

October 5, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: May 29, 2026
¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Los grandes modelos lingüísticos como ChatGPT y los modelos de difusión como Stable Diffusion han conquistado el mundo en poco menos de un año. Cada vez son más las organizaciones que están empezando a aprovechar la IA generativa para sus nuevos e interesantes casos de uso actuales. Si bien la mayoría de las empresas pueden empezar a utilizar directamente las API proporcionadas por empresas como OpenAI, Anthropic, Cohere, etc., estas API también tienen un coste elevado. A largo plazo, a muchas empresas les gustaría perfeccionar las versiones pequeñas y medianas de LLM equivalentes de código abierto, como Llama, Flan-T5, FLAN-UL2, GTP-neo, OPT, Bloom, etc., como Alpaca y GPT4 todo los proyectos lo hicieron.
Ajustar los modelos más pequeños con salidas de modelos más grandes puede resultar útil de varias maneras:
Para posibilitar todo esto, las GPU se han convertido en un elemento esencial para cualquier empresa que trabaje con estos modelos fundamentales. Con el aumento del tamaño de los modelos y alcanzando billones de parámetros distribuidos, el entrenamiento en varias GPU se está convirtiendo poco a poco en la nueva norma. Nvidia lidera el mercado del hardware con sus nuevas tarjetas de las series Ampere y Hopper. La interconexión NVLink e Infiniband de alta velocidad permite conectar hasta 256 Nvidia A100 o Nvidia H100 (y alrededor de 4 000 en clústeres de supercápsulas) para entrenar e inferir con modelos cada vez más grandes en tiempos récord.
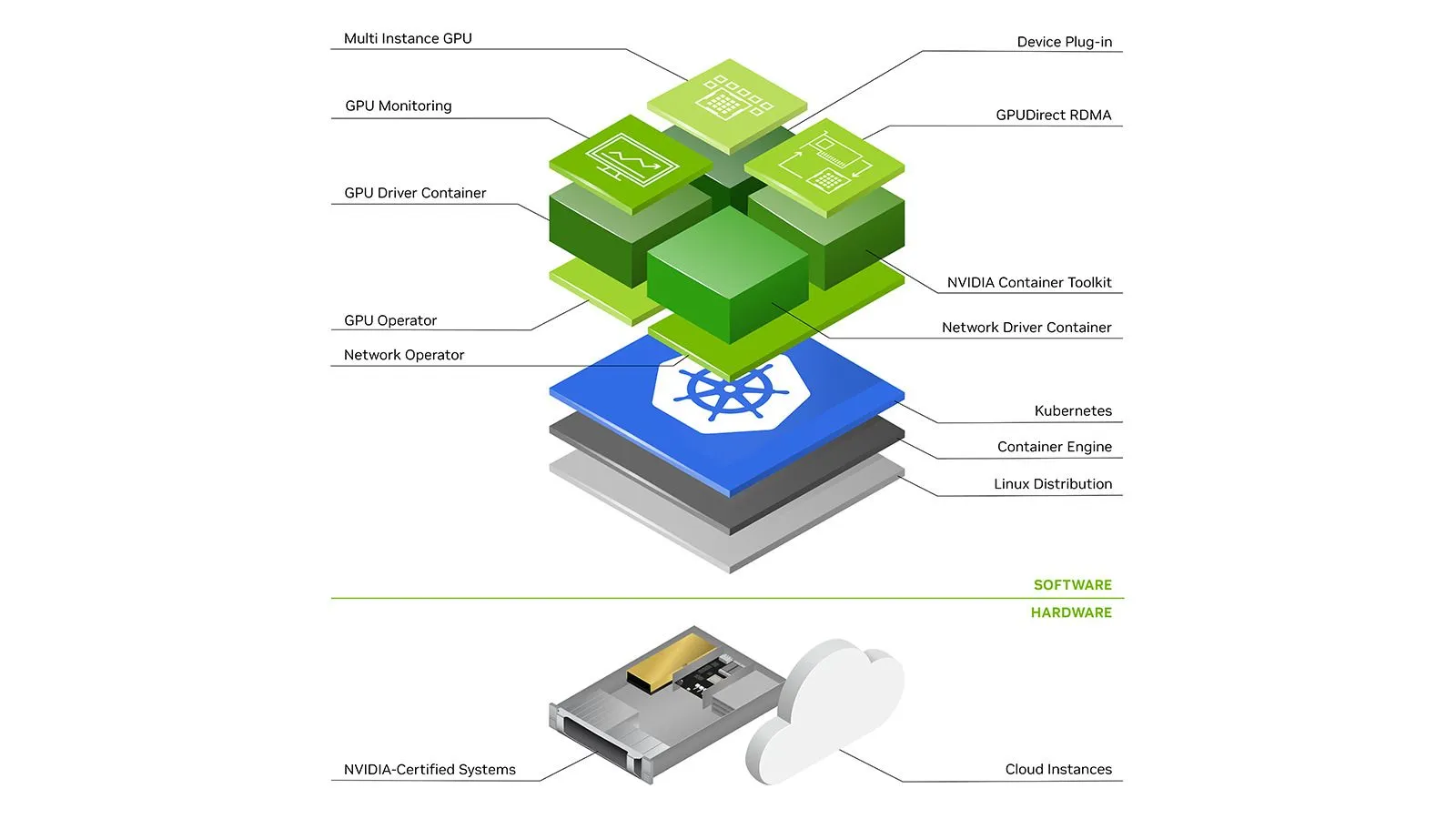
Ahora repasaremos los componentes necesarios para usar las GPU con Kubernetes, principalmente en AWS EKS y GCP GKE (estándar o piloto automático), pero los componentes mencionados son esenciales en cualquier clúster de K8s.
Su proveedor de nube tiene máquinas virtuales con GPU, ¿cómo las incorporamos al clúster K8s? Una forma es configurar manualmente grupos de nodos de GPU de tamaño fijo o con escalador automático de clústeres que puede incorporar nodos de GPU cuando sea necesario y soltarlos cuando no. Sin embargo, esto aún requiere la configuración manual de varios grupos de nodos diferentes. Una solución aún mejor es configurar sistemas de aprovisionamiento automático como Carpintero de AWS o Aprovisionadores automáticos de nodos de GCP. Hablamos de ellos en nuestro artículo anterior: Escalado automático de clústeres para Big 3 Clouds ☁️
Versión de API: karpenter.sh/v1alpha5
tipo: Aprovisionador
metadatos:
nombre: gpu-provisioner
espacio de nombres: karpenter
especificación:
peso: 10
Configuración de Kubelet:
Número máximo de Pods: 110
límites:
recursos:
CPU: «500"
requisitos:
- clave: karpenter.sh/∙ type
operador: En
valores:
- punto
- a pedido
- clave: topology.kubernetes.io/zone
operador: En
valores:
- ap-sur-1
- clave: karpenter.k8s.aws/instance-family
operador: En
valores:
- mp3
- p4
- p5
- g4dn
- 5 g
contaminaciones:
- clave: «nvidia.com/gpu»
efecto: «NoSchedule»
Referencia del proveedor:
nombre: predeterminado
TTL segundos después de estar vacío: 30
Ejemplo de configuración del aprovisionador automático de nodos de GCP
Límites de recursos:
- Tipo de recurso: 'cpu'
mínimo: 0
máximo: 1000
- ResourceType: 'memoria'
mínimo: 0
máximo: 10000
- Tipo de recurso: 'nvidia-tesla-v100'
mínimo: 0
máximo: 4
- Tipo de recurso: 'nvidia-tesla-t4'
mínimo: 0
máximo: 4
- Tipo de recurso: 'nvidia-tesla-a100'
mínimo: 0
máximo: 4
Ubicaciones de aprovisionamiento automático:
- us-central1-c
gestión:
AutoRepair: cierto
Actualización automática: verdadero
Configuración de instancia protegida:
EnableSecureBoot: verdadero
EnableIntegrityMonitoring: verdadero
Tamaño del disco GB: 100
Tenga en cuenta que aquí también podemos configurar nuestros aprovisionadores para que usen lugar escriba instancias para ahorrar entre un 30 y un 90% en aplicaciones sin estado.
Para que cualquier máquina virtual utilice GPU, sus controladores deben estar instalados en el host. Afortunadamente, tanto en AWS EKS como en GCP, los nodos GKE están preconfigurados con ciertas versiones de los controladores de Nvidia.
Porque cada la versión más reciente de CUDA requiere una versión de controlador mínima más alta, es posible que incluso desee controlar la versión del controlador para todos los nodos. Esto se puede hacer aprovisionando los nodos con imágenes personalizadas que no tengan el controlador y permitiendo que Nvidia operador de GPU instalar una versión especificada. Sin embargo, es posible que esto no esté permitido en todos los proveedores de nube, así que ten en cuenta las versiones de los controladores de tus nodos para evitar problemas de compatibilidad.
Hablamos de la operador de GPU más adelante, más adelante.
En Kubernetes, dado que todo funciona dentro de pods (un conjunto de contenedores), no basta con instalar los controladores en el host. Nvidia proporciona un componente independiente llamado kit de herramientas para contenedores nvidia que instala ganchos para contenedor Ejecutar C para que los controladores y dispositivos de GPU del host estén disponibles para los contenedores que se ejecutan en el nodo. Consulta este artículo para obtener una explicación más detallada.
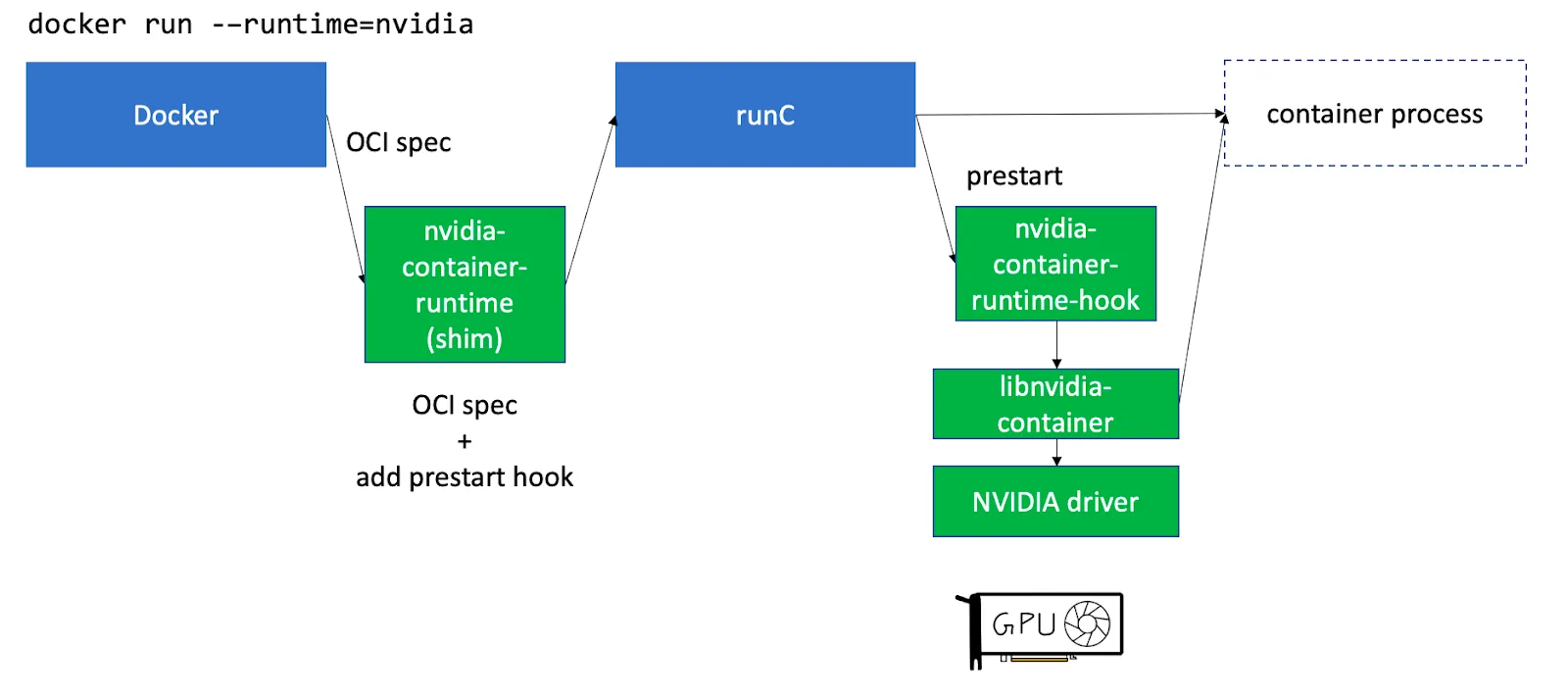
kit de herramientas para contenedores nvidia se puede instalar para ejecutarse como Daemonset en los nodos de la GPU.
Tener GPU en el nodo no es suficiente, el programador de Kubernetes necesita saber qué nodo tiene cuántas GPU disponibles. Esto se puede hacer usando un Plugin de dispositivo. Un complemento de dispositivo permite anunciar recursos de hardware personalizados en el plano de control, p. ej. nvidia.com/gpu . Nvidia ha publicado un complemento de dispositivo que anuncia las GPU asignables en un nodo. De nuevo, este complemento se puede ejecutar como un Daemonset.
Una vez configurados los componentes anteriores, necesitamos añadir algunas cosas a la especificación del pod para programarlo en el nodo GPU, principalmente recursos , afinidad y tolerancias
Por ejemplo, en GCP GKE podemos hacer lo siguiente:
especificación:
# Definimos cuántas GPU queremos para el pod
recursos:
límites:
nvidia.com/gpu: 2
# las afinidades nos ayudan a colocar el pod en los nodos de la GPU
afinidad:
Afinidad de nodo:
Necesario durante la programación Se ignora durante la ejecución:
Términos del selector de nodos:
- Expresiones coincidentes:
# Especifique qué familia de instancias queremos
- operador: En
clave: cloud.google.com/machine-family
valores:
- a2
# Especifique qué tipo de GPU queremos
- operador: En
clave: cloud.google.com/gke-accelerator
valores:
- nvidia-tesla-a100
# Especifique que queremos una máquina virtual puntual
- operador: En
clave: cloud.google.com/gke-Spot
valores:
- «cierto»
tolerancias:
# Las máquinas virtuales puntuales tienen una mancha, por lo que mencionamos una tolerancia
- clave: cloud.google.com/gke-Spot
operador: igual
valor: «verdadero»
efecto: NoSchedule
# Manchamos los nodos de la GPU, por lo que mencionamos una tolerancia
- clave: nvidia.com/gpu
operador: Existe
efecto: NoSchedule
recursos.límites secciónTen en cuenta que estas configuraciones variarán según los métodos de aprovisionamiento y los proveedores de nube que utilices (por ejemplo, Karpenter en AWS o NAP en GKE)
Supervisar las métricas de la GPU, como la utilización, el uso de la memoria, el consumo de energía, la temperatura, etc., es importante para garantizar que todo funcione sin problemas y para realizar más optimizaciones.
Afortunadamente, Nvidia tiene un componente llamado exportador dcgm- que puede ejecutarse como Daemonset en los nodos de la GPU y publicar métricas en un punto final. Luego, estas métricas pueden ser extraídas con Prometheus y consumidas. Este es un ejemplo de configuración de scrape:
- nombre_trabajo: gpu-metrics
scrape_interval: 15 s
scrape_timeout: 10 s
metrics_path: /metrics
esquema: http
kubernetes_sd_configs:
- rol: puntos finales
espacios de nombres:
nombres:
- <dcgm-exporter-namespace-here>
relabel_configs:
- etiquetas_fuente: [__meta_kubernetes_pod_node_name]
acción: reemplazar
etiqueta_objetivo: kubernetes_node
Sin embargo, tenga en cuenta que exportador dcgm- necesita funcionar con HostIPC: verdadero y privilegiados Contexto de seguridad. Esto está bien para EKS y GKE Standard. Sin embargo, el piloto automático de GKE no permite ese acceso, sino GKE publica métricas en el preconfigurado complemento de dispositivo nvidia Conjuntos de demonios que se pueden extraer o ver en GCP Cloud Monitoring.
AWS EKSGCP GKE StandardGCP GKE AutoPilotProvisioningKarpenter//ManualGCP Node Auto ProvisioningDrivers/ManualAuto ProvisioningDriversPreinstalado/instalado mediante operador de GPUKit de herramientas de contenedores preinstaladokit de herramientas para contenedores nvidiavía operador de GPUPlugin de dispositivo preconfiguradocomplemento de dispositivo nvidiavía operador de GPUDaemonSetPreconfiguradoMétricas de DaemonSetPreconfiguradasexportador nvidia-dcgm+vía operador de GPUAutónomo exportador nvidia-dcgm+ /Raspado personalizadoRaspado personalizado
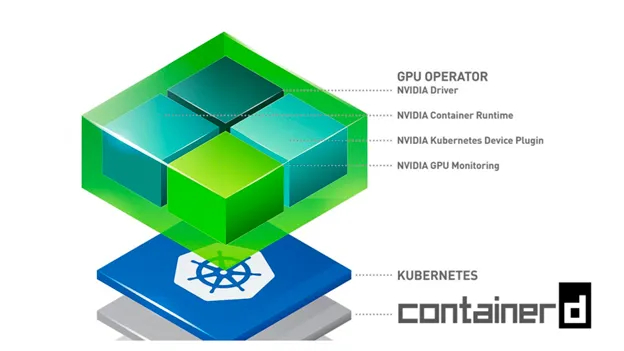
El operador de GPU mencionado anteriormente, en la mayor parte de AWS EKS hay un montón de componentes independientes de Nvidia, como controladores, contenedores, kits de herramientas, complementos de dispositivos y exportadores de métricas, entre otros, todos combinados y configurados para usarse juntos a través de un único gráfico de timón. El operador de GPU ejecuta un módulo maestro en el plano de control que puede detectar los nodos de GPU del clúster. Al detectar un nodo de GPU, implementa un daemonset de trabajo que, además, programa los pods para instalar, de forma opcional, los controladores, el kit de herramientas de contenedor, el complemento de dispositivo, el kit de herramientas CUDA, el exportador de métricas y los validadores. Puedes obtener más información al respecto aquí.
Por lo general, es posible tener el kit de herramientas CUDA instalado en la máquina host y ponerlo a disposición del módulo mediante el montaje por volumen, sin embargo, nos parece que esto puede resultar bastante frágil, ya que requiere jugar con CAMINO y LD_LIBRARY_PATH variables. Además, todos los pods del mismo nodo deben usar la misma versión del kit de herramientas CUDA, lo que puede resultar bastante restrictivo. Por lo tanto, es mejor colocar el kit de herramientas CUDA (o solo partes de él) dentro de la imagen del contenedor.
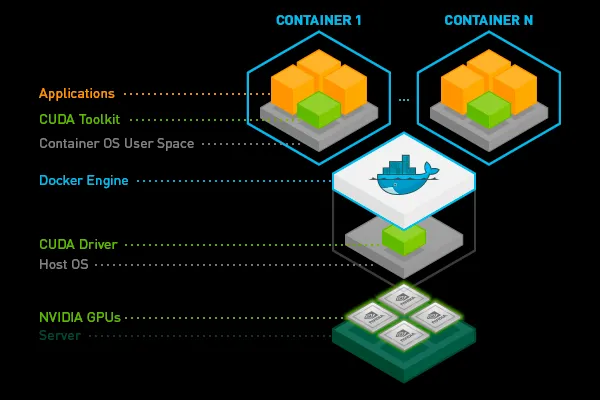
Puede partir de imágenes ya creadas proporcionadas por Nvidia o tu aprendizaje profundo favorito marco de referencia o agréguelo usando una línea en la plataforma Truefoundry
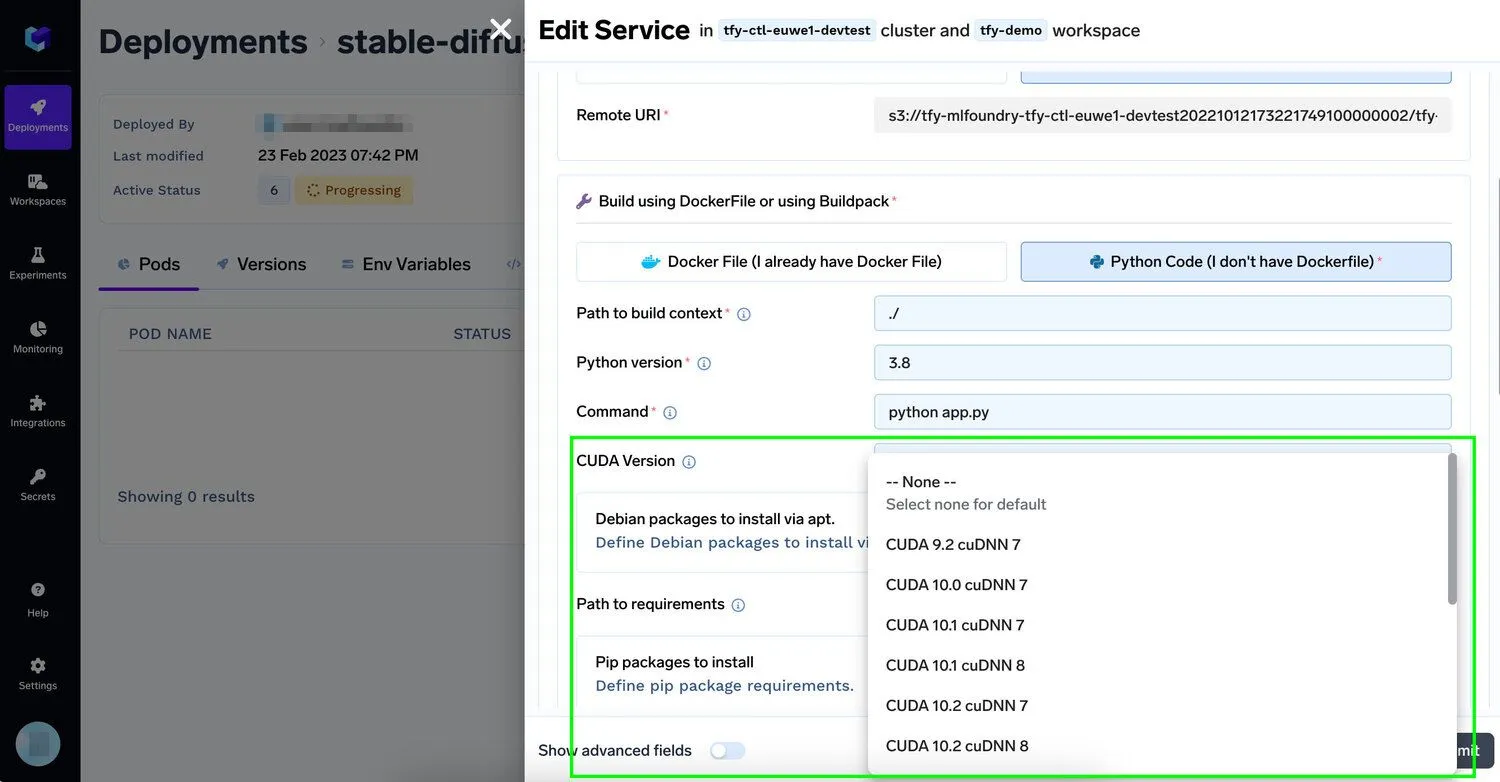
Para que las organizaciones puedan ajustar y distribuir sus modelos de IA generativa con mayor rapidez en su infraestructura actual, la plataforma TrueFoundry permite a los desarrolladores añadir una o más GPU de Nvidia a sus aplicaciones con un mínimo esfuerzo y, al mismo tiempo, admite los flujos de trabajo utilizados junto con mejores herramientas de ingeniería rápida. Los desarrolladores solo necesitan especificar cuántas instancias necesitan de algunas de las mejores GPU para el aprendizaje automático, como la V100, la A100 de 40 GB, la A100 de 80 GB (óptima para el entrenamiento) o la T4 y A10 (óptima para la inferencia), y nosotros nos encargamos del resto. Obtén más información en nuestra documentos. A medida que las cargas de trabajo de IA respaldadas por la GPU pasan a la producción, este tipo de control de la infraestructura también adquiere importancia para Plataformas de seguridad de IA, donde el aislamiento de la computación, la gobernanza del acceso y la observabilidad de la carga de trabajo deben trabajar en conjunto.
Las GPU son una tecnología fantástica y esto es solo el principio para nosotros. Estamos trabajando activamente en los siguientes problemas:
Si algo de esto suena emocionante, póngase en contacto con nosotros para trabajar con nosotros para crear la mejor plataforma de mLOps.
True Foundry es un PaaS de implementación de aprendizaje automático sobre Kubernetes para acelerar los flujos de trabajo de los desarrolladores y, al mismo tiempo, permitirles una flexibilidad total a la hora de probar e implementar modelos, al tiempo que garantiza una seguridad y un control totales para el equipo de Infra. A través de nuestra plataforma, permitimos a los equipos de aprendizaje automático implementar y supervisar modela en 15 minutos con un 100% de confiabilidad, escalabilidad y la capacidad de revertirse en segundos, lo que les permite ahorrar costos y lanzar los modelos a la producción más rápido, lo que permite obtener un verdadero valor empresarial.
Hable con nosotros sobre sus desafíos en el proceso de aprendizaje automático aquí
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


