

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Les grands modèles de langage deviennent rapidement une couche centrale des logiciels d'entreprise. Ce qui n'était au départ qu'une expérimentation basée sur le cloud avec des API hébergées évolue aujourd'hui vers des systèmes de production intégrés à des outils internes, à des applications destinées aux clients et à des flux de travail automatisés.
Face à cette évolution, de nombreuses entreprises sont confrontées à une dure réalité : les charges de travail liées à l'IA ne peuvent pas toutes être exécutées dans le cloud public.
Les données d'entreprise sensibles, la propriété intellectuelle exclusive, les charges de travail réglementées, les applications critiques en matière de latence et les obligations de conformité incitent les équipes à déployer des LLM au sein infrastructure sur site ou privée. Cependant, de simples modèles d'auto-hébergement ne résolvent pas le problème opérationnel plus vaste. À mesure que de plus en plus d'équipes, d'applications et de modèles sont mis en ligne, les entreprises ont besoin d'un moyen cohérent de contrôler l'accès, d'appliquer les politiques, de surveiller l'utilisation et de gérer les coûts au sein de leur écosystème LLM.
C'est là qu'un Infrastructure sur site LLM Gateway devient fondamental.
Plutôt que de permettre à chaque application de s'intégrer directement à des modèles individuels, une passerelle LLM introduit une couche de contrôle centralisée qui régit la manière dont les modèles sont accessibles et utilisés. Dans les environnements sur site, cette passerelle devient l'épine dorsale qui permet aux entreprises de faire évoluer l'adoption du LLM de manière sécurisée, conforme et efficace sans sacrifier la visibilité ou le contrôle.
Un Passerelle LLM est une couche d'accès et de gouvernance centralisée située entre les applications et les modèles de langage. Au lieu que les applications appellent directement les modèles, toutes les demandes LLM transitent par la passerelle, qui assure la sécurité, le routage, l'observabilité et les contrôles de politique en un seul endroit.
Dans un configuration sur site, la passerelle et les modèles s'exécutent entièrement au sein de l'infrastructure de l'entreprise, telle qu'un centre de données, un cloud privé (VPC) ou un environnement isolé. Cela garantit que les invites, les réponses, les intégrations et les métadonnées ne quittent jamais des limites contrôlées.
À un niveau élevé, une passerelle LLM sur site fournit :
En faisant abstraction de l'accès au modèle derrière une API standardisée, la passerelle dissocie le développement des applications de l'infrastructure du modèle. Les équipes peuvent changer de modèle, introduire des versions affinées ou appliquer de nouvelles règles de gouvernance sans modifier le code de l'application.
Dans les environnements sur site où l'infrastructure est limitée, les exigences de conformité strictes et la complexité opérationnelle élevée, cette couche de passerelle centralisée est ce qui rend l'adoption du LLM à grande échelle viable. Il transforme les modèles auto-hébergés issus de déploiements isolés en une plateforme d'IA gouvernée et prête à la production.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

L'exécution de LLM sur site est rarement une simple décision d'infrastructure. Il est généralement piloté par exigences non négociables de l'entreprise autour du contrôle, de la sécurité et de la gouvernance des données. Un Passerelle LLM est ce qui rend ces déploiements pratiques à grande échelle.
Les entreprises traitent souvent des entrées sensibles telles que des documents internes, des dossiers clients, du code source ou des données classifiées. Dans les environnements réglementés, même des données rapides et transitoires quittant une infrastructure contrôlée sont inacceptables.
Une passerelle LLM sur site garantit que :
Cela est particulièrement important pour les organisations soumises à des exigences strictes en matière de localisation des données ou de souveraineté.
Les intégrations directes entre les applications et les modèles créent des limites de sécurité fragmentées. Chaque service finit par gérer ses propres informations d'identification, ses autorisations et sa logique d'accès, ce qui rend difficile l'application de normes de sécurité uniformes.
Une passerelle LLM centralise :
En acheminant l'ensemble du trafic via une seule couche de contrôle, les entreprises réduisent considérablement leur surface d'attaque et gagnent en confiance dans la manière dont les modèles sont accessibles.
Les cadres réglementaires obligent de plus en plus les organisations à répondre à des questions telles que :
Une passerelle LLM sur site fournit des pistes d'audit intégrées par défaut. Chaque demande peut être enregistrée, mesurée et tracée sans avoir à faire appel à des équipes d'application individuelles pour implémenter correctement la logique de conformité.
Cela est essentiel pour les environnements soumis au RGPD, à l'ITAR, à l'HIPAA ou à des normes de gouvernance internes.
Les ressources GPU sur site sont limitées et coûteuses. Sans contrôles centralisés, les équipes peuvent facilement surconsommer la capacité d'inférence ou déployer des charges de travail inefficaces.
Une passerelle LLM permet de :
Cela permet aux organisations de traiter l'inférence LLM comme une ressource gérée plutôt que comme une dépense incontrôlée.
Un sur site LLM Gateway n'est pas un service unique, c'est un pile d'infrastructure en couches conçu pour contrôler la manière dont les modèles sont accessibles, gérés et exploités dans les environnements d'entreprise.
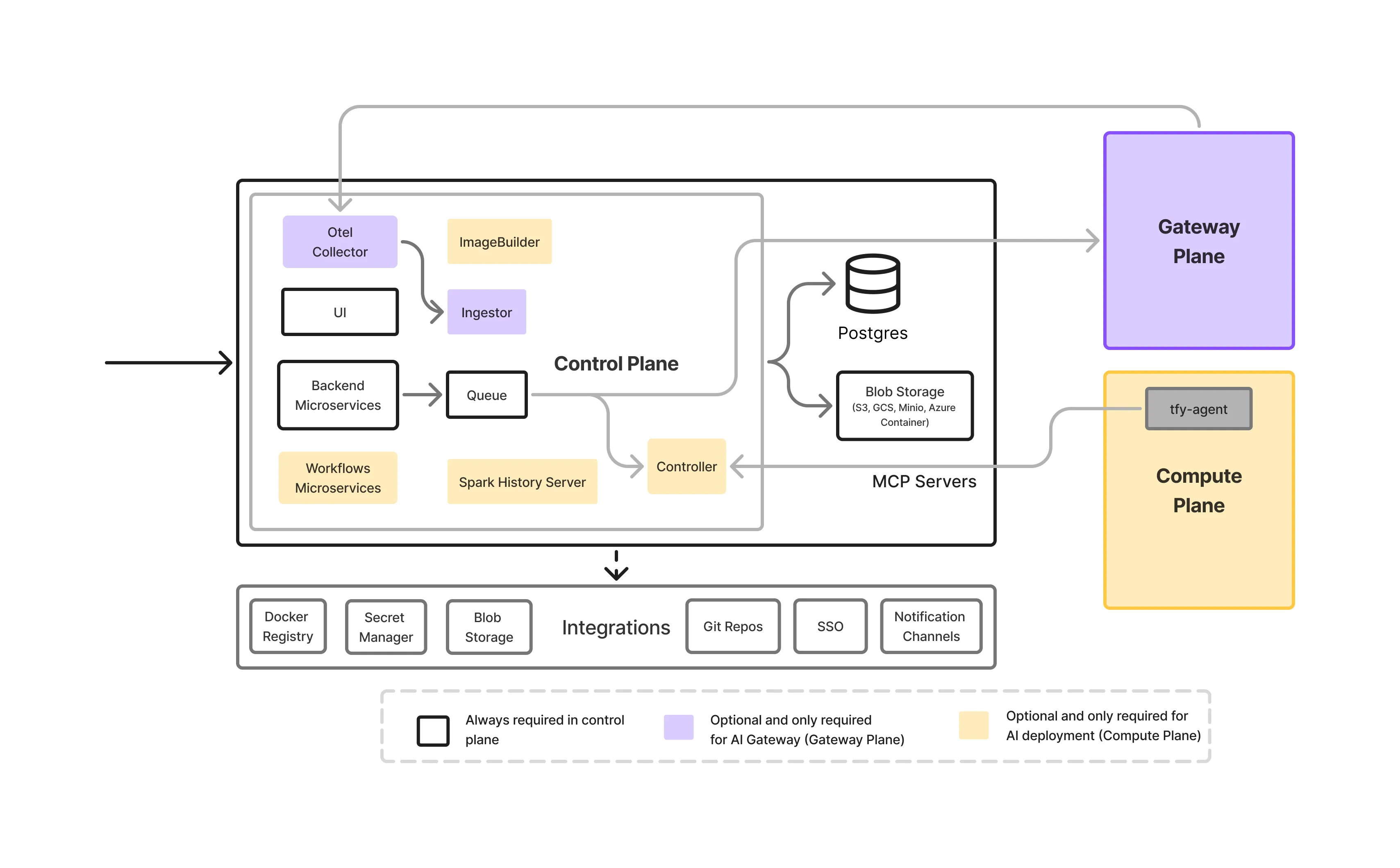
C'est la porte d'entrée pour tout le trafic LLM.
Il gère l'authentification, l'autorisation, la validation des demandes et les décisions de routage. En appliquant les politiques de manière centralisée, le plan de contrôle évite aux équipes chargées des applications d'intégrer une logique de sécurité ou de gouvernance dans leur code.
Cette couche est responsable de service de modèles, hébergeant les LLM réels exécutés sur site et les exposant à une inférence à faible latence accélérée par GPU, notamment :
La passerelle résume ces modèles dans une API unifiée, permettant aux équipes de modifier ou de mettre à niveau les modèles sans affecter les applications.
La visibilité est essentielle dans les environnements sur site où les ressources sont limitées.
La passerelle fournit :
Cela permet aux équipes de comprendre comment les modèles sont utilisés et d'identifier rapidement les problèmes de performance ou de coûts.
Les règles de gouvernance sont définies une seule fois et appliquées partout.
Cela inclut :
La gouvernance centralisée empêche la dérive des politiques entre les équipes et les applications.
Les services de passerelle et de modèle s'exécutent généralement sur une infrastructure basée sur Kubernetes avec prise en charge du GPU. Cette couche fournit :
Cela garantit que la passerelle fonctionne de manière fiable dans le cadre de l'ensemble plus large de l'IA sur site.
Dans une configuration sur site, la passerelle LLM fait office de couche de commande centrale entre les applications et les modèles auto-hébergés. Toutes les demandes passent par cette couche, ce qui garantit une sécurité, une gouvernance et une observabilité cohérentes.
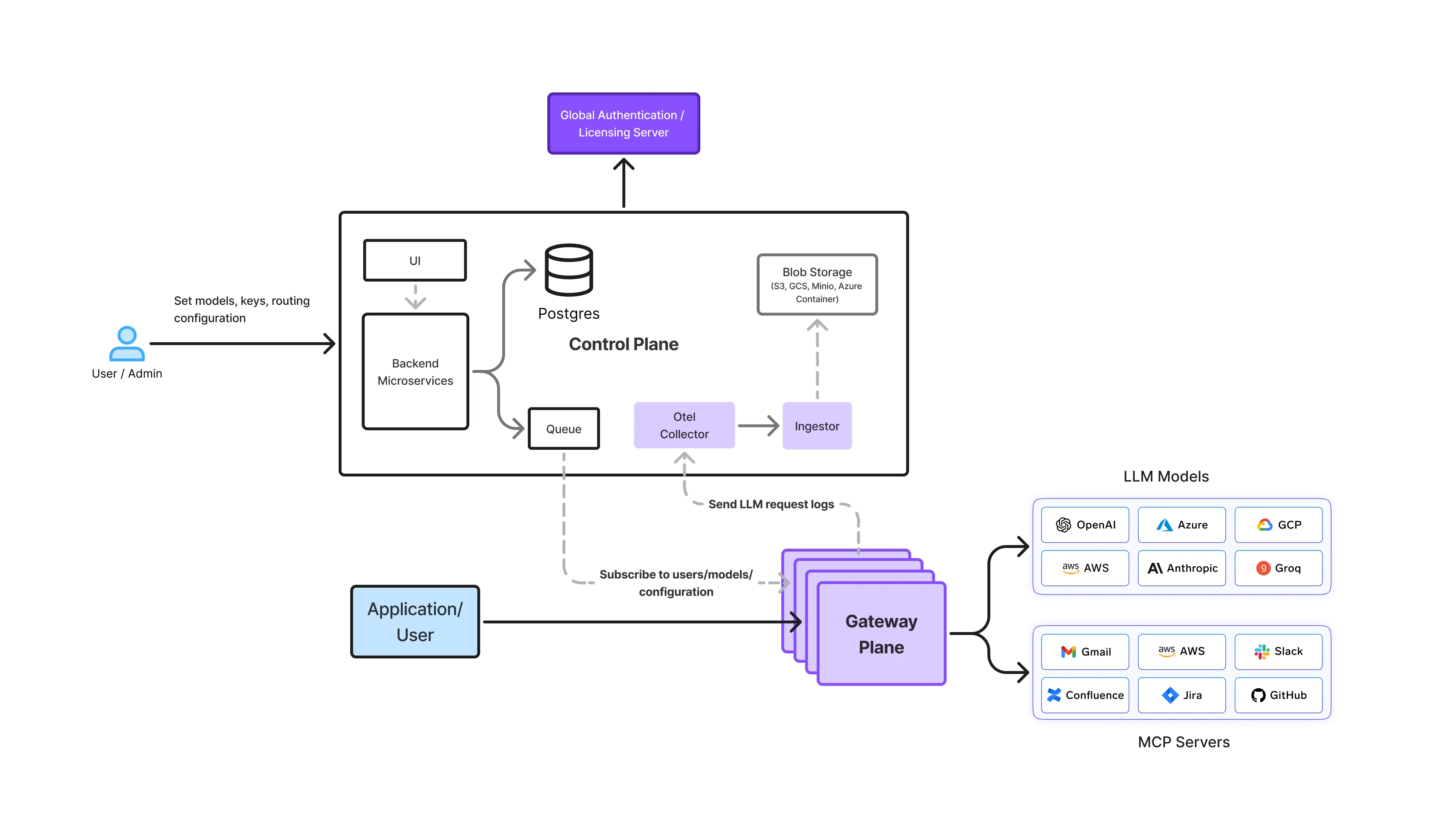
Les entreprises déploient des passerelles LLM sur site de différentes manières en fonction des exigences de sécurité, de conformité et de connectivité. L'architecture de la passerelle reste la même, le modèle de déploiement change.
Dans les environnements hautement réglementés, l'infrastructure fonctionne avec pas d'accès au réseau externe.
Dans ces configurations, la passerelle LLM fournit un contrôle complet tout en répondant à des exigences d'isolation strictes.
De nombreuses entreprises déploient des passerelles LLM dans leurs propres comptes cloud ou réseaux privés.
Ce modèle est courant pour les organisations de services financiers et de SaaS réglementées.
Certaines organisations répartissent les charges de travail en fonction de leur sensibilité.
La passerelle garantit la cohérence des politiques, même lorsque plusieurs environnements d'exécution sont impliqués.
Bien que les passerelles LLM sur site assurent le contrôle et la conformité, elles présentent également des défis opérationnels auxquels les entreprises doivent se préparer.
La gestion des charges de travail d'inférence assistées par GPU sur site nécessite une planification minutieuse des capacités. Sans automatisation, les modèles de dimensionnement ou la gestion des pics de trafic peuvent devenir lourds sur le plan opérationnel.
Les environnements sur site ont une capacité de calcul limitée. Un mauvais routage ou un manque de contrôle des requêtes peuvent entraîner des problèmes de latence ou une sous-utilisation des GPU. La gestion centralisée du trafic est essentielle pour trouver un équilibre entre performances et efficacité.
Au fur et à mesure que plusieurs équipes adoptent des LLM, les règles de gouvernance peuvent facilement évoluer si elles sont appliquées au niveau de l'application. Il est difficile de maintenir des contrôles d'accès et des politiques d'utilisation cohérents dans tous les environnements sans passerelle centralisée.
Les entreprises doivent conserver des enregistrements clairs de l'utilisation de LLM sans surcharger le stockage ni affecter les performances. Trouver le juste équilibre entre observabilité et frais généraux est un défi courant.
Les entreprises qui réussissent leurs déploiements LLM sur site considèrent la passerelle comme infrastructure de base, et pas simplement un proxy d'API.
Toutes les applications et tous les agents doivent accéder aux modèles exclusivement via la passerelle. Cela élimine les intégrations parallèles et garantit une sécurité et une gouvernance uniformes.
Les applications ne doivent jamais dépendre de points de terminaison spécifiques du modèle. L'abstraction des modèles derrière la passerelle permet aux équipes d'échanger, de mettre à niveau ou d'affiner les modèles sans modifier le code.
Les contrôles d'accès, les limites de débit et les règles d'utilisation doivent se trouver au niveau de la couche passerelle, et non dans la logique de l'application. Cela permet d'éviter toute dérive des politiques entre les équipes et les environnements.
Le développement, le staging et la production doivent être isolés au niveau de l'infrastructure et des politiques. Cela réduit les risques et sécurise les expériences.
Capturez suffisamment de données télémétriques à des fins d'auditabilité et d'optimisation, tout en masquant ou en limitant les données sensibles rapides si nécessaire. L'observabilité doit permettre le contrôle et non introduire de nouveaux risques.
Le respect de ces pratiques garantit que les passerelles LLM sur site restent sécurisé, évolutif et gérable à mesure que l'adoption augmente.
Alors que les entreprises vont au-delà de l'expérimentation et intègrent de grands modèles linguistiques dans leurs systèmes de base, le contrôle devient aussi important que la capacité. Les déploiements sur site répondent aux besoins de résidence, de sécurité et de conformité des données, mais sans couche d'accès centralisée, ils deviennent rapidement fragmentés et difficiles à gérer.
Un Infrastructure sur site LLM Gateway fournit ce plan de contrôle manquant. Il normalise la façon dont les applications interagissent avec les modèles, applique des politiques cohérentes et fournit la visibilité requise pour exploiter les LLM de manière responsable à grande échelle.
Choisir le meilleure passerelle LLM pour les déploiements sur site, il faut trouver un équilibre entre gouvernance, performances et simplicité opérationnelle plutôt que de se concentrer uniquement sur le routage des demandes.
Plutôt que de traiter les modèles auto-hébergés comme des services isolés, les entreprises qui adoptent une approche axée sur les passerelles transforment les LLM en infrastructures d'entreprise gérées, sécurisées, observables et prêtes pour une croissance à long terme.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


