

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: May 29, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Les grands modèles linguistiques ont franchi un seuil important. Ce qui n'était au départ que des expériences isolées et des projets pilotes a aujourd'hui évolué vers des charges de travail de production intégrées aux systèmes de l'entreprise. Le support client, la recherche de connaissances internes, le développement de logiciels, les analyses et les agents autonomes s'appuient de plus en plus sur les LLM comme éléments de base plutôt que sur des améliorations facultatives.
Ce changement a mis en lumière une nouvelle catégorie de défis en matière d'infrastructure. Les charges de travail LLM se comportent de manière très différente des services applicatifs traditionnels. Les coûts évoluent en fonction des jetons plutôt que des demandes, la latence varie considérablement selon les fournisseurs et les régions, et les modes de défaillance (délais d'attente, hallucinations ou réponses partielles) sont souvent opaques. Au fur et à mesure que les organisations adoptent de multiples modèles provenant de différents fournisseurs, ces problèmes s'aggravent rapidement.
Pour la plupart des entreprises, les premières intégrations LLM ont été conçues avec des appels d'API directs et une logique au niveau de l'application. Cette approche n'est pas valable à grande échelle. Les équipes sont rapidement confrontées à des coûts d'inférence imprévisibles, à une visibilité limitée sur l'utilisation, à une dépendance vis-à-vis des fournisseurs et à des problèmes de gouvernance croissants. L'optimisation des charges de travail LLM devient de plus en plus difficile lorsque chaque application met en œuvre son propre routage, ses nouvelles tentatives, ses contrôles des coûts et sa propre journalisation.
Alors que l'adoption de l'IA se développe horizontalement dans les équipes et verticalement dans tous les environnements, L'optimisation de la charge de travail LLM passe d'un problème d'application à un problème d'infrastructure. Les entreprises ont besoin d'une couche centralisée capable d'observer, de contrôler et d'optimiser la manière dont les modèles sont utilisés de manière cohérente et à grande échelle. Ce besoin a entraîné l'émergence de passerelles d'IA en tant que composant fondamental de l'infrastructure d'IA moderne.
L'optimisation des charges de travail LLM est fondamentalement différente de l'optimisation du calcul traditionnel ou des microservices. Les défis sont systémiques et non localisés.
Tout d'abord, la dynamique des coûts n'est pas linéaire. Une petite modification de la structure des invites, de la logique des nouvelles tentatives ou de la taille du contexte peut augmenter considérablement la consommation de jetons et les dépenses. Sans visibilité centralisée et structurée Solution de suivi des coûts LLM, ces changements passent souvent inaperçus jusqu'à ce que les coûts augmentent. Les contrôles au niveau des applications ne disposent pas du contexte global requis pour appliquer les budgets ou comparer l'efficacité entre les équipes et les cas d'utilisation.
Deuxièmement, la variabilité des performances est inhérente. Cela devient encore plus visible pendant Inférence LLM, où la latence et le débit diffèrent selon les modèles, les fournisseurs et les régions, et fluctuent en fonction de la charge et de la disponibilité. Le codage en dur d'un fournisseur ou d'un modèle unique dans une application crée de la fragilité. En cas de panne ou de limite de débit, les équipes sont obligées de recourir à des solutions réactives au lieu de procéder à une optimisation proactive.
Troisièmement, l'adoption de modèles multiples entraîne une complexité opérationnelle. Les entreprises utilisent de plus en plus une combinaison de modèles haut de gamme pour les flux de travail critiques et de modèles à moindre coût pour les tâches à volume élevé ou non critiques. La gestion efficace de cette combinaison nécessite des décisions de routage qui équilibrent les coûts, la qualité et la latence, des décisions qui ne devraient pas être intégrées au code de l'application.
Enfin, gouvernance et les pressions en matière de conformité continuent d'augmenter. Les organisations doivent appliquer des contrôles d'accès, surveiller l'utilisation, tenir à jour des journaux d'audit et garantir la résidence des données dans toutes les régions. Ces exigences concernent toutes les charges de travail liées à l'IA et ne peuvent pas être satisfaites efficacement au cas par cas.
Ensemble, ces facteurs montrent clairement que l'optimisation de la charge de travail LLM ne peut pas être résolue au coup par coup. Cela nécessite une couche de contrôle centralisée offrant une visibilité sur l'ensemble du trafic d'IA et habilitée à appliquer les politiques de manière cohérente.
Les passerelles IA répondent à ce défi en agissant en tant que plan de contrôle pour les charges de travail LLM. Positionnée entre les applications et les fournisseurs de modèles, une passerelle IA centralise la façon dont les requêtes LLM sont acheminées, observées, régies et optimisées.
Contrairement aux passerelles API traditionnelles, les passerelles IA sont spécialement conçues pour les caractéristiques des charges de travail LLM. Ils comprennent le comportement spécifique au modèle, la tarification basée sur les jetons, les compromis en matière de latence et la nécessité d'une observabilité affinée. Cela permet de mettre en œuvre des stratégies d'optimisation une seule fois au niveau de la couche d'infrastructure et de les appliquer de manière uniforme à toutes les applications.
À un niveau élevé, les passerelles IA permettent d'optimiser la charge de travail LLM en :
Cette approche architecturale dissocie la logique des applications de la gestion des modèles. Les développeurs se concentrent sur la création de fonctionnalités basées sur l'IA, tandis que les équipes chargées de la plateforme gardent le contrôle des performances, des coûts et des risques.
À mesure que les entreprises intensifient leur utilisation des LLM, cette séparation devient essentielle. Sans elle, les efforts d'optimisation sont fragmentés, réactifs et difficiles à maintenir. Grâce à elle, les entreprises disposent d'un moyen cohérent, mesurable et reproductible d'exécuter efficacement les charges de travail LLM, quel que soit le nombre de modèles, d'équipes ou d'applications impliqués.
À mesure que les organisations développent leur utilisation des LLM, les stratégies d'optimisation deviennent de plus en plus systématiques et axées sur l'infrastructure. D'ici 2026, plusieurs modèles deviendront une pratique courante dans les entreprises qui gèrent des charges de travail LLM à grande échelle.
Plutôt que de considérer la sélection des modèles comme un choix fixe, les entreprises adoptent orchestration axée sur les coûts. Dans ce modèle, les passerelles IA équilibrent dynamiquement les coûts, la qualité et la latence en fonction du contexte de chaque demande.
Par exemple :
Cette approche permet aux entreprises d'optimiser leurs dépenses sans compromettre l'expérience utilisateur. Au fil du temps, cela crée également une boucle de rétroaction dans laquelle les données d'utilisation réelles permettent de prendre de meilleures décisions d'orchestration.
Les exigences réglementaires et les réalités géopolitiques redéfinissent la manière dont les systèmes d'IA sont déployés. Les entreprises sont de plus en plus actives piles d'IA géopartitionnées, où les charges de travail LLM sont isolées par région pour répondre aux exigences de résidence, de souveraineté et de conformité des données.
Dans la pratique, cela signifie que :
Les passerelles d'IA jouent un rôle central dans l'application de ces contraintes tout en fournissant un modèle opérationnel unifié dans toutes les régions.
À mesure que l'utilisation du LLM augmente, les entreprises cessent d'envoyer à plusieurs reprises des contextes volumineux aux modèles. Au lieu de cela, ils adoptent systèmes d'IA pilotés par des outils, où les modèles récupèrent des informations à la demande via des interfaces contrôlées.
Ce changement :
Les passerelles d'IA assurent de plus en plus la médiation non seulement des appels de modèles, mais également de l'exécution d'outils et d'API, garantissant ainsi que les systèmes d'IA interagissent avec les données de l'entreprise de manière contrôlée et auditable.
L'essor des agents autonomes et semi-autonomes pose de nouveaux défis d'optimisation. Les agents effectuent souvent plusieurs appels de modèles, invoquent des outils et exécutent des flux de travail de longue durée.
Les principales organisations étendent leurs stratégies d'optimisation à la couche agent en :
Les passerelles d'IA évoluent pour accompagner ce changement, en agissant comme une couche de médiation à la fois pour l'inférence de modèles et pour l'exécution des agents.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

Le choix d'une passerelle IA n'est pas une décision d'outillage, c'est une engagement en matière d'infrastructure. Pour la plupart des entreprises, cette couche se trouve au cœur de chaque application alimentée par la technologie LLM, ce qui rend ses choix de conception difficiles à inverser ultérieurement. Par conséquent, l'évaluation devrait se concentrer moins sur les caractéristiques de surface et davantage sur l'ajustement architectural, la maturité opérationnelle et la flexibilité à long terme.
Vous trouverez ci-dessous un cadre pratique que les responsables techniques peuvent utiliser pour évaluer les passerelles d'IA, en particulier dans l'optique de l'optimisation de la charge de travail LLM.
Une passerelle d'IA de premier plan devrait permettre une véritable utilisation multimodèle sans obliger les applications à changer lorsque les modèles ou les fournisseurs changent.
Principales questions à se poser :
Si le choix du modèle s'immisce dans la logique de l'application, l'optimisation sera lente et fragile.
L'optimisation du LLM est impossible sans visibilité des coûts. Les passerelles devraient fournir des informations et des mesures d'application au niveau où les décisions sont prises.
Recherchez :
Une passerelle qui ne rapporte que l'utilisation globale est insuffisante pour une véritable optimisation.
Étant donné que la passerelle se trouve sur le chemin chaud, les caractéristiques de performance sont importantes.
Evaluer :
Même une petite baisse de performance peut s'aggraver à grande échelle.
L'optimisation dépend des boucles de rétroaction. La passerelle doit servir de système d'enregistrement de l'activité LLM.
Déterminez si la passerelle fournit :
Si l'observabilité semble renforcée, l'optimisation sera réactive plutôt que systématique.
L'optimisation doit coexister avec les contrôles des risques de l'entreprise.
Les principales considérations sont les suivantes :
Une passerelle qui nécessite des compromis entre optimisation et conformité ne pourra pas évoluer dans les environnements réglementés.
Enfin, évaluez comment la passerelle s'intègre à votre infrastructure et à votre modèle d'exploitation existants.
Envisagez :
Plus la passerelle s'intègre étroitement à votre pile de plateformes, plus elle sera facile à exploiter sur le long terme.
TrueFoundry l'architecture repose sur une prémisse claire : Optimisation de la charge de travail LLM est un problème d'infrastructure, pas une responsabilité d'application. Par conséquent, sa passerelle AI est conçue comme un plan de contrôle de première classe qui se trouve au centre de la pile d'IA de l'entreprise.
Dans un déploiement TrueFoundry, les applications et les agents n'interagissent jamais directement avec les fournisseurs de modèles. Au lieu de cela, tout le trafic LLM passe par Passerelle IA, qui agit comme une interface unique et stable pour l'inférence, le routage, l'observabilité et la gouvernance.
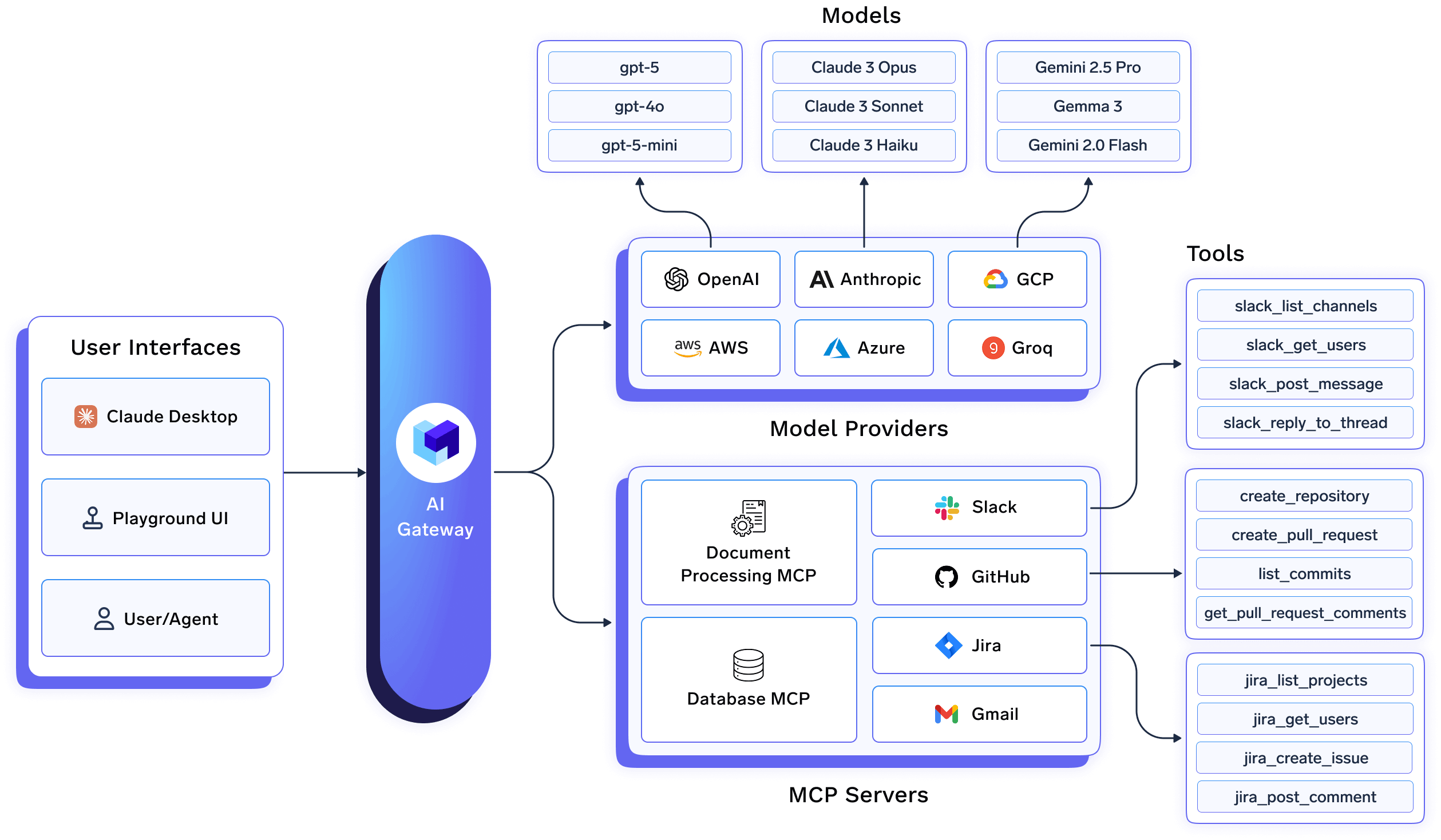
Sur le plan architectural, cela signifie :
Cette conception élimine les problèmes spécifiques au modèle du code de l'application et permet aux stratégies d'optimisation d'évoluer de manière indépendante.
La passerelle IA de TrueFoundry permet un véritable fonctionnement multimodèle en regroupant les API spécifiques aux fournisseurs dans un seul contrat. Les décisions de routage, telles que le modèle à utiliser, le moment de recourir ou la manière d'équilibrer les coûts par rapport à la latence, sont gérées de manière centralisée au niveau de la passerelle.
Dans la pratique, cela permet aux équipes de la plateforme de :
Le routage étant géré au niveau de la passerelle, les modifications de prix, de performances ou de disponibilité des fournisseurs peuvent être traitées immédiatement, sans nécessiter de modifications au niveau de l'application.
L'un des principes fondamentaux de l'architecture de TrueFoundry est que l'AI Gateway fonctionne comme système d'enregistrement pour toutes les activités du LLM. Chaque demande passant par la passerelle est capturée avec des métadonnées détaillées, notamment la sélection du modèle, l'utilisation des jetons, la latence et le contexte de la demande.
Contrairement à de nombreuses plateformes qui centralisent ces données dans des systèmes gérés par les fournisseurs, la conception de TrueFoundry garantit que :
Cette approche évite le problème de la « boîte noire » et permet aux organisations de créer des boucles de feedback d'optimisation à long terme à l'aide de leurs propres données.
TrueFoundry Passerelle IA intègre des contrôles de coûts et de gouvernance directement dans le chemin des demandes. Plutôt que de s'appuyer sur des rapports de facturation en aval ou des outils externes, l'optimisation et la mise en œuvre se font en temps réel.
Les principales fonctionnalités architecturales sont les suivantes :
Ces contrôles étant centralisés, chaque application alimentée par LLM en hérite automatiquement. Cela permet d'étendre l'utilisation de l'IA à toutes les équipes sans dupliquer la logique de gouvernance.
La passerelle IA de TrueFoundry est conçue pour être déployée là où se trouvent déjà les données de l'entreprise. Il peut fonctionner dans des VPC privés, des environnements sur site ou des régions cloud contrôlées, permettant aux entreprises de répondre à des exigences réglementaires et de résidence des données strictes.
Sur le plan architectural, cela prend en charge :
Cette conception s'aligne sur les entreprises opérant dans plusieurs juridictions, où le mouvement des données doit être étroitement contrôlé.
L'architecture centrée sur les passerelles de TrueFoundry s'inscrit également dans la transition vers des systèmes d'IA basés sur des agents. Alors que les agents orchestrent de plus en plus des flux de travail en plusieurs étapes et invoquent des outils ou des API, la passerelle devient le point d'application naturel.
Dans le cadre de ce modèle, l'AI Gateway peut :
Cela positionne la passerelle non seulement comme une couche d'inférence, mais comme un plan de contrôle d'exécution plus large pour les systèmes intelligents.
La caractéristique déterminante de l'approche de TrueFoundry est que l'optimisation, la gouvernance et l'observabilité sont mises en œuvre une seule fois au niveau de l'infrastructure et réutilisées partout. Cela réduit la complexité opérationnelle, améliore la cohérence et permet aux entreprises de faire évoluer les charges de travail LLM sans perdre le contrôle.
L'essentiel à retenir est que la passerelle IA de TrueFoundry n'est pas positionnée comme un module complémentaire, mais comme infrastructure d'IA de base. En considérant la passerelle comme une couche architecturale durable, TrueFoundry s'aligne sur la façon dont les entreprises envisagent déjà les systèmes critiques tels que les passerelles API, les plateformes de données et l'orchestration informatique.
À mesure que l'adoption de la technologie LLM évolue, l'optimisation n'est plus une question de réglage rapide ou de sélection de modèle, mais décision en matière d'infrastructure. La volatilité des coûts, la variabilité des performances et les exigences de gouvernance exigent une couche de contrôle centralisée capable de fonctionner entre les modèles, les équipes et les applications.
Les passerelles d'IA sont apparues comme cette couche. En consolidant le routage, l'observabilité, le contrôle des coûts et l'application des politiques, ils font de l'optimisation LLM une capacité systématique plutôt qu'une charge opérationnelle continue.
Des plateformes comme True Foundry reflètent cette évolution en traitant l'AI Gateway comme un élément essentiel de l'infrastructure d'IA des entreprises. Pour les responsables techniques, le message est clair : la durabilité de l'échelle LLM dépend moins du choix du bon modèle que de la mise en place des bonnes bases pour les gérer.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


