

October 5, 2023
|
5 min de lecture


Accédez instantanément à un environnement TrueFoundry en direct. Déployez des modèles, acheminez le trafic LLM et explorez la plateforme complète : votre sandbox est prête en quelques secondes, aucune carte de crédit n'est requise.









Published: April 22, 2026

Une méthode incroyablement rapide pour créer, suivre et déployer vos modèles !
Les entreprises qui créent des applications GenAI sont confrontées à un compromis bien connu : le cloud pur accélère l'expérimentation mais soulève des problèmes de gouvernance et de coûts, tandis que le cloud purement sur site renforce le contrôle mais ralentit les équipes. L'approche hybride de TrueFoundry équilibre les deux en combinant une architecture à plans divisés, des opérations natives de Kubernetes et une passerelle d'intelligence artificielle qui centralise la gouvernance, le routage et l'observabilité.
- Préservez la confidentialité des données sensibles tout en restant flexible. Exécutez des bases de données vectorielles, des intégrations, des artefacts et des services de modèles de base dans vos environnements privés (sur site ou VPC), et utilisez des points de terminaison cloud lorsque vous avez besoin d'élasticité.
- Standardisez l'accès aux modèles. L'AI Gateway extrait les fournisseurs afin que les équipes puissent changer ou mélanger les points de terminaison sans refactoriser.
- Appliquez la gouvernance sans ralentir les développeurs. Les politiques centralisées en matière d'authentification, de limites de débit et de coûts permettent aux équipes chargées de la plateforme et de la sécurité de définir des garde-fous pendant que les développeurs continuent à expédier.
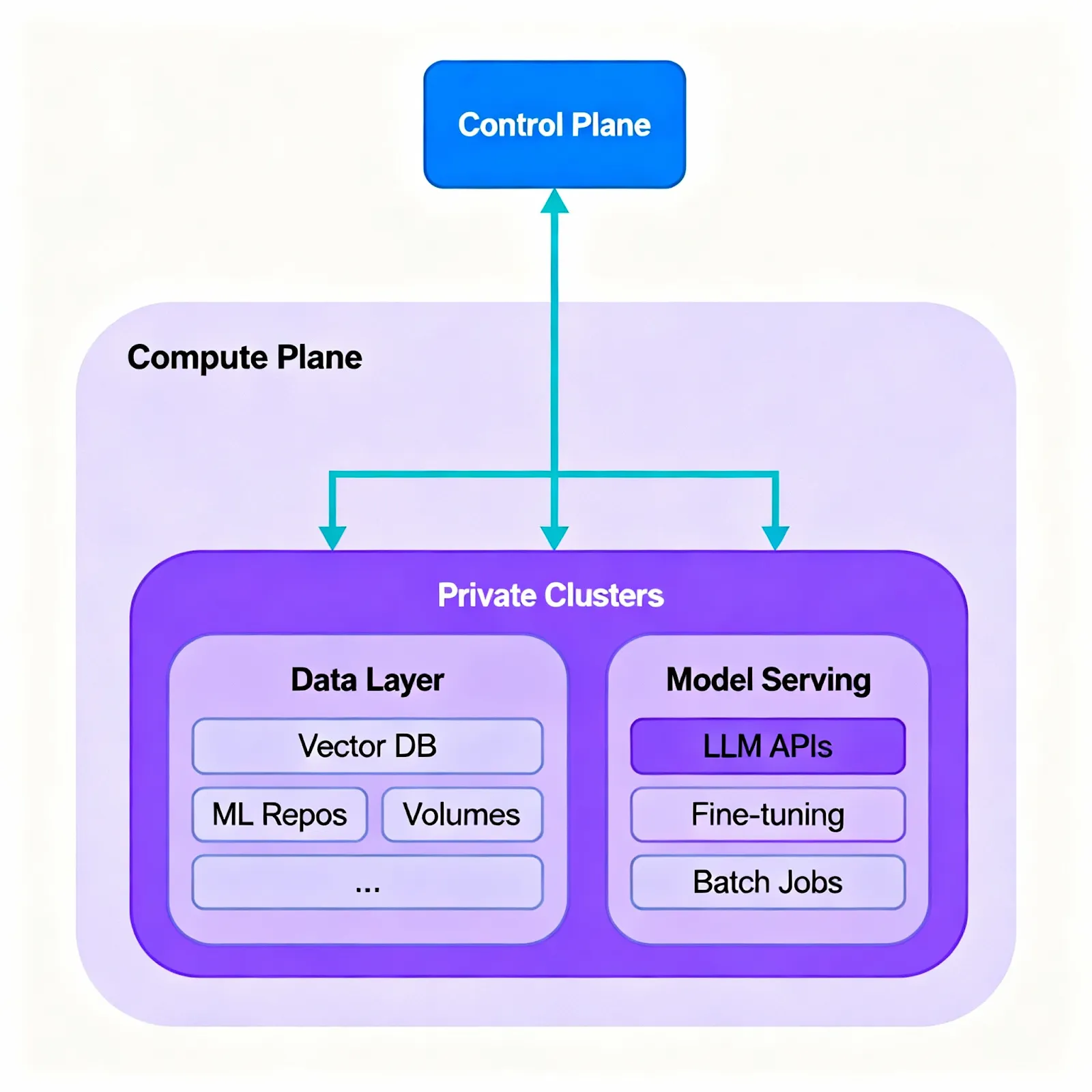
- Plan de contrôle/plan de calcul partagé : utilisez un plan de contrôle hébergé ou auto-hébergé pour l'orchestration, les politiques et l'observabilité ; exécutez des plans de calcul dans des clusters privés (sur site ou VPC) où se trouvent les charges de travail et les données. Ce découplage permet des opérations cohérentes dans tous les environnements.
- Opérations natives de Kubernetes : déployez des services et des jobs via YAML/CLI ; utilisez des sondes de santé, une mise à l'échelle automatique et des stratégies de déploiement standardisées sur les clusters ; adoptez des promotions en forme de canari et bleu/vert pour réduire les risques ; mettez en pause ou réduisez les piles inactives pour économiser les ressources.
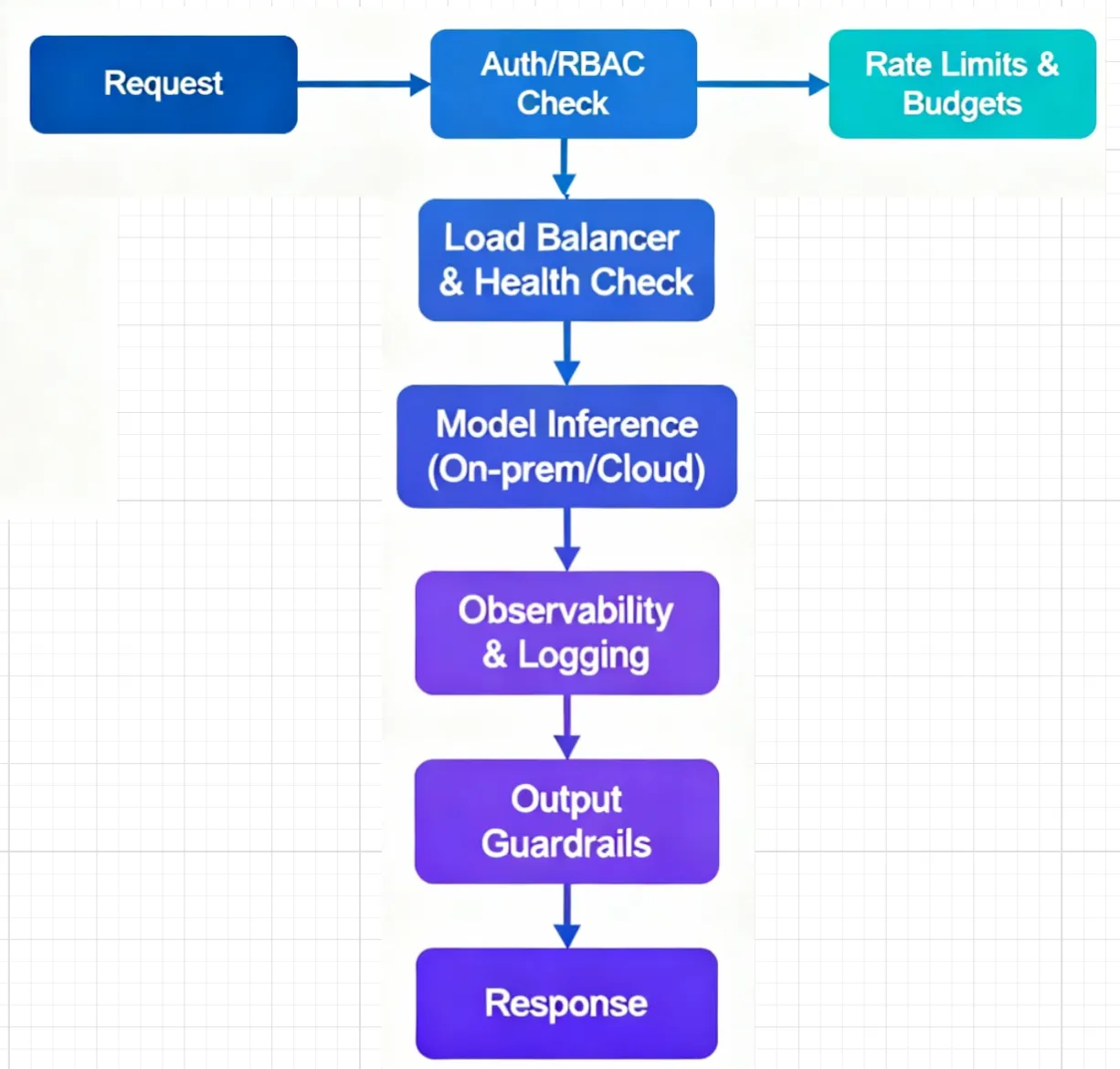
- Authentification et RBAC : centralisez les clés, intégrez le SSO et délimitez l'accès par projet/équipe pour éviter la prolifération des informations d'identification.
- Quotas et budgets tenant compte des jetons : définissez des limites qui reflètent l'utilisation du LLM (demandes et jetons), appliquées par utilisateur, équipe ou modèle.
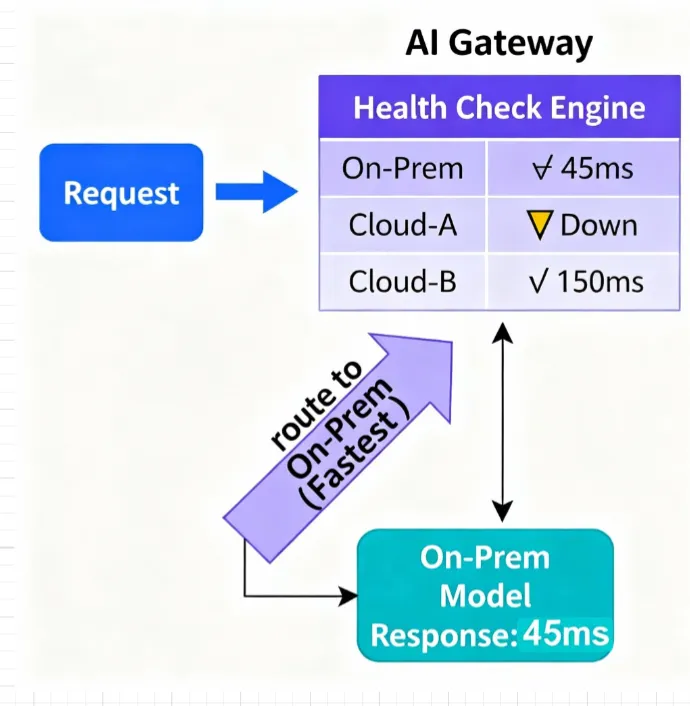
- Routage multifournisseur : acheminez le trafic par poids pour les expériences, préférez des terminaux sains plus rapides en termes de latence et de santé, et basculez automatiquement lorsqu'un point de terminaison est défectueux.
- Observabilité et suivi des coûts : suivez les demandes de bout en bout, comparez le comportement des fournisseurs et des modèles dans tous les environnements, et attribuez l'utilisation aux équipes et aux applications.
- Garde-corps : appliquez des contrôles d'entrée/sortie pour aligner les instructions et les réponses sur les politiques de l'entreprise.
- Configurez un cluster privé (sur site ou VPC).
- Connectez le SSO et les secrets.
- Déployez un service d'API simple et enregistrez un modèle derrière AI Gateway ; validez le routage, les journaux et les traces.
- Acheminez les applications existantes via la passerelle.
- Activez le RBAC, les quotas/budgets tenant compte des jetons et les tableaux de bord d'observabilité partagés.
- Supprimez les informations d'identification des fournisseurs codées en dur des applications ; gérez-les de manière centralisée.
- Hébergez des bases de données vectorielles, des intégrations et des artefacts dans votre environnement privé.
- Servez des modèles critiques sur preme/VPC pour les flux principaux ; continuez à utiliser des points de terminaison cloud pour les débordements ou effectuez des expériences via le routage par passerelle.
- Ajoutez des clusters de mise en scène et de production sur tous les sites/clouds.
- Utilisez les promotions canaries/bleu-vert, redimensionnez automatiquement en fonction du trafic et mettez en pause les environnements inactifs le cas échéant.
- Comparez le comportement sur site et dans le cloud d'une personne à l'autre grâce à un traçage et à des mesures courants.
- Mise à l'échelle automatique et mise à l'échelle vers zéro : adaptez la capacité à la demande d'API, de travailleurs et de tâches par lots.
- Routage basé sur des règles : dirigez le trafic vers les terminaux qui respectent vos politiques de latence/SLA et de budget, avec une solution souple en cas d'erreur ou de limites de quota.
- Budgets et auditabilité centralisés : appliquez des limites par équipe/modèle et conservez une source de référence unique pour les clés, l'accès et l'utilisation.
- Déploiements plus sûrs : les stratégies Canary et bleu/vert réduisent le rayon d'explosion et permettent un retour en arrière rapide.
- Contrôles cohérents : les politiques, les secrets et les accès sont gérés de manière centralisée pendant que les développeurs déploient le self-service.
- Télémétrie unifiée : les journaux, les mesures et les traces regroupés en un seul endroit accélèrent le débogage, la planification des capacités et les évaluations des coûts.
- Le même flux de travail partout : le modèle Kubernetes-first permet d'aligner le développement, le staging et la production sur site et dans le cloud.
- « Servez et adaptez » rapidement pour les API et les travailleurs à l'aide de modèles et de flux CLI/YAML.
- Observabilité intégrée qui raccourcit les cycles de feedback.
- Des modèles réutilisables pour les charges de travail GenAI courantes (par exemple, les pipelines RAG, les API de chat, le traitement asynchrone), afin que les équipes puissent expédier sans réinventer l'infrastructure.
- Jours 1 et 2 : création d'un plan de calcul privé, câblage SSO/Secrets, déploiement d'une petite API et d'un modèle derrière la passerelle, et confirmation du flux des demandes grâce au traçage.
- Jours 3 à 5 : acheminez une application existante via la passerelle, activez des quotas et des tableaux de bord tenant compte des jetons, et standardisez les informations d'identification des fournisseurs de manière centralisée.
- Semaine 2 : ajout d'un deuxième environnement, introduction du routage Canary pour un terminal adjacent à la production et test des règles de mise à l'échelle automatique et de repli.
- Architecture AI Gateway : https://www.truefoundry.com/blog/how-to-think-about-ai-gateway-architecture-in-the-generative-ai-stack
- Plateformes d'IA sur site : https://www.truefoundry.com/blog/on-premise-ai-platform
- Stratégies d'équilibrage de charge : https://www.truefoundry.com/blog/load-balancing-in-ai-gateway
- Meilleures pratiques en matière de limitation des débits : https://www.truefoundry.com/blog/rate-limiting-in-llm-gateway
- Mise en œuvre de garde-corps IA : https://www.truefoundry.com/blog/ai-guardrails-in-enterprise- Modèles d'observabilité : https://www.truefoundry.com/blog/observability-in-ai-gateway
TrueFoundry AI Gateway offre une latence d'environ 3 à 4 ms, gère plus de 350 RPS sur 1 processeur virtuel, évolue horizontalement facilement et est prête pour la production, tandis que LiteLM souffre d'une latence élevée, peine à dépasser un RPS modéré, ne dispose pas d'une mise à l'échelle intégrée et convient parfaitement aux charges de travail légères ou aux prototypes.











Les dernières nouvelles, articles et ressources envoyés dans votre boîte de réception








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


