

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: June 11, 2026
.webp)
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Et si votre système d'intelligence artificielle pouvait réellement faire certaines choses, comme extraire des données d'un CRM, mettre à jour un tableau de bord ou envoyer un e-mail, sans avoir besoin d'une équipe d'ingénieurs pour tout configurer ? C'est là qu'intervient le Model Context Protocol, ou MCP. Il s'agit d'une nouvelle norme ouverte qui aide Agents d'IA connectez-vous en toute sécurité aux outils, aux systèmes et aux sources de données avec beaucoup moins d'efforts.
À mesure que l'IA devient plus performante, le véritable défi n'est pas le modèle. Il s'agit de lui donner accès au contexte et aux actions appropriés. Alors, comment MCP résout-il ce problème ? À quoi ça ressemble sous le capot ? Et pourquoi des entreprises comme Anthropic et Microsoft parient-elles dessus ? Allons-y.
.webp)
.webp)
MCP, abréviation de Model Context Protocol, est une norme ouverte conçue pour aider les agents d'IA à interagir avec des outils, des données et des services externes de manière structurée et sécurisée. Imaginez-le comme un connecteur universel qui permet à votre modèle d'IA de « se connecter » à des systèmes du monde réel, tout comme un port USB connecte des appareils à votre ordinateur. Plutôt que de s'appuyer sur des API codées en dur ou des intégrations propriétaires, MCP fournit un langage commun permettant aux outils et aux agents de communiquer entre eux. C'est le cœur de MCP contre API: les API traditionnelles exposent des points de terminaison prédéfinis, tandis que MCP ajoute un protocole structuré qui permet aux systèmes d'IA de découvrir de manière dynamique des outils, des ressources et des instructions lors de l'exécution.
Le protocole a été introduit par Anthropic dans le cadre de leur vision plus large visant à rendre les agents d'IA plus capables, plus sûrs et plus autonomes. Il utilise une architecture simple mais puissante : les clients (comme un modèle d'IA) envoient des requêtes à des serveurs (qui encapsulent des outils ou des sources de données) et obtiennent des réponses structurées qui peuvent être réintégrées au modèle en tant que contexte.
L'un des principaux avantages de MCP est sa modularité. Que votre outil soit une base de données, une application interne, un produit SaaS ou même un système de fichiers, vous pouvez l'exposer en tant que Serveur MCP. Cela signifie que vos agents n'ont pas besoin de suivre une nouvelle formation ou de réintégrer chaque fois qu'un nouveau système est ajouté. Ils suivent simplement le protocole.
MCP est également indépendant de la langue et flexible en matière de transport. Il prend en charge plusieurs SDK (Python, TypeScript, Java, C#) et peut fonctionner sur différentes couches de communication, notamment HTTP et WebSockets. Cela facilite son utilisation sur toutes les plateformes, que vous exécutiez des flux de travail d'IA dans le cloud, en périphérie ou même au sein d'environnements informatiques d'entreprise.
À la base, MCP fait passer la conversation sur l'IA à la question « que peut dire le modèle ? » à « que peut faire le modèle faire? » Et c'est exactement ce dont les agents ont besoin pour passer d'assistants passifs à de véritables collaborateurs décisionnels.
Le protocole MCP (Model Context Protocol) est conçu pour permettre aux agents IA d'interagir en toute sécurité avec des outils externes et des sources de données à l'aide d'une interface standardisée. Son architecture répartit clairement les responsabilités entre trois niveaux : l'hôte, le client et le serveur. Chaque couche joue un rôle spécifique dans la gestion de l'accès, le maintien de l'isolation et l'activation de l'échange de contexte.
Au cœur de tout cela se trouve un protocole de communication structuré et dynamique basé sur JSON-RPC 2.0 qui gère les flux requêtes-réponses entre les agents et les interfaces des outils. Le résultat est un système modulaire qui permet aux développeurs de créer une seule fois et de s'adapter à tous les agents, outils et domaines sans avoir à le réimplémenter. Cette séparation des préoccupations permet également aux équipes de travailler en parallèle sur le développement des agents et l'intégration des systèmes. L'architecture est conçue pour prendre en charge les déploiements locaux et distribués.
.webp)
L'hôte est l'environnement d'exécution principal de l'agent ou du modèle d'IA. Il coordonne tout, des politiques de sécurité à la stratégie d'échantillonnage en passant par les flux de travail d'appel d'outils. Les hôtes sont responsables de la création et de la gestion des instances clientes et jouent un rôle central dans la manière dont une application d'IA interagit avec l'écosystème MCP.
Par exemple, dans un système tel que Claude Desktop, l'hôte gère plusieurs connexions clients, chacune interagissant avec un service externe différent, tout en maintenant un contexte unifié pour la boucle de raisonnement du modèle.
Chaque client est un pont de communication dédié entre l'hôte et un seul serveur MCP. Il négocie les fonctionnalités avec le serveur, gère la session RPC et achemine les données dans les deux sens. Les clients sont conçus pour être isolés et apatrides au-delà de la portée d'une seule session.
Les clients agissent comme la couche d'abstraction qui permet au modèle d'IA d'invoquer des outils ou de récupérer des données sans être directement couplé aux détails de mise en œuvre du système.
Un serveur MCP est une enveloppe autour d'un outil, d'une API ou d'un système externe. Il expose les fonctionnalités et les données dans un format standardisé, ce qui les rend accessibles à tout client compatible MCP. Les serveurs fonctionnent de manière indépendante et sont chargés de définir l'étendue de leurs capacités.
Par exemple, un serveur peut exposer une base de données Postgres en tant que ressource interrogeable ou encapsuler l'API de GitHub sous la forme d'un ensemble d'outils appelables. Une fois créé, le même serveur peut servir plusieurs types de clients sur différents hôtes.
Remarque : La conception hôte-client-serveur de MCP impose une séparation stricte des responsabilités. L'hôte contrôle l'accès et le contexte, chaque client gère une session isolée et les serveurs exposent les fonctionnalités de l'outil via un protocole standard. Cette structure est essentielle pour créer des systèmes d'agents IA sécurisés, modulaires et évolutifs à travers diverses chaînes d'outils.
Les interactions MCP sont régies par quatre primitives clés : les outils, les ressources, les invites et la couche session. Ces composants éliminent la complexité de bas niveau et fournissent une interface claire permettant aux modèles de raisonner, d'agir et d'interagir avec des systèmes du monde réel de manière modulaire et prévisible.
Les outils sont des fonctions exécutables exposées par le serveur et appelables par le modèle via le client. Chaque outil est défini à l'aide de paramètres d'entrée, d'un schéma de sortie et d'une description de son objectif. Ces métadonnées sont utilisées par le modèle pour déterminer quand et comment utiliser un outil. Les exemples incluent la création de tickets d'assistance, l'envoi de messages Slack ou le lancement de flux de travail. Les outils peuvent être synchrones ou asynchrones, selon l'implémentation du backend. Le modèle détermine le moment d'invocation de l'outil en fonction du contexte actuel et de l'intention de la tâche.
Les ressources sont des données en lecture seule que les serveurs exposent pour fournir un contexte au modèle. Il peut s'agir d'enregistrements de base de données, de documents, d'entrées de journal ou de résultats de recherche. Les clients demandent des ressources lorsque le modèle doit rechercher ou récupérer des données avant d'effectuer une action. Les serveurs définissent ce qui est disponible et le client gère le formatage pour l'inclure dans l'invite du modèle. Les ressources sont essentielles pour fonder les réponses des agents sur des informations actualisées et pertinentes.
Les invites sont des modèles prédéfinis ou des flux d'interaction enregistrés par le serveur. Ils servent d'échafaudages structurés qui peuvent guider le comportement du modèle dans des contextes spécifiques. Par exemple, une invite peut définir la mise en page d'un rapport de bogue, d'un e-mail d'escalade ou d'un guide d'intégration. Les invites peuvent être déclenchées par l'utilisateur ou invoquées par programmation. Leur rôle est de renforcer la cohérence, de réduire les hallucinations et d'accélérer la génération structurée dans les flux de travail à enjeux élevés.
Toutes les communications entre les clients et les serveurs se font via JSON-RPC 2.0. Ce protocole prend en charge la messagerie bidirectionnelle avec état et est flexible en matière de transport. Il fonctionne sur STDIO, HTTP/SSE ou WebSockets. La couche session permet les appels requêtes-réponses, les notifications d'événements, l'enregistrement des capacités et les opérations de longue durée. En adhérant à la norme JSON-RPC, MCP garantit une saisie efficace, des modèles de communication prévisibles et une compatibilité entre les langues et les plateformes. Ce modèle de session permet la découverte dynamique d'outils et l'interaction lors de l'exécution.
Remarque : Les outils, les ressources, les instructions et la couche de session constituent la base de chaque interaction MCP. Ils permettent aux modèles de raisonner, d'agir et de récupérer le contexte à l'aide de primitives structurées et prévisibles, permettant ainsi une intégration en temps réel avec des systèmes externes sans sacrifier la sécurité ou la flexibilité.
Lorsque vous utilisez des serveurs MCP (Model Context Protocol), la sécurité est une priorité absolue car ces serveurs agissent comme des passerelles entre les modèles d'IA et les systèmes externes. Une sécurité adéquate garantit que les données sensibles, les API et les flux de travail commerciaux restent protégés tout en permettant des intégrations d'IA fluides.
Un serveur MCP correctement sécurisé fournit un environnement sécurisé permettant aux modèles d'IA d'interagir avec des systèmes externes tout en minimisant le risque de violation de données, d'utilisation abusive ou de défaillance du système.
MCP fonctionne selon un flux structuré en cinq étapes qui permet aux modèles de langage de découvrir, d'invoquer et d'interagir avec des outils et des sources de données en temps réel. Voici comment fonctionne le protocole sous le capot :
L'application hôte lance le processus en lançant un ou plusieurs clients MCP, chacun étant configuré pour se connecter à un serveur MCP spécifique. L'hôte est également responsable de la gestion des autorisations des utilisateurs, de l'application des politiques de contrôle d'accès et de la gestion du contexte dans les interactions entre plusieurs outils.
Chaque client initie une poignée de main avec le serveur qui lui est attribué. Au cours de cet échange, le serveur annonce ses outils, ressources et invites pris en charge, avec des descriptions, des paramètres d'entrée et des types de retour. Le client regroupe ensuite ces métadonnées dans le contexte du modèle afin que celui-ci sache ce qu'il peut utiliser.
Les données de capacité étant désormais intégrées à son invite, le modèle raisonne en fonction des outils disponibles et des entrées actuelles de l'utilisateur. Si la tâche nécessite une action ou une récupération d'informations, le modèle décide de l'outil ou de la ressource à invoquer, formule les paramètres appropriés et envoie la demande au client.
Le client transmet la demande du modèle au serveur à l'aide de JSON-RPC. Le serveur exécute la fonction ou récupère les données, puis renvoie une réponse structurée. Le client renvoie le résultat au modèle, qui l'utilise pour poursuivre le traitement ou prendre d'autres décisions.
L'application hôte surveille la boucle complète, gère l'état de la session en cours, enregistre l'utilisation des outils, applique les limites de débit et veille à ce que l'agent reste dans les limites de son périmètre. Cette étape garantit la sécurité, la traçabilité et l'observabilité des actions pilotées par l'IA.
.webp)
Ce diagramme montre comment un agent IA utilise le MCP pour découvrir des outils, appeler des actions et gérer les tickets sur plusieurs serveurs en temps réel. Il visualise le flux complet de bout en bout, de l'entrée de l'utilisateur à la réponse du système.
Prenons l'exemple d'un agent de support basé sur l'IA intégré à une application de support technique. Lorsque l'application hôte démarre, elle initialise deux clients MCP : l'un connecté à un serveur MCP Zendesk et l'autre lié à un système d'escalade interne. Chaque client effectue un échange de fonctionnalités avec son serveur respectif. Le serveur Zendesk propose des outils tels que GetTicketByID et UpdateTicketStatus, tandis que le serveur d'escalade expose EscalateTicket.
Ces métadonnées sont transmises au contexte du modèle. Lorsqu'un utilisateur saisit l'instruction « Escalade le ticket #1289 s'il est marqué comme urgent », le modèle interprète la demande et détermine qu'il doit d'abord récupérer le ticket. Il appelle GetTicketByID (« 1289 ») via le client Zendesk. Le serveur répond avec les détails du ticket, indiquant que la priorité est « urgente ». Sur cette base, le modèle décide d'aggraver le problème et appelle EscalateTicket (« 1289") via le second client.
Les deux appels sont exécutés via JSON-RPC. Les clients transmettent les demandes à leurs serveurs respectifs, qui traitent les fonctions et renvoient des réponses structurées. Ces réponses, les métadonnées du ticket et la confirmation d'escalade sont renvoyées vers le modèle et intégrées à son contexte. L'hôte finalise ensuite la boucle en enregistrant les interactions, en validant les politiques d'accès et en mettant à jour l'interface utilisateur avec le résultat : « Le ticket #1289 a été escaladé avec succès ».
Avant d'intégrer des systèmes d'IA, il est important de comprendre comment le MCP (Model Context Protocol) et le RAG (Retrieval-Augmented Generation) ont des objectifs différents. Tout en améliorant les fonctionnalités LLM, MCP se concentre sur la connexion des modèles aux outils et aux API, tandis que RAG enrichit les réponses des modèles grâce à des connaissances externes.
Lisez également : MCP contre RAG
À mesure que les agents d'IA gagnent en capacité, leur principale limite n'est pas le raisonnement, mais l'accès. La plupart des modèles de langage fonctionnent de manière isolée, sans aucun moyen structuré d'interagir avec des outils externes ou des sources de données. Les développeurs finissent par coder en dur les appels d'API, créer des wrappers fragiles ou gérer des intégrations ponctuelles qui ne s'adaptent pas bien. Cela ralentit non seulement le développement, mais pose également des problèmes de sécurité et de maintenabilité.
MCP résout ce problème en normalisant la façon dont les agents d'IA découvrent, raisonnent et invoquent les outils. Il définit un protocole propre qui permet aux systèmes d'exposer leurs fonctionnalités, telles que les API, les bases de données ou les systèmes de fichiers, de manière structurée et conviviale pour les modèles. Les agents, quant à eux, peuvent apprendre dynamiquement quelles actions sont disponibles, décider quand les utiliser et les déclencher en toute sécurité à l'aide de JSON-RPC.
Prenons l'exemple d'un assistant IA intégré à une plateforme RH d'entreprise. À l'aide de MCP, l'assistant peut se connecter à un serveur de paie, à une base de connaissances interne et à un annuaire des employés, chacun en tant que serveur MCP. Lorsqu'un responsable tape « Accordez à Rahul cinq jours de congé et prévenez les RH », le modèle appelle dynamiquement les outils appropriés exposés par ces serveurs : un pour mettre à jour le statut des congés, un autre pour envoyer un message Slack aux RH et un troisième pour enregistrer la demande dans le système interne, le tout en temps réel, sans aucun code personnalisé dans le modèle.
Ce type d'orchestration serait fragile et coûteux à créer manuellement. Avec MCP, il devient modulaire, reproductible et sécurisé sur Plateformes d'automatisation MCP. Avec MCP, il devient modulaire, reproductible et sécurisé. Au fur et à mesure que les organisations déploient de plus en plus d'outils et de services, MCP garantit que les agents IA peuvent interagir avec eux de manière sûre et intelligente, sans avoir besoin de nouvelles intégrations pour chaque changement.
Les appels de fonctions ont permis aux modèles de langage d'interagir avec les outils de manière structurée. Vous définissez un outil, ses paramètres et son objectif, et le modèle peut l'invoquer en renvoyant un objet JSON. Cela fonctionne bien pour les cas d'utilisation simples, en particulier lorsque le nombre d'outils est faible et statique. Mais l'appel de fonction présente des limites critiques : il suppose que vous connaissez tous les outils à l'avance, que chaque modèle y est étroitement lié et que l'infrastructure qui les entoure est soit codée en dur, soit fragile.
MCP comble ces lacunes en introduisant un protocole complet, et pas seulement un format. Pour les équipes qui évaluent MCP contre A2A, cette distinction est importante car le MCP normalise l'interaction entre le modèle et l'outil, tandis que l'A2A se concentre sur la communication entre les agents autonomes. Il formalise l'interaction entre les agents d'IA et les systèmes externes à l'aide d'une architecture hôte-client-serveur et d'une communication structurée via JSON-RPC. Plutôt que d'intégrer des définitions d'outils directement dans l'invite du modèle, MCP permet aux modèles de découvrir dynamiquement quels outils sont disponibles au moment de l'exécution, de les invoquer en toute sécurité et de recevoir des réponses structurées, le tout via une interface standard.
Imaginez un assistant intelligent intégré dans un tableau de bord des opérations de vente au détail. Avec l'appel de fonction, le modèle devrait être configuré manuellement avec l'accès à des outils tels que GetInventory, UpdatePrice et NotifyWarehouse. Chaque outil doit être connecté à l'invite système de l'agent. Mais avec MCP, vous pouvez vous connecter à différents serveurs : un pour l'inventaire, un pour la tarification, un pour la logistique, et l'agent découvrira automatiquement tous les outils exposés. Pas de codage en dur, pas de redéploiement.
L'appel de fonction était une première étape nécessaire. MCP s'appuie sur cette base avec l'infrastructure, le protocole et la flexibilité nécessaires pour créer des systèmes d'agents robustes et de qualité production.
.webp)
TrueFoundry Passerelle MCP fournit un portail unique pour découvrir et enregistrer tous vos serveurs MCP, qu'ils soient internes, sur site, hybrides ou tiers, dans des « groupes de serveurs MCP » organisés qui isolent les environnements (par exemple, développement et production) et appliquent des flux d'approbation pilotés par le RBAC pour la gouvernance et la visibilité. Prêt à l'emploi, le Gateway inclut des connecteurs prédéfinis pour les outils d'entreprise tels que Slack, Confluence, Datadog, Sentry et GitHub, permettant une intégration zéro code dans les flux de travail des agents LLM. Pour des besoins personnalisés, vous pouvez enregistrer n'importe quelle API interne ou propriétaire en quelques minutes pour la rendre instantanément détectable et utilisable par les agents alimentés par LLM sans modifier votre SDK.
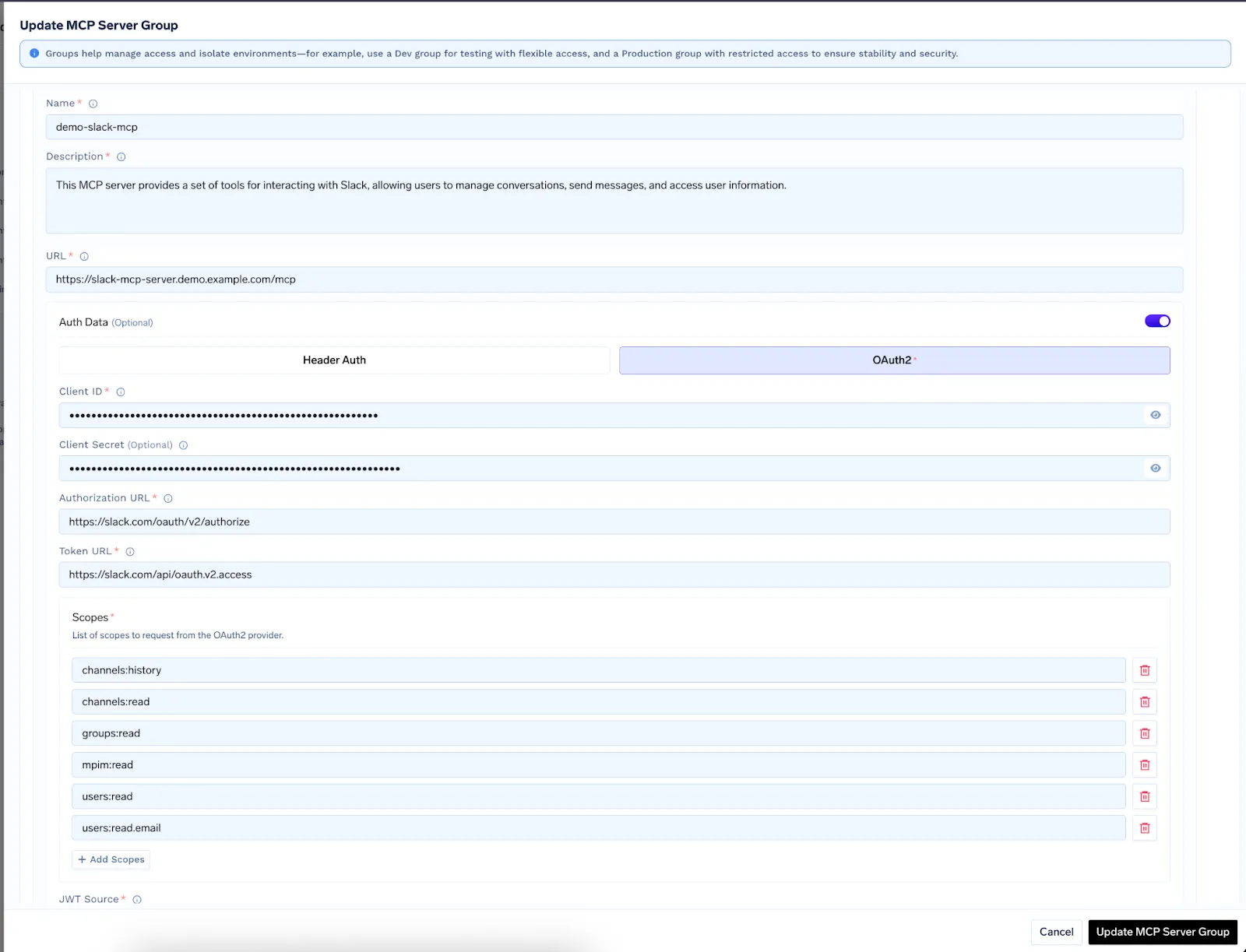
La passerelle prend en charge plusieurs schémas d'authentification, notamment l'absence d'authentification, les jetons basés sur les en-têtes et les informations d'identification du client OAuth2, avec un SSO fédéré via des fournisseurs d'identité tels qu'Okta et Azure AD. Les informations d'identification OAuth2 sont stockées en toute sécurité dans le gestionnaire de secrets intégré à TrueFoundry et injectées automatiquement lors des demandes de proxy, centralisant ainsi la gestion des informations d'identification et réduisant les risques.
.webp)
Les développeurs peuvent interagir par programmation avec les serveurs MCP enregistrés à l'aide des SDK Python et TypeScript officiels, qui gèrent Autorisation MCP de bout en bout, ou via l'AI Gateway Playground, une interface intuitive dans laquelle vous ajoutez des serveurs MCP, sélectionnez des outils et exécutez des instructions en langage naturel qui invoquent des services à distance en temps réel. Le Playground et le SDK fournissent tous deux des boutons « Extrait de code d'API » pour générer un schéma d'intégration prêt à l'emploi dans la langue de votre choix.
La passerelle IA de TrueFoundry intègre une observabilité et un équilibrage de charge de niveau entreprise. Les demandes sont acheminées en fonction du poids ou de la latence vers les terminaux les plus sains, tandis que toutes les invocations MCP sont enregistrées et auditées dans des tableaux de bord de gouvernance, garantissant ainsi la conformité et le suivi des performances. Dans un blog récent, l'équipe décrit comment la passerelle agit en tant que plan de contrôle central pour une infrastructure d'IA générative moderne, en unifiant les LLM, les serveurs MCP et les protocoles agent-agent au sein d'une seule interface pour une faible latence, une fiabilité élevée et une évolutivité fluide. Cette approche permet l'orchestration en langage naturel dans les systèmes de l'entreprise, permettant ainsi une automatisation de bout en bout, telle que la création de problèmes Jira à partir d'alertes Slack, sans écrire de code d'intégration.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


