
.webp)
June 26, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: June 26, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
El Gateway de IA de TrueFoundry emite trazas de OpenTelemetry para cada solicitud que procesa y las publica asincrónicamente a través de NATS a un exportador OTEL que las reenvía a cualquier backend compatible con OTLP a través de HTTP o gRPC. Honeycomb es uno de esos backends. Acepta datos OTLP en https://api.honeycomb.io/v1/traces a través de HTTP con codificación protobuf y se autentica usando el x-honeycomb-team encabezado. Una vez que llegan las trazas, Honeycomb indexa cada atributo de span y los pone a disposición para consultas ad hoc sin necesidad de un esquema predefinido.
Esta publicación cubre cómo el gateway de TrueFoundry genera y exporta trazas, qué hace Honeycomb con ellas una vez que llegan y cómo se conectan ambos sistemas a nivel de protocolo.
El Gateway de IA de TrueFoundry está construido sobre el framework Hono y se ejecuta como un pod de gateway sin estado con 1 vCPU y 1 GB de RAM, manejando más de 250 solicitudes por segundo con aproximadamente 3 ms de latencia adicional. El gateway cumple con OpenTelemetry y genera spans a lo largo de todo el ciclo de vida de cada solicitud entrante.
El árbol de spans cubre cinco etapas. La primera es el manejador HTTP de entrada, que registra la llegada de la solicitud junto con los metadatos del cliente. La segunda es la autenticación, donde el gateway verifica el token JWT contra una clave pública en caché descargada del proveedor de identidad. No se realiza ninguna llamada de autenticación externa durante este paso. La tercera es la resolución del modelo, donde el gateway resuelve el identificador lógico del modelo a un endpoint de proveedor físico utilizando una tabla de enrutamiento en memoria sincronizada desde el plano de control a través de NATS. La cuarta es la llamada al proveedor de salida, donde el gateway traduce la solicitud de formato compatible con OpenAI al formato del proveedor de destino a través de un adaptador y la reenvía. La quinta es el manejo de la respuesta en streaming, donde el gateway captura el recuento de tokens y las razones de finalización a medida que la respuesta se transmite de vuelta.
Los atributos de span siguen las gen_ai.* convenciones semánticas junto con atributos específicos de TrueFoundry. El gen_ai.request.model atributo registra el identificador del modelo. Los gen_ai.usage.prompt_tokens y gen_ai.usage.completion_tokens atributos registran el consumo de tokens. Los tfy.input y tfy.output los atributos contienen el texto completo de la solicitud y la respuesta. El tfy.input_short_hand atributo contiene una versión truncada para su visualización. El tfy.span_type atributo identifica la categoría de span, como ChatCompletion o MCPGateway.
Una vez completada la solicitud, el gateway publica estos spans en NATS de forma asíncrona. Un exportador OTEL en segundo plano lee de esta ruta asíncrona y reenvía los spans al endpoint externo configurado. Este diseño significa que la exportación de trazas nunca añade latencia a la ruta de la solicitud. El gateway no falla una solicitud si el endpoint OTEL externo no es accesible. La ruta de exportación es aditiva y no reemplaza el propio almacenamiento interno de trazas de TrueFoundry.

Para cargas de trabajo donde el contenido de la solicitud y la respuesta no debe salir del entorno, el gateway proporciona un Excluir datos de solicitud conmutador. Cuando está activado, elimina tfy.input y tfy.output y tfy.input_short_hand de los spans antes de la exportación. Todos los demás atributos de span, incluidos los recuentos de tokens, las latencias y los metadatos del modelo, siguen fluyendo.
El Gateway MCP sigue el mismo modelo de rastreo. Cada invocación de herramienta genera un span que registra al usuario que realiza la llamada, el servidor MCP, el nombre de la herramienta, la carga útil completa de la solicitud y la respuesta, y la latencia. Estos spans aparecen en el mismo árbol de trazas que los spans de llamadas LLM, lo que permite una visibilidad de trazas de extremo a extremo en los flujos de trabajo basados en agentes.
Honeycomb ingiere datos OTLP y almacena cada span como una fila con columnas arbitrarias. No hay un esquema fijo. Cada atributo que TrueFoundry emite, ya sea gen_ai.usage.prompt_tokens o tfy.span_type o http.response.status_code se convierte en una columna consultable en Honeycomb en el momento en que llega el primer span que lo contiene.
La primitiva de consulta central en Honeycomb es el BubbleUp análisis. Dado un conjunto de trazas lentas o fallidas, BubbleUp calcula qué valores de atributos están estadísticamente sobrerrepresentados en ese conjunto en comparación con la línea de base. Para el tráfico del gateway LLM, esto significa identificar si un pico de latencia está correlacionado con un modelo específico, un usuario específico o un servidor MCP específico sin tener que escribir una consulta manualmente.
Honeycomb organiza los datos en datasets. El gateway de TrueFoundry establece service.name como tfy-llm-gateway y Honeycomb enruta los spans a un dataset con ese nombre por defecto. Para enrutar los spans a un dataset diferente, el x-honeycomb-dataset se añade el encabezado a la configuración del exportador junto con x-honeycomb-team. Se pueden utilizar varios conjuntos de datos para separar el tráfico de producción y de staging, o para separar las trazas del gateway LLM de las trazas del gateway MCP.
La Trazas pestaña en Honeycomb presenta la vista de cascada de spans. Cada fila es un span. La jerarquía muestra las relaciones padre-hijo, de modo que un span raíz MCPGateway: resources/list span con spans anidados MCP: resources/templates/list spans y un span saliente POST https://... span se corresponde directamente con lo que ejecutó el gateway. Las barras de duración hacen visible la distribución de la latencia de un vistazo. El Spans con errores contador aísla las trazas con fallos.
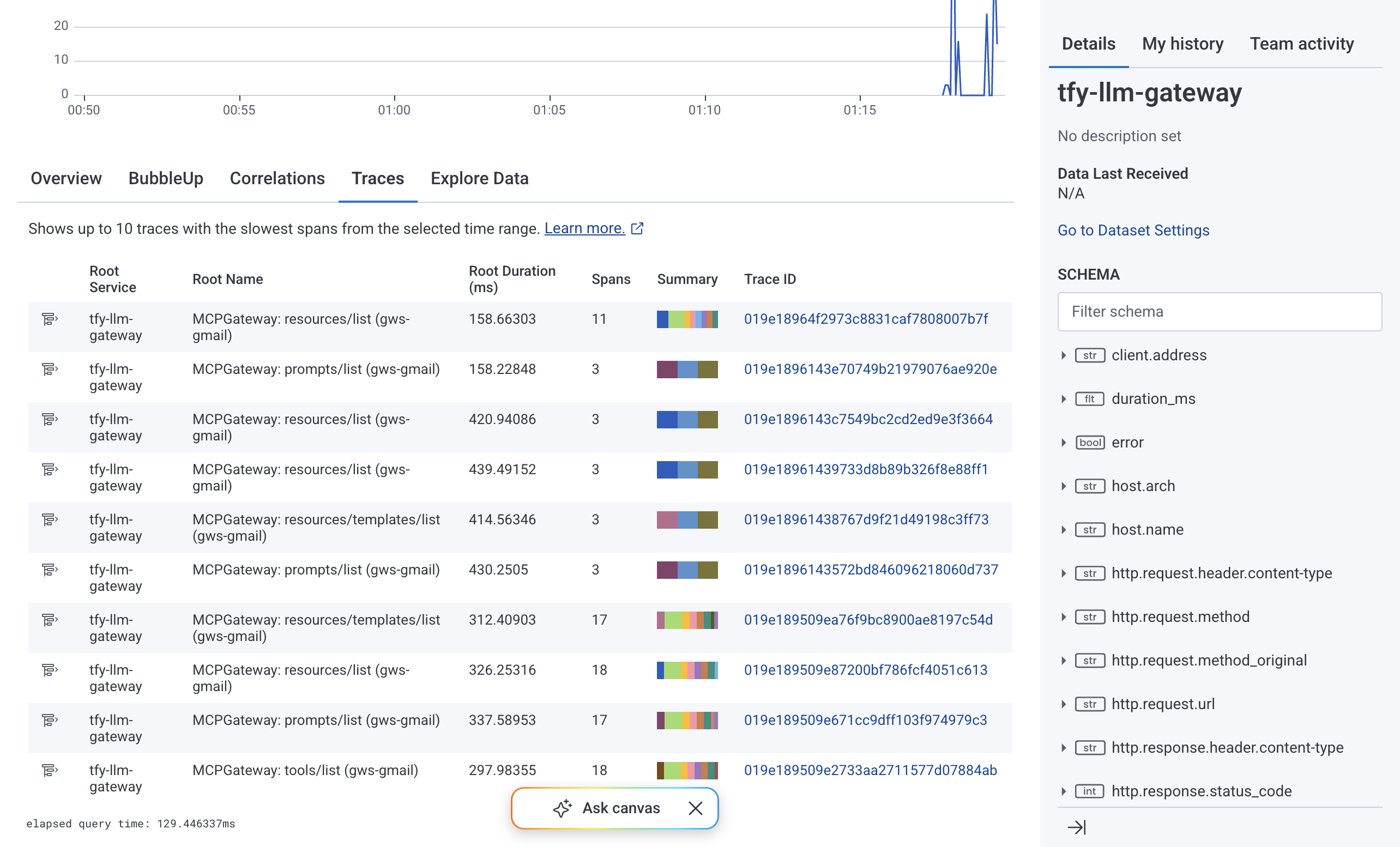
La Resumen pestaña agrega el total de spans, el total de errores y el total de excepciones durante el período de tiempo seleccionado, y representa el volumen de trazas, el volumen de spans y el volumen de errores como gráficos de series temporales. Esta vista refleja el estado del gateway de un vistazo sin necesidad de construir un panel de control desde cero.

Al hacer clic en cualquier ID de traza, se expande la cascada completa de spans para esa traza. Cada span muestra su nombre de servicio, duración y cualquier indicador de error. Los spans hijos anidados reflejan la jerarquía de llamadas interna del gateway, lo que permite aislar qué etapa introdujo latencia por cada solicitud.

El gateway de TrueFoundry exporta trazas a través de OTLP HTTP con codificación protobuf. Honeycomb acepta este formato en dos puntos finales regionales.
La autenticación utiliza una única cabecera. La x-honeycomb-team cabecera contiene la clave API de ingesta de Honeycomb. La clave debe tener el Enviar Eventos ámbito de permiso. No hay flujo de OAuth ni intercambio de token de portador. La clave se envía como un valor de cabecera en texto plano en cada solicitud de exportación.
x-honeycomb-team: <your-honeycomb-ingest-api-key>
El enrutamiento del conjunto de datos se controla mediante una segunda cabecera opcional. Cuando x-honeycomb-dataset se omite, Honeycomb utiliza service.name de los atributos del recurso para determinar el conjunto de datos de destino. Cuando se establece explícitamente, todos los spans de ese lote de exportación se escriben en el conjunto de datos nombrado, independientemente de service.name.
x-honeycomb-dataset: tfy-llm-gateway-production
La pasarela de TrueFoundry no añade automáticamente rutas de señal al punto final configurado. La ruta completa, incluyendo /v1/traces debe estar presente en el campo del punto final. Esto difiere del exportador HTTP OTLP del OpenTelemetry Collector, que añade /v1/traces automáticamente según el tipo de señal de la canalización. En el Collector, una única URL base como https://api.honeycomb.io:443 es suficiente porque el Collector resuelve la ruta a partir de la definición del pipeline. En TrueFoundry, el endpoint se utiliza tal cual.
La interfaz de configuración en TrueFoundry se mapea directamente a los campos que Honeycomb requiere.
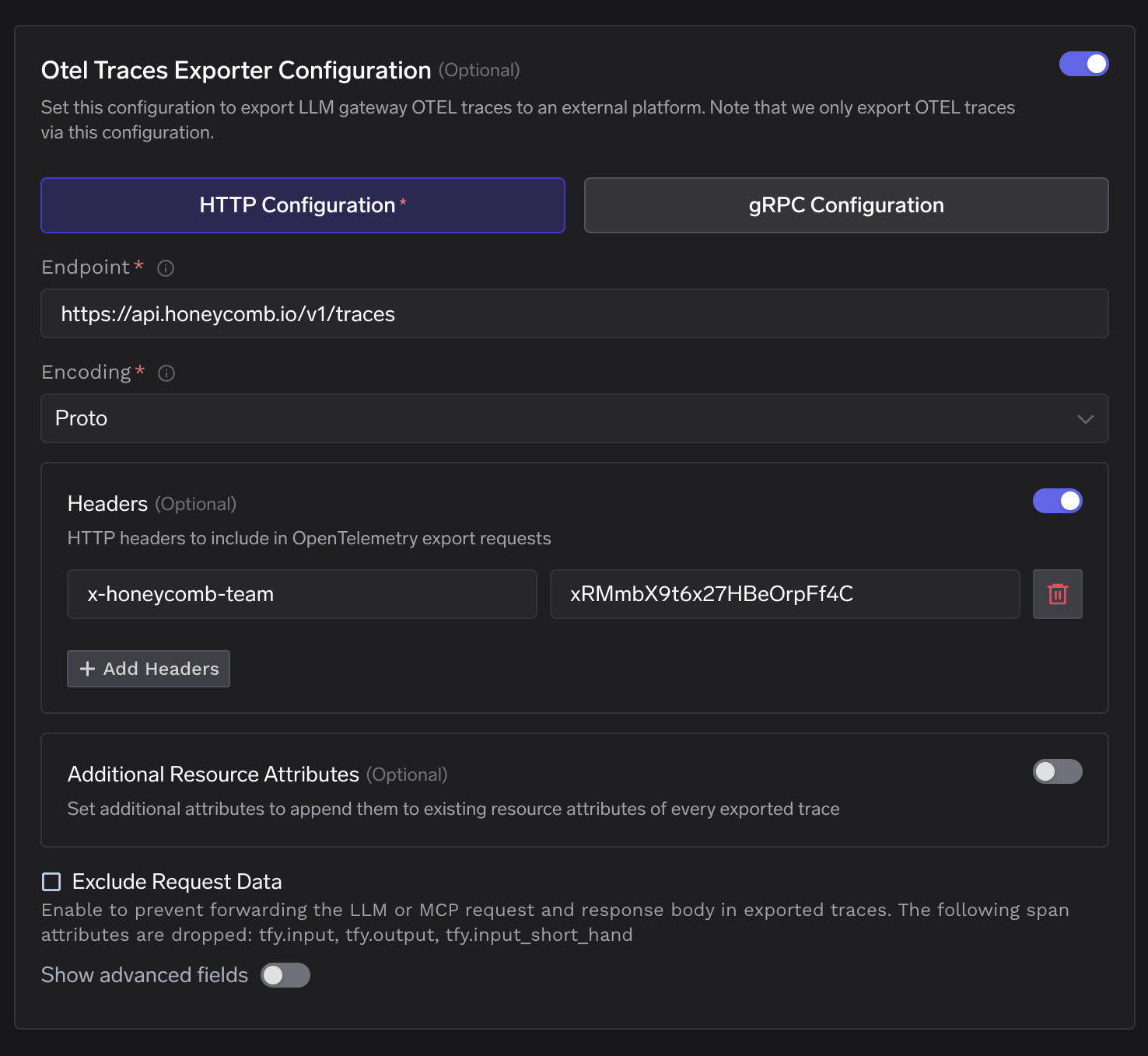
El Atributos de recurso adicionales campo añade pares clave-valor al bloque de recursos de cada span exportado. Esto es útil para añadir una etiqueta de entorno de despliegue o un identificador de clúster que no esté ya presente en los atributos del span.
El Excluir datos de la solicitud casilla de verificación elimina tfy.input y tfy.output y tfy.input_short_hand antes de que los spans salgan de la pasarela. Honeycomb seguirá recibiendo todos los atributos estructurales, incluyendo recuentos de tokens, latencias, nombres de modelos y banderas de error.
Cuando una solicitud llega a la pasarela de TrueFoundry, el árbol completo de spans se ensambla en memoria durante el procesamiento de la solicitud y se publica en NATS una vez que la respuesta se completa. El exportador OTEL se suscribe a este tema de NATS y agrupa los spans antes de enviarlos a https://api.honeycomb.io/v1/traces a través de HTTPS con el x-honeycomb-team encabezado presente. Honeycomb escribe cada span como una fila en el tfy-llm-gateway conjunto de datos. Las trazas se pueden consultar a los pocos segundos de su llegada.
No se requieren cambios en el código de la aplicación. No se implementan contenedores sidecar junto con el gateway. No se incrusta ningún SDK en el cliente. La integración es una superficie de configuración en el gateway: una URL de punto final y un encabezado de autenticación. Los clientes existentes que llaman al gateway a través de la API compatible con OpenAI siguen funcionando sin modificaciones.
El principio que hace que esta integración sea fiable es la ruta de exportación asíncrona. La exportación de trazas está desacoplada del ciclo de vida de la solicitud a través de NATS. Una interrupción de la API de Honeycomb o una partición de red entre el gateway y el punto final de ingesta de Honeycomb no afecta la disponibilidad de la inferencia. El gateway procesa las solicitudes y publica las trazas en NATS independientemente de si la exportación posterior tiene éxito. Esto significa que la canalización de observabilidad puede configurarse, reconfigurarse y reiniciarse sin afectar la ruta de servicio de solicitudes.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada
© 2026 Todos los derechos reservados.




.webp)

.webp)
.webp)
.png)






.webp)
.webp)


