
.webp)
July 3, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: May 21, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Stdio is fine for the developer laptop. Streamable HTTP is what enterprise deployments actually need. We walk through both transports — wire format, connection lifecycle, auth, audit, and benchmarks — and show what changes when an MCP estate scales past one user.
A Friday afternoon at Northwind. Six months after rolling out Cargo Copilot, Northwind's security lead asks the engineering team a routine audit question: which developers called the internal customer-data MCP tool in the last 30 days, and against which customer IDs? The team has every JSON-RPC message that ever crossed those tools — inside the stderr logs of every developer's local Cursor process. Spread across fifty laptops. With no shared timestamp source, no schema, and no way to correlate. The question takes a week to answer, and the answer is partial. The cause is not negligence. It is the transport choice they made six months ago.
Northwind started where most teams start: stdio MCP servers, one per developer machine. That is the right default for local experimentation — and the wrong default for everything else. This post explains why, with the specifics of the wire formats, the deployment models, and the migration path.
The MCP transport specification defines stdio in one paragraph: the client launches the server as a subprocess; the server reads JSON-RPC 2.0 messages from stdin and writes responses to stdout. Each message is one line of UTF-8 text terminated by a newline. The server may write logs to stderr; it MUST NOT write anything to stdout that is not a valid MCP message.
A single tool call from agent to server is one line of JSON:
Wire format — newline-delimited JSON-RPC over stdio
# stdin (client → server)
{"jsonrpc":"2.0","id":1,"method":"tools/call","params":{"name":"search_issues","arguments":{"query":"is:open label:critical"}}}
# stdout (server → client)
{"jsonrpc":"2.0","id":1,"result":{"content":[{"type":"text","text":"Found 3 issues..."}]}}The framing rules are simple but unforgiving. The MCP specification requires messages to be on a single line, so compliant servers escape any internal newline characters as \n during JSON serialization. What actually breaks framing in production is non-JSON contamination of stdout: a stray print() statement, an uncaught exception traceback, a debug log accidentally routed to stdout instead of stderr, or a server that forgets to flush stdout after each message. In all of these cases the client either sees a malformed message or waits forever for a response that has technically been written. Every MCP SDK ships with a stdio transport implementation precisely to make these edge cases someone else's problem.
What stdio gives you in exchange for those constraints is process isolation. The agent owns the server's lifecycle: when the agent exits, the OS reclaims the process. There is no network, no auth handshake, no firewall question. For local development, this is exactly what you want.
Streamable HTTP, introduced in MCP spec 2025-03-26 and retained in the November 2025 revision, replaces the older HTTP+SSE transport with a single-endpoint design. The server exposes one URL (e.g. /mcp) that accepts both POST and GET. Clients POST JSON-RPC messages; servers respond with either a single JSON body or upgrade to a Server-Sent Events stream for long-running calls. There is no separate "events" endpoint.
The client signals what it can accept; the server picks the response mode. Here is a tool call in HTTP form:
Wire format — Streamable HTTP, both response modes
POST /mcp HTTP/1.1
Content-Type: application/json
Accept: application/json, text/event-stream
Mcp-Session-Id: 1d3f...e7c2
Authorization: Bearer eyJhbGciOi...
{"jsonrpc":"2.0","id":1,"method":"tools/call","params":{"name":"search_issues",...}}
# --- Server response: short call returns plain JSON ---
HTTP/1.1 200 OK
Content-Type: application/json
{"jsonrpc":"2.0","id":1,"result":{"content":[...]}}
# --- Server response: long call upgrades to SSE ---
HTTP/1.1 200 OK
Content-Type: text/event-stream
event: message
data: {"jsonrpc":"2.0","method":"notifications/progress","params":{...}}
event: message
data: {"jsonrpc":"2.0","id":1,"result":{"content":[...]}}Three details matter operationally. The Mcp-Session-Id header binds requests to a session and is assigned by the server at initialization — it persists across pod restarts only if the server externalizes session state. The Accept header is mandatory: per the spec, clients MUST list both application/json and text/event-stream, and a compliant server may reject a missing or incomplete Accept with HTTP 406 Not Acceptable (per HTTP semantics; 415 Unsupported Media Type applies to incompatible Content-Type, not Accept). And per the spec's security section, servers MUST validate the Origin header on every connection to prevent DNS rebinding attacks against locally bound servers — a normative requirement, not a recommendation, with HTTP 403 Forbidden as the prescribed response to an invalid Origin.
The two transports model connections completely differently, and this is where the operational gap opens.
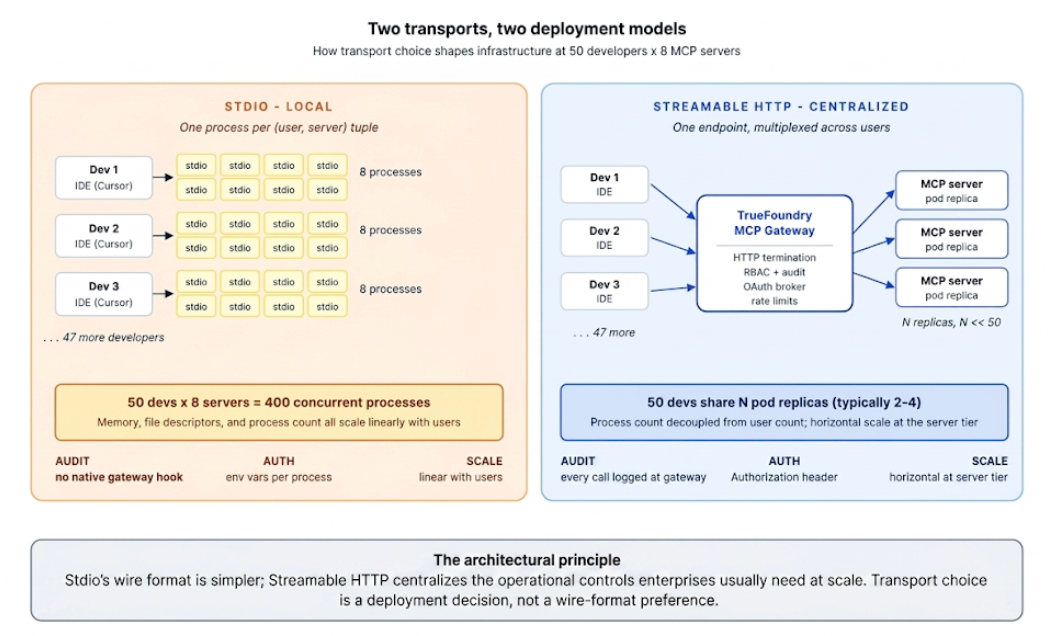
For a single developer working locally, stdio's process-per-connection model is a feature, not a bug — process isolation is free, and the cold start happens once when the IDE opens. The moment more than one user needs the server, that model becomes the constraint.
The stdio constraint that breaks at enterprise is more arithmetic than engineering: typical stdio MCP deployments run one process per (user, server) tuple, with no built-in sharing across users. Some implementations multiplex multiple tool definitions inside one subprocess, and a few pool subprocesses, but the common deployment pattern in the wild — and the one that ships in the official SDKs — is one process per user per server.
At Northwind, 50 developers each run an IDE with eight MCP servers attached. That is 400 stdio processes during peak hours, distributed across 50 laptops. Each process holds memory (a Python MCP server with a few dependencies sits around 60–120 MB resident; a Node server is similar), keeps file descriptors open, and maintains an active runtime blocked on stdin. The aggregate resource footprint is not catastrophic — 400 small processes is well within the budget of modern hardware — but the real cost is operational rather than computational: process count fragments the control plane.
The harder problem is shared-state servers. Imagine the internal Logistics API MCP server caches a 200 MB customer-graph in memory at startup. Under stdio, every developer's machine loads its own copy. Under Streamable HTTP, two pod replicas hold the graph for the whole company. Same data, two orders of magnitude less memory in aggregate, plus the cache is hot across users because it is shared.
It is worth naming the other side of the trade. Stdio's decentralized model has real advantages a senior infrastructure team will rightly cite: strong fault isolation (one developer's crashed server affects no one else), no shared ingress dependency, no centralized auth outage to drag down the whole estate, and minimal infrastructure to operate. For small teams, highly trusted local workflows, or air-gapped environments, those properties can genuinely outweigh the operational benefits of a centralized HTTP tier. The argument in this post is not that stdio is bad; it is that the failure modes it pushes onto the organization — fragmented audit, distributed credentials, no central rate limiting — show up exactly when an estate crosses from "a few power users" to "shared infrastructure with compliance obligations."
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada
© 2026 Todos los derechos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




