Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.
9,9
Comment choisir une passerelle IA
Published: May 29, 2026
Conçu pour la vitesse : latence d'environ 10 ms, même en cas de charge
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Gère plus de 350 RPS sur un seul processeur virtuel, aucun réglage n'est nécessaire
Prêt pour la production avec un support complet pour les entreprises
Alors que les entreprises déploient de plus en plus d'applications basées sur la technologie LLM au sein de leurs équipes, une nouvelle couche d'infrastructure apparaît comme essentielle : Passerelle IA. Une passerelle d'IA se trouve entre vos applications et les services ou modèles d'IA sous-jacents, agissant comme un plan de contrôle central pour le trafic d'IA. Il fournit un accès unifié à des dizaines ou des centaines de modèles tout en appliquant les politiques de l'entreprise en matière de sécurité, de coût et d'observabilité. Cela est de plus en plus important à mesure que l'utilisation évolue : d'ici 2026, plus de 80 % des entreprises devraient utiliser l'IA générative, et Gartner prévoit que d'ici 2028, 70 % des équipes d'ingénierie qui créent des applications multimodèles s'appuieront sur des passerelles d'IA pour améliorer la fiabilité et contrôler les coûts. Sans passerelle, chaque appel client IA doit être géré individuellement, ce qui entraîne des dépenses non gérées en jetons, une journalisation fragmentée et des failles de sécurité. Dans cet environnement, une passerelle d'IA bien conçue devient nouvelle couche de contrôle pour l'IA d'entreprise, en fournissant la cohérence, la gouvernance et l'efficacité qui font défaut aux passerelles API traditionnelles.
Qu'est-ce qu'une passerelle IA et pourquoi c'est important
Un Passerelle IA est une couche intergicielle spécialisée qui gère le trafic entre les applications et les modèles d'IA. Contrairement aux passerelles API classiques, elle est conçue spécifiquement pour les charges de travail d'IA. Il gère Préoccupations spécifiques à l'IA tels que la limitation du débit au niveau des jetons, les réponses en streaming et les contrôles de sécurité rapides, auxquels les passerelles HTTP normales ne répondent pas. Dans la pratique, une application soumet d'abord chaque demande d'IA à la passerelle : la passerelle authentifie ensuite la demande, applique les filtres de contenu ou les garde-fous, l'achemine vers le modèle approprié et renvoie enfin la réponse (éventuellement avec son propre post-traitement) à l'application. Cette couche centralisée permet des fonctionnalités telles que l'orchestration des modèles (équilibrage ou basculement entre différents fournisseurs d'IA) et la facturation unifiée.
Gartner a identifié quatre tâches fondamentales qu'une passerelle d'IA doit fonctionner dans les entreprises modernes : routage, sécurité/garde-corps, contrôle des coûts, et observabilité.
Routage : Il oriente les demandes vers le modèle ou le fournisseur le plus approprié en fonction de politiques (par exemple, choisir entre des modèles plus rapides mais coûteux ou des modèles moins chers).
Sécurité : Il applique l'authentification, la gestion des clés et le filtrage du contenu à partir d'un point de contrôle unique. Cela inclut la prévention de problèmes tels que l'injection rapide ou la fuite de données sensibles en appliquant des barrières de sécurité centralisées sur les entrées et les sorties.
Contrôle des coûts : Il suit l'utilisation des jetons par demande et applique des budgets ou des quotas pour éviter les dépassements de coûts. Par exemple, il peut mettre en cache les demandes dupliquées pour enregistrer les jetons et réacheminer les demandes si un modèle dépasse le budget.
Observabilité : Il enregistre chaque appel d'IA et expose des métriques/traces afin que les équipes puissent surveiller les performances, les tendances d'utilisation et détecter les anomalies dans tous les modèles et applications.
En intégrant ces fonctions, une passerelle IA transforme le trafic IA en plan politique programmable — comme Kubernetes l'a fait pour les conteneurs. Cela permet de résoudre les principaux problèmes liés au passage des expériences d'IA à la production : sans passerelle, il est facile de perdre de la visibilité sur les dépenses liées aux jetons, d'appliquer des contrôles de sécurité incohérents et de disposer de données de performance fragmentées. Une passerelle garantit que chaque La demande d'IA est régie et mesurable. Comme le note un guide d'analyste, « sans cette couche, les entreprises ont du mal à contrôler les coûts, à maintenir la sécurité et à surveiller les performances à grande échelle ». En résumé, une passerelle d'IA permet de préparer l'utilisation de l'IA aux entreprises en ajoutant les contrôles et la télémétrie dont les grandes équipes ont besoin.
Quand une organisation a-t-elle besoin d'une passerelle IA ?
Tous les petits projets d'IA n'ont pas besoin d'une passerelle complète, mais dès que plusieurs équipes, modèles ou modèles d'utilisation apparaissent, une passerelle devient utile. Vous avez probablement besoin d'une passerelle IA dans les cas suivants :
Vous utilisez plusieurs fournisseurs ou modèles d'IA. Lorsque vos applications appellent plusieurs API LLM (par exemple, en combinant OpenAI, Azure ou des modèles personnalisés), une passerelle vous permet d'y accéder via une interface unique et cohérente. Cela empêche chaque équipe de réinventer la logique d'accès et garantit des politiques de sécurité uniformes.
L'utilisation est évolutive ou interéquipes. Si des dizaines de développeurs de différents départements intègrent des LLM, vous risquez une « IA fantôme », c'est-à-dire une utilisation incontrôlée sur différents comptes. Une passerelle IA unifie ce trafic et permet de savoir qui appelle quel modèle. Gartner prévoit que l'utilisation des passerelles augmentera de manière significative à mesure que les applications multimodèles se répandront.
Les coûts et les budgets sont importants. Chaque demande d'IA consomme des jetons qui coûtent de l'argent. Une seule invite peut utiliser des milliers de jetons. À mesure que l'utilisation augmente, il devient facile de dépasser le budget sans que personne ne s'en aperçoive. Une passerelle IA suit l'utilisation des jetons par demande et peut appliquer des budgets par équipe ou par projet, évitant ainsi des coûts exorbitants. Si l'équipe chargée des finances ou de la plateforme se plaint de dépenses imprévisibles liées à l'IA, il est temps de créer une passerelle.
La sécurité et la conformité sont requises. Pour les secteurs réglementés (finance, santé, etc.), vous avez besoin d'un audit central des interactions avec l'IA, de contrôles d'accès stricts et de contrôles de sécurité du contenu. C'est exactement ce que fournit une passerelle IA : par exemple, elle peut bloquer les informations personnelles dans les sorties ou appliquer la désinfection des entrées. Si vous avez besoin d'une conformité HIPAA/SOC2 ou si vous devez intégrer des systèmes SIEM, une passerelle dotée d'une sécurité de niveau professionnel est essentielle.
Vous avez des charges de travail multi-locataires ou agentiques. Si plusieurs unités commerciales ou clients utilisent la même infrastructure d'IA, vous devez isoler la charge de travail. Un véritable support multi-tenant (espaces de travail séparés, RBAC, clés API) s'accompagne d'une passerelle. De même, si vous déployez des agents IA (qui utilisent des protocoles tels que MCP/Model Context Protocol), une passerelle conçue pour les agents peut gérer ces appels d'outil/modèle de manière centralisée.
Key Metrics for Evaluating Gateway
Criteria
What should you evaluate ?
Priority
TrueFoundry
Latency
Adds <10ms p95 overhead for time-to-first-token?
Must Have
✅ Supported
Data Residency
Keeps logs within your region (EU/US)?
Depends on use case
✅ Supported
Latency-Based Routing
Automatically reroutes based on real-time latency/failures?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Evaluating an AI Gateway?
A practical guide used by platform & infra teams
Principales caractéristiques à rechercher dans une passerelle IA
Lorsque vous comparez des solutions de passerelle IA, concentrez-vous sur les fonctionnalités qui garantissent évolutivité, sécurité, observabilité, et rentabilité. Les fonctionnalités importantes incluent :
API multimodèle unifiée : La passerelle doit présenter un point de terminaison unique compatible avec OpenAI pour les modèles d'appels, même s'ils proviennent de fournisseurs différents. Cela signifie qu'il peut traduire vos demandes vers des fournisseurs tels que OpenAI, Azure OpenAI, Amazon Bedrock, Gemini, Groq, ou même des modèles auto-hébergés à l'aide d'une interface v1/chat/completions standard. Une couverture étendue des modèles est essentielle : vérifiez la prise en charge des principaux modèles prêts à l'emploi et découvrez un moyen simple d'intégrer des modèles nouveaux ou personnalisés. Idéalement, vous devriez pouvoir changer de modèle via des en-têtes ou des modifications de configuration sans toucher au code de votre application. Cette interface unifiée simplifie le développement et vous permet d'expérimenter différents modèles de manière fluide.
Hautes performances et évolutivité : Étant donné que la passerelle assure le proxy de chaque appel d'IA de production, elle doit être rapide et évolutive. Recherchez une latence minimale (de manière optimale, quelques millisecondes ajoutées par demande). La passerelle doit prendre en charge un RPS (requêtes par seconde) élevé, même avec des ressources modestes ; par exemple, une passerelle bien conçue peut gérer des centaines de RPS par cœur de processeur. La mise à l'échelle automatique et le déploiement multirégional sont également essentiels : la passerelle doit être en mesure de créer des pods ou des instances supplémentaires à la demande et de fonctionner dans toutes les zones/régions afin de réduire la latence pour les équipes mondiales. Sur le plan architectural, de nombreuses passerelles implémentent des contrôles de limite de débit et d'équilibrage de charge en mémoire (aucun appel externe dans le chemin de la demande) pour atteindre des latences inférieures à 50 ms. Confirmez les indications de référence du fournisseur (par exemple, X RPS par capsule) et testez sous la charge prévue.
Routage, équilibrage de charge et fiabilité : La passerelle doit distribuer le trafic de manière intelligente. Les principales fonctionnalités incluent l'équilibrage de charge pondéré ou basé sur la latence entre les réplicas/fournisseurs de modèles, les nouvelles tentatives automatiques et les solutions de repli des modèles en cas d'échec, ainsi que la mise en cache sémantique des invites. Fort Équilibrage de charge LLM les fonctionnalités garantissent une distribution intelligente du trafic entre les fournisseurs afin de maintenir les performances, de réduire les pics de latence et d'améliorer la fiabilité de la production. Vous devriez être en mesure de définir des limites de débit par utilisateur ou par équipe pour éviter les abus, et de définir des quotas ou des budgets (en jetons ou en dollars) par projet. La prise en charge de politiques de routage avancées (par exemple, l'envoi de trafic prioritaire vers des modèles premium ou le routage basé sur les délais d'attente des demandes) est un avantage. Dans l'ensemble, assurez-vous que la passerelle peut servir de proxy résilient afin qu'une panne ou un pic d'API en aval ne fasse pas planter votre application.
Observabilité robuste : Chaque demande via la passerelle doit générer des journaux et des mesures détaillés. Les fonctionnalités d'observabilité essentielles incluent le suivi des demandes avec des métadonnées riches (texte rapide, modèle utilisé, jetons d'entrée/sortie, identité de l'utilisateur, latence, etc.) et des tableaux de bord en temps réel ou historiques montrant les tendances d'utilisation et de performances. La passerelle doit présenter des hooks d'intégration pour votre stack de surveillance, par exemple, la compatibilité avec OpenTelemetry et l'exportation facile des logs/métriques vers Grafana, Prometheus, Datadog, etc. Questions clés : Pouvez-vous filtrer les logs/métriques par utilisateur, par équipe ou par modèle ? Pouvez-vous analyser les erreurs (4xx/5xx) ou les événements de repli ? Les véritables solutions d'entreprise vous permettent de découper les données de coûts et d'utilisation comme vous le souhaitez (par modèle, par service, etc.) afin d'allouer les budgets avec précision. La liste de contrôle de l'évaluation suggère de vérifier que indicateurs de coûts et indicateurs de performance (comme le délai jusqu'au premier jeton) sont disponibles à des niveaux granulaires.
Sécurité, garde-corps et gouvernance des accès : La sécurité doit être intégrée. Recherchez la prise en charge intégrée du filtrage des messages et du contenu (listes de mots clés, règles d'expression régulière, politiques contextuelles) afin d'empêcher les sorties dangereuses ou indésirables. La passerelle doit pouvoir s'intégrer à des filtres de contenu externes ou à des outils TriSM (par exemple, AWS Content Moderation, fournisseurs de garde-corps IA). Toutes les demandes d'API doivent être enregistrées avec des pistes d'audit complètes, et vous devez être en mesure d'attribuer des autorisations précises : par exemple, en limitant les équipes ou les utilisateurs qui peuvent appeler quels modèles. Le contrôle d'accès basé sur les rôles (RBAC) est indispensable : assurez-vous que la passerelle prend en charge l'intégration avec votre SSO/IdP (SAML, OIDC, etc.) et que les rôles et les politiques peuvent être synchronisés à partir de celle-ci. Vérifiez le chiffrement des données au repos/en transit et les certifications de conformité (telles que SOC2, GDPR, HIPAA si vous en avez besoin) sur la solution SaaS ou sur site du fournisseur.
Gestion des coûts : Outre le suivi des jetons bruts, des contrôles avancés des coûts sont essentiels. La passerelle doit tenir à jour des tableaux de prix (ou autoriser une tarification personnalisée) pour les principaux fournisseurs afin de pouvoir calculer le coût en dollars de chaque demande. Il doit appliquer les politiques de dépenses, par exemple en envoyant des alertes ou en bloquant les demandes lorsqu'une équipe atteint 80 % de son budget. Certaines passerelles vous permettent de prédéfinir des tarifs personnalisés pour les forfaits d'entreprise ou les modèles auto-hébergés, et de les appliquer au calcul des coûts. La mise en cache sémantique des réponses (par exemple via des intégrations) peut également réduire considérablement l'utilisation. C'est donc un avantage pour réaliser des économies. En fin de compte, recherchez la capacité de générer rapports de coûts par utilisateur ou par projet et pour voir les dépenses en jetons en temps réel.
Expérience et intégrations pour les développeurs : Une bonne passerelle est facile à utiliser pour les développeurs. Il doit être compatible avec les frameworks et les agents d'IA courants, par exemple, prendre en charge LangChain, LLamaIndex ou les outils no-code populaires (n8n, Flowise) via son API. Vérifiez s'il propose un terrain de jeu unifié ou un outil de gestion des versions pour gérer les invites de manière centralisée. La prise en charge multimodale (gestion du texte, des images, du son et des intégrations) via la même interface est utile si vos cas d'utilisation ne se limitent pas au chat. Enfin, la passerelle doit fournir une API REST ou des SDK clairs pour la gestion : par exemple, créer des clés d'API, configurer des modèles, définir des budgets, etc. La passerelle TrueFoundry, par exemple, offre un terrain de jeu rapide, une gestion des clés d'API et fonctionne prête à l'emploi avec tous les principaux frameworks LLM.
Flexibilité de déploiement : En fonction de votre niveau de sécurité, vous pourriez avoir besoin de la passerelle en tant que solution SaaS ou auto-hébergée. Vérifiez si la passerelle peut fonctionner dans votre cloud ou sur site (TrueFoundry prend en charge les deux) et de quelle infrastructure elle a besoin (Kubernetes, etc.). Réfléchissez à la façon dont la configuration est gérée : recherchez le support Terraform/Helm et l'intégration GitOps si vous utilisez ces pratiques. Vérifiez également les capacités de déploiement périphérique ou régional afin de minimiser la latence pour les équipes internationales. Par exemple, le SaaS de TrueFoundry est distribué dans le monde entier et sa passerelle sur site peut être placée dans n'importe quelle région cloud, ce qui permet de maintenir les temps de réponse en dessous de 5 ms en pratique.
En résumé, votre évaluation devrait couvrir routage/orchestration, performance, observabilité, sécurité, contrôle des coûts, et déploiement. Comme étape pratique, utilisez une liste de contrôle structurée pour évaluer chaque passerelle en fonction de ces dimensions.
L'approche de TrueFoundry en matière de conception de passerelles d'IA
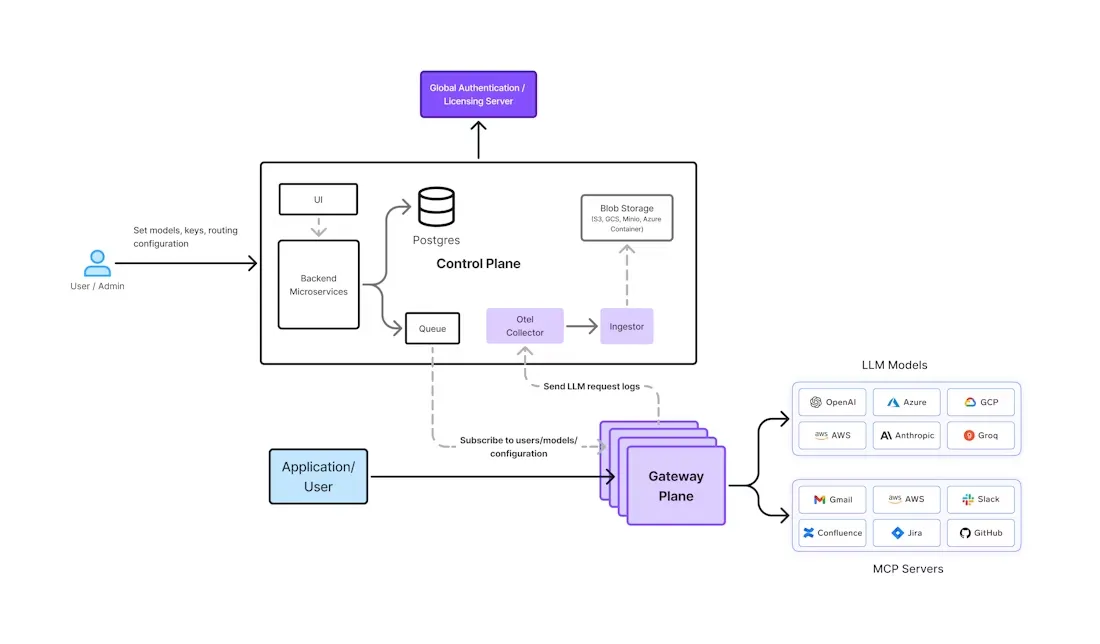
La passerelle IA de TrueFoundry a été conçue à partir de zéro en tenant compte de ces exigences d'entreprise. Il fournit une interface unifiée avec plus de 1000 LLM (OpenAI, Anthropic, Gemini, Bedrock, modèles open source, etc.) tout en intégrant la sécurité, l'observabilité et la gouvernance au cœur de ses activités. L'architecture sépare les fonctions du plan de contrôle (interface utilisateur, base de données de politiques, etc.) des pods de passerelle sans état qui gèrent le trafic d'inférence (voir la figure ci-dessous).
Figure 1 : Architecture de la passerelle IA de TrueFoundry. Un plan de contrôle central (à gauche) transmet la configuration aux modules de passerelle distribués dans le monde entier (à droite). Toutes les vérifications de politique (authentification, limites de débit, routage) sont effectuées en mémoire sur chaque pod.
TrueFoundry les pods de passerelle s'abonnent à un flux de messages NATS depuis le plan de contrôle. Les modifications de politique (telles que les nouvelles autorisations des utilisateurs, les configurations de modèles ou les règles d'équilibrage) sont publiées dans NATS et immédiatement disponibles pour chaque pod. Lorsqu'une demande arrive sur un module de passerelle, toutes les vérifications critiques sont effectuées en mémoire sans sauts réseau supplémentaires — cela inclut l'authentification JWT, les contrôles RBAC, l'application des limites de débit et les décisions d'équilibrage de charge des modèles. Par conséquent, les tests de TrueFoundry indiquent des surcharges de latence de l'ordre de quelques millisecondes par requête. Même dans le cadre d'un traçage complet (enregistrement de chaque invite et du nombre de jetons), le matériel moderne gère des centaines de requêtes par seconde et par module, et le système évolue de manière linéaire en ajoutant de nouveaux modules.
Dans les coulisses, les demandes approuvées sont acheminées vers le fournisseur d'IA ou le point de terminaison du modèle choisi. Si une réponse est positive, elle est immédiatement renvoyée au client. Simultanément, les métadonnées de la demande et de la réponse (jetons utilisés, latence, utilisateur, modèle) sont publiées de manière asynchrone dans la file de messages. Un service d'analyse backend ingère ces événements dans ClickHouse (via le stockage blob) pour calculer les mesures d'utilisation et de coûts. Ce pipeline asynchrone signifie que la journalisation et les analyses ne bloquent jamais le chemin du trafic réel. Les clients du tableau de bord et de l'API peuvent ensuite interroger la télémétrie agrégée (via les normes OpenTelemetry) pour suivre l'utilisation par modèle, équipe ou période.
La sécurité est appliquée partout. La passerelle de TrueFoundry utilise des données à grain finRBAC afin que les équipes ne voient et n'invoquent que les modèles qu'elles sont autorisées à utiliser. Toutes les clés et jetons d'API peuvent être gérés de manière centralisée et détaillée journaux d'audit capturez chaque action (horodatage, ID utilisateur, modèle utilisé, etc.). Contenu personnalisé garde-corps peuvent être définies dans le portail (par exemple, des filtres de mots clés ou des règles contextuelles), et la passerelle bloquera ou signalera toutes les réponses qui enfreignent la politique. TrueFoundry s'intègre également aux fournisseurs d'identité d'entreprise, ce qui vous permet de synchroniser les rôles depuis votre IdP (SSO via SAML/OIDC) et de les appliquer automatiquement aux autorisations de passerelle.
Les autres fonctionnalités incluent la prise en charge multimodale (la même API gère le texte, les images, le son et les intégrations de manière fluide) et un système de gestion des invites intégré. La passerelle propose un Terrain de jeu rapidepour gérer les versions et tester les invites de manière centralisée, ce qui est particulièrement utile pour les équipes qui itèrent en fonction des invites de production. Il fournit également des contrôles globaux du budget et des limites de taux : par exemple, vous pouvez définir un quota mensuel en dollars par équipe ou appliquer des budgets basés sur des jetons par projet. Dans la pratique, les organisations utilisant la passerelle de TrueFoundry bénéficient d'une visibilité immédiate sur les dépenses liées aux jetons (même ventilées par fournisseur et modèle) et peuvent automatiquement arrêter ou avertir les utilisateurs en cas de dépassement de budget.
La flexibilité du déploiement est l'une des caractéristiques de la conception de TrueFoundry. L'AI Gateway peut fonctionner en tant que SaaS géré (avec des nœuds dans plusieurs régions cloud pour une faible latence et une haute disponibilité) ou être installée dans votre propre environnement cloud/sur site. Dans les deux cas, l'impact sur les performances est minime : une récente FAQ indique que le SaaS de TrueFoundry ajoute moins de 5 ms de surcharge par requête. Comme il peut être déployé dans n'importe quel cluster Kubernetes (ou même en périphérie), vous pouvez placer des modules de passerelle à proximité de vos applications ou de vos sources de données afin de réduire encore le temps d'aller-retour. TrueFoundry prend également en charge un fonctionnement sécurisé sur site : les seules données envoyées au serveur de licences cloud sont des mesures d'utilisation anonymisées, et le déploiement complet du plan de contrôle peut rester derrière votre pare-feu si nécessaire.
Choisir la passerelle adaptée à votre cas d'utilisation
Aucune passerelle d'IA n'est parfaite pour tous les scénarios, alors alignez votre choix sur vos priorités :
Cas d'utilisation sensibles aux coûts : Si un contrôle budgétaire strict est essentiel, donnez la priorité aux passerelles avec politiques de dépenses intégrées. Assurez-vous qu'il peut appliquer une tarification personnalisée (reflétant par exemple les remises accordées à votre entreprise) et déclencher des alertes aux seuils budgétaires. TrueFoundry, par exemple, vous permet de précharger les tarifs des fournisseurs publics et de définir des tarifs personnalisés pour vos contrats ou modèles auto-hébergés, avec des notifications automatisées à l'approche des seuils.
Exigences de haute sécurité/conformité : Dans les secteurs réglementés, recherchez des fonctionnalités telles que l'auditabilité complète (journaux inviolables), le RBAC granulaire et la gestion des clés de chiffrement. La passerelle de TrueFoundry prend en charge les flux de travail SOC2 et HIPAA prêts à l'emploi (via des options sur site et un stockage sécurisé des clés) et peut s'intégrer aux outils SIEM. Des fonctionnalités telles que la détection des informations personnelles et la rédaction des données peuvent être déterminantes si vous gérez des données sensibles.
Débit extrêmement élevé/faible latence : Pour les applications en temps réel (par exemple, les chatbots clients ou les systèmes de trading), les performances de la passerelle sont primordiales. Consultez les benchmarks du fournisseur ou lancez un projet pilote : l'architecture de TrueFoundry peut servir plus de 250 RPS par pod avec une latence supplémentaire minimale, et peut facilement être étendue à plusieurs milliers avec davantage de répliques. Si vous avez besoin d'une latence extrêmement faible, il est important de déployer des pods de passerelle dans la même région (ou même dans des zones périphériques) que vos utilisateurs. L'option SaaS multirégionale ou sur site de TrueFoundry le permet.
Environnements multicloud ou hybrides : Si vous utilisez plusieurs fournisseurs de cloud ou si vous avez des exigences strictes en matière de résidence des données, choisissez une passerelle capable de les utiliser. TrueFoundry prend en charge le déploiement sur n'importe quelle infrastructure cloud ou sur site et peut synchroniser les politiques à l'échelle mondiale. Cela signifie qu'un seul plan de contrôle peut gérer les passerelles déployées dans différentes régions ou différents clouds.
Applications multimodales ou agentiques : Si votre cas d'utilisation implique des agents (outils, actions) via les protocoles MCP/A2A, ou si vous avez besoin d'une prise en charge fluide des images et du son, vérifiez que la passerelle dispose de ces fonctionnalités. TrueFoundry étend activement sa passerelle pour virtualiser les serveurs MCP et unifier les outils d'IA au sein d'une seule API. Aujourd'hui déjà, il propose des « serveurs MCP virtuels » où vous pouvez combiner des outils et des modèles provenant de plusieurs agents en une seule interface (bientôt disponible dans GA). Pour le multimodal, TrueFoundry prend en charge le texte, l'image, le son et les modèles d'intégration de manière uniforme.
Adaptation du développeur à l'écosystème : Réfléchissez à ce que vos équipes de développement utilisent. S'ils s'appuient sur les frameworks LangChain ou LLM, choisissez une passerelle connue pour fonctionner avec eux prête à l'emploi. La facilité d'intégration (documentation d'API, SDK clients) est importante pour l'adoption. TrueFoundry fournit des API ouvertes et des bibliothèques clientes dans plusieurs langues, et son API unifiée signifie que le code basé sur OpenAI existant fonctionne souvent sans changement. Vérifiez également si la passerelle s'intègre au CI/CD ou aux outils d'infrastructure que vous utilisez (par exemple, la prise en charge de Terraform dans TrueFoundry).
Dans tous les cas, associez ces exigences à votre liste de contrôle d'évaluation. Attribuez des poids aux critères en fonction de ce qui est le plus important pour votre projet (sécurité, coût, fonctionnalités). Le cadre d'évaluation de TrueFoundry peut être personnalisé (il est disponible sous forme de fichier CSV public) afin que vous puissiez évaluer les fournisseurs côte à côte en fonction des fonctionnalités exactes dont vous avez besoin. L'objectif est de choisir la passerelle qui répond non seulement aux besoins actuels, mais qui peut également évoluer avec vos initiatives en matière d'IA.
Conclusion
À mesure que l'adoption de l'IA augmente, une passerelle spécialement conçue devient rapidement une couche de contrôle incontournable. Cela met de l'ordre dans ce qui serait autrement un mélange chaotique d'API, de coûts et de risques de sécurité. En gérant le routage, l'observabilité, la budgétisation et la conformité en un seul endroit, une passerelle d'IA transforme l'infrastructure d'IA en une plateforme fiable et gouvernée. Passerelle IA de TrueFoundry repose sur ces principes : il offre une interface unifiée à des centaines de modèles avec des contrôles de sécurité, de surveillance et de politiques de niveau professionnel.
Lorsque vous choisissez une passerelle, utilisez une approche structurée : comprenez vos charges de travail, consultez la liste de contrôle d'évaluation et comparez les performances, l'observabilité, le contrôle des coûts et les fonctionnalités de gouvernance de chaque option en termes de flexibilité du routage, de performances, d'observabilité, de contrôle des coûts et de fonctionnalités de gouvernance. Ce faisant, vous pouvez sélectionner la solution qui servira de « plan de contrôle de l'IA » pour les applications LLM et basées sur des agents de votre organisation. Une passerelle robuste protège non seulement les budgets et les données, mais accélère également le développement en fournissant une base cohérente et évolutive pour tous les services d'IA. En fin de compte, investir dans la bonne passerelle d'IA permet de faire passer en toute sécurité vos cas d'utilisation de l'IA de l'expérience à la réalité à l'échelle de l'entreprise.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.
Conçu pour la vitesse : latence d'environ 10 ms, même en cas de charge

































.png)

.webp)
.webp)
.webp)



.webp)
.webp)


