

July 21, 2026
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: May 29, 2026
.webp)
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Les opérations financières (FinOps) sont devenues une discipline essentielle à l'ère du cloud, réunissant des équipes d'ingénierie, des finances et des affaires pour maximiser la valeur des dépenses technologiques. À mesure que les entreprises adoptent IA et grands modèles de langage (LLM) à grande échelle, les principes FinOps sont désormais également essentiels pour les charges de travail liées à l'IA.
Pourquoi ? Parce que l'IA introduit nouveaux défis en matière de coûts que la gestion traditionnelle des coûts du cloud n'a pas été conçue pour gérer. Dans un monde piloté par l'IA, le contrôle des dépenses est aussi essentiel que la précision des modèles ou la disponibilité. Voici quelques défis financiers uniques posés par les initiatives modernes d'IA :
FinOps est la discipline de la gestion financière dans le cloud, et ses principes fondamentaux sont les suivants visibilité, responsabilité, et optimisation. FinOps for AI signifie appliquer ces mêmes principes à ces défis spécifiques à l'IA. Dans les sections ci-dessous, nous expliquerons comment chaque principe FinOps s'applique à l'IA et, surtout, comment la plateforme TrueFoundry aide à les mettre en œuvre de manière pratique et conviviale pour l'ingénierie.
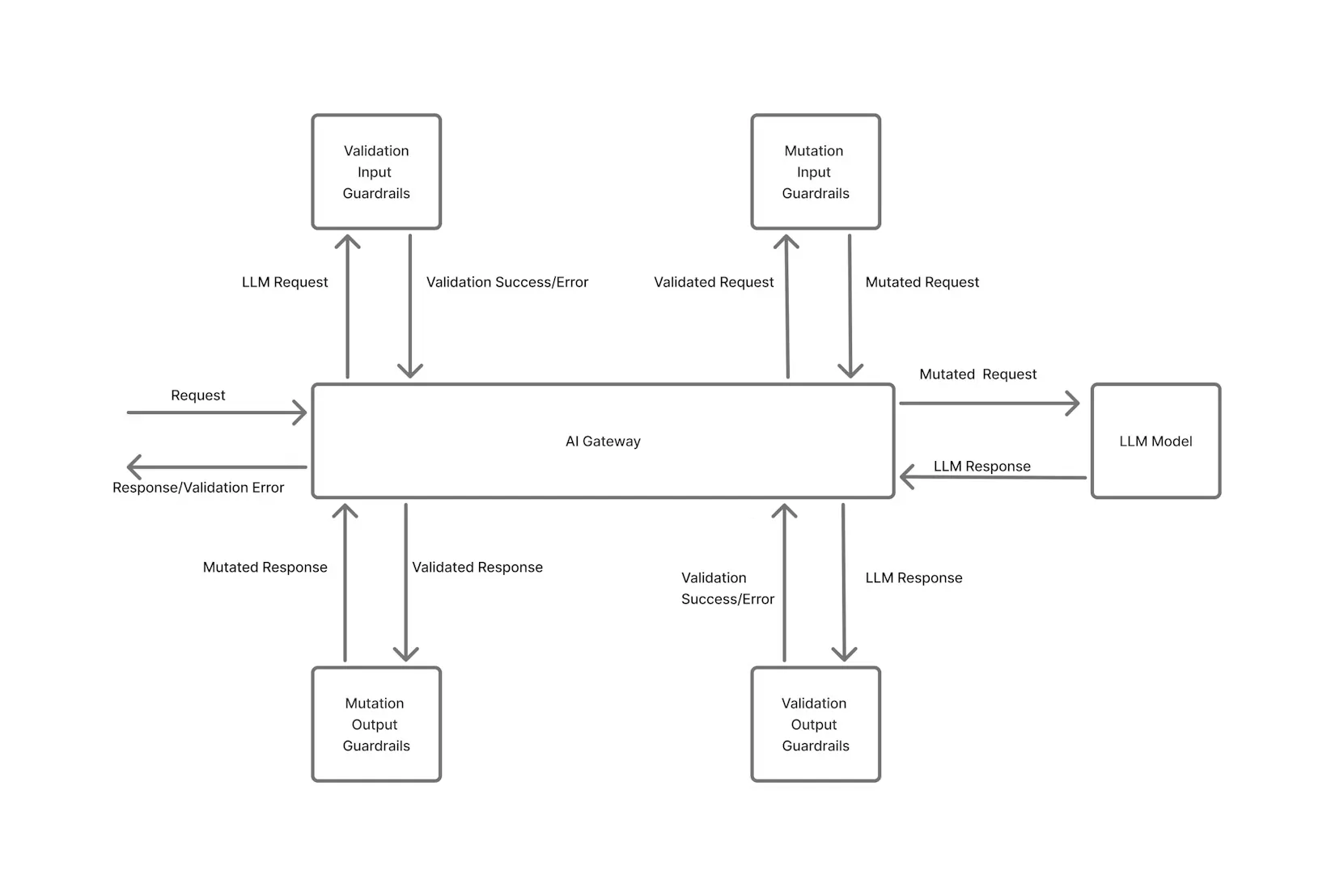
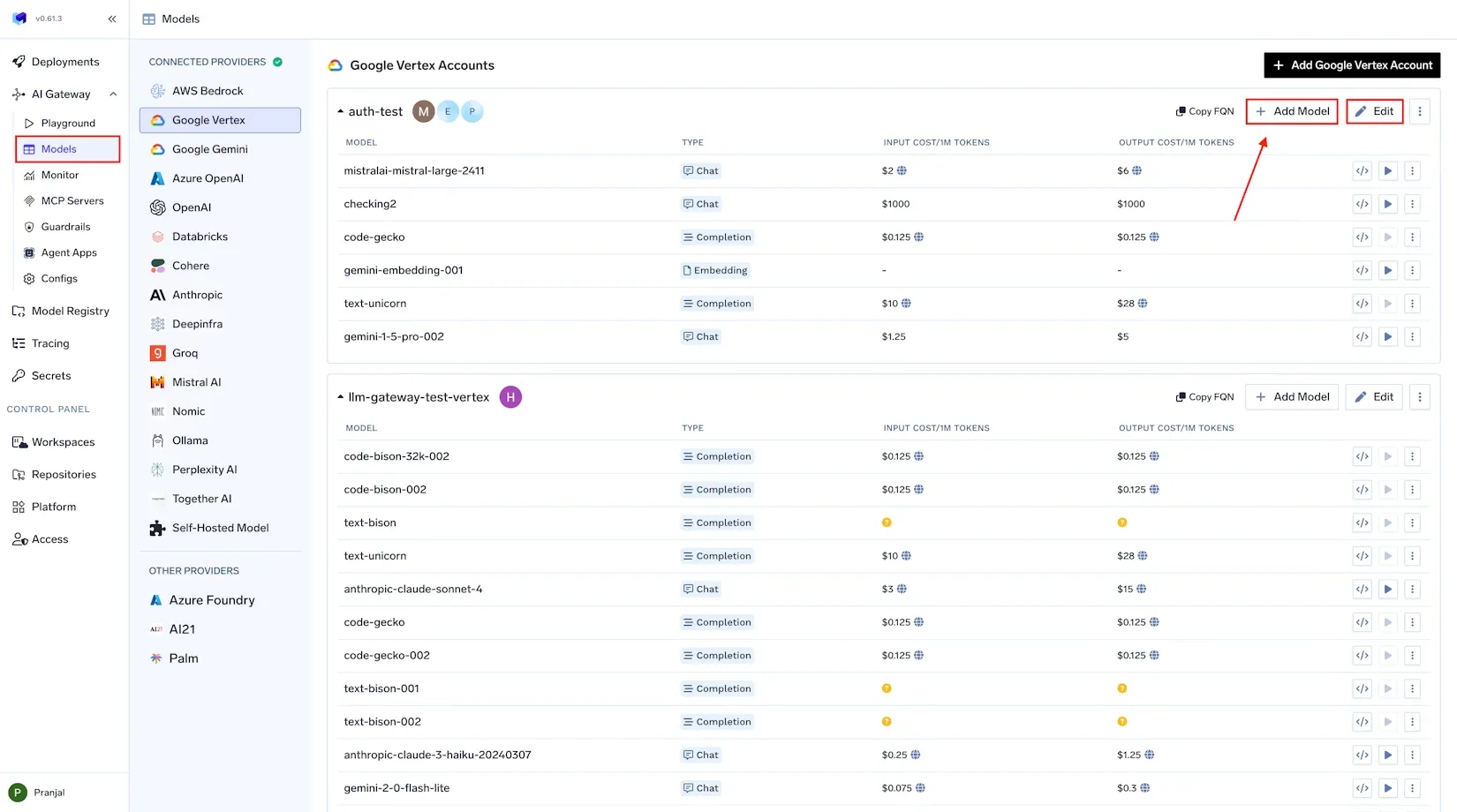
Le premier pilier du FinOps est visibilité — « Vous ne pouvez pas améliorer ce que vous ne mesurez pas. » Dans le contexte de l'IA, la visibilité signifie la capture de données complètes sur chaque appel de modèle, afin que vous sachiez exactement où vont vos budgets en matière de jetons et de GPU. C'est plus facile à dire qu'à faire lorsque l'utilisation est répartie entre plusieurs fournisseurs et infrastructures. TrueFoundry résout ce problème grâce à une solution centralisée Passerelle IA par lequel toutes les demandes d'IA sont acheminées.
Passerelle IA unifiée : TrueFoundry Passerelle IA agit comme un point d'entrée unique (proxy) pour tous les appels de modèles d'IA, qu'il s'agisse d'une API externe comme OpenAI ou Anthropic, ou d'un modèle auto-hébergé exécuté sur votre infrastructure. En acheminant toutes les demandes d'inférence via une seule passerelle, vous établissez un « vitre unique » pour l'observabilité et suivi des coûts. La passerelle est consciente des nuances spécifiques au modèle, telles que le comptage des jetons et la latence, et enregistre chaque demande de manière structurée. Cela élimine les angles morts liés à la fragmentation des outils : quel que soit le modèle ou le fournisseur utilisé, l'utilisation est suivie de manière centralisée.
Journalisation granulaire et métadonnées: Chaque demande passant par la passerelle AI de TrueFoundry est automatiquement enregistrée avec de riches métadonnées à des fins d'attribution. Cela inclut le nom du modèle, l'horodatage, le nombre de jetons d'entrée/sortie, la latence, l'utilisateur ou la clé d'API à l'origine de la demande, etc. Les équipes peuvent également joindre des balises/métadonnées personnalisées à chaque demande, comme customer_id, application, environment ou feature_name.
Par exemple, vous pouvez associer les demandes à la fonctionnalité du produit ou à l'équipe interne responsable. TrueFoundry facilite cette tâche en permettant aux développeurs d'inclure un en-tête X-TFY-METADATA dans les appels d'API. Par exemple, en utilisant le SDK Python :
client = OpenAI(api_key="...", base_url="https://llm-gateway.truefoundry.com/api/inference/openai")
response = client.chat.completions.create(
model="openai-main/gpt-4",
messages=[{"role": "user", "content": "Hello"}],
extra_headers={
"X-TFY-METADATA": '{"application":"booking-bot","environment":"staging","customer_id":"123456"}',
"X-TFY-LOGGING-CONFIG": '{"enabled": true}'
}
)
Dans cet extrait, la demande est balisée avec un nom d'application, un environnement et un ID client en tant que métadonnées. Toutes les valeurs sont des chaînes (128 caractères maximum) et vous pouvez inclure autant de champs que nécessaire. Ces balises accompagnent la demande via la passerelle et sont enregistrées dans les journaux et les métriques.
Collecte de métriques en temps réel: L'AI Gateway ne se contente pas d'enregistrer les données brutes, elle émet également des mesures structurées à des fins de surveillance. Pour chaque demande, TrueFoundry suit des indicateurs tels que le nombre de jetons d'entrée, de jetons de sortie et le coût estimé de cette demande. Ces mesures sont étiquetées avec des dimensions telles que le nom du modèle, le nom d'utilisateur (ou service) et toutes les balises de métadonnées personnalisées que vous avez activées en tant qu'étiquettes.
Par exemple, llm_gateway_request_total_cost est un compteur qui cumule le coût des jetons utilisés, étiquetés par modèle, utilisateur et des métadonnées personnalisées telles que customer_id. Cela signifie que vous pouvez instantanément ventiler les coûts selon les catégories importantes pour votre entreprise (équipe, client, fonctionnalité, etc.) dans vos outils de surveillance.
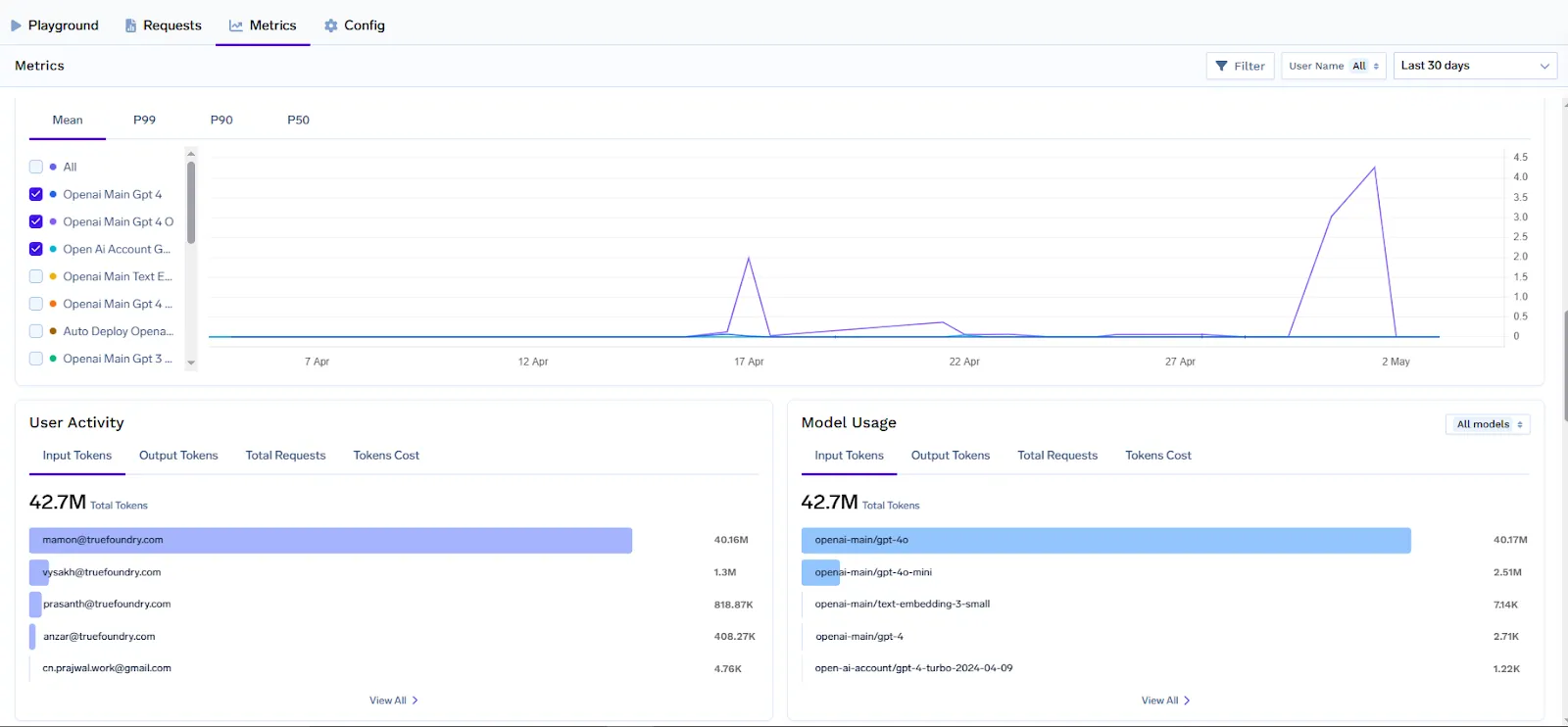
Intégration aux tableaux de bord de surveillance : L'observabilité de TrueFoundry est conçue pour s'intégrer à votre stack de surveillance existant. La passerelle expose un point de terminaison /metrics contenant des métriques compatibles avec Prometheus et peut également envoyer des métriques via OpenTelemetry. Avec quelques paramètres de configuration, vous pouvez demander à la passerelle de publier des métriques sur votre backend Prometheus ou Datadog en temps réel. Une fois ingérées, ces métriques peuvent être visualisées sur les tableaux de bord Grafana ou sur toute plateforme d'analyse utilisée par votre organisation.
En fait, TrueFoundry fournit un tableau de bord Grafana JSON prédéfini pour les métriques d'AI Gateway, qui couvre les vues par modèle, par utilisateur et par règle de configuration.
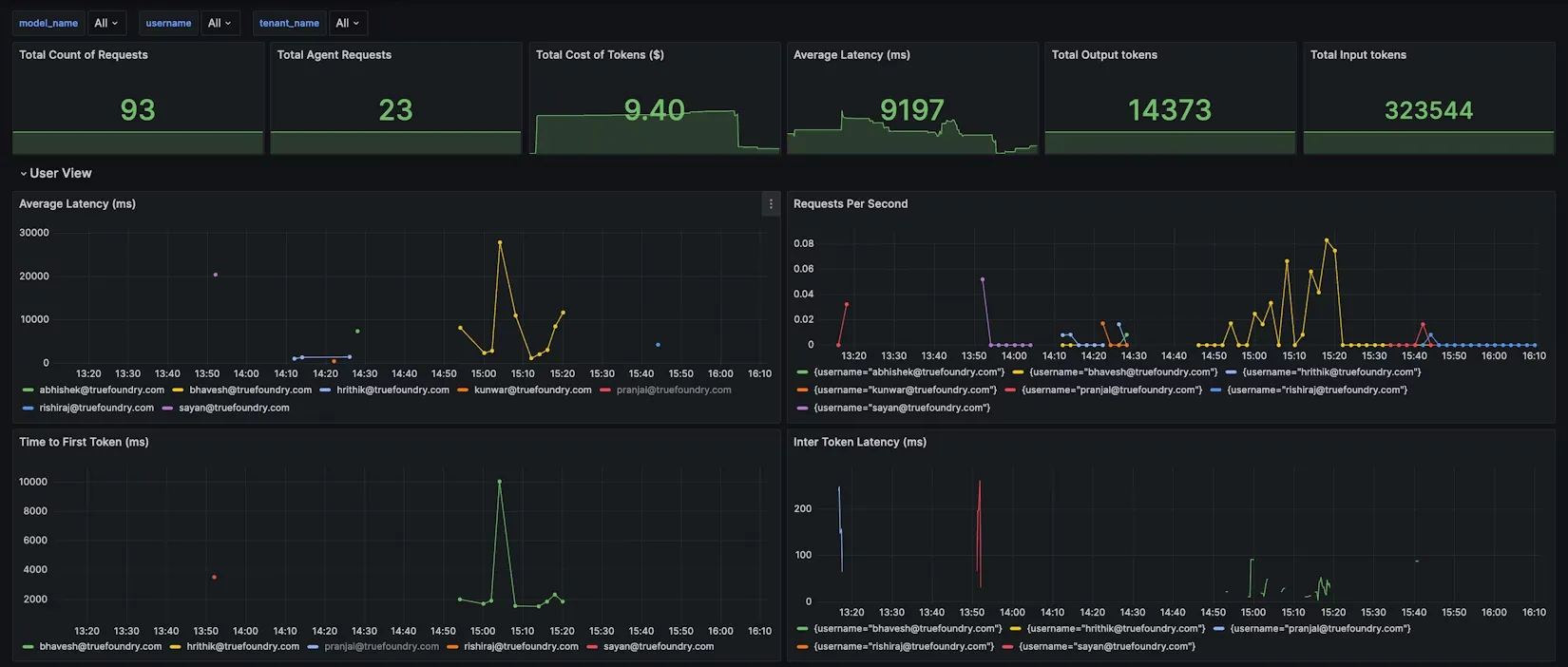
Par exemple, le Vue du modèle peut indiquer l'utilisation des jetons et la latence par modèle, tandis que Affichage de l'utilisateur ventile l'utilisation par nom d'utilisateur pour identifier les gros utilisateurs. Vous pouvez même ajouter des filtres de tableau de bord personnalisés pour vos balises de métadonnées (par exemple, filtrer tous les graphiques par customer_id ou par projet) afin d'obtenir des rapports de coûts à la demande pour un client ou un projet donné.
En centralisant toutes ces données, vous atteignez visibilité complète dans la consommation d'IA. Il devient banal de répondre à des questions telles que : Quelle équipe a généré le plus de jetons GPT-4 cette semaine ? Combien a coûté notre nouvelle fonctionnalité de chatbot en appels d'API ? Quels clients ou utilisateurs génèrent la plus forte consommation ? Avec TrueFoundry, vous pouvez simplement activer un filtre ou exécuter une requête pour obtenir ces réponses. Ce niveau de transparence est à la base du FinOps dans le domaine de l'IA : il met en lumière chaque jeton et chaque heure GPU, transformant l'incertitude en informations exploitables.
Key Metrics for Evaluating Gateway
| Criteria | What should you evaluate ? | Priority | TrueFoundry |
|---|---|---|---|
| Latency | Adds <10ms p95 overhead for time-to-first-token? | Must Have | ✅ Supported |
| Data Residency | Keeps logs within your region (EU/US)? | Depends on use case | ✅ Supported |
| Latency-Based Routing | Automatically reroutes based on real-time latency/failures? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |
| Key Rotation & Revocation | Rotate or revoke keys without downtime? | Must Have | ✅ Supported |

La visibilité prépare le terrain, mais FinOps exige également responsabilité et proactif gouvernance de dépenses. Dans le cloud FinOps, les équipes sont encouragées à maîtriser leur utilisation et à respecter les budgets. Dans le domaine de l'IA FinOps, compte tenu de l'imprévisibilité de l'utilisation, il est essentiel d'appliquer certaines garde-corps afin que les coûts ne soient pas exorbitants à cause d'un bug ou d'une expérience qui a dérapé. La plateforme TrueFoundry construit gouvernance des coûts directement dans la couche d'infrastructure d'IA, afin que vous puissiez contrôler l'utilisation en temps réel au lieu de simplement en rendre compte après coup.
Attribution par demande et rétrofacturations : Comme TrueFoundry étiquette et suit chaque demande à l'aide des métadonnées de l'équipe et du projet, vous pouvez attribuer les coûts à un niveau précis en temps réel. Cela permet de créer des modèles de rétrofacturation ou de rétrofacturation internes, par exemple en indiquant à chaque équipe produit combien ses fonctionnalités consacrent à l'IA, ou en facturant un client externe pour son utilisation spécifique.
Les indicateurs de coûts de TrueFoundry peuvent être filtrés en fonction de ces attributs pour produire des ventilations instantanées (coût par utilisateur, par fonctionnalité, par client, etc.). Le partage de ces rapports favorise la responsabilisation : les équipes peuvent voir l'impact de leur code et de leurs instructions sur la facture, et les finances peuvent s'assurer que les dépenses sont mappées aux unités commerciales ou aux clients.
Contrôle d'accès et autorisations basés sur les rôles: Une partie de la gouvernance consiste à garantir que seule l'utilisation autorisée de ressources coûteuses est autorisée. La passerelle professionnelle de TrueFoundry prend en charge le contrôle d'accès basé sur les rôles (RBAC) et la gestion des clés d'API. Cela signifie que vous pouvez restreindre les personnes autorisées à appeler certains modèles onéreux ou limiter l'accès aux fonctionnalités expérimentales.
Par exemple, vous pouvez autoriser un environnement d'assurance qualité ou de test à utiliser un modèle plus petit, mais seule la production peut appeler la coûteuse API GPT-4. Vous pouvez également limiter la clé d'API d'un développeur junior à un modèle sandbox. En bloquant l'accès, vous empêchez l'utilisation accidentelle de modèles coûteux par de mauvaises personnes. Combiné à des journaux d'audit et à des métadonnées détaillés, cela crée également une piste d'audit pour la conformité (c'est-à-dire que vous savez exactement quel utilisateur ou quel service a effectué chaque demande).
Politiques de limitation des taux: L'un des garde-fous FinOps les plus puissants est limitation de débit. La passerelle IA de TrueFoundry vous permet de configurer des règles de limite de débit flexibles pour limiter l'utilisation selon différents critères : par utilisateur, équipe, modèle ou même par balises personnalisées.
Par exemple, vous pouvez dire « L'utilisateur X ne peut effectuer que 1 000 requêtes GPT-4 par jour » ou « Toutes les demandes du projet ABC sont limitées à 50 000 jetons par heure. » La configuration est définie dans un format YAML simple. Voici un extrait illustrant quelques règles :
name: ratelimiting-config
type: gateway-rate-limiting-config
rules:
# 1. Limit a specific user to 1000 requests/day on the GPT-4 model
- id: "limit-gpt4-user1-daily"
when:
subjects: ["user:[email protected]"]
models: ["openai-main/gpt4"]
limit_to: 1000
unit: requests_per_day
# 2. Limit each project (by metadata tag) to 50k tokens per hour
- id: "project-{metadata.project_id}-hourly"
when: {}
limit_to: 50000
unit: tokens_per_hourDans la règle #1 ci-dessus, un utilisateur spécifique (identifié par sa clé API ou son nom d'utilisateur) est limité à 1 000 requêtes GPT-4 par jour. Dans la règle #2, nous imposons une limite de 50 000 jetons/heure par projet, en supposant que chaque demande inclut un project_id dans ses métadonnées. La syntaxe {metadata.project_id} signifie que la passerelle appliquera un compartiment distinct pour chaque ID de projet unique rencontré. En pratique, cette règle empêche un projet de consommer accidentellement plus de 50 000 jetons en une heure (par exemple, si une intégration ne fonctionne pas correctement ou si un client connaît un pic inattendu). La passerelle évalue les demandes entrantes par rapport à ces règles dans l'ordre, et si une demande dépasse une limite, elle est étranglé ou rejeté sur place.
Alertes budgétaires et quotas : Outre les limites de débit brut, TrueFoundry permet de définir des seuils budgétaires. Vous pouvez définir des plafonds de dépenses mensuels ou quotidiens pour une équipe ou une application. Par exemple, vous pourriez prévoir un budget de 1 000$ par mois pour l'expérimentation des LLM par une équipe de développement. La passerelle peut suivre le coût cumulé des demandes et, une fois le seuil franchi, elle peut soit envoyer des alertes, soit désactiver toute utilisation ultérieure jusqu'à ce qu'un administrateur intervienne. Il s'agit essentiellement exécution automatique du budget. Au lieu de découvrir à la fin du mois que l'équipe A a trop dépensé, vous constatez que cela représente (disons) 80 % du budget et vous pouvez agir.
La passerelle de TrueFoundry peut même accélération automatique ou pause demandes lorsqu'un budget est épuisé, évitant ainsi les dépenses excessives tout en informant les parties prenantes. Les équipes financières apprécient ce type de filet de sécurité, car il permet de transformer la gouvernance des coûts en un processus actif et continu plutôt qu'en une analyse a posteriori.
Garde-corps et validation rapides: Un autre aspect de la gouvernance consiste à appliquer les meilleures pratiques en matière d'instructions et de modèles d'utilisation afin d'éviter une explosion des coûts. La plateforme TrueFoundry inclut des fonctionnalités de garde-corps permettant, par exemple, de bloquer certaines instructions dangereuses ou inefficaces. Vous pouvez définir des règles pour rejeter les invites qui dépassent la longueur maximale du jeton ou qui contiennent du contenu non autorisé.
De même, TrueFoundry prend en charge schémas de sortie structurés et des modèles rapides qui permettent de garder les réponses concises et prévisibles, en contrôlant indirectement l'utilisation des jetons.
Le principe final du FinOps est optimisation — amélioration continue de la rentabilité sans sacrifier les performances ou les résultats. Après avoir gagné en visibilité et mis en place une gouvernance, les organisations peuvent se concentrer sur la valorisation de chaque dollar dépensé dans l'IA. TrueFoundry propose plusieurs moyens d'optimiser les charges de travail de l'IA, du routage intelligent des demandes au niveau du modèle à l'utilisation efficace de l'infrastructure GPU.
Sélection intelligente du modèle (modèles de bonne taille) : Toutes les tâches ne nécessitent pas le modèle le plus cher. L'une des caractéristiques de l'optimisation des coûts de l'IA consiste à utiliser suffisant le moins cher modèle pour chaque tâche. La passerelle AI de TrueFoundry prend en charge modèle de routage hybride stratégies qui vous permettent de diriger automatiquement les demandes vers différents modèles en fonction de politiques de coût ou de complexité.
Par exemple, vous pouvez acheminer des requêtes simples ou des requêtes de faible priorité vers un modèle plus petit et moins cher (comme un modèle 7B open source ou un niveau OpenAI GPT-3.5), et envoyer uniquement des requêtes complexes ou à enjeux élevés vers un modèle premium tel que GPT-4. De nombreuses équipes constatent qu'une grande partie de leur trafic peut être gérée par des modèles moins chers, réservant le modèle coûteux aux rares cas où ses capacités supérieures sont réellement nécessaires. TrueFoundry rend cela possible en autorisant le routage basé sur des règles (ou même le routage dynamique basé sur le ML) dans la configuration de la passerelle. Le résultat est d'éviter de payer trop cher pour des modèles « surdimensionnés » : vous ne payez jamais trop cher pour des fonctionnalités dont vous n'avez pas besoin lorsque la passerelle peut automatiquement passer à un modèle moins cher pour les bons scénarios.
Traitement par lots et mise en cache : Lorsque vous payez par demande ou par jeton, il est rentable d'éliminer le travail redondant. La plateforme TrueFoundry fournit des fonctionnalités pour traitement par lots et mise en cache des réponses pour améliorer l'efficacité. Avec le API d'inférence par lots, vous pouvez combiner plusieurs invites ou entrées en une seule demande afin d'amortir les frais généraux.
Optimisation et troncature rapides : Une autre voie d'optimisation consiste à réduire la taille des invites. Grâce à l'observabilité, vous pourriez découvrir que certaines instructions sont inutilement longues (par exemple, si elles incluent un contexte non pertinent). Des techniques telles que la compression rapide, l'utilisation d'un historique plus court ou l'utilisation de la génération augmentée par extraction (où les connaissances externes sont récupérées de manière pertinente au lieu de transférer un document entier dans l'invite) peuvent réduire le nombre de jetons.
TrueFoundry prend en charge les flux de travail RAG et même les outils de gestion rapide (tels que la gestion des versions et les tests rapides) pour aider les équipes à itérer vers des invites plus efficaces. Par exemple, au lieu qu'une conversation utilisateur envoie l'intégralité de l'historique des discussions à chaque fois, vous pouvez résumer ou supprimer l'ancien contexte une fois qu'il n'est plus pertinent, en échangeant un tout petit peu de précision pour réaliser des économies importantes. TrueFoundry Terrain de jeu rapide et les analyses peuvent vous aider à analyser la corrélation entre la rapidité et le coût, en mettant en évidence les domaines dans lesquels vous pourriez réduire la graisse.
Optimisation de l'utilisation du GPU: Pour les équipes utilisant des modèles auto-hébergés ou effectuant des tâches de formation, l'optimisation de l'infrastructure GPU est cruciale pour FinOps. La plateforme ML de TrueFoundry est conçue pour optimiser l'utilisation du GPU et éliminer le gaspillage. Les fonctionnalités clés incluent :
Une initiative FinOps pratique bénéficie de rapports et de tableaux de bord clairs qui rassemblent les indicateurs et les informations commerciales. TrueFoundry simplifie la création de Tableaux de bord FinOps pour l'IA en fournissant toutes les données nécessaires prêtes à l'emploi et des points d'intégration pour les outils courants.
À l'aide des métriques exportées par AI Gateway, les équipes peuvent créer des tableaux de bord dans Grafana, Datadog ou tout autre outil de BI pour visualiser l'utilisation de l'IA et les tendances en matière de dépenses. Par exemple, étant donné que chaque demande est étiquetée avec une équipe et un modèle, vous pouvez créer un panneau Grafana affichant « Coût par équipe (7 derniers jours) » en interrogeant la métrique llm_gateway_request_total_cost groupée par tenant_name (team). Un autre panneau pourrait afficher « Jetons par demande et par modèle » pour identifier les modèles qui sont gourmands en jetons et qui pourraient avoir besoin d'être optimisés. TrueFoundry tableau de bord Grafana pré-intégré inclut déjà des vues permettant d'analyser l'utilisation par modèle, par utilisateur et par règles de configuration (par exemple, pour voir si des limites de débit sont fréquemment atteintes). Vous pouvez les étendre avec des métadonnées personnalisées ; par exemple, ajouter un filtre pour customer_id en tant que variable, afin que les parties prenantes puissent sélectionner un client spécifique et voir l'utilisation de ses jetons et ses coûts au fil du temps.
L'intégration avec d'autres outils de surveillance et d'APM est possible via OpenTelemetry. Si votre organisation utilise Datadog, vous pouvez transmettre les métriques de la passerelle à la collecte de métriques de Datadog (puisque Datadog peut ingérer des métriques OpenTelemetry ou Prometheus). Cela signifie que vos indicateurs de coûts liés à l'IA peuvent coexister avec vos indicateurs de coûts d'infrastructure. Il devient facile de corréler, par exemple, une augmentation de l'utilisation de jetons à un déploiement ou à un lancement de fonctionnalité particulier, car toutes les données sont accessibles en un seul endroit.
TrueFoundry fournit également un API d'analyse pour les données d'utilisation. Si vous préférez les extraire dans un tableau de bord financier personnalisé ou dans une feuille de calcul, vous pouvez le faire. De nombreuses entreprises exportent des données brutes (TrueFoundry permet même le téléchargement des données de coûts au format CSV) pour les combiner avec les enregistrements de facturation, ce qui permet d'obtenir une image complète du coût par projet lorsque vous ajoutez des frais généraux tels que le stockage ou la mise en réseau.
L'essentiel est qu'avec les bases posées par TrueFoundry (balisage des métadonnées, mesures en temps réel), la création de ces informations FinOps ne nécessite pas de créer un pipeline de données à partir de zéro. Vous obtenez des données précises et riches en attributions en temps réel, ce qui représente une avancée considérable par rapport à l'attente de la facture cloud de fin de mois. Les responsables de l'ingénierie, du machine learning et des finances peuvent examiner ensemble des tableaux de bord qui répondent à des questions techniques et commerciales concernant l'utilisation de l'IA. Cette visibilité transversale favorise une culture de prise de conscience des coûts
La mise en œuvre de FinOps pour l'IA est un processus continu. Cela commence par conscience et devient une discipline intégrée au cycle de vie du développement de l'IA. En établissant des pratiques en matière de visibilité, de responsabilité et d'optimisation, les organisations progressent vers la maturité FinOps, qu'il s'agisse de rapports de coûts réactifs, de contrôle des coûts en temps réel, voire d'optimisation prédictive. Plus important encore, la construction d'un La culture FinOps autour de l'IA garantit la durabilité. L'adoption de l'IA ralentira si les coûts augmentent de manière incontrôlée ou imprévisible. En envisageant l'IA du point de vue FinOps, les entreprises considèrent l'accès aux modèles et le temps passé sur le GPU comme des ressources précieuses à gérer, et non comme une magie illimitée. Ce changement culturel est rendu possible par l'outillage : lorsque les équipes ont accès en libre-service aux indicateurs et aux rapports sur les coûts, elles peuvent s'en approprier la situation. TrueFoundry la solution accélère cette adoption culturelle en utilisant l'IA transparent et régi par le design — la visibilité et les contrôles des coûts sont intégrés à la plateforme, et non pas après coup.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception




.png)

.webp)
.webp)
.webp)



.webp)
.webp)


