
.webp)
July 2, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: June 26, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
TrueFoundry AI Gateway es una capa de ejecución unificada para la infraestructura de LLM. Gestiona la autenticación, el enrutamiento entre proveedores, la limitación de velocidad, la aplicación de políticas, la gestión de llamadas a herramientas MCP y —fundamental para esta integración— la trazabilidad compatible con OpenTelemetry. Cada solicitud a través del gateway genera un 'span' que contiene atributos estándar gen_ai.* atributos (nombre del modelo, recuento de tokens, motivo de finalización) junto con atributos específicos de TrueFoundry como tfy.input, tfy.output, y tfy.span_type. Estos 'spans' se publican asincrónicamente en una cola de mensajes NATS una vez completada la solicitud, lo que significa que la ruta de exportación nunca detiene una solicitud en curso. Un servicio de exportación OTEL dedicado lee de esa cola y reenvía los 'spans' a cualquier punto final OTLP configurado a través de HTTP o gRPC.
Pydantic Logfire es una plataforma de observabilidad creada por el equipo detrás de Pydantic —la capa de validación integrada en el SDK de OpenAI, el SDK de Anthropic y la mayoría de los frameworks de IA en producción hoy en día. Logfire ingiere datos OTLP estándar y aplica un renderizado nativo de IA sobre ellos: cuando detecta gen_ai.* atributos en un 'span', el Panel LLM se activa automáticamente, mostrando el historial completo de la conversación, los argumentos de las llamadas a herramientas, los recuentos de tokens por solicitud y los costos calculados —sin necesidad de integración de SDK en el lado del envío. Las consultas de Logfire están escritas en SQL compatible con PostgreSQL, por lo que los rastreos de producción son accesibles tanto para humanos como para agentes de codificación. Está disponible como un servicio en la nube gestionado con puntos finales regionales en EE. UU. y la UE.
La integración se conecta en un único punto: la OTEL Configde TrueFoundry, que acepta un punto final HTTP OTLP y un encabezado de autorización. Vaya a AI Gateway → Controles → Configuración → OTEL Config y haga clic en el botón de edición para abrir el panel de configuración.

Sección de configuración de OTEL de TrueFoundry: el endpoint de trazas apunta a la URL de ingesta de Logfire para la UE con el encabezado Authorization configurado.
Configure el endpoint en la URL de ingesta regional de Logfire, seleccione HTTP con codificación proto y añada el token de escritura de Logfire como el Authorization valor del encabezado. El mismo token de escritura cubre tanto los exportadores de trazas como los de métricas.
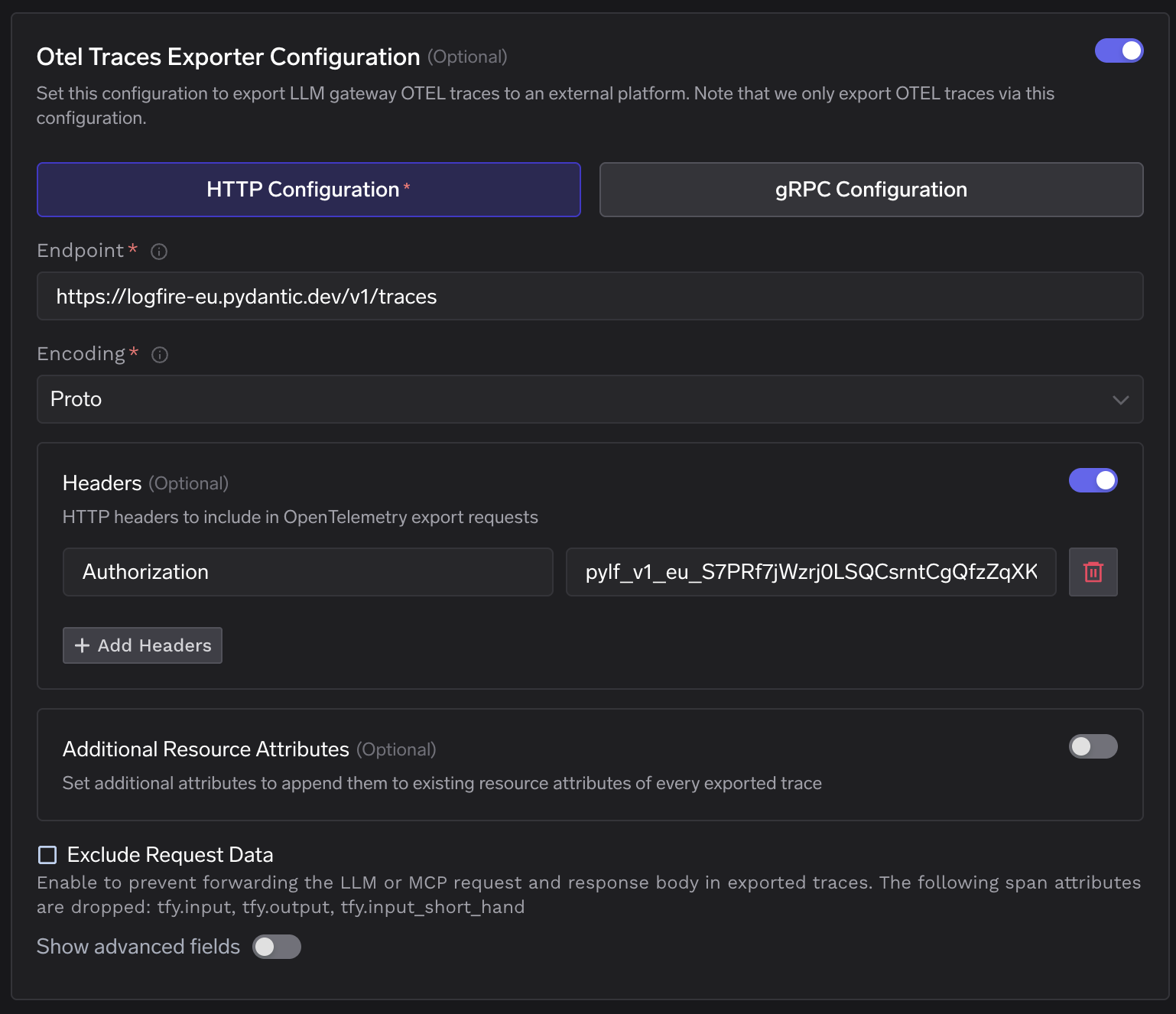
El formulario del exportador de trazas rellenado — endpoint configurado en https://logfire-eu.pydantic.dev/v1/traces, codificación Proto, y el token de escritura de Logfire en el encabezado Authorization.
No se requieren cambios en el código de las aplicaciones que envían solicitudes a través del gateway. La pipeline de trazabilidad opera completamente en la capa de infraestructura. Una solicitud de cualquier equipo, utilizando cualquier modelo, a través de cualquier proveedor, genera un span que fluye a Logfire llevando el contexto completo de lo que ocurrió en el gateway.
Cuando una solicitud llega al gateway, la secuencia es:
Una vez configurados, los spans de tfy-llm-gateway comienzan a aparecer en la vista en vivo de Logfire en tiempo real. El tfy.span_type atributo distingue los spans ChatCompletion, AgentResponsey MCPGateway , lo que permite a los equipos filtrar por tipo de operación o consultarlos en SQL.

Vista en vivo de Logfire mostrando los spans de tfy-llm-gateway: las operaciones AgentResponse, ChatCompletion y MCPGateway aparecen con temporización completa, estado y spans hijos anidados.
Más allá de las trazas individuales, el exportador de métricas presenta datos de uso agregados entre proveedores, modelos y equipos. La vista general de uso de Logfire los agrupa por alcance y nombre de span, lo que proporciona a los líderes de plataforma una visión general de alto nivel de hacia dónde se dirige el tráfico y en qué volumen.
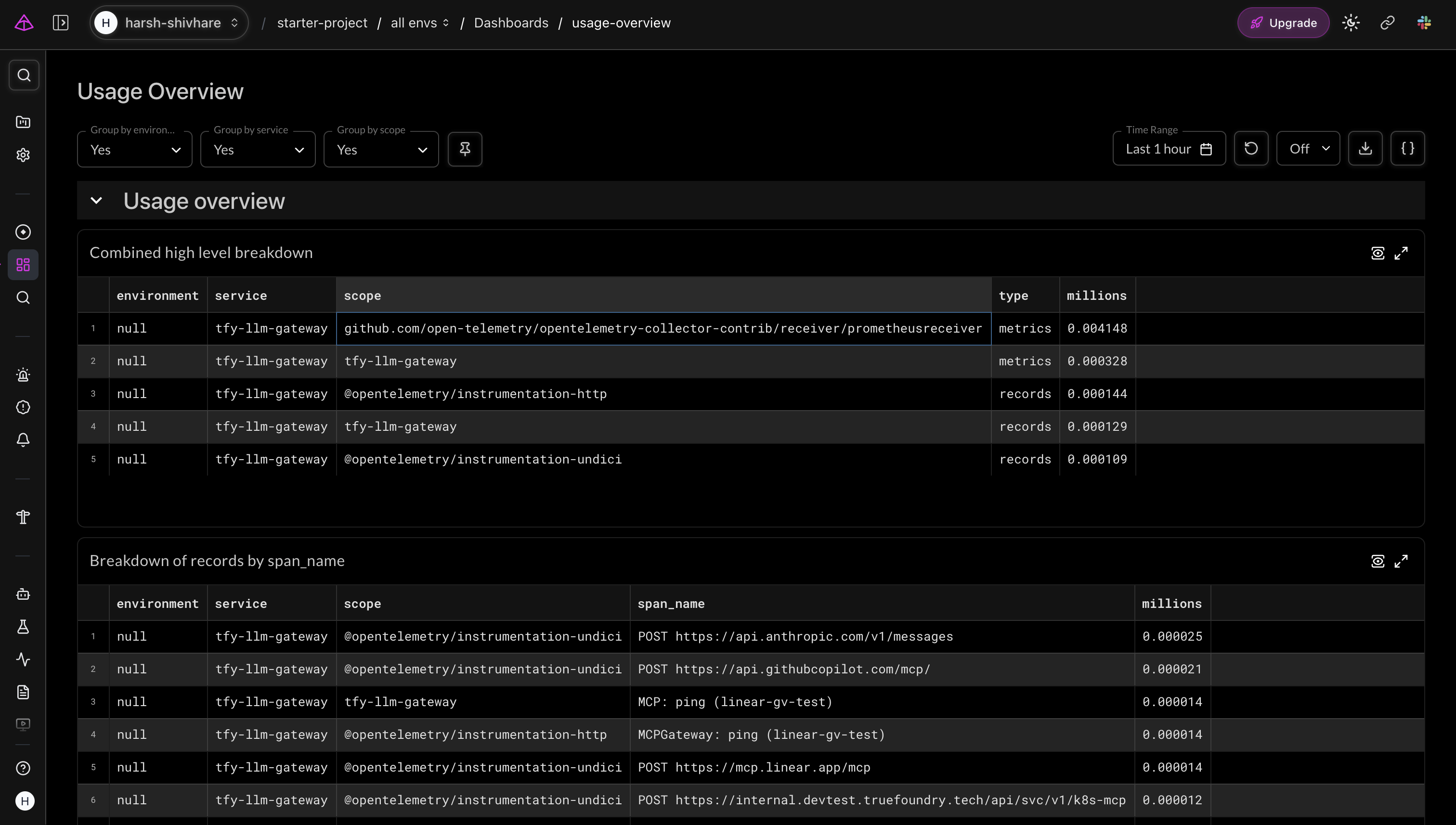
Vista general de uso de Logfire: métricas del tfy-llm-gateway desglosadas por alcance de instrumentación, mostrando el tráfico de ChatCompletion y MCPGateway entre proveedores.
Empiece creando un token de escritura en Logfire. Vaya a su proyecto, abra Configuración del proyecto → Tokens de escritura, y haga clic en Nuevo token de escritura. Copie el token inmediatamente; Logfire no volverá a mostrar el valor completo.

La página de Tokens de escritura de Logfire: cree un token dedicado para TrueFoundry y guárdelo de forma segura antes de cerrar el diálogo.
Luego vaya a Puerta de enlace de IA → Controles → Configuración → Configuración de OTEL en TrueFoundry y configure los exportadores de trazas y métricas con el punto final regional de Logfire y el token de escritura. La referencia completa del punto final y la guía de configuración están disponibles en la documentación de TrueFoundry. Logfire ofrece un nivel gratuito perpetuo, con una opción empresarial autoalojada para equipos con requisitos de residencia de datos.
La conclusión importante de esta integración es arquitectónica: TrueFoundry y Logfire nunca necesitaron coordinarse directamente. La puerta de enlace emite spans estándar de OpenTelemetry con atributos gen_ai.*; Logfire lee ese mismo estándar y activa automáticamente sus vistas compatibles con LLM. OpenTelemetry es el contrato entre ellos: la puerta de enlace rige la ejecución y genera telemetría, Logfire registra y visualiza el comportamiento, y el estándar los conecta sin que ninguno de los sistemas dependa de los detalles internos del otro.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada
© 2026 Todos los derechos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




