

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Les grands modèles linguistiques (LLM) transforment la façon dont les entreprises automatisent les tâches, génèrent du contenu et interagissent avec les données. Cependant, la plupart des services LLM actuels sont centrés sur le cloud, ce qui soulève des préoccupations en matière de sécurité, de conformité et de contrôle des données.
Pour les organisations qui traitent des informations sensibles ou réglementées, il n'est souvent pas viable de s'appuyer sur des API externes ou des modèles de cloud public. Cela a entraîné une évolution croissante vers les déploiements LLM sur site, dans le cadre desquels les entreprises exécutent des modèles en toute sécurité au sein de leur propre infrastructure.
Dans cet article, nous explorons ce que sont les LLM sur site, pourquoi elles sont importantes, comment elles fonctionnent et comment des plateformes telles que TrueFoundry permettent des déploiements évolutifs et sécurisés dans les environnements d'entreprise.

Les LLM sur site font référence à grands modèles de langage qui sont déployés et gérés au sein de la propre infrastructure de l'entreprise plutôt que par le biais de services cloud externes ou d'API tierces. Ces modèles peuvent être open source ou propriétaires et sont généralement exécutés sur des serveurs GPU internes, des centres de données privés ou des environnements cloud isolés configurés pour répondre aux normes internes de sécurité et de conformité.
Contrairement aux LLM hébergées dans le cloud qui s'appuient sur des terminaux publics et une infrastructure gérée par le fournisseur, les LLM sur site sont entièrement contrôlées par l'organisation. Cela permet une personnalisation, un réglage et une intégration accrus avec les systèmes et flux de travail internes. Les entreprises peuvent choisir les modèles à utiliser, tels que LLama 2, Mistral ou Mixtral, et les optimiser en fonction des besoins spécifiques de l'entreprise ou du domaine.
Le déploiement sur site permet aux équipes d'adapter le comportement des modèles, d'appliquer des politiques de résidence des données et de s'assurer que les informations sensibles ne quittent jamais leur réseau de confiance. Cela ouvre également la voie à un réglage plus strict des performances et à un contrôle des coûts, en particulier pour les applications à volume élevé ou sensibles à la latence. Pour les organisations qui accordent la priorité à l'autonomie, à la sécurité et à la conformité réglementaire, les LLM sur site offrent une alternative pratique et évolutive aux API d'IA commerciales.
Le déploiement de LLM sur site vous permet de contrôler totalement l'infrastructure, les données et le comportement des modèles. Cependant, cela nécessite également une planification minutieuse, des investissements et une gestion continue. Vous trouverez ci-dessous les principaux aspects à prendre en compte :
Vous avez besoin d'un matériel performant pour exécuter efficacement de grands modèles de langage. Cela inclut des GPU puissants tels que NVIDIA A100 ou H100, une mémoire vive suffisante, une mise en réseau haut débit et un stockage SSD rapide pour gérer des poids de modèles et des ensembles de données importants.
Vous conservez l'entière propriété de vos données, ce qui vous permet de configurer des espaces isolés, de mettre en place des politiques de pare-feu strictes et de vous conformer aux réglementations relatives à la résidence des données telles que le RGPD et la HIPAA. Le déploiement sur site est donc idéal pour les secteurs qui traitent des informations sensibles ou réglementées.
Vous devez implémenter des pipelines ML pour la gestion des versions, la conteneurisation, le déploiement et la surveillance. Le suivi continu des performances permet de garantir la précision, la fiabilité et la stabilité opérationnelle du modèle dans le temps.
Bien que vous évitiez les frais d'API récurrents basés sur des jetons, le déploiement de LLM sur site nécessite un investissement initial important en matériel. Vous devez également tenir compte des coûts opérationnels permanents tels que l'alimentation, le refroidissement, la maintenance et le personnel qualifié.
Vous bénéficiez d'un accès complet aux pondérations des modèles, ce qui vous permet d'effectuer des réglages avancés à l'aide de données propriétaires. Cela permet d'obtenir des performances hautement personnalisées adaptées aux flux de travail de votre organisation, contrairement aux modèles génériques hébergés dans le cloud.
Votre évolutivité dépend de la capacité matérielle disponible. Contrairement à la mise à l'échelle automatique du cloud, vous devez planifier les pics de charge de travail, mettre en œuvre un équilibrage de charge et optimiser les systèmes pour maintenir une faible latence et un débit élevé.
Votre équipe informatique ou DevOps interne est responsable de l'application des correctifs de sécurité, de la maintenance de l'infrastructure et des mises à jour des modèles. Une maintenance régulière garantit la fiabilité, la sécurité et la compatibilité du système avec l'évolution des exigences en matière d'IA.
Les services d'IA basés sur le cloud ont permis aux équipes d'expérimenter, de prototyper et de déployer facilement des modèles d'apprentissage automatique à grande échelle. Cependant, en ce qui concerne les charges de travail de production dans les environnements d'entreprise, le fait de s'appuyer uniquement sur des LLM centrés sur le cloud présente plusieurs limites qui ne peuvent être ignorées.
Confidentialité et contrôle des données constituent les préoccupations les plus importantes. Lorsque vous utilisez des API de cloud public, les données d'entrée sensibles doivent être transmises via Internet et traitées sur une infrastructure externe. Cela présente des risques de fuite de données, d'accès non autorisé et de violations de la conformité, en particulier dans des secteurs tels que la santé, la finance, la défense et les services juridiques, où des normes réglementaires strictes s'appliquent.
Verrouillage vis-à-vis d'un fournisseur constitue un autre inconvénient majeur. Les plateformes d'IA dans le cloud regroupent souvent des API d'inférence, du stockage et des ajustements dans des écosystèmes propriétaires. Une fois qu'un flux de travail est construit autour d'un fournisseur spécifique, la migration vers un autre service ou le transfert des charges de travail en interne prend du temps et coûte cher. Cette dépendance limite la flexibilité à long terme et le contrôle des mises à jour des modèles ou des conditions d'utilisation.
Dimensionnement imprévisible des coûts devient également un défi à mesure que l'utilisation augmente. Les LLM sont gourmands en ressources de calcul, et les modèles de tarification du cloud basés sur le nombre de jetons ou le volume des demandes peuvent entraîner une hausse des coûts opérationnels, en particulier pour les applications à haut débit ou à interaction constante.
En outre, les environnements cloud offrent des options limitées pour déploiements à faible latence et en périphérie. Les applications qui nécessitent des réponses quasi instantanées ou des fonctionnalités hors ligne peuvent avoir du mal à atteindre leurs objectifs de performance lorsqu'elles dépendent d'API externes.
Enfin, les fournisseurs de cloud suppriment une grande partie de l'infrastructure, laissant aux équipes une visibilité minimale sur les goulots d'étranglement en matière de performances, les opportunités d'optimisation ou les paramètres de réglage.
Pour les entreprises qui exigent le contrôle, la transparence et la durabilité à long terme, ces limites plaident en faveur de l'adoption de solutions LLM sur site.
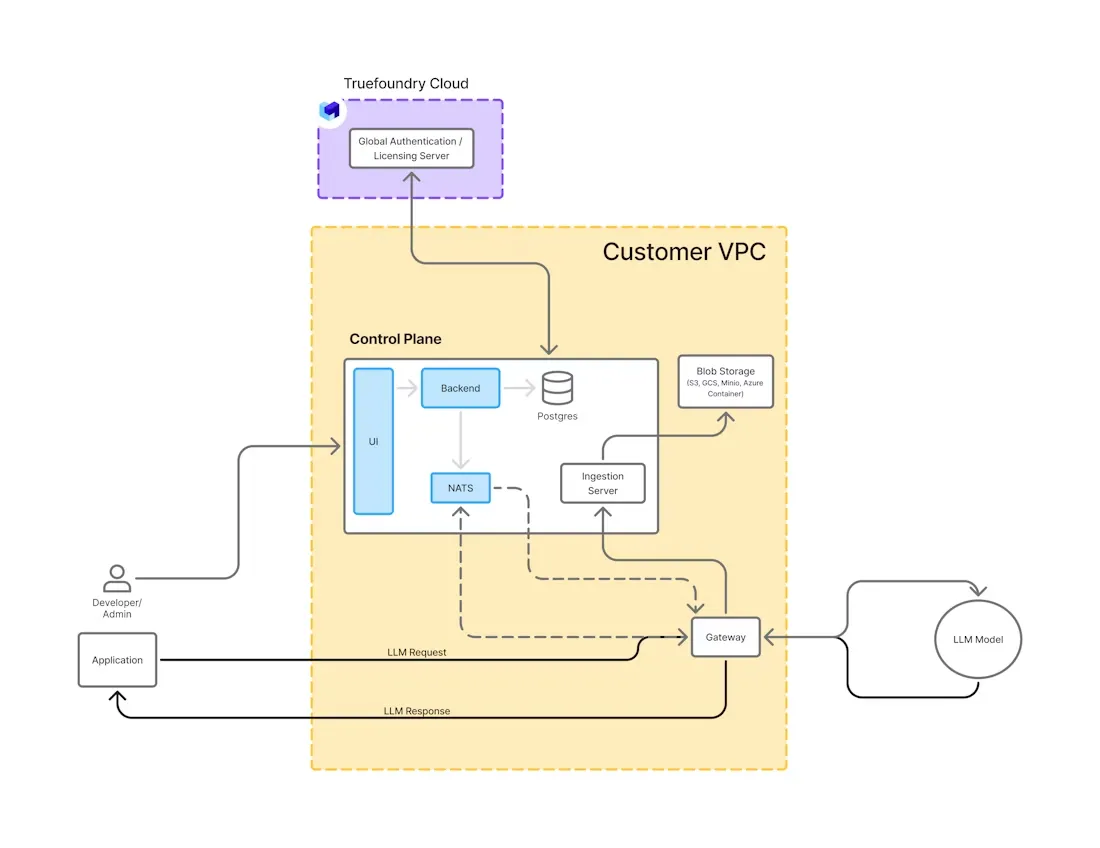
Le déploiement de LLM sur site nécessite une architecture soigneusement structurée qui équilibre les performances, la sécurité et la maintenabilité. Vous trouverez ci-dessous les principaux composants que l'on trouve généralement dans une configuration de production.
Infrastructure informatique : Les GPU hautes performances constituent la base des LLM sur site. Les entreprises utilisent souvent des GPU NVIDIA A100, H100 ou L40, en fonction de la taille du modèle et des exigences de débit. Ils sont hébergés dans des centres de données locaux ou des clusters de cloud privés dotés d'un refroidissement, d'une mise en réseau et d'un stockage appropriés.
Moteur d'inférence : Les frameworks d'inférence tels que vLLM, TGI ou DeepSpeed-Inference gèrent l'exécution réelle du modèle. Ils optimisent l'utilisation de la mémoire, prennent en charge le streaming de jetons et permettent de regrouper plusieurs demandes pour optimiser le débit.
Gestion et stockage des modèles : Les modèles sont stockés localement dans des référentiels d'artefacts sécurisés ou dans des montages de volume. Les mécanismes de contrôle des versions, de restauration et d'accès sont essentiels pour gérer les cycles de vie des modèles et auditer les modifications.
Conteneurisation et orchestration : Des outils tels que Docker et Kubernetes sont utilisés pour déployer, faire évoluer et gérer les charges de travail LLM. Kubernetes gère la mise à l'échelle automatique, la planification du GPU, l'équilibrage de charge et la reprise après panne, garantissant ainsi des performances constantes sur tous les services.
Couche API et routage : Une couche d'API compatible REST ou OpenAI expose les fonctionnalités LLM aux applications internes. Il peut inclure un routage multimodèle, une authentification des utilisateurs et un filtrage rapide pour des raisons de sécurité et de contrôle.
Observabilité et surveillance : Des mesures telles que la latence, l'utilisation du GPU, le débit des requêtes et la vitesse de génération de jetons sont suivies à l'aide d'outils tels que Prometheus, Grafana et OpenTelemetry. La journalisation et les alertes sont essentielles pour maintenir la disponibilité et résoudre les problèmes de débogage.
Cette architecture modulaire permet aux entreprises de créer des systèmes LLM évolutifs et sécurisés adaptés à leurs politiques internes, à leurs objectifs de performance et à leurs exigences de conformité.
Les LLM sur site sont de plus en plus adoptés dans les secteurs qui nécessitent la souveraineté des données, des performances à faible latence et un contrôle total des pipelines d'IA. Voici quelques cas d'utilisation courants et efficaces.
Les hôpitaux et les laboratoires de recherche utilisent les LLM pour résumer les notes des patients, générer des rapports de sortie et faciliter la documentation clinique. Les déploiements sur site garantissent que les informations relatives à la santé des patients restent au sein de l'infrastructure sécurisée de l'hôpital, conformément à la loi HIPAA et aux politiques relatives aux données de l'établissement.
Les institutions financières utilisent les LLM pour des tâches telles que la synthèse des appels de revenus, l'automatisation des rapports de conformité et l'analyse des états financiers. Les configurations sur site empêchent les données financières sensibles d'être exposées à des API tierces tout en garantissant la conformité aux cadres de risque internes et aux audits réglementaires.
Les agences utilisent les LLM pour répondre aux questions, résumer les rapports classifiés et rechercher des connaissances internes. Étant donné que les données de sécurité nationale doivent rester strictement contenues, les LLM sur site permettent des applications d'IA génératives sans enfreindre les protocoles de classification des données.
Les cabinets d'avocats et les services juridiques utilisent les LLM pour analyser les contrats, générer des résumés et faciliter la recherche juridique. Le déploiement sur site garantit que les informations confidentielles avocat-client ne quittent jamais les serveurs internes, préservant ainsi la confidentialité et répondant aux exigences de l'association du barreau.
Les entreprises du secteur manufacturier utilisent les LLM pour générer des guides de dépannage, interpréter les journaux des capteurs et aider les techniciens de terrain. Le déploiement de LLM sur des serveurs locaux permet d'éviter d'envoyer des données de machines propriétaires à des services externes et de réduire la latence dans les environnements distants ou déconnectés.
Les entreprises de télécommunications utilisent les LLM pour alimenter les chatbots, trier les tickets et fournir des recommandations de services automatisées. Le déploiement sur site permet des performances en temps réel tout en conservant les données des clients au sein de l'infrastructure interne afin de respecter les lois régionales en matière de confidentialité.
Ces cas d'utilisation montrent comment les LLM sur site permettent une automatisation et une intelligence puissantes sans compromettre la sécurité, la conformité ou le contrôle.
Le déploiement de LLM sur site implique une série d'étapes coordonnées, de la sélection du modèle au suivi de la production. Un flux de travail bien défini garantit que le système est évolutif, sécurisé et optimisé pour les besoins de votre organisation.
Le processus commence par le choix d'un modèle approprié en fonction de votre cas d'utilisation. Les modèles open source populaires tels que LLama 2, Mistral ou Mixtral sont souvent préférés pour les déploiements sur site. Une fois sélectionné, le modèle est téléchargé, quantifié si nécessaire et validé pour assurer sa compatibilité avec votre infrastructure.
Ensuite, les serveurs GPU ou les ressources cloud privées sont préparés. Cela inclut la configuration des environnements d'exécution des conteneurs (par exemple, Docker), des orchestrateurs (par exemple, Kubernetes) et des couches de stockage pour héberger les poids et les journaux des modèles. Les contrôles d'accès et les politiques de sécurité sont configurés pour répondre aux exigences de conformité.
Le modèle est chargé dans un moteur d'inférence tel que VLLm ou TGI. Ces moteurs fournissent l'environnement d'exécution pour la génération de texte en temps réel, le traitement par lots, le streaming et l'optimisation de la mémoire. Les fichiers de configuration définissent la taille des lots, le nombre maximum de jetons et les limites de simultanéité.
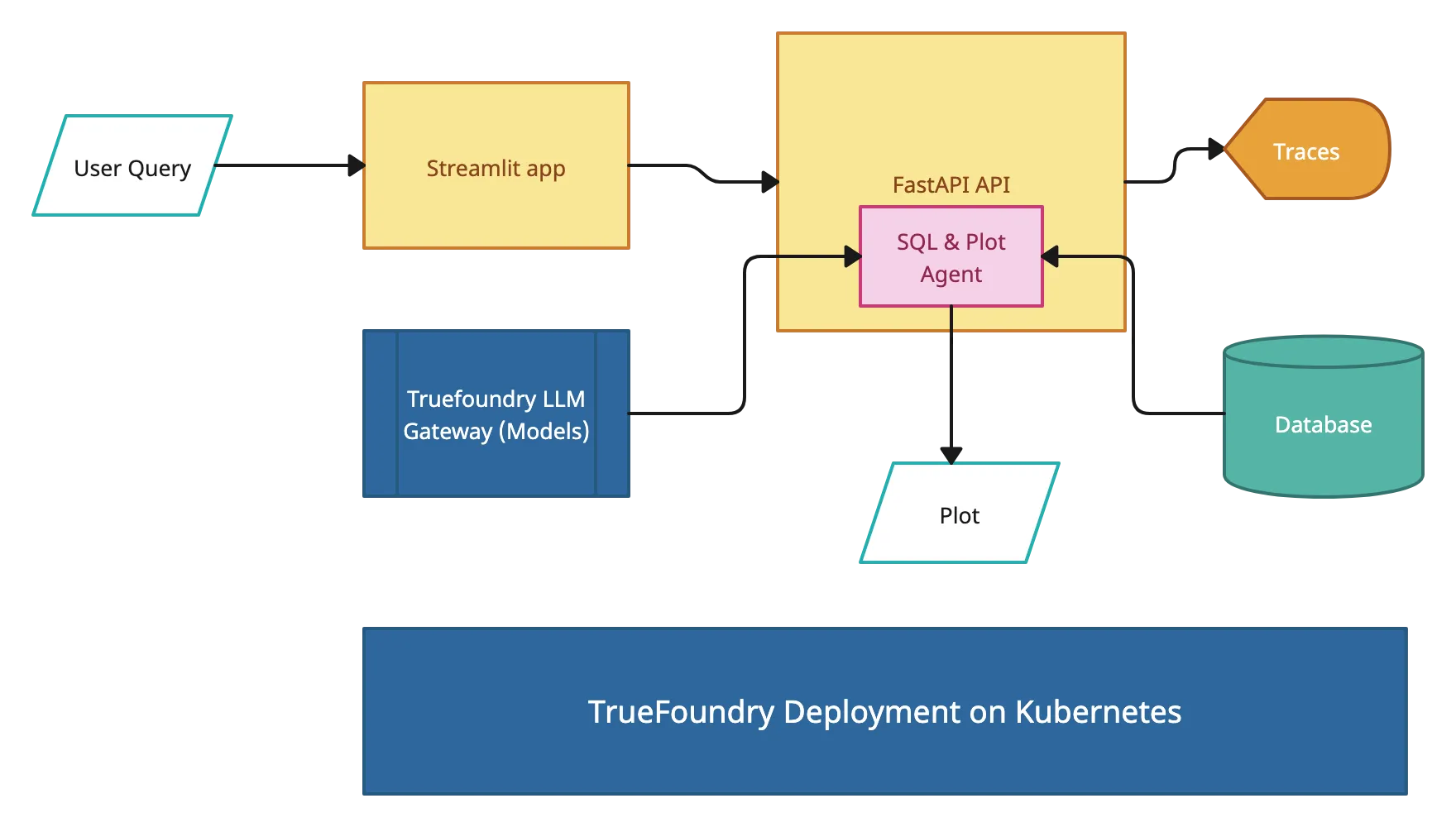
Une fois que le moteur est opérationnel, il est exposé via une API compatible REST ou OpenAI. Cela permet aux applications, outils ou interfaces utilisateur internes d'interroger le modèle. Un routage multimodèle, une authentification et une limitation de débit peuvent être ajoutés à cette couche pour un meilleur contrôle.
Les outils d'observabilité sont connectés pour suivre l'utilisation du GPU, la latence, le débit des jetons et les erreurs de requête. Sur la base des modèles de trafic, des politiques de dimensionnement automatique ou des procédures de dimensionnement manuelles sont configurées pour gérer la demande sans interruption.
Le respect de ce flux de travail aide les organisations à lancer et à gérer efficacement des LLM au sein de leur infrastructure sans avoir à recourir à des plateformes externes ni à exposer des données sensibles.
Ces outils et techniques vous aident à déployer des LLM sur site avec des performances, une sécurité et un contrôle total des données, tout en conservant une fiabilité de niveau professionnel.
Le déploiement de LLM sur site permet aux entreprises de contrôler totalement leur infrastructure d'IA, mais comporte également des compromis. Il est essentiel de comprendre à la fois les avantages et les défis pour une adoption réussie.
TrueFoundry simplifie le déploiement et la gestion de grands modèles linguistiques au sein d'une infrastructure privée, rendant GenAI sur site accessible aux entreprises sans nécessiter une expertise approfondie en matière de DevOps ou de MLOps. Construit sur Kubernetes, TrueFoundry permet un service LLM rapide, sécurisé et évolutif grâce à la prise en charge préintégrée de moteurs d'inférence hautes performances tels que vLLM et TGI.
La plateforme simplifie la gestion des conteneurs, des GPU et des politiques de dimensionnement, permettant aux équipes de se concentrer sur la création d'applications plutôt que sur la maintenance de l'infrastructure. Avec Passerelle IA de TrueFoundry, les organisations peuvent exposer les LLM à l'aide d'API compatibles avec OpenAI tout en appliquant une limitation de débit, une facturation basée sur des jetons et un routage multimodèle, le tout dans leur environnement sécurisé.
TrueFoundry offre également une observabilité intégrée, notamment une surveillance en temps réel de l'utilisation des jetons, de la latence et des performances des modèles. Cela permet aux équipes d'optimiser le débit, de résoudre les problèmes et de renforcer la gouvernance.
Qu'il s'agisse de déployer LLama 2, Mistral ou de modèles internes affinés, TrueFoundry offre aux entreprises une solution prête à la production pour GenAI sur site, entièrement personnalisable, conforme et conçue pour évoluer.
Alors que les entreprises adoptent de plus en plus de grands modèles linguistiques, le déploiement sur site offre une solution sécurisée et flexible pour les exploiter Génération I sans compromettre la confidentialité des données, la conformité ou le contrôle de l'infrastructure. Bien que les solutions basées sur le cloud soient pratiques, elles sont souvent insuffisantes dans les environnements réglementés ou sensibles. Les LLM sur site donnent aux entreprises la pleine propriété de la pile, une plus grande personnalisation et des coûts prévisibles, ce qui en fait la solution idéale pour les stratégies d'IA à long terme. Grâce à des plateformes telles que TrueFoundry, le déploiement et la mise à l'échelle des LLM en interne deviennent plus rapides, plus efficaces et plus faciles à gérer. Pour les organisations axées sur le contrôle, la transparence et l'innovation, GenAI sur site n'est pas seulement une alternative, c'est un avantage stratégique.
Vous déployez des LLM sur site en conteneurisant des modèles avec Docker, en les orchestrant via Kubernetes et en les diffusant via des moteurs d'inférence optimisés tels que vLLM ou TGI. Vous configurez les GPU, le réseau et le stockage, intégrez des outils de surveillance et implémentez des pipelines MLOps pour gérer le versionnage, la mise à l'échelle, la sécurité et les performances au sein de votre infrastructure privée.
Le déploiement dans le cloud offre une évolutivité à la demande, une infrastructure gérée et une tarification à l'utilisation, tandis que le déploiement sur site assure un contrôle, une personnalisation et une conformité complets des données. Vous échangez la flexibilité du cloud contre une sécurité et une souveraineté accrues sur site, mais vous devez gérer les coûts matériels, la maintenance, les limites d'évolutivité et la complexité opérationnelle en interne.
Vous pouvez utiliser des services LLM dans le cloud public, des environnements de cloud privé, des déploiements hybrides ou des plateformes d'IA gérées. Les modèles basés sur des API tels qu'OpenAI ou les terminaux Hugging Face hébergés réduisent les frais d'infrastructure. Les configurations hybrides vous permettent de conserver les données sensibles sur site tout en tirant parti de l'évolutivité du cloud pour les charges de travail et les expériences de pointe.
Les LLM sur site nécessitent des coûts matériels initiaux élevés, une maintenance continue, un personnel qualifié et une planification des capacités. Vous êtes confronté à des contraintes d'évolutivité, à des dépenses d'alimentation et de refroidissement et à des mises à niveau plus lentes. La gestion des correctifs de sécurité, des mises à jour des modèles et de la fiabilité de l'infrastructure accroît la complexité opérationnelle par rapport aux services d'IA entièrement gérés dans le cloud.
TrueFoundry simplifie le déploiement de LLM sur site en intégrant l'orchestration Kubernetes, la planification des GPU, le service de modèles, la surveillance et les contrôles de sécurité. Vous bénéficiez d'une gestion centralisée, d'un RBAC, d'une observabilité et d'une évolutivité fluide entre les environnements. Ses moteurs d'inférence préintégrés et ses fonctionnalités prêtes à être mises en conformité vous aident à déployer une IA de niveau production de manière sécurisée et efficace.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


