortem
Alors que l'observabilité traditionnelle repose sur l'analyse périodique des journaux, les plateformes d'observabilité LLM telles que AI Gateway de TrueFoundry fournissent des tableaux de bord interactifs pour le filtrage en temps réel et l'exploration des tendances, vous permettant de découper les métriques par balises de métadonnées à la volée.
En résumé, l'observabilité traditionnelle répond à la question « L'infrastructure de serveur est-elle saine ? » LLM Observability explique : « Comment, quand et pourquoi chaque jeton est-il généré, et qu'est-ce que cela signifie en termes de coût, de performances et de qualité de sortie ? »
La mise en œuvre d'une observabilité robuste pour les LLM est essentielle pour maintenir les performances, contrôler les coûts et garantir des résultats de haute qualité. Ces piliers fondamentaux fonctionnent ensemble pour donner aux équipes une visibilité complète sur chaque événement d'inférence. En les comprenant et en les appliquant, vous pouvez surveiller, diagnostiquer et optimiser efficacement vos déploiements LLM.
1. Analyses interactives
Un tableau de bord unifié fournit des informations en temps réel sur tous les aspects de votre charge de travail LLM. Vous pouvez suivre les volumes de jetons d'entrée et de sortie cumulés et par modèle, le nombre total de demandes et les coûts basés sur les jetons. Les percentiles de latence détaillés, P50, P90 et P99, révèlent les caractéristiques de performance. Les graphiques des demandes par seconde et des taux d'erreur vous aident à repérer les anomalies. Les filtres vous permettent d'explorer les appels concernés par les limites de débit, les règles d'équilibrage de charge ou les solutions de secours pour un dépannage ciblé.
2. Contexte piloté par les métadonnées
En joignant des métadonnées personnalisées à chaque demande, telles que l'environnement (développement, préparation, production), le nom de la fonctionnalité, l'identifiant utilisateur ou l'équipe, vous pouvez découper vos statistiques en tranches. Les métadonnées permettent une surveillance granulaire de l'utilisation entre les cohortes, pilotent des contrôles conditionnels pour la limitation du débit et la sélection des modèles, et permettent un filtrage précis des journaux pour les audits et la conformité. Vous transmettez des métadonnées via un seul en-tête X-TFY-METADATA dans les SDK OpenAI ou LangChain, les requêtes REST ou les appels cURL.
3. Journalisation complète
Chaque inférence est enregistrée dans un format structuré qui inclut des paires complètes de réponses rapides, le nombre de jetons, les détails de latence, les codes d'erreur et les métadonnées associées. Ce niveau de détail vous permet d'effectuer une analyse des causes profondes des hallucinations, des régressions de qualité ou des anomalies de performance. Vous pouvez comparer les versions rapides, surveiller l'impact des modifications apportées aux modèles sur la qualité de sortie et retracer les problèmes liés à des cohortes d'utilisateurs ou à des fonctionnalités spécifiques.
4. Exportation et audit des journaux
Pour une analyse ou un archivage hors ligne plus approfondis, TrueFoundry prend en charge les exportations JSON structurées des journaux et des traces. Les administrateurs demandent simplement des exportations via le support dans un délai spécifié. Les données exportées permettent des analyses personnalisées, des rapports de conformité ou un stockage à long terme.
Ensemble, ces piliers offrent une transparence totale sur les inducteurs de coûts, les profils de performance et la qualité de sortie, garantissant ainsi la fiabilité, l'efficacité et la rentabilité de vos déploiements LLM.
Voici les 4 meilleurs outils d'observabilité LLM, avec un bref aperçu de chacun :
La passerelle IA de TrueFoundry fournit une solution d'observabilité et de gouvernance unifiée de niveau entreprise pour les LLM dotée des fonctionnalités suivantes :
Mesures en temps réel
.webp)
Tableaux de bord interactifs affichant le nombre de jetons d'entrée/sortie cumulés et par modèle, le volume total des demandes, la ventilation des coûts par modèle et par utilisateur, et les percentiles de latence détaillés (P50, P90, P99). Cartes thermiques des demandes par seconde, tendances des taux d'erreur et alertes d'anomalies configurables pour détecter les pics de pannes ou de latence
Informations basées sur les métadonnées
{
« tfy_log_request » : « true », //Faut-il ajouter un log/trace pour cette requête ou maintenant
« environment » : « staging »,//L'environnement - dev, staging ou prod ?
« feature » : « countdown-bot » //Quelle fonctionnalité a initié la demande ?
}
Étiquetez les demandes en fonction du contexte commercial (environnement, fonctionnalité, utilisateur, équipe) via un seul en-tête X-TFY-METADATA. Découpez les tableaux de bord et les journaux par métadonnées pour comparer les environnements, isoler l'utilisation des fonctionnalités et auditer l'activité des utilisateurs ou des équipes.
Contrôles de politique sous forme de code
Définissez des règles de limitation de débit pilotées par YAML (par exemple, « 1 000 appels GPT-4 par jour pour les développeurs »), des pondérations d'équilibrage de charge entre les fournisseurs et des chaînes de secours en cas d'erreur
Définitions de politiques contrôlées par version gérées via les flux de travail GitOps, permettant la révision des demandes d'extraction, la validation du CI et les annulations
Enregistrement et suivi complets

Stockez des journaux JSON structurés contenant les paires complètes de réponses rapides, les ventilations au niveau des jetons, la latence, les codes d'erreur et les identifiants de politique appliqués. Corrélez les traces distribuées pour déboguer des flux de travail en plusieurs étapes ou des pipelines RAG
Exportation et conformité :
Exportation à la demande de journaux et de traces au format JSON pour une analyse hors ligne, un archivage à long terme ou des audits réglementaires. Le RBAC et les pistes d'audit intégrés garantissent que seuls les utilisateurs autorisés peuvent consulter ou exporter des données sensibles
Ces fonctionnalités font de TrueFoundry un choix exceptionnel pour les équipes qui ont besoin d'une visibilité de bout en bout, d'un contrôle précis des coûts, d'une gouvernance basée sur la politique en tant que code et d'une auditabilité robuste dans leurs déploiements LLM.
LangSmith est spécialisé dans le traçage approfondi et le débogage pour les applications basées sur Langchain. Il capture automatiquement chaque étape de vos chaînes, en enregistrant les entrées rapides, les sorties intermédiaires et les réponses finales. Les développeurs disposent d'un visualiseur de traces interactif pour comparer les modèles d'invite au fil du temps, identifier les régressions de performances et analyser les appels de fonctions. LangSmith enregistre également des mesures d'exécution telles que l'utilisation des jetons et la latence par étape de la chaîne, et vous permet de joindre des métadonnées personnalisées pour le suivi des fonctionnalités. Grâce à la gestion des expériences intégrée, vous pouvez baliser les essais, comparer la qualité de sortie entre les versions des modèles et revenir à des configurations éprouvées. L'accent mis sur l'ergonomie pour les développeurs et la transparence de la chaîne en fait un outil idéal pour une itération et un débogage rapides.
Helicone propose une plateforme d'observabilité centrée sur les API et adaptée à l'IA générative. Il enregistre chaque appel d'API à OpenAI, Anthropic ou à d'autres points de terminaison, en capturant les textes d'invite complets, les réponses, l'utilisation des jetons et les détails de synchronisation. Le tableau de bord d'Helicone met en évidence le coût par appel, les modèles d'invite les plus utilisés et la répartition des erreurs, ce qui vous permet d'identifier les modèles coûteux ou sujets aux pannes. Les visualisations intégrées de l'organisation du trafic révèlent l'impact des limites de débit et des quotas sur le débit, et vous pouvez configurer des alertes en cas de hausse des coûts ou de taux d'erreur élevés. Grâce à ses intégrations légères au SDK, Helicone fournit des informations rapides sur les dépenses et les performances, ce qui en fait un excellent choix pour les équipes qui se concentrent sur le contrôle des coûts des API et l'optimisation rapide.
Lunary met l'accent sur la simplicité et l'expérience des développeurs pour assurer l'observabilité du LLM. Il instrumente automatiquement les appels du SDK OpenAI et Anthropic, en enregistrant les trajets rapides, les métriques des jetons et les temps de réponse avec une configuration minimale. Son tableau de bord présente des modèles d'invite versionnés et une détection de régression pour la qualité de sortie, vous alertant lorsque des modifications entraînent des résultats inattendus. Lunary propose également une API d'annotations pour baliser des expériences ou des tests A/B, permettant ainsi des comparaisons claires entre les essais. Bien que léger, il prend en charge les contrôles conditionnels pour la limitation du débit et le routage de secours. L'accent mis par Lunary sur la facilité de configuration et les fonctionnalités d'observabilité de base en fait la solution idéale pour les petites équipes ou les prototypes qui ont besoin d'un retour rapide sur le comportement des modèles sans intégrations complexes.
Utilisation variable des jetons : Les LLM génèrent des sorties jeton par jeton, de sorte que chaque demande peut consommer des nombres de jetons très différents. Le suivi et l'attribution des coûts deviennent complexes lorsque les volumes de jetons fluctuent énormément selon les invites et les utilisateurs. Sans un suivi précis des jetons, les équipes risquent des pics de facturation inattendus ou des demandes inefficaces inaperçues.
Volume de données élevé : La capture de paires complètes de réponses rapides, de métriques de jetons, de détails de latence et de métadonnées pour chaque inférence peut générer des millions d'entrées de journal par jour. Le stockage, l'indexation et l'interrogation de ce volume de données structurées nécessitent des solutions de stockage évolutives et des moteurs de requêtes optimisés pour éviter les goulots d'étranglement en termes de performances dans votre pipeline d'observabilité.
Complexité contextuelle : Le comportement du LLM dépend fortement de la rapidité de la formulation, des réglages de température et de la version du modèle. Corréler les changements de qualité de sortie ou de latence avec des modifications rapides spécifiques ou des ajustements de configuration nécessite des liens de trace et un versionnage robustes. Les équipes doivent mettre en œuvre un balisage cohérent des métadonnées et un contrôle de version rapide pour démêler l'ensemble des facteurs d'influence.
Corrélation entre fournisseurs : De nombreux déploiements font appel à plusieurs fournisseurs LLM pour l'équilibrage de charge ou l'optimisation des coûts. L'agrégation des métriques sur OpenAI, Azure, Anthropic et d'autres points de terminaison dans une vue unifiée nécessite de normaliser des API, des formats de réponse et des structures de coûts disparates. L'impossibilité d'unifier ces flux entraîne une fragmentation des informations et des angles morts dans les comparaisons de performances entre fournisseurs.
Alertes en temps réel et bruit : Il est difficile de définir des seuils d'alerte significatifs pour les taux d'erreur, les pics de latence ou les anomalies de coûts dans un environnement où les fluctuations naturelles sont courantes. Les alertes trop sensibles entraînent une lassitude des alertes, tandis que des seuils trop élevés peuvent retarder la détection de problèmes critiques. Les équipes ont besoin de stratégies d'alerte adaptatives qui apprennent les modèles d'utilisation normaux et ajustent les seuils de manière dynamique.
Conformité et confidentialité : Le stockage de journaux de conversations complets peut entrer en conflit avec les réglementations en matière de confidentialité des données ou les politiques de sécurité internes. Trouver un équilibre entre le besoin de données d'observabilité et les exigences de minimisation des données, de chiffrement et de contrôle d'accès nécessite une définition minutieuse des politiques et la prise en charge d'outils pour la rédaction sélective des journaux ou l'anonymisation.
Pour relever ces défis, il faut disposer d'un cadre d'observabilité robuste qui évolue en fonction de l'utilisation, applique des pratiques cohérentes en matière de métadonnées, normalise les données provenant de plusieurs fournisseurs et propose des alertes intelligentes pour identifier uniquement les problèmes les plus critiques.
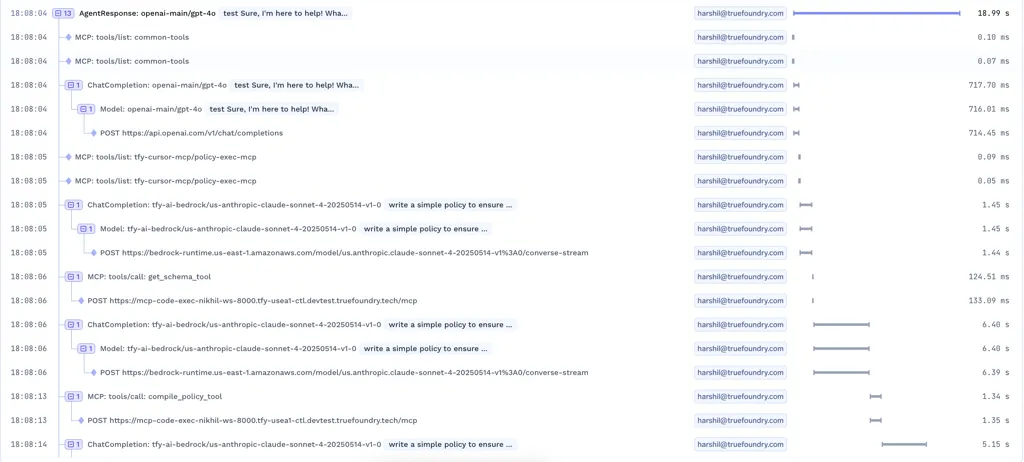
Dans les systèmes réels, une demande LLM est rarement un appel unique à un modèle. C'est une chaîne d'étapes.
La saisie par l'utilisateur devient une invite. Cette invite met en contexte. Le modèle répond. La réponse déclenche un outil. Le résultat de l'outil est réintégré au modèle. Ce n'est qu'alors que l'utilisateur reçoit une réponse. Chaque étape implique de répéter Inférence LLM, c'est pourquoi le traçage doit saisir toutes les décisions intermédiaires plutôt que uniquement le résultat final.
Un bon traçage le rend visible.
Les équipes ont besoin de voir :
Sans cela, le débogage devient une conjecture. Grâce à lui, les équipes peuvent suivre exactement ce qui s'est passé et où les choses se sont mal passées.
Pour de nombreuses équipes, le coût est la première véritable sonnette d'alarme. Les coûts du LLM n'augmentent pas comme les coûts d'infrastructure. Ils se développent au fil des jetons, de la verbosité, des nouvelles tentatives et des étapes intermédiaires masquées. Un petit changement rapide ou un agent qui se comporte mal peuvent discrètement doubler les dépenses.
C'est pourquoi la visibilité au niveau des jetons est importante.
Les équipes doivent comprendre :
Lorsque les données des jetons sont liées à des traces, les coûts cessent d'être une surprise et commencent à être quelque chose que vous pouvez gérer.
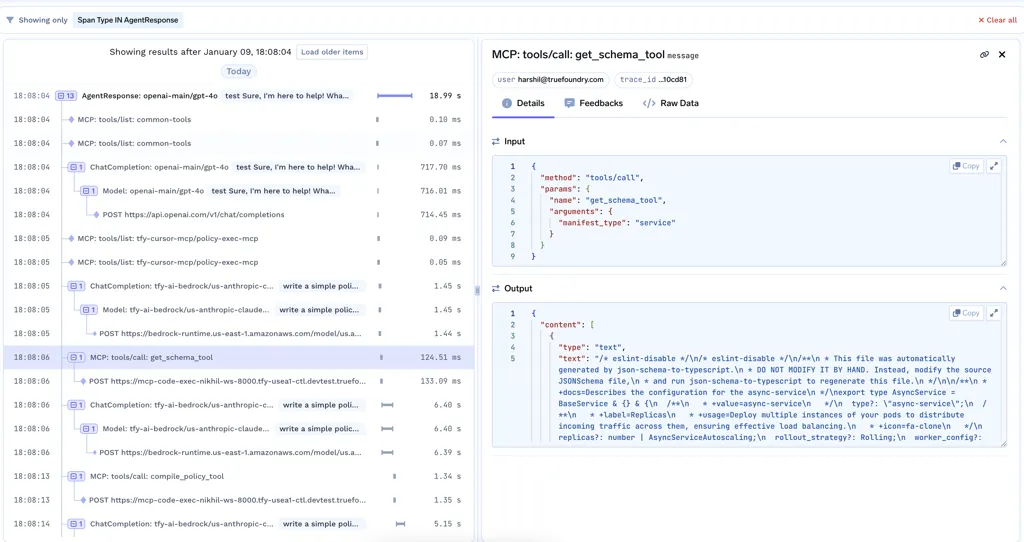
Une fois que les LLM commencent à appeler les outils, les choses deviennent plus puissantes et plus fragiles. Les agents peuvent effectuer des recherches dans des bases de données, appeler des API ou déclencher des flux de travail. Avec MCP, ces outils sont découverts et invoqués de manière dynamique, ce qui rend les systèmes plus flexibles mais aussi plus difficiles à raisonner.
En production, les équipes ont besoin de réponses claires à des questions fondamentales :
Sans observabilité au Niveau d'outil d'observabilité LLM, les équipes perdent rapidement confiance. Il leur permet d'auditer le comportement, de corriger les défaillances et de faire évoluer en toute sécurité les systèmes basés sur des agents.
L'objectif n'est pas d'améliorer les tableaux de bord. C'est de la confiance. Dans la pratique, c'est là LLmops devient critique, car les données d'observabilité doivent continuellement alimenter les décisions de déploiement, le contrôle des coûts et la gouvernance des modèles. Lorsque les équipes peuvent voir clairement les traces, l'utilisation des jetons et le comportement des outils, elles peuvent détecter les problèmes plus tôt, contrôler les coûts et améliorer la qualité sur la base de données de production réelles.
Cela crée une boucle : observez ce qui se passe en production, tirez-en des leçons, améliorez le système et recommencez. Des plateformes comme Passerelle IA de TrueFoundry aidez les équipes à y parvenir en regroupant le traçage, les mesures et la gouvernance en un seul endroit, afin que les systèmes LLM puissent être traités comme l'infrastructure critique qu'ils sont.
La mise en œuvre de l'observabilité LLM transforme les pipelines d'inférence opaques en systèmes transparents et gérables. En combinant des analyses interactives, un contexte basé sur les métadonnées, des contrôles politiques dynamiques, une journalisation complète et une exportation fluide des journaux, les équipes obtiennent les informations nécessaires pour surveiller les performances, contrôler les coûts et maintenir la qualité des résultats. Alors que des défis tels que l'utilisation variable des jetons, le volume de données et la corrélation entre fournisseurs nécessitent des architectures évolutives et des pratiques de métadonnées disciplinées, une solution d'observabilité unifiée vous permet de détecter les anomalies à un stade précoce, de résoudre les problèmes efficacement et d'itérer sur demande en toute confiance. Dans le paysage actuel piloté par l'IA, une observabilité LLM robuste n'est pas facultative mais essentielle pour fournir des applications fiables et rentables à grande échelle.
Réservez une démonstration pour découvrir comment TrueFoundry peut vous aider à améliorer l'observabilité du LLM.
L'observabilité en IA fait référence à la capacité de comprendre l'état interne d'un système en examinant sa télémétrie et ses sorties. En analysant les traces, les métriques et les journaux, les équipes peuvent diagnostiquer les problèmes de performance en temps réel. Cela garantit que les déploiements complexes restent transparents, fiables et étroitement alignés sur les objectifs commerciaux prévus.
Les cinq piliers de l'observabilité LLM incluent l'analyse interactive, le contexte piloté par les métadonnées, la journalisation complète, les évaluations et les exportations de journaux. Ces éléments fournissent une visibilité sur la consommation de jetons, les coûts et la qualité des réponses. Ensemble, ils permettent aux équipes d'ingénierie de surveiller, de dépanner et d'optimiser efficacement leurs applications LLM.
Parmi les plateformes populaires permettant d'obtenir des informations approfondies sur les modèles, citons LangSmith, Helicone et Arize Phoenix. Pour les organisations qui accordent la priorité à la souveraineté des données, TrueFoundry offre un moyen puissant de mettre en œuvre l'observabilité LLM au sein de leur propre infrastructure. Ces outils aident les développeurs à déboguer les chaînes de raisonnement, à suivre les coûts et à maintenir une qualité de sortie élevée des réponses.
La surveillance traditionnelle permet de suivre des indicateurs connus tels que la latence ou les taux d'erreur afin de préserver la santé de l'infrastructure. LLM Observability utilise le traçage sémantique pour expliquer pourquoi des problèmes spécifiques surviennent. Alors que la surveillance ne fait que signaler la défaillance d'un système, l'observabilité fournit les données détaillées et le contexte nécessaires pour trouver et corriger la cause première.
TrueFoundry est unique car il unifie le suivi au niveau des applications avec la surveillance de l'infrastructure au sein de votre propre VPC sécurisé. Il maintient une latence inférieure à 10 ms tout en gérant un trafic élevé entre plusieurs fournisseurs. Cette intégration garantit que les efforts d'observabilité du LLM restent rentables et sécurisés tout en fournissant des informations détaillées sur chaque interaction entre les modèles.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception







.png)

.webp)
.webp)
.webp)



.webp)
.webp)


