Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.
9,9
Comment envisager l'architecture AI Gateway dans la stack d'IA générative
Dans les systèmes d'IA générative modernes, le Passerelle IA fonctionne comme couche proxy critique entre les applications et les fournisseurs de modèles linguistiques (LLM). Il joue un rôle central dans la gestion de la fiabilité, de l'observabilité, du contrôle d'accès et de la rentabilité pour chaque demande entrant en production.
Parce que la porte d'entrée se trouve sur le chemin critique du trafic de production, il doit être conçu en tenant compte des principes fondamentaux suivants :
Principales priorités architecturales :
Haute disponibilité : La passerelle ne doit pas devenir un point de défaillance unique. Même en cas de problèmes de dépendance (tels que des pannes de base de données ou de files d'attente), il devrait continuer à gérer le trafic avec élégance.
Faible latence : Comme elle est intégrée à chaque demande d'inférence, la passerelle doit ajouter frais généraux minimaux pour garantir une expérience utilisateur agréable.
Débit et évolutivité élevés : Le système doit évoluer de manière linéaire en fonction de la charge et être capable de gérer des milliers de demandes simultanées avec une utilisation efficace des ressources.
Aucune dépendance externe dans le Hot Path : Toutes les opérations liées au réseau ou au disque doivent être déchargées vers des systèmes asynchrones afin d'éviter tout goulot d'étranglement des performances.
Prise de décision en mémoire : Les contrôles critiques tels que la limitation du débit, l'équilibrage de charge, l'authentification et l'autorisation doivent tous être effectués en mémoire pour une vitesse et une fiabilité maximales.
Séparation du plan de contrôle et du plan proxy : Les modifications de configuration et la gestion du système doivent être dissociées du routage du trafic réel, afin de permettre des déploiements mondiaux avec une isolation régionale des pannes.
Architecture de passerelle IA de TrueFoundry
TrueFoundry Passerelle IA intègre tous les principes de conception ci-dessus, spécialement conçus pour une faible latence, une fiabilité élevée et une évolutivité sans faille
Architecture de passerelle de TrueFoundry
Principales caractéristiques de l'architecture AI Gateway
Construit sur Hono Framework : La passerelle tire parti Hono, un framework minimaliste et ultrarapide optimisé pour les environnements périphériques. Cela garantit une charge d'exécution minimale et une gestion des demandes extrêmement rapide.
Aucun appel externe sur le chemin de la demande : Une fois qu'une demande atteint la passerelle, elle ne déclenche aucun appel externe (sauf si la mise en cache sémantique est activée). Toute la logique opérationnelle est gérée en interne, ce qui réduit les risques et renforce la fiabilité.
Application en mémoire : Toutes les décisions d'authentification, d'autorisation, de limitation de débit et d'équilibrage de charge sont prises à l'aide de configurations en mémoire, garantissant des temps de réponse inférieurs à la milliseconde.
Journalisation asynchrone : Les journaux et les métriques de demande sont envoyés vers une file de messages de manière asynchrone, ce qui garantit que l'observabilité des données ne bloque ni ne ralentit le chemin de la demande.
Comportement infaillible : Même si la file d'attente de journalisation externe est en panne, la passerelle ne pas échouer toutes les demandes. Cela garantit la disponibilité et la résilience en cas de défaillance partielle du système.
Évolutif horizontalement : La passerelle est liée au processeur et sans état, ce qui facilite son évolutivité. Il fonctionne efficacement dans des conditions de simultanéité élevée et de faible utilisation de la mémoire.
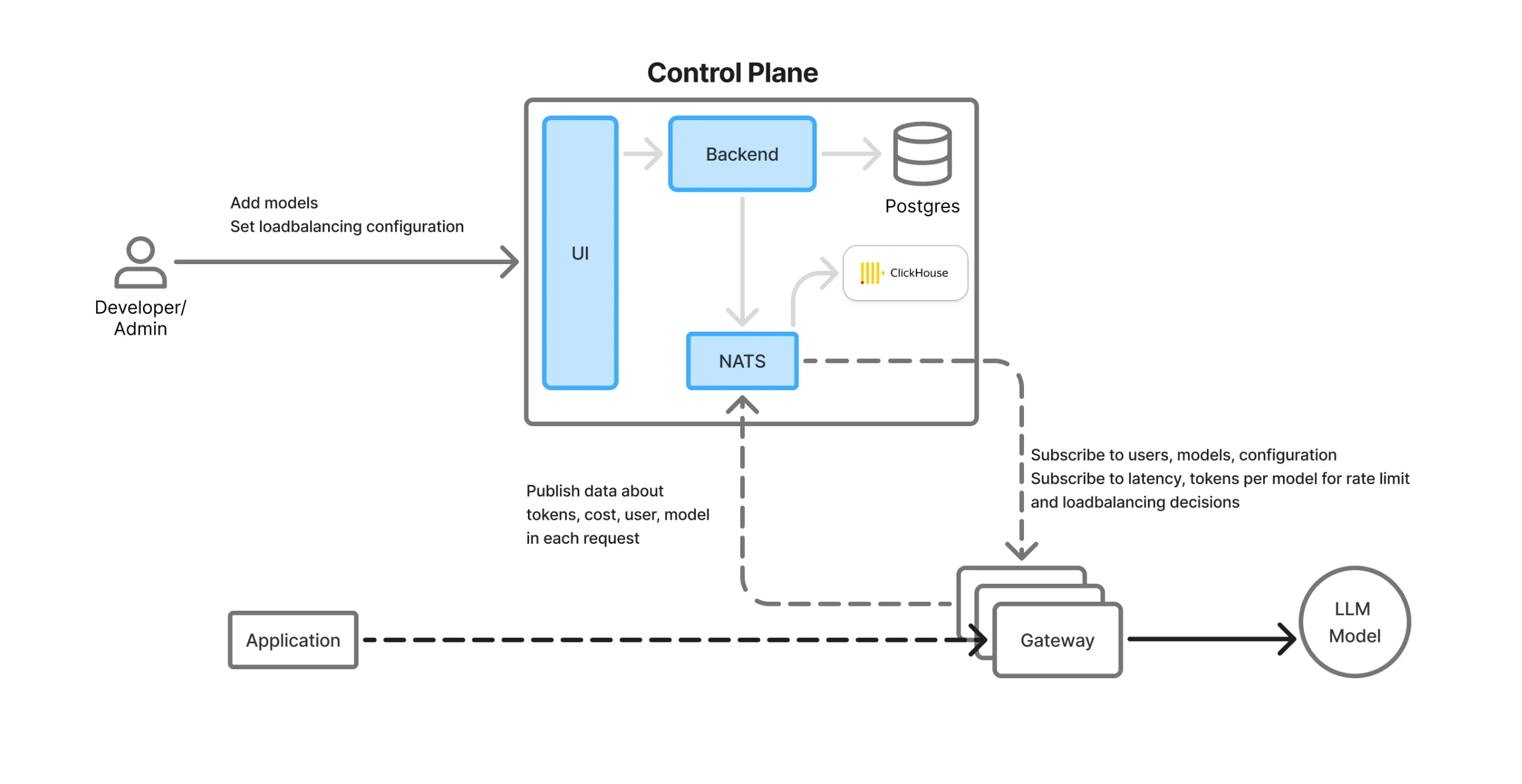
Plan de contrôle et flux de données
TrueFoundry sépare les plan de contrôle (gestion) depuis le plan de données (routage du trafic en temps réel) pour des raisons d'évolutivité et de flexibilité.
Présentation des composants de l'AI Gateway :
INTERFACE UTILISATEUR : Interface Web avec un terrain de jeu LLM, des tableaux de bord de surveillance et des panneaux de configuration pour les modèles, les équipes, les limites de débit, etc.
Base de données Postgres : Stocke les données de configuration persistantes (utilisateurs, équipes, clés, modèles, comptes virtuels, etc.)
Cliquez sur House : Base de données colonnaire haute performance utilisée pour stocker des journaux, des mesures et des analyses d'utilisation.
File d'attente NATS : Agit comme un bus de synchronisation en temps réel entre le plan de contrôle et les modules de passerelle distribués. Toutes les mises à jour de configuration/d'état sont transmises via NATS et disponibles instantanément dans toutes les régions.
Service principal : Orchestration de la synchronisation des configurations, des mises à jour des bases de données et de l'ingestion d'analyses.
Pods Gateway : Proxys légers, autonomes et intégrés à la région, qui gèrent le trafic LLM réel. Ils consomment des messages NATS et exécutent toute la logique en mémoire, sans aucune dépendance externe.
Key Metrics for Evaluating Gateway
Criteria
What should you evaluate ?
Priority
TrueFoundry
Latency
Adds <10ms p95 overhead for time-to-first-token?
Must Have
✅ Supported
Data Residency
Keeps logs within your region (EU/US)?
Depends on use case
✅ Supported
Latency-Based Routing
Automatically reroutes based on real-time latency/failures?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Evaluating an AI Gateway?
A practical guide used by platform & infra teams
Benchmarks de performance pour la passerelle IA de TrueFoundry
La passerelle de TrueFoundry a été minutieusement évaluée en termes de performances sous des charges similaires à celles de la production :
250 RPS sur 1 CPU/1 Go de RAM avec uniquement Latence supplémentaire de 3 ms.
Évolue efficacement jusqu'à 350 RPS par pod avant d'atteindre la saturation du processeur, au-delà de laquelle vous pouvez ajouter des répliques.
Supports des dizaines de milliers de RPS avec une mise à l'échelle horizontale entre les régions.
Aucune latence supplémentaire même si plusieurs règles de limite de débit, d'authentification et d'équilibrage de charge sont en place.
Pourquoi c'est important
Si vous exécutez des charges de travail GenAI à grande échelle ou si vous envisagez d'intégrer plusieurs LLM (OpenAI, Claude, open source, etc.), la passerelle devient la base de votre stack.
La conception de TrueFoundry garantit :
Tu peux acheminez et évoluez en toute sécurité tous fournisseurs confondus.
Postulez commandes précises au niveau de l'utilisateur/de l'équipe.
Maintenez l'observabilité et la gouvernance dans l'ensemble du système tout en contrôlant coût de l'IA générative.
Faites tout cela sans impact sur la latence ou la fiabilité.
Réservez une démo dès maintenant si vous souhaitez commencer à utiliser AI Gateway.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.
Conçu pour la vitesse : latence d'environ 10 ms, même en cas de charge

































.png)

.webp)
.webp)
.webp)



.webp)
.webp)


