Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.
9,9
Considérations financières liées à l'utilisation d'une passerelle d'IA : optimisation des dépenses d'IA des entreprises
Published: May 29, 2026
Conçu pour la vitesse : latence d'environ 10 ms, même en cas de charge
Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Gère plus de 350 RPS sur un seul processeur virtuel, aucun réglage n'est nécessaire
Prêt pour la production avec un support complet pour les entreprises
La gestion des coûts liés à l'utilisation de grands modèles linguistiques (LLM) est devenue une préoccupation essentielle pour les entreprises qui déploient l'IA à grande échelle. Contrairement aux logiciels traditionnels, les services basés sur LLM utilisent souvent tarification basée sur des jetons — les fournisseurs facturent par jeton d'entrée/sortie — ce qui rend la budgétisation difficile à prévoir ou à contrôler. De nombreux facteurs contribuent à cette complexité :
Différents modèles de tarification : Chaque fournisseur LLM (OpenAI, Anthropic, Cohere, etc.) ou taille de modèle a son propre tarif par jeton, les modèles plus grands (par exemple la classe GPT-4) coûtant beaucoup plus cher par jeton que les plus petits.
Modèles d'utilisation imprévisibles : La consommation de jetons peut varier considérablement selon l'utilisateur, la fonctionnalité ou le flux de travail : une fonctionnalité peut utiliser 10 fois plus de jetons qu'une autre, et l'utilisation peut augmenter de manière inattendue en fonction du comportement de l'utilisateur.
Pipelines rapides dynamiques : Les cas d'utilisation avancés tels que la génération augmentée par extraction (RAG), les agents utilisant des outils ou les chaînes en plusieurs étapes peuvent augmenter par inadvertance la taille des invites et la longueur des réponses, multipliant ainsi les jetons (et le coût) requis par requête.
Par conséquent, sans une visibilité et des contrôles adéquats, les équipes ne se rendent souvent pas compte de la rapidité avec laquelle les coûts s'accumulent avant l'arrivée de la facture. Il n'est pas rare que les dépenses ballon de façon inattendue, menaçant les budgets des projets et entravant les efforts de mise à l'échelle. Un récent rapport de Gartner met également en garde contre le manque de visibilité des coûts et de gouvernance peut rapidement entraîner des dépassements de budget dans les initiatives d'IA. En résumé, alors que les entreprises intègrent des LLM dans leurs produits, le contrôle des coûts d'utilisation est aussi essentiel que la précision du modèle ou la disponibilité. La tarification basée sur les jetons crée une incertitude qui peut réduire le retour sur investissement si elle n'est pas gérée activement.
C'est là que le concept de Passerelle IA entre. Une passerelle IA est en train de devenir un élément clé pour reprendre le contrôle de l'utilisation et des dépenses du LLM. Avant de nous pencher sur les inducteurs de coûts et les solutions, définissons ce qu'est une passerelle IA et comment elle influence les coûts.
Qu'est-ce qu'une passerelle IA ? (Et comment cela affecte les coûts)
Un Passerelle IA est une couche intergicielle spécialisée qui gère toutes les interactions entre vos applications et plusieurs modèles ou fournisseurs d'IA. Considérez-le comme une passerelle d'API conçue spécifiquement pour les charges de travail d'IA, une passerelle qui comprend les nuances spécifiques aux modèles, telles que la facturation basée sur des jetons, la latence d'inférence et le routage dynamique. Il fournit un point de terminaison unifié pour toutes les demandes d'IA, en dirigeant intelligemment le trafic vers le bon modèle de backend en fonction de politiques de coût, de performances ou de disponibilité.
Bien que l'ajout d'une passerelle entraîne des frais généraux mineurs tels que les coûts d'hébergement et les efforts de configuration, ceux-ci sont compensés par le contrôle et la visibilité qu'elle fournit. En acheminant chaque demande via une seule couche, les entreprises peuvent surveiller l'utilisation, appliquer les budgets et prendre des décisions en temps réel quant au modèle offrant le meilleur compromis coût-performance. Gartner décrit les passerelles IA comme des « contrôleurs de trafic intelligents » qui aident les entreprises à évaluer et à optimiser l'utilisation des modèles dans toutes les applications.
Passerelle IA de TrueFoundry fonctionne comme ce plan de contrôle qui unifie l'accès entre les modèles et les fournisseurs tout en appliquant les politiques de l'entreprise telles que le contrôle d'accès, la gouvernance des coûts, la mise en cache et l'observabilité. Il transforme la consommation d'IA d'une dépense imprévisible en un système géré, mesurable et optimisable.
Principaux facteurs de coûts liés à l'utilisation du LLM
Lors de l'utilisation de grands modèles linguistiques en production, plusieurs facteurs clés déterminent le coût d'exploitation global. Comprendre ces facteurs constitue la première étape de la gestion et de la réduction des coûts liés au LLM :
Choix du modèle et taille : Le choix du modèle a un impact considérable sur les coûts. Les modèles plus grands et plus avancés (avec un plus grand nombre de paramètres ou davantage de fonctionnalités) ont généralement des coûts par jeton beaucoup plus élevés. Par exemple, le GPT-4 ou d'autres modèles de « raisonnement » peuvent coûter un ordre de grandeur plus cher par jeton que les modèles plus petits. L'utilisation d'un modèle de premier plan pour chaque demande, y compris les requêtes triviales, augmentera les coûts inutilement.
Utilisation des jetons (invite et longueur de réponse) : Le nombre de jetons envoyés dans les invites et les jetons générés dans les réponses déterminent directement la facturation. Les conversations ou les documents longs, les fenêtres contextuelles très longues ou les invites non optimisées contenant des informations non pertinentes font grimper le nombre de jetons. Des fonctionnalités telles que le fait de demander au modèle d'être détaillé ou de renvoyer des explications détaillées peuvent augmenter son utilisation de façon exponentielle. Efficace ingénierie rapide le fait de garder les instructions succinctes et de cibler les résultats peut réduire considérablement les coûts. Chaque jeton compte lorsque vous payez des fractions de cent par jeton des millions de fois.
Volume et structure du trafic : La fréquence et l'ampleur de l'utilisation des fonctionnalités d'IA auront évidemment une incidence sur les coûts, mais il ne s'agit pas seulement du volume total, mais de la tendance. Un trafic élevé et imprévisible peut entraîner des coûts pendant les périodes de pointe d'utilisation, ce qui entraîne une réduction du budget mensuel. La variabilité entre les utilisateurs ou les fonctionnalités signifie que quelques utilisateurs expérimentés ou un outil interne peuvent consommer secrètement la majorité des jetons. Les pics d'utilisation soudains (par exemple, une nouvelle fonctionnalité devenant virale) peuvent entraîner des factures imprévues si elles ne sont pas limitées. Augmenter l'utilisation sans renforcer la surveillance des coûts est une recette pour les dépassements.
Utilisation multimodèle et sélection du fournisseur : De nombreuses équipes utilisent une combinaison de modèles, par exemple un modèle open source pour certaines tâches et une API propriétaire pour d'autres, ou différents fournisseurs pour différentes langues. Chaque modèle/fournisseur peut avoir des unités de prix différentes (certains facturent pour 1 000 jetons, d'autres par demande, etc.) et éventuellement des frais supplémentaires. De plus, si une équipe choisit toujours par défaut le modèle le plus coûteux « pour des raisons de sécurité », elle rate des occasions d'économiser. Sélection du le bon modèle pour chaque tâche est un levier de coût majeur : une requête simple n'a pas besoin d'un modèle coûteux de 175 Go de paramètres alors qu'un modèle plus petit (et moins cher) ferait l'affaire. À l'inverse, certaines tâches complexes peuvent justifier le coût d'un modèle supérieur. La stratégie (ou l'absence de stratégie) d'acheminement du trafic vers les modèles est un facteur de coût important.
Infrastructure et frais généraux : Il existe également des coûts au-delà des frais par jeton. Si vous hébergez vous-même des LLM open source pour éviter les coûts d'API, vous payez en termes d'infrastructure : serveurs GPU, mémoire, maintenance et efforts MLOps. Comme l'indique succinctement une analyse, « Les LLM open source ne sont pas gratuits. Ils ne font que déplacer la facture des licences vers l'ingénierie, l'infrastructure, la maintenance et les risques stratégiques. » Même en utilisant des API cloud, vous pouvez avoir besoin d'une infrastructure supplémentaire pour gérer les demandes (par exemple, exécuter un service ou une passerelle interne, des bases de données vectorielles pour RAG, etc.), ce qui entraîne des coûts de cloud computing. Les frais d'intégration et le temps d'ingénierie sont des coûts « cachés » qui peuvent augmenter.
Frais de licence ou d'abonnement : Certains modèles et services impliquent des frais fixes en plus de l'utilisation. Par exemple, certaines API d'IA d'entreprise nécessitent un abonnement ou un engagement mensuel. Même les modèles open source peuvent comporter des restrictions de licence qui poussent les entreprises à opter pour des options payantes. Si vous adoptez un modèle propriétaire de plateforme de service, des frais de licence peuvent être facturés. Ces frais doivent être pris en compte dans le coût total de possession lié à l'utilisation d'un modèle donné. Parfois, un modèle « moins cher par jeton » peut nécessiter une licence coûteuse, annulant ainsi les économies réalisées.
Coûts d'intégration et d'inefficacité : Enfin, la manière dont vous intégrez l'IA à vos systèmes peut entraîner des économies. Les appels redondants, l'absence de mise en cache ou une mauvaise gestion de la charge peuvent entraîner un gaspillage de jetons. Les premières entreprises à les adopter ont découvert que l'utilisation d'une passerelle API standard ou d'une intégration ad hoc conduisait à dépassements de coûts importants — dans certains cas, 300 % de plus que les prévisions initiales — car l'outillage ne tenait pas compte des optimisations spécifiques à l'IA, telles que la mise en cache d'instructions similaires ou l'équilibrage de charge entre les modèles. La création et la maintenance de votre propre infrastructure pour un accès et une surveillance multimodèles entraînent des coûts. Si chaque équipe appelle les API d'IA de manière indépendante, vous perdez des économies d'échelle et une supervision centralisée, ce qui entraîne souvent des dépenses globales plus élevées que nécessaire (par exemple, plusieurs équipes utilisent le même modèle avec la même demande et paient deux fois).
La compréhension de ces facteurs de coûts montre pourquoi il ne suffit pas de donner aux équipes l'accès à une API LLM : l'utilisation non gérée de nombreuses applications et utilisateurs entraîne presque inévitablement des surprises. Plus l'utilisation de l'IA est critique et généralisée, plus le besoin de gouvernance est grand.C'est là que les passerelles IA prouvent leur valeur : elles ciblent directement ces inducteurs de coûts, en fournissant des mécanismes permettant de maîtriser les coûts sans sacrifier les performances ou la fiabilité.
Gestion et réduction des coûts de LLM grâce à une passerelle IA
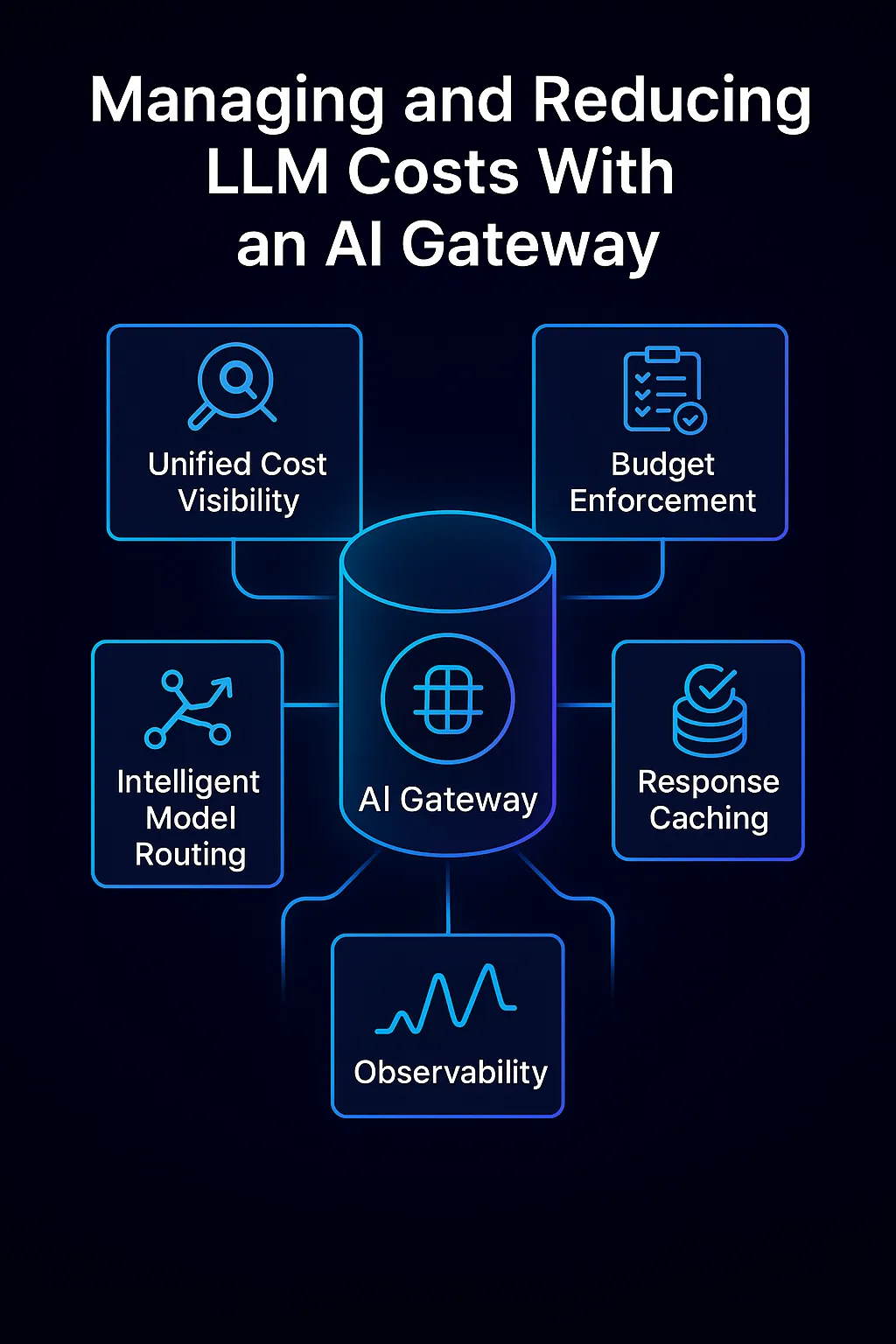
Une passerelle IA propose une suite d'outils et de stratégies intelligentes pour lutter contre les facteurs de coûts ci-dessus. Il sert de centre couche de gouvernance des coûts pour toutes les utilisations de l'IA. Selon Gartner, les passerelles d'IA peuvent atténuer le risque de « la spirale des coûts de l'IA due à une mauvaise gouvernance » en agissant comme point de contrôle entre les consommateurs et les fournisseurs d'IA. La passerelle IA de TrueFoundry, par exemple, intègre de nombreuses fonctionnalités pour surveiller et optimiser les coûts. Examinons en détail comment une passerelle d'IA permet de gérer et de réduire les coûts de LLM :
Visibilité unifiée des coûts : Toutes les demandes sont acheminées via la passerelle, qui enregistre des mesures d'utilisation détaillées pour chaque appel : modèle utilisé, jetons consommés, latence, attribution utilisateur/équipe, etc. Cela fournit une visibilité granulaire en temps réel sur la destination de vos dollars symboliques. Les dirigeants peuvent enfin répondre à la question « quelles applications ou quels cas d'utilisation sont à l'origine de la majeure partie de notre projet de loi OpenAI ? » avec précision. Cette visibilité inter-applications est quasiment impossible à obtenir lorsque les équipes appellent directement les modèles. Avec une passerelle, vous bénéficiez d'un source unique de vérité tableau de bord pour l'utilisation et les dépenses de l'IA. Une telle transparence permet la comptabilisation par rétrofacturation/rétrofacturation (répartition des coûts entre les départements), ce qui favorise la responsabilisation.
Exécution du budget et garde-fous : La visibilité à elle seule ne suffit pas : la passerelle permet également de politiques pour éviter une utilisation excessive. Vous pouvez définir limites tarifaires et quotas (par exemple, pas plus de N jetons ou X $ dépensés par jour pour un utilisateur ou une fonctionnalité donné) et la passerelle rejettera ou limitera les demandes au-delà de cela. Cela garantit qu'un script qui se comporte mal ou un pic d'utilisation inattendu ne fasse pas exploser le budget. Vous pouvez également configurer alertes budgétaires ou arrêt automatique règles : si l'utilisation mensuelle d'une équipe dépasse un certain seuil, la passerelle peut envoyer des notifications ou interrompre temporairement les appels jusqu'à approbation, évitant ainsi des factures surprises. De plus, les passerelles permettent contrôle d'accès et restrictions relatives aux modèles — par exemple, vous pouvez autoriser uniquement l'utilisation de modèles coûteux tels que le GPT-4 pour certains flux de travail critiques, tandis que les utilisations moins critiques sont limitées aux modèles les moins chers. Une autre forme de protection est le filtrage des requêtes : il s'agit de bloquer les demandes qui déclencheraient des sorties extrêmement longues ou des requêtes peu rentables. En appliquant ces règles de gouvernance de manière centralisée, les organisations fixent des limites strictes en matière d'exposition aux coûts.
Key Metrics for Evaluating Gateway
Criteria
What should you evaluate ?
Priority
TrueFoundry
Latency
Adds <10ms p95 overhead for time-to-first-token?
Must Have
✅ Supported
Data Residency
Keeps logs within your region (EU/US)?
Depends on use case
✅ Supported
Latency-Based Routing
Automatically reroutes based on real-time latency/failures?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Key Rotation & Revocation
Rotate or revoke keys without downtime?
Must Have
✅ Supported
Evaluating an AI Gateway?
A practical guide used by platform & infra teams
Routage intelligent des modèles : La plus grande économie de coûts est peut-être la capacité de la passerelle à acheminer dynamiquement chaque demande vers le modèle ou le fournisseur optimal en fonction du contexte. Au lieu de recourir à une solution unique, la passerelle peut évaluer des facteurs tels que la complexité de la requête, la précision requise, la latence et le coût, puis choisir (ou même commutation automatique) le modèle qui répond le mieux aux besoins au moindre coût. Par exemple, une question factuelle simple pourrait être répondue par un modèle plus petit et moins cher sans différence de qualité notable, tandis qu'une tâche complexe est envoyée à un modèle plus puissant. Ce type de sélection de modèles en temps réel réduit les coûts en évitant les dépenses excessives. La passerelle AI de TrueFoundry l'implémente via règles de routage intelligentes et équilibrage de charge : vous pouvez le configurer de telle sorte que, par défaut, les requêtes soient envoyées à un modèle open source tel que Mistral pour des raisons de rapidité et de faible coût, mais si l'invite semble complexe ou si la confiance du plus petit modèle est faible, la passerelle achemine cette demande vers un modèle plus grand comme GPT-4. Sur des centaines de milliers de demandes, ce routage adaptatif peut permettre de réaliser des économies considérables tout en préservant la qualité globale. Il permet de surmonter la fausse dichotomie entre le choix d'un modèle performant et d'un modèle à faible coût : vous pouvez avoir les deux en utilisant chacune d'elles là où elles ont du sens.
Mise en cache des réponses : Une autre optimisation des coûts est mise en cache réponses d'IA répétées ou courantes. Si plusieurs utilisateurs posent la même question ou si votre système effectue des requêtes identiques à plusieurs reprises, une passerelle IA peut renvoyer une réponse mise en cache au lieu d'appeler à nouveau le modèle, ce qui permet d'enregistrer entièrement ces jetons. Même la mise en cache de résultats partiels (comme des étapes intermédiaires coûteuses) peut être utile. Cela est particulièrement utile pour les tâches de backend ou les applications où la même invite est fréquemment utilisée. La mise en cache permet non seulement de réduire les coûts, mais aussi d'améliorer la latence de ces requêtes. TrueFoundry la passerelle prend en charge à la fois la mise en cache simple et plus avancée mise en cache sémantique — où des invites sémantiquement similaires peuvent être traitées comme des accès au cache. (La mise en cache sémantique doit être utilisée avec précaution, car de subtiles différences entre les instructions peuvent modifier la réponse, mais dans les bons scénarios, elle peut augmenter les taux d'accès du cache et réduire les coûts.) Des études ont montré que les mécanismes de mise en cache sémantique pouvaient réduire les coûts de l'API LLM jusqu'à 70 % dans les cas d'utilisation en entreprise. Dans la pratique, même un cache plus simple pour des requêtes identiques permet de réduire considérablement les coûts liés aux applications à volume élevé
Observabilité et détection des anomalies : Comme la passerelle surveille toutes les demandes, elle peut également détecter modèles d'utilisation anormaux cela peut indiquer un bogue ou un abus. Par exemple, si cette heure indique 5 fois l'utilisation du jeton par rapport à la dernière heure, ou si une application commence soudainement à spammer le modèle avec de grandes instructions, la passerelle (et ses tableaux de bord intégrés) détectera cette anomalie. Grâce à la détection précoce, vous pouvez intervenir avant que le budget ne soit épuisé. L'observabilité contribue également à la fiabilité : elle permet de suivre les taux d'erreur et les latences, ce qui permet de différencier les ralentissements liés aux coûts des problèmes de modèle. Certaines passerelles, comme celle de TrueFoundry, s'intègrent à des outils tels qu'OpenTelemetry afin que vous puissiez fusionner les mesures d'utilisation de LLM avec votre pile de surveillance globale. Cette observabilité globale vous garantit le maintien des coûts et objectifs de performance. Il permet également des rétrofacturations internes : étant donné que l'utilisation est enregistrée de manière centralisée, vous pouvez demander aux équipes de prendre en charge leur part de la facture d'IA, les incitant ainsi à être efficaces.
Comment une passerelle IA gère et réduit les coûts de LLM en combinant une visibilité unifiée, l'application du budget, le routage intelligent des modèles, la mise en cache et l'observabilité au sein d'une seule couche de contrôle.
Toutes ces fonctionnalités se combinent pour renforcer la discipline des coûts sans supervision manuelle constante. En utilisant une passerelle IA, la gestion des coûts devient proactive et automatisée: vous avez coûté limites en place pour ne pas trop dépenser, vous avez informations en temps réel pour ajuster les habitudes d'utilisation, et vous avez optimisations automatisées (routage, mise en cache) en éliminant les inefficacités à la volée. Il transforme ce qui pourrait être un centre de coûts opaque et galopant en un service public régi.
La passerelle IA de TrueFoundry illustre ces contrôles des coûts dans la pratique. Il fournit des tableaux de bord de suivi des coûts, configuration de la politique budgétaire, routage multimodèle règles et mécanismes de mise en cache, tous configurables via une interface conviviale pour les entreprises. Le résultat est que les entreprises peuvent adopter davantage de cas d'utilisation de l'IA sans la peur des factures imprévisibles. Bien entendu, l'utilisation d'une telle passerelle introduit certaines considérations concernant les performances et l'architecture, que nous aborderons ensuite.
Équilibrer les coûts, la précision, la latence et la complexité
Toute stratégie visant à maîtriser les coûts de manière agressive doit être mise en balance avec d'autres exigences techniques et commerciales. Compromis sont inévitables. Dans le contexte des déploiements LLM, les dimensions clés à équilibrer sont le coût, la précision (ou la qualité des résultats), la latence (vitesse de réponse) et la complexité architecturale. Une passerelle d'IA permet de gérer ces compromis, mais il est important de les comprendre pour définir les bonnes politiques :
Coût et précision : Des modèles de meilleure qualité entraînent généralement des coûts plus élevés, mais toutes les tâches ne nécessitent pas un raisonnement de niveau GPT 4. Un modèle 7B plus petit peut répondre à la question « Quelle est la capitale de la France ? » aussi précisément qu'un modèle phare, mais pas une question juridique complexe. La clé est d'utiliser intelligence de routage de la passerelle pour décider quand une précision optimale en vaut le prix. Transférez les tâches quotidiennes vers des modèles plus petits et réservez les modèles haut de gamme aux raisonnements complexes. Au fil du temps, les analyses permettent d'affiner ces seuils en trouvant le juste équilibre entre une précision acceptable et des économies de coûts substantielles.
Coût par rapport à la latence : Les modèles les moins chers fournissent également souvent des réponses plus rapides, en particulier lorsqu'ils sont hébergés localement. Cependant, un routage multimodèle naïf peut introduire une latence si le système essaie un modèle, puis revient à un autre. La passerelle de TrueFoundry atténue ce problème avec routage basé sur la latence et sensible à la charge, en veillant à ce que les demandes soient acheminées vers le modèle viable le plus rapide sans sauts inutiles. Son architecture n'ajoute que quelques millisecondes de temps (environ 3 à 4 ms par demande), ce qui est négligeable par rapport aux temps d'inférence des modèles, ce qui permet aux équipes de gagner en efficacité sans compromettre l'expérience utilisateur.
Coût par rapport à la complexité architecturale : L'ajout d'une passerelle IA introduit une couche d'infrastructure supplémentaire, mais offre également une visibilité, des garanties et une fiabilité qui font défaut aux configurations à modèle unique. Pour les petites équipes ou les prototypes, des appels de modèles directs peuvent suffire. Mais à mesure que l'utilisation augmente, la centralisation du routage, de la mise en cache et de la gouvernance des coûts devient essentielle.
En fin de compte, l'équilibre entre ces facteurs est un exercice permanent. La meilleure pratique consiste à surveiller en permanence l'impact de vos mesures d'économie sur la qualité de sortie du modèle et l'expérience utilisateur (ce que l'observabilité de la passerelle facilite), et à ajuster les boutons (règles de routage, paramètres de cache, etc.) en conséquence. La beauté de l'approche de passerelle IA réside dans le fait que vous avoir ces boutons à tourner : vous n'êtes pas limité à une utilisation universelle du modèle. Vous pouvez augmenter ou diminuer les dépenses dans certains domaines tout en préservant ce qui compte le plus pour votre demande, qu'il s'agisse du temps de réponse ou de la précision des réponses.
Meilleures pratiques pour l'optimisation des coûts de LLM à l'aide d'une passerelle
Pour tirer le meilleur parti d'une passerelle d'IA, les organisations doivent associer la technologie à des stratégies d'utilisation judicieuses. Voici quelques bonnes pratiques pratiques pour optimiser les coûts de LLM tout en maintenant les performances :
1. Optimisez les invites et les sorties. Supprimez les jetons inutiles et concentrez-vous sur les invites. Des instructions trop longues ou trop verbeuses gaspillent des jetons. Les formats structurés, tels que les puces ou les schémas JSON, garantissent la concision et la prévisibilité des réponses. Passez en revue et raccourcissez les instructions contextuelles courantes qui sont ajoutées à chaque appel. Cette optimisation « à coût zéro » réduit directement les dépenses.
2. Utilisez le routage par modèle hybride. Adoptez une stratégie de modèle à plusieurs niveaux : acheminez les requêtes simples ou à faible enjeu vers des modèles plus petits et moins coûteux, et les requêtes complexes vers des modèles haut de gamme. De nombreuses équipes suivent un schéma 90/10 : 90 % du trafic est dirigé vers des modèles rapides et peu coûteux et 10 % vers des modèles de haute qualité pour les tâches critiques. La passerelle de TrueFoundry automatise cela grâce à un routage basé sur des règles ou basé sur le ML, ce qui vous permet de ne jamais payer trop cher pour des fonctionnalités dont vous n'avez pas besoin.
3. Appels par lots et parallélisation. Lorsque vous payez par jeton ou par appel, réduisez les frais généraux en regroupant plusieurs invites en une seule demande. L'API d'inférence par lots de TrueFoundry vous permet de regrouper les tâches connexes, ce qui est idéal pour les tâches périodiques telles que la synthèse de grands ensembles de documents. Dans certains cas, des demandes parallèles peuvent être envoyées à la fois à des modèles bon marché et coûteux, en annulant le modèle le plus coûteux si le premier donne un résultat satisfaisant.
4. Mettez en cache les requêtes à haute fréquence. Réutilisez les résultats au lieu de les recalculer. La passerelle prend en charge à la fois la correspondance exacte et la mise en cache sémantique, où des invites similaires peuvent réutiliser les réponses précédentes. Même un faible taux d'accès au cache peut permettre d'économiser d'importantes dépenses en jetons tout en améliorant la latence, ce qui constitue un avantage majeur pour les flux de travail répétés ou les requêtes courantes.
5. Affinez ou spécialisez les modèles. Pour les tâches répétitives spécifiques à un domaine, le réglage fin d'un modèle plus petit ou l'intégration du RAG (génération augmentée par extraction) peuvent raccourcir les invites et réduire le nombre de jetons. La plateforme TrueFoundry permet de peaufiner et de personnaliser le déploiement, aidant ainsi les équipes à trouver un équilibre entre précision et efficacité à grande échelle.
6. Tirez parti de modèles open source ou auto-hébergés. En cas de volumes élevés, il peut être moins coûteux d'héberger des modèles open weight sur des GPU dédiés plutôt que de payer par appel d'API. La passerelle permet un déploiement hybride fluide, en acheminant une partie du trafic vers des modèles auto-hébergés tout en maintenant une journalisation unifiée et des contrôles de politique. Cette configuration hybride peut permettre de réaliser des économies substantielles tout en préservant la flexibilité.
En plus de ces pratiques, toujours
surveiller et itérer
. Utilisez les données de la passerelle pour identifier les stratégies qui ont le plus d'impact (par exemple, les taux d'accès au cache, les jetons enregistrés par le routage, etc.) et ajustez-les en conséquence. L'optimisation des coûts n'est pas un processus ponctuel, mais la passerelle vous fournit les outils nécessaires pour en faire un effort continu et gérable plutôt qu'une surprise de lutte contre les incendies.
L'approche de TrueFoundry en matière de suivi des coûts et de gouvernance
Bien que l'optimisation des coûts constitue un défi universel pour les déploiements de LLM, Passerelle IA de TrueFoundry en fait un processus structuré, mesurable et continu. Au lieu de s'appuyer sur une budgétisation manuelle ou des rapports de coûts éparpillés, TrueFoundry intègre la gouvernance directement dans la couche d'infrastructure, garantissant ainsi que chaque interaction avec l'IA est enregistrée, facturée et attribuée en temps réel. Cette infrastructure unifiée permet de structurer Solution de suivi des coûts LLM, permettant aux entreprises de suivre les dépenses au niveau du modèle, de l'équipe et du flux de travail en toute transparence.
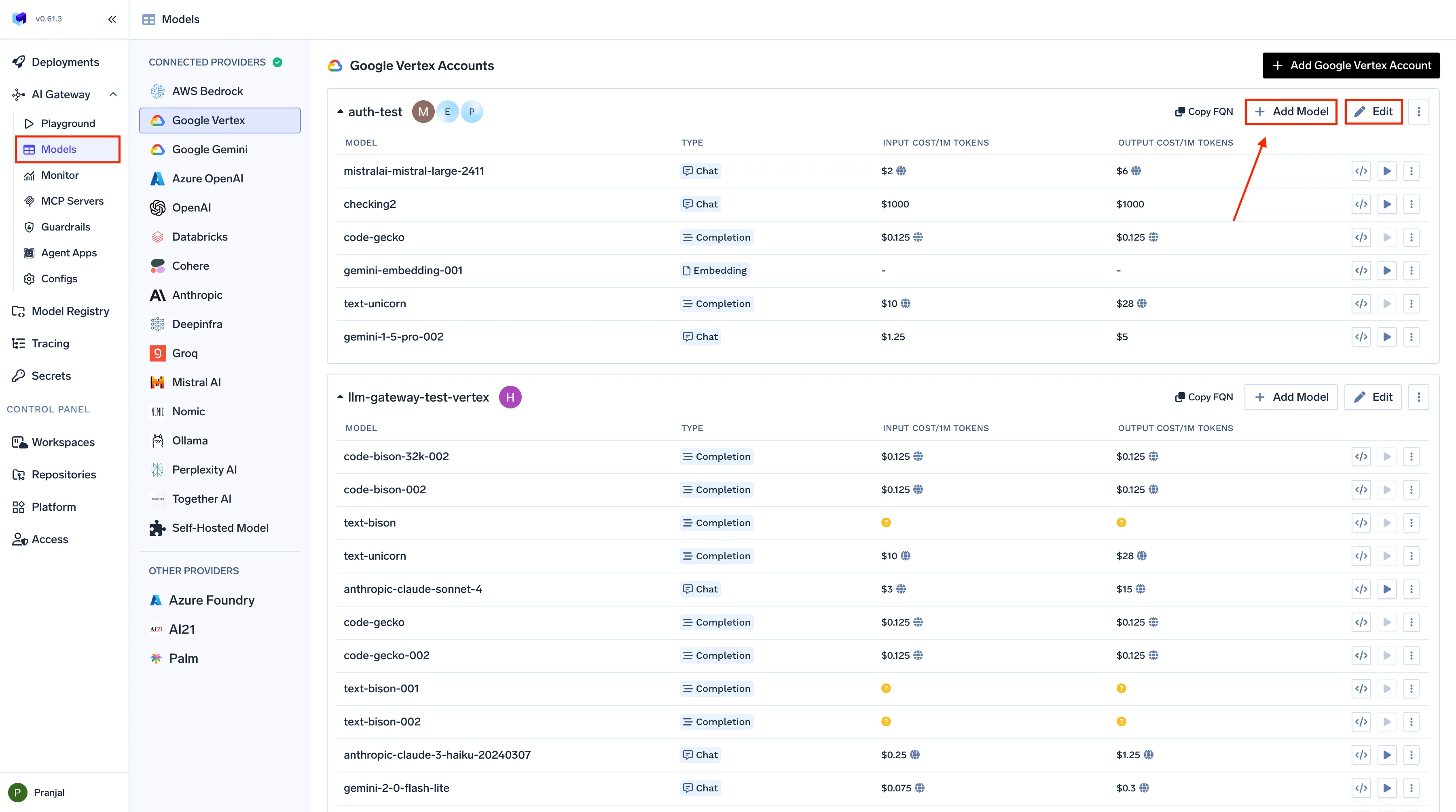
Interface de configuration des coûts des modèles de TrueFoundry
1. Attribution des coûts en temps réel
Chaque demande qui passe par la passerelle de TrueFoundry est automatique étiqueté et évalué. Le système combine le nombre de jetons d'entrée/sortie avec données de tarification spécifiques au modèle, qu'il s'agisse d'API publiques ou de tarifs négociés par l'entreprise, pour calculer le coût exact par inférence. Les équipes peuvent filtrer ces indicateurs par modèle, équipe, environnement ou utilisateur, offrant une visibilité précise sur les utilisateurs qui dépensent ou sur les dépenses. Cela permet de répartir facilement les coûts, d'effectuer des rétrofacturations internes ou de justifier le retour sur investissement des fonctionnalités d'IA.
2. Modèle de tarification et de budgets configurables
TrueFoundry permet aux entreprises de définir tarification personnalisée par modèle, en alignant le suivi interne sur les contrats réels des fournisseurs ou les coûts de calcul auto-hébergés. Les administrateurs peuvent également créer seuils ou quotas budgétaires pour chaque application ou environnement. Lorsque les dépenses dépassent une limite définie, la passerelle peut déclencher des alertes automatisées ou même appliquer une limitation temporaire afin de limiter les coûts sans intervention manuelle.
3. Observabilité intégrée
TrueFoundry exporte les données de coût et d'utilisation vers Prometheus et OpenTelemetry, en s'intégrant parfaitement aux pipelines de surveillance existants. Cela permet aux mesures de coût, de latence et de fiabilité de l'IA d'apparaître dans les mêmes tableaux de bord que ceux utilisés pour la surveillance de l'infrastructure et des applications. Le résultat est un panneau de verre unique où les équipes d'ingénierie, des finances et des produits partagent une vision unifiée des performances et des dépenses.
4. Gouvernance dès la conception
Parce que chaque appel inclut balisage des métadonnées (équipe, projet et environnement), les organisations peuvent mettre en œuvre une responsabilisation structurée entre les départements. Combiné avec contrôle d'accès basé sur les rôles (RBAC) et des autorisations au niveau du modèle, cela garantit que les modèles coûteux ou à haut risque ne sont accessibles qu'aux équipes approuvées. Ces garde-fous garantissent la conformité, la discipline budgétaire et la transparence automatique, pas manuel.
Quand une passerelle IA n'est peut-être pas justifiée
Les passerelles IA offrent une valeur considérable à grande échelle, mais toutes les organisations n'en ont pas besoin immédiatement. Pour les petites équipes ou les projets en phase de démarrage utilisant un modèle unique et de faibles volumes de demandes, le déploiement d'une passerelle complète peut représenter une surcharge inutile. Un prototype appelant un modèle OpenAI avec quelques milliers de jetons par jour peut être géré facilement grâce à des appels d'API directs et à une surveillance de base.
Les directives du secteur suggèrent que lorsque l'utilisation est limitée (des dizaines de milliers de jetons par mois) et que les besoins de conformité ou de fiabilité sont minimes, un proxy léger ou un suivi manuel peuvent suffire. Le véritable avantage de la passerelle apparaît à mesure que les charges de travail évoluent ou se diversifient selon les modèles et les fournisseurs. Si votre organisation expérimente encore les LLM ou dispose d'une infrastructure minimale, concentrez-vous d'abord sur l'itération, mais planifiez à l'avance. La passerelle de TrueFoundry, par exemple, peut être réduite efficacement, offrant une visibilité et une gouvernance précoces sans configuration lourde. Bref, évaluez votre Maturité et évolutivité de l'IA: pour les cas d'utilisation à modèle unique et à faible volume, une passerelle peut s'avérer prématurée ; à mesure que l'adoption se développe, elle devient rapidement essentielle pour le contrôle des coûts, la fiabilité et la gouvernance à long terme.
Conclusion
Le contrôle des coûts de LLM dans les environnements d'entreprise est complexe, mais les passerelles AI sont conçues pour résoudre exactement cela. Au lieu de laisser les coûts au hasard, une passerelle comme TrueFoundry intègre la gouvernance des coûts directement dans votre architecture d'IA. Grâce à un suivi centralisé, à des garde-fous en matière de budgétisation, à un routage intelligent et à une mise en cache, il fait du contrôle des coûts une fonctionnalité intégrée plutôt qu'une fonction secondaire.
Rapport sur les entreprises utilisant des passerelles IA 40 à 60 % de réduction des coûts d'inférence, ainsi qu'une fiabilité et une sécurité accrues. La passerelle de TrueFoundry, en particulier, fournit la responsabilité dès la conception — en offrant aux équipes une visibilité précise, une attribution des coûts et des rétrofacturations — et réduction des risques à grande échelle via des limites automatisées et des dispositifs de sécurité intégrés. Il fournit également transparence totale dans les modèles d'utilisation afin qu'aucun problème de coût ou de latence ne passe inaperçu.
En unifiant les politiques entre les régions et les équipes, la passerelle garantit une gouvernance et une conformité cohérentes, essentielles pour les secteurs qui traitent des données sensibles. Résultat : les projets d'IA passent de l'expérimentation à la production avec des dépenses prévisibles et une confiance opérationnelle.
En bref, les passerelles AI permettent de pérenniser l'adoption du LLM. La tarification basée sur les jetons peut être imprévisible, mais grâce au plan de contrôle centralisé de TrueFoundry, les entreprises peuvent optimiser leurs dépenses, appliquer des garde-fous et évoluer de manière responsable. C'est ainsi que l'innovation et la discipline fiscale coexistent, transformant l'IA en une capacité gouvernée, efficace et prête à être utilisée par les entreprises.
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.
Conçu pour la vitesse : latence d'environ 10 ms, même en cas de charge






























.png)

.webp)
.webp)
.webp)



.webp)
.webp)


