
.webp)
July 2, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: June 26, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Cuando Moonshot AI liberó Kimi K2 como código abierto, la comunidad de IA tomó nota. Cuando le siguió con Kimi K2 Thinking, un modelo capaz de razonar a través de cientos de llamadas a herramientas con una coherencia notable, los profesionales empezaron a prestarle seria atención. Ahora, con Kimi K2.6, Moonshot ha ido aún más lejos: un modelo de código abierto de última generación que se sitúa en lo más alto de los benchmarks de codificación y de agentes de largo alcance, rivalizando con las mejores ofertas de código cerrado del mundo.
Esta publicación es un análisis profundo de lo que hace que K2.6 sea notable, lo que significan realmente los números de los benchmarks para cargas de trabajo reales y cómo puedes ponerlo en marcha sin un proyecto de implementación de seis semanas.
Kimi K2.6 es el modelo multimodal de próxima generación de Moonshot AI, disponible en Hugging Face y a través de la API de Kimi. Al igual que sus predecesores, está construido sobre una arquitectura de Mezcla de Expertos (MoE) con una ventana de contexto de 262.144 tokens. Pero K2.6 es más que una mejora incremental: representa un cambio de diseño significativo hacia tres aspectos que la generación anterior manejaba de forma inconsistente: codificación de largo alcance, diseño impulsado por código, y coordinación de enjambres de agentes.
Aquí tienes una rápida ilustración de lo que significa "largo alcance" en la práctica. En una demostración de benchmark, K2.6 desplegó de forma autónoma un modelo Qwen3.5-0.8B localmente en un Mac, implementó la inferencia en Zig (un lenguaje de programación de sistemas de nicho), y durante más de 4.000 llamadas a herramientas y más de 12 horas de ejecución continua, mejoró el rendimiento de ~15 a ~193 tokens por segundo (aproximadamente un 20% más rápido que LM Studio). Eso no es un chatbot respondiendo a una pregunta; eso es una IA actuando como un ingeniero de rendimiento senior en un compromiso sostenido.
En una demostración separada, K2.6 renovó un motor de emparejamiento financiero de código abierto de 8 años de antigüedad durante una sesión de 13 horas, realizando más de 1.000 cambios de código específicos para lograr una mejora del 185% en el rendimiento medio y una ganancia del 133% en el rendimiento máximo — sin ninguna guía humana después de la especificación inicial de la tarea.
Los números importan, pero el contexto importa más. Así es como K2.6 se desempeña en los benchmarks más relevantes para sistemas agénticos de producción:
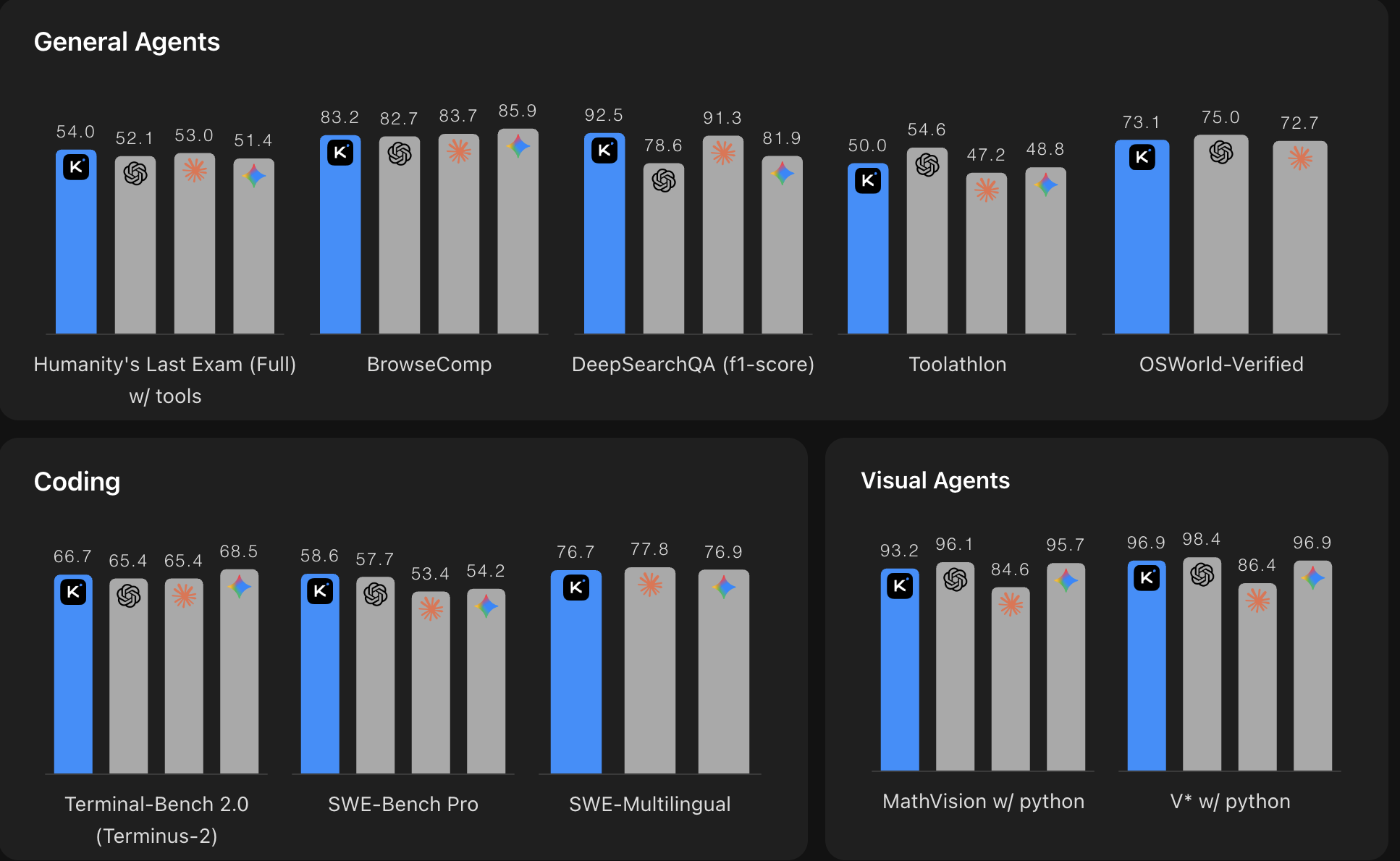
*Fuente: Comparación de benchmarks de Moonshot AI Kimi K2.6. Cuanto más alto, mejor. El gráfico compara Kimi K2.6 con los principales modelos de código cerrado en benchmarks de agentes generales, codificación y agentes visuales.*
K2.6 compite con los mejores modelos de código cerrado, incluyendo Claude Opus 4.6 y GPT-5.4, en prácticamente todas las dimensiones importantes para la codificación agéntica y tareas de largo alcance. Y lo hace como un modelo de peso abierto a 0.74 $ / 3.50 $ por millón de tokens de entrada/salida. lo que representa una fracción del costo de alternativas propietarias comparables.
El salto con respecto a Kimi K2.5 también es significativo: una mejora de casi el 80% en Toolathlon, aproximadamente 8 puntos porcentuales en BrowseComp y SWE-Bench Pro. Estas no son ganancias marginales.
Los socios empresariales que tuvieron acceso anticipado reportan resultados igualmente convincentes: el CTO de Augmentcode destacó la "precisión quirúrgica en grandes bases de código" de K2.6; Vercel observó una mejora de más del 50% en su benchmark de Next.js en comparación con K2.5; y CodeBuddy midió una mejora del 12% en la precisión de la generación de código, con un éxito de invocación de herramientas que alcanzó el 96.6%.
La mayoría de los LLM son adecuados para la generación de código de una sola vez. K2.6 está diseñado para tareas que llevan horas: refactorizaciones de múltiples archivos, optimizaciones entre lenguajes, mejoras en el pipeline de compilación y bucles de depuración iterativos donde el modelo tiene que leer la salida del compilador, ajustar su hipótesis y volver a intentarlo.
El modelo muestra una fuerte generalización en Python, Rust, Go e incluso lenguajes poco comunes como Zig, lo cual es notable porque sugiere que el modelo ha internalizado conceptos de programación lo suficientemente profundo como para transferirlos, en lugar de simplemente memorizar patrones de los datos de entrenamiento.
K2.6 puede transformar una única instrucción en lenguaje natural en un frontend completo y listo para producción —no solo un prototipo estático, sino uno con elementos interactivos, animaciones de desplazamiento y autenticación respaldada por base de datos. En el Kimi Design Bench interno de Moonshot, K2.6 supera a Google AI Studio en tareas de entrada visual, construcción de páginas de destino, desarrollo de aplicaciones full-stack y programación creativa general.
Para los equipos que desarrollan flujos de trabajo asistidos por IA, esto significa, en efecto, un único modelo que gestiona todo el stack: arquitectura, lógica, interfaz de usuario y andamiaje de despliegue.
K2.6 introduce una importante expansión arquitectónica del sistema de enjambre de agentes presentado por primera vez en K2.5. El enjambre ahora escala hasta 300 subagentes ejecutando simultáneamente a través de 4.000 pasos coordinados, frente a los 100 agentes y 1.500 pasos de K2.5. Esto no es solo una mejora de escala; es un cambio cualitativo en el tipo de tareas que se vuelven factibles.
Una tarea que antes requería la orquestación humana (por ejemplo, "investigar 100 empresas de semiconductores, construir cinco estrategias de inversión cuantitativas y producir una presentación al estilo McKinsey") ahora puede emitirse como una única instrucción a K2.6 y entregarse como un resultado completo.
Aquí es donde la conversación suele detenerse: un equipo lee los números de referencia, se entusiasma y luego pasa las siguientes tres semanas averiguando cómo servir el modelo de forma fiable.
K2.6 es un modelo MoE grande. Su ventana de contexto de 262K significa que los requisitos de memoria son significativos. Las cargas de trabajo agénticas —por definición— generan patrones de tráfico altamente variables: silenciosas durante horas, y luego, de repente, cientos de subagentes paralelos realizando solicitudes simultáneamente. Las estrategias de despliegue ingenuas se desmoronan bajo esa carga.
Este es el problema de infraestructura que TrueFoundry AI Gateway está diseñado para resolver.
En lugar de aprovisionar su propio clúster de GPU, construir un balanceador de carga personalizado y ajustar manualmente los parámetros de inferencia, TrueFoundry le permite apuntar su aplicación a un único endpoint — y se encarga del resto. El Gateway enruta las solicitudes de forma inteligente entre proveedores, gestiona la concurrencia para cargas de trabajo de ráfaga (como un enjambre que dispara 300 subagentes simultáneos) y le proporciona las herramientas de observabilidad —rastreos, histogramas de latencia, uso de tokens por equipo— que de otro modo tendría que construir usted mismo.
En nuestras pruebas internas con Kimi K2 Thinking, el Gateway de TrueFoundry manejó más de 350 RPS en una única vCPU con una sobrecarga de ~10ms. Para cargas de trabajo agénticas donde una única tarea iniciada por el usuario puede ramificarse en docenas o cientos de llamadas a la API, ese margen es importante.
También existe una dimensión organizativa práctica. Los equipos empresariales que utilizan K2.6 suelen tener múltiples equipos —ciencia de datos, ingeniería de producto, plataforma— todos queriendo experimentar con el mismo modelo. El Gateway proporciona un único plano de control para la limitación de velocidad, la atribución de costos y las políticas de acceso, sin que cada equipo necesite su propia gestión de claves API.
El camino más rápido para ejecutar K2.6 en un entorno gestionado y listo para producción:
1. A través del Gateway de IA de TrueFoundry (API)
Si ya utiliza el SDK de OpenAI o cualquier cliente compatible con OpenAI, puede cambiar a K2.6 con un solo cambio en la cadena del modelo:
from openai import OpenAI
client = OpenAI(
api_key="<your-truefoundry-api-key>",
base_url="https://llm-gateway.truefoundry.com/api/inference/openai"
)
response = client.chat.completions.create(
model="moonshotai/kimi-k2.6",
messages=[
{"role": "user", "content": "Refactor this codebase for better performance..."}
]
)El Gateway gestiona de forma transparente la selección de proveedores, el enrutamiento de respaldo y la limitación de velocidad.
2. Para cargas de trabajo de agentes
La interfaz de llamada a herramientas de K2.6 sigue el esquema estándar de llamada a funciones de OpenAI. Para tareas de largo alcance, querrá:
- Establecer `max_tokens` generosamente (el modelo puede hacer un uso productivo de un gran presupuesto de generación)
- Habilitar el streaming para obtener salidas incrementales de cadenas de herramientas largas
- Utilizar el panel de seguimiento de TrueFoundry para visualizar qué llamadas a herramientas están tardando y dónde se está consumiendo el contexto
3. Para la orquestación de enjambres de agentes
Si está construyendo sistemas multiagente, el Gateway de TrueFoundry proporciona metadatos a nivel de solicitud: puede etiquetar las solicitudes de cada subagente con un ID de tarea principal y luego reconstruir el rastro de ejecución completo a posteriori. Esto es invaluable para depurar el comportamiento del enjambre y comprender dónde el paralelismo está ayudando (o perjudicando).
Equipos de ingeniería que desarrollan herramientas de codificación agénticas: K2.6 es el primer modelo de código abierto que compite seriamente con GPT-5.4 y Claude Opus en SWE-Bench Pro. Si ha estado esperando un modelo de pesos abiertos que pueda manejar tareas de bases de código de grado de producción, este es el indicado.
Equipos de plataforma de ML que gestionan el acceso a modelos: una empresa que evalúa K2.6 junto con otros modelos de vanguardia se beneficia de ejecutar todo a través de un único gateway. El enfoque de catálogo de modelos de TrueFoundry le permite realizar pruebas A/B de K2.6 frente a Claude o GPT-5.4 en sus cargas de trabajo reales, con seguimiento de costos y latencia en paralelo.
Equipos con requisitos de residencia de datos: Los pesos abiertos de K2.6 significan que puede implementarse en una infraestructura que usted controla. La plataforma de despliegue de TrueFoundry gestiona la orquestación, por lo que obtiene una gobernanza de modelos de nivel empresarial sin que un proveedor propietario se interponga en su ruta de inferencia.
Cualquiera que esté cansado de pagar los precios de los modelos de código cerrado: con un costo de $0.74 / $3.50 por millón de tokens y un rendimiento de referencia que iguala o supera a las alternativas propietarias en la mayoría de las tareas agénticas, el argumento de costo-rendimiento de K2.6 es difícil de ignorar.
Kimi K2.6 es un modelo de vanguardia genuino. No es "bueno para ser de código abierto", sino que compite de verdad con los mejores modelos del mundo en los puntos de referencia que importan para el trabajo de ingeniería real. Su fiabilidad a largo plazo, su arquitectura de enjambre de agentes y sus precios competitivos lo convierten en el modelo de peso abierto más convincente disponible hoy en día para sistemas agénticos de producción.
La pregunta práctica no es si vale la pena usar K2.6. Sí la vale. La pregunta es con qué rapidez y fiabilidad puedes ponerlo en producción. TrueFoundry AI Gateway responde a esa pregunta, para que tu equipo dedique su tiempo a construir con el modelo, no a construir la infraestructura que lo rodea.
Pruébalo ahora: Accede a Kimi K2.6 a través de [TrueFoundry AI Gateway](https://www.truefoundry.com/ai-gateway), o [reserva una demostración](https://www.truefoundry.com/book-demo) para ver cómo se adapta al flujo de trabajo de tu equipo.
*Todas las cifras de referencia citadas provienen del blog técnico oficial de Kimi K2.6 y de evaluaciones verificadas de terceros en OpenRouter. Los números de rendimiento de la infraestructura provienen de pruebas internas de TrueFoundry.*
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada
© 2026 Todos los derechos reservados.






.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




