

July 20, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Supongamos que hay un equipo A asignado para desarrollar la aplicación RAG para caso de uso-1, luego está equipo B que está desarrollando la aplicación RAG para caso de uso-2, y luego está equipo C, que solo está planificando su próximo caso de uso de la aplicación RAG. ¿Ha deseado que la creación de canalizaciones de RAG en varios equipos hubiera sido fácil? ¿No es necesario que cada equipo comience desde cero, sino de forma modular en la que cada equipo pueda usar la misma funcionalidad básica y desarrollar sus propias aplicaciones de manera efectiva sobre ella sin ninguna interferencia?
¡¡No te preocupes!! Es por eso que creamos Cognita. Si bien RAG es innegablemente impresionante, el proceso de crear una aplicación funcional con él puede resultar abrumador. Hay mucho que entender en relación con las prácticas de implementación y desarrollo, que van desde la selección de los modelos de IA adecuados para el caso de uso específico hasta la organización de los datos de manera eficaz para obtener la información deseada. Si bien herramientas como Cadena LANG y Índice Llama existen para simplificar el proceso de diseño de prototipos, aún no existe una plantilla RAG de código abierto accesible y lista para usar que incorpore las mejores prácticas y ofrezca soporte modular, lo que permita a cualquier persona utilizarla rápida y fácilmente.
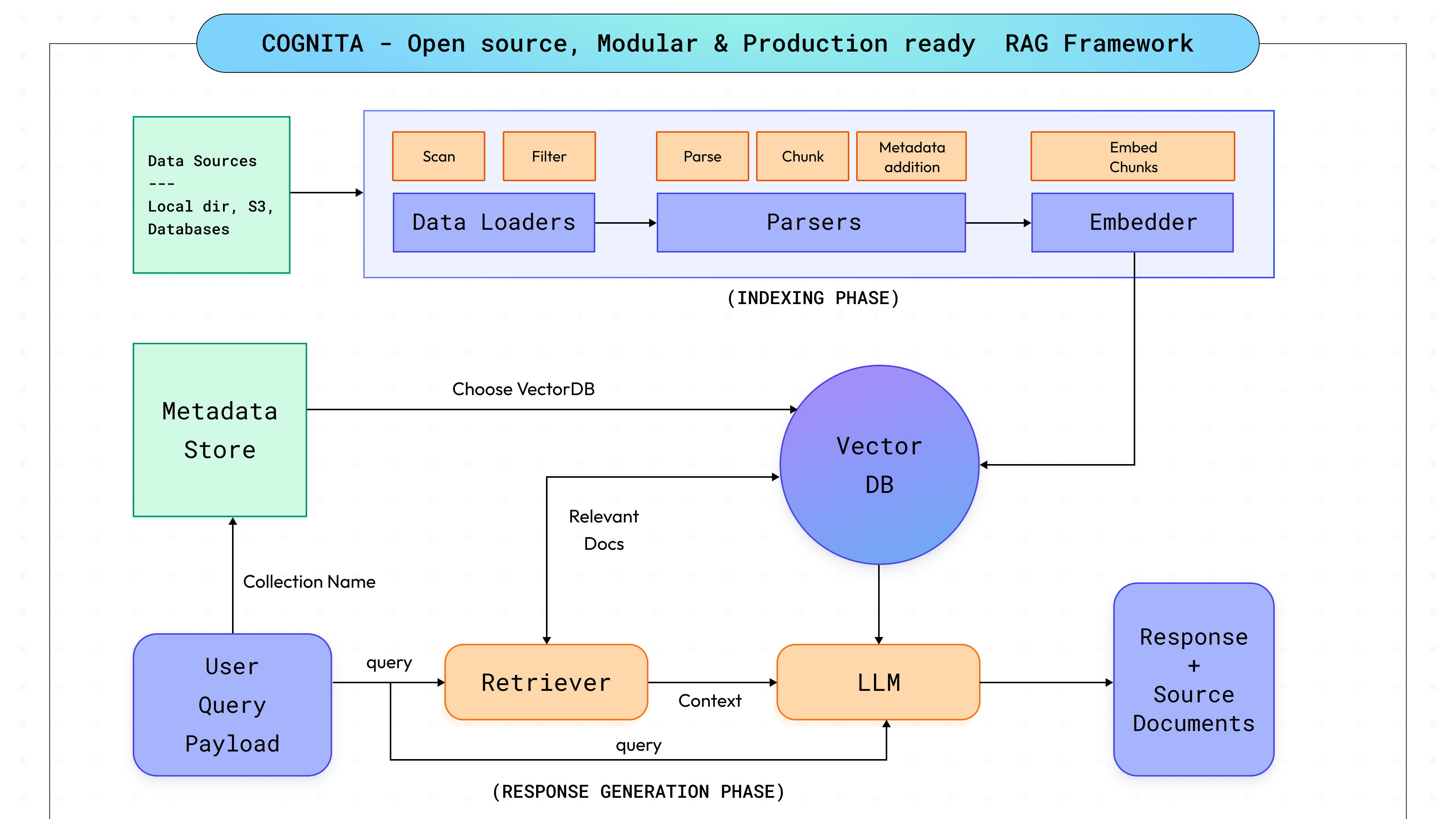
Profundizando en el funcionamiento interno de Cognita, nuestro objetivo era lograr un equilibrio entre la personalización total y la adaptabilidad y, al mismo tiempo, garantizar la facilidad de uso desde el primer momento. Dado el rápido ritmo de los avances en RAG e IA, era imperativo para nosotros diseñar Cognita teniendo en cuenta la escalabilidad, lo que permitiría una integración perfecta de los nuevos avances y los diversos casos de uso. Esto nos llevó a dividir el proceso RAG en distintos pasos modulares (como se muestra en el diagrama anterior, que se analizará en las secciones siguientes), lo que facilitó el mantenimiento del sistema, la adición de nuevas funcionalidades, como la interoperabilidad con otras bibliotecas de IA, y permitió a los usuarios adaptar la plataforma a sus requisitos específicos. Nuestro objetivo sigue siendo proporcionar a los usuarios una herramienta sólida que no solo satisfaga sus necesidades actuales, sino que también evolucione junto con la tecnología, incluidos cambios arquitectónicos más amplios, como MCP frente a RAG, garantizando un valor a largo plazo.
Cognita está diseñado en torno a siete módulos diferentes, cada uno personalizable y controlable para adaptarse a diferentes necesidades:
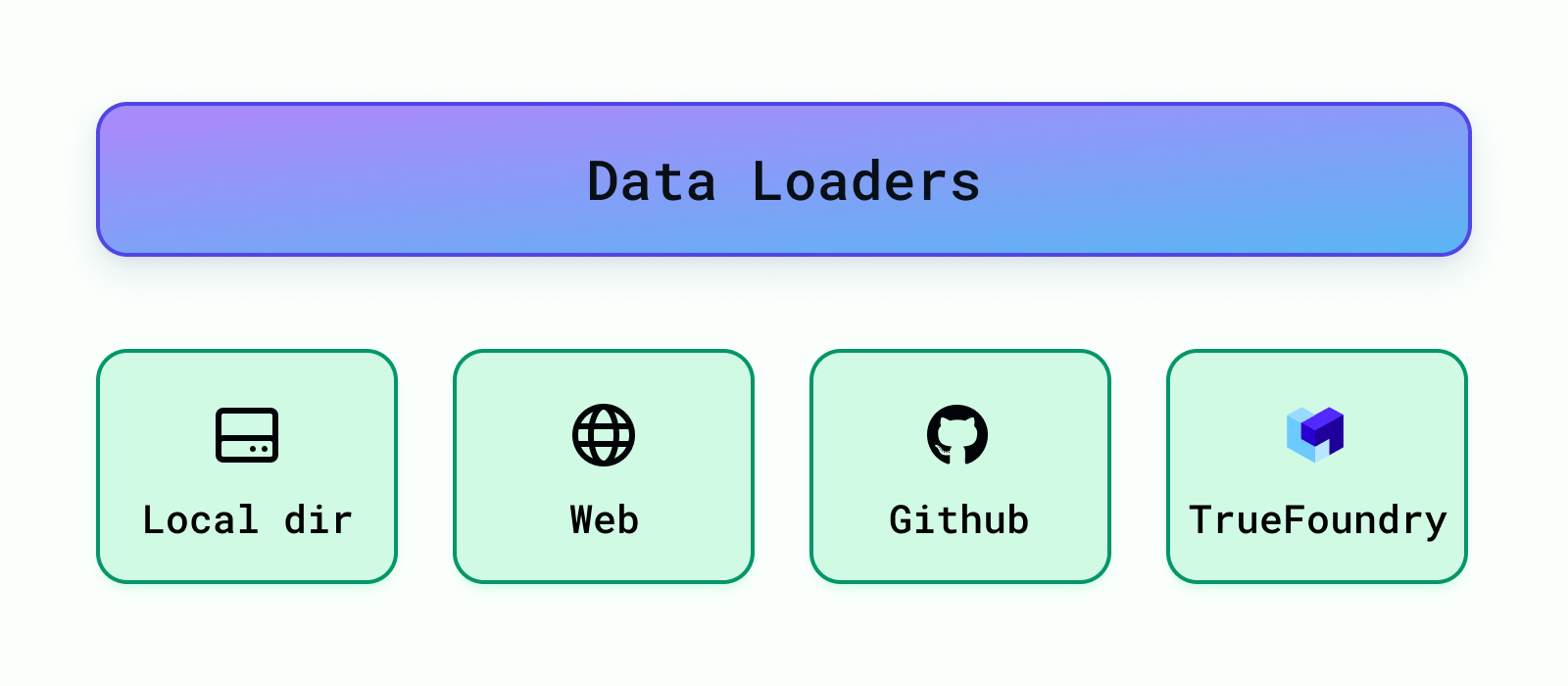
Estos cargan los datos de diferentes fuentes, como directorios locales, cubos de S3, bases de datos, Verdadera fundición artefactos, etc. Actualmente, Cognita admite la carga de datos desde el directorio local, la URL web, el repositorio de Github y los artefactos de Truefoundry. Se pueden añadir fácilmente más cargadores de datos en backend/módulos/cargadores de datos/ . Una vez que se agrega un cargador de datos, debe registrarlo para que la aplicación RAG pueda usarlo en backend/modules/dataloaders/__init__.py Para registrar un cargador de datos, añada lo siguiente:
En este paso, tratamos diferentes tipos de datos, como archivos de texto normales, PDF e incluso archivos Markdown. El objetivo es convertir todos estos tipos diferentes en un formato común para que podamos trabajar con ellos más fácilmente más adelante. Esta parte, llamada análisis, suele ser la que lleva más tiempo y es difícil de implementar cuando estamos configurando un sistema como este. Sin embargo, el uso de Cognita puede ayudar porque ya nos permite gestionar la ardua tarea de gestionar las canalizaciones de datos.
Después de esto, dividimos los datos analizados en fragmentos uniformes. Pero, ¿por qué necesitamos esto? El texto que obtenemos de los archivos puede tener diferentes longitudes. Si utilizamos estos textos largos directamente, acabaremos añadiendo un montón de información innecesaria. Además, dado que todos los LLM solo pueden procesar una cierta cantidad de texto a la vez, no podremos incluir todo el contexto importante necesario para la pregunta. Por lo tanto, vamos a dividir el texto en partes más pequeñas para cada sección. Intuitivamente, los fragmentos más pequeños contendrán conceptos relevantes y serán menos ruidosos en comparación con los fragmentos más grandes.
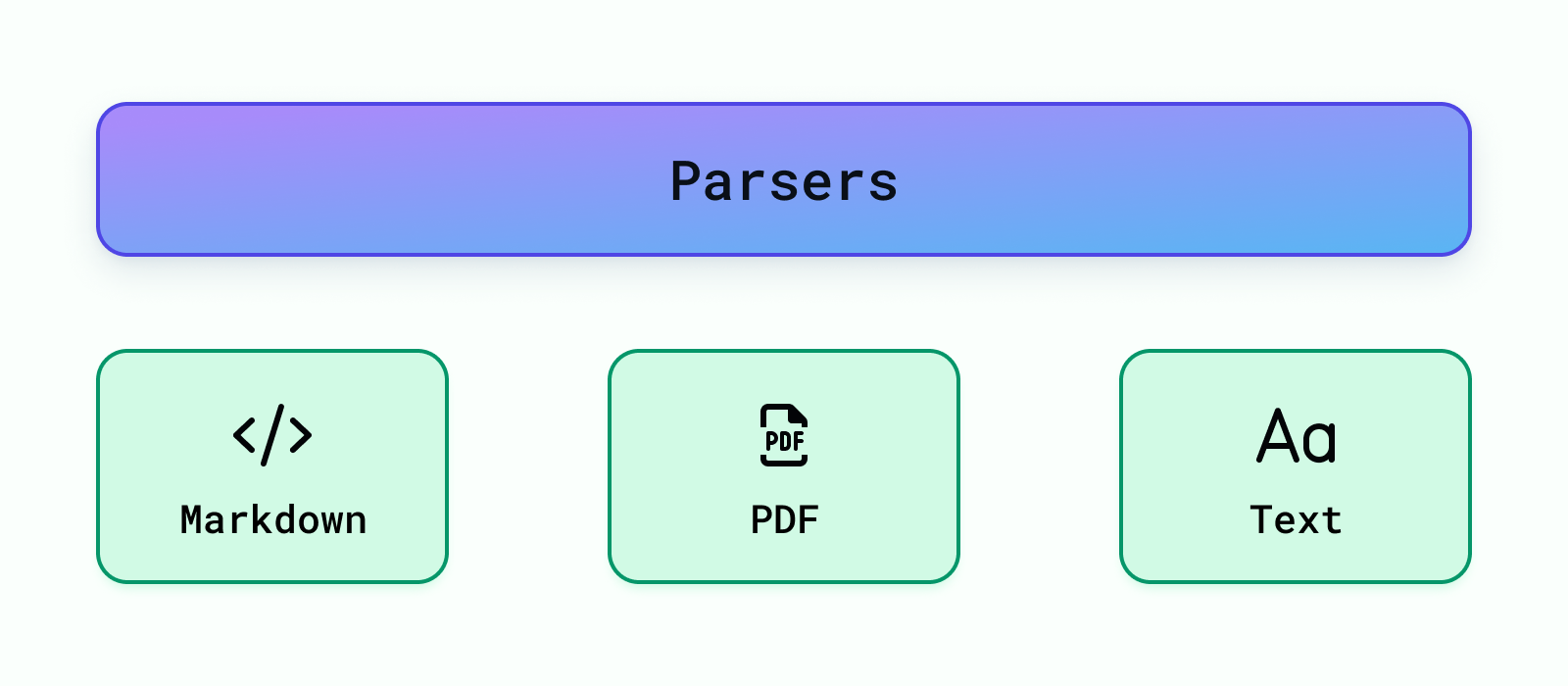
Actualmente admitimos el análisis de Markdown, PDF y Texto archivos. Se pueden agregar fácilmente más analizadores de datos en backend/módulos/analizadores/ . Una vez que se agrega un analizador, debe registrarlo para que la aplicación RAG pueda usarlo en backend/modules/parsers/__init__.py Para registrar un analizador, añada lo siguiente:
Una vez que hayamos dividido los datos en partes más pequeñas, queremos encontrar los fragmentos más importantes para una pregunta específica. Una forma rápida y eficaz de hacerlo es utilizar un modelo previamente entrenado (modelo de incrustación) para convertir nuestros datos y la pregunta en códigos especiales denominados incrustaciones. Luego, comparamos las incrustaciones de cada fragmento de datos con las de la pregunta. Al medir el similitud de coseno entre estas incrustaciones, podemos averiguar qué partes están más estrechamente relacionadas con la pregunta, lo que nos ayuda a encontrar las mejores para usar.
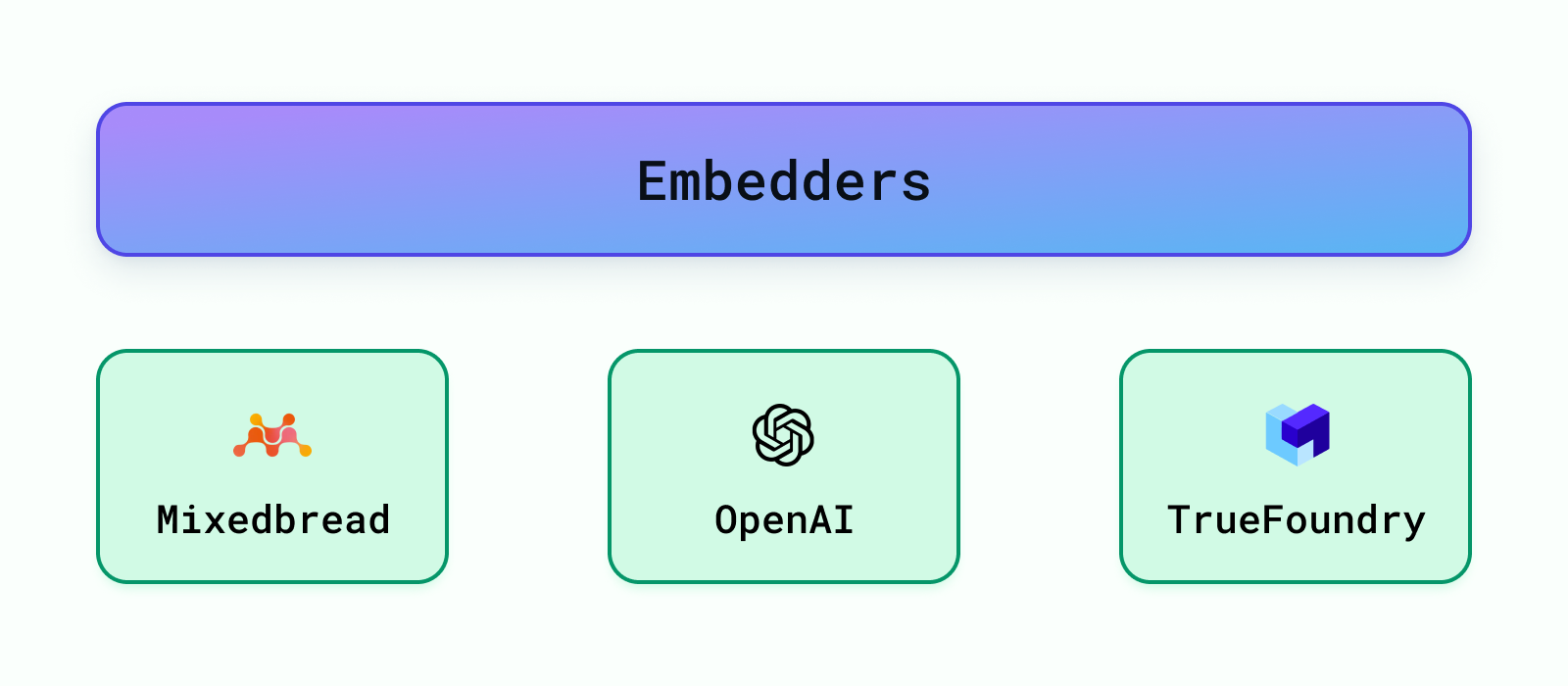
Hay muchos modelos previamente entrenados disponibles para incrustar los datos, como los modelos de OpenAI, Cohere, etc. Los más populares se pueden descubrir a través de El punto de referencia de incrustación masiva de texto de HuggingFace (MTEB) tabla de clasificación. Brindamos soporte para incrustaciones de OpenAI, embeddings de TrueFoundry y también para las actuales SOTA incrustaciones (a partir de abril de 2024) de pan mixto - ai.
Se pueden agregar fácilmente más incrustadores debajo backend/módulos/integrador/ . Una vez que se agrega un incrustador, debe registrarlo para que la aplicación RAG pueda usarlo en backend/modules/embedders/__init__.py Para registrar un analizador, añada lo siguiente:
Nota: Recuerda que las incrustaciones no son el único método para encontrar partes importantes. ¡También podríamos usar un LLM para esta tarea! Sin embargo, los LLM son mucho más grandes que los modelos de incrustación y tienen un límite en cuanto a la cantidad de texto que pueden procesar a la vez. Por eso es más inteligente usar las incrustaciones para elegir primero los k fragmentos principales. Luego, podemos usar los LLM en estos pocos fragmentos para determinar cuáles son los mejores para usarlos como contexto para responder a nuestra pregunta.
Una vez que el paso de incrustación encuentra algunas posibles coincidencias, que pueden ser muchas, se aplica un paso de reclasificación. Cambie la clasificación para asegurarse de que los mejores resultados estén en la parte superior. Como resultado, podemos elegir los x documentos principales, lo que hace que nuestro contexto sea más conciso y la consulta rápida sea más corta. Brindamos soporte para SOTA reranker (a partir de abril de 2024) desde pan mixto - ai que se implementa en backend/módulos/cambio de posicionamiento/
Una vez que creamos vectores para textos, los almacenamos en algo llamado base de datos vectorial. Esta base de datos realiza un seguimiento de estos vectores para que podamos encontrarlos rápidamente más adelante utilizando diferentes métodos. Las bases de datos normales organizan los datos en tablas, como filas y columnas, pero las bases de datos vectoriales son especiales porque almacenan y encuentran datos basados en estos vectores. Esto es muy útil para cosas como reconocer imágenes, entender el lenguaje o recomendar cosas. Por ejemplo, en un sistema de recomendaciones, cada artículo que quieras recomendar (como una película o un producto) se convierte en un vector, con diferentes partes del vector que representan diferentes características del artículo, como su género o precio. Del mismo modo, en el lenguaje, cada palabra o documento se convierte en un vector, y partes del vector representan características de la palabra o el documento, como la frecuencia con la que se usa la palabra o su significado. Estas bases de datos vectoriales están diseñadas para gestionarlos de manera eficiente. Usando diferentes formas de medir qué tan cerca están los vectores entre sí, por ejemplo, qué tan similares son o qué tan separados están, encontramos los vectores que están más cerca de la consulta de usuario dada. Las formas más comunes de medir esto son la distancia euclidiana, la similitud de cosenos y el producto de puntos.
Hay varias bases de datos vectoriales disponibles en el mercado, como Qdrant, SingleStore, Weaviate, etc. Actualmente admitimos Qarant y Tienda única. La clase db vectorial Qdrant se define en /backend/modules/vector_db/qdrant.py, mientras que la clase db vectorial SingleStore se define en /backend/modules/vector_db/singlestore.py
También se pueden agregar otros dbs vectoriales en el vector_db carpeta y se puede registrar en /backend/modules/vector_db/__init__.py
Para añadir cualquier soporte de base de datos vectorial en Cognita, el usuario debe hacer lo siguiente:
Base Vector DB (desde backend.modules.vector_db.base importar BaseVectorDB) e inicialízalo con Configuración de VectorDB (desde backend.types importar VectorDBConfig)crear_colección: Para inicializar la colección/proyecto/tabla en vector db.upsert_documents: Para insertar los documentos en la base de datos.get_collections: Obtenga todas las colecciones presentes en la base de datos.eliminar_colección: Para eliminar la colección de la base de datos.get_vector_store: Para obtener el almacén de vectores de la colección dada.get_vector_client: Para obtener el cliente vectorial para la colección dada, si lo hubiera.lista_data_punto_vectores: Para enumerar los vectores ya presentes en la base de datos que son similares a los documentos que se están insertando.eliminar vectores de puntos de datos: Para eliminar los vectores de la base de datos, se utiliza para eliminar los vectores antiguos del documento actualizado.Ahora mostramos cómo podemos agregar una nueva base de datos vectorial al sistema RAG. Tomamos un ejemplo de ambos Qarant y Tienda única vectores dbs.
Qarant es una base de datos vectorial de código abierto y un motor de búsqueda vectorial escrito en Rust. Proporciona vectores rápidos y escalables búsqueda de similitud servicio con una cómoda API. Para agregar Qdrant vector db al sistema RAG, siga los pasos que se indican a continuación:
En el archivo.env puede agregar lo siguiente
VECTOR_DB_CONFIG = '{"url»: "<url_here>«, «provider»: «qdrant"}' # URL de Qdrant para la instancia implementadaVECTOR_DB_CONFIG=' {"proveedor» :"qdrant», "local» :"true "} '# Para una instancia de Qdrant basada en archivos locales sin Docker
Base de datos vectorial QDRANT en backend/modules/vector_db/qdrant.py que hereda de Base Vector DB e inicialízalo con Configuración de VectorDBcrear_colección método para crear una colección en Qdrantupsert_documents método para insertar los documentos en la base de datosget_collections método para obtener todas las colecciones presentes en la base de datoseliminar_colección método para eliminar la colección de la base de datosget_vector_store método para obtener el almacén vectorial de la colección dadaget_vector_client método para obtener el cliente vectorial para la colección dada, si lo haylista_data_punto_vectores método para enumerar los vectores ya presentes en la base de datos que son similares a los documentos que se están insertandoeliminar vectores de puntos de datos método para eliminar los vectores de la base de datos, utilizado para eliminar los vectores antiguos del documento actualizadoSingleStore ofrece una potente funcionalidad de base de datos vectorial que se adapta perfectamente a aplicaciones basadas en inteligencia artificial, chatbots, reconocimiento de imágenes y más, lo que elimina la necesidad de ejecutar una base de datos vectorial especializada únicamente para sus cargas de trabajo vectoriales. A diferencia de las bases de datos vectoriales tradicionales, SingleStore almacena los datos vectoriales en tablas relacionales junto con otros tipos de datos. La ubicación conjunta de los datos vectoriales con los datos relacionados le permite consultar fácilmente los metadatos ampliados y otros atributos de los datos vectoriales con toda la potencia de SQL.
SingleStore ofrece un nivel gratuito para que los desarrolladores comiencen con su base de datos vectorial. Puedes registrarte para obtener una cuenta gratuita aquí. Al registrarte, ve a Nube -> espacio de trabajo -> Crear usuario. Usa las credenciales para conectarte a la instancia de SingleStore.
En el archivo.env puede agregar lo siguiente
VECTOR_DB_CONFIG = '{"url»: "<url_here>«, «proveedor»: «tienda única"}' # url: mysql://{usuario}: {contraseña} @ {host}: {port}/{db}
Para agregar la base de datos vectorial SingleStore al sistema RAG, siga los pasos que se indican a continuación:
Base de datos vectorial de una sola tienda en backend/modules/vector_db/singlestore.py que hereda de Base Vector DB e inicialízalo con Configuración de VectorDBcrear_colección método para crear una colección en SingleStoreupsert_documents método para insertar los documentos en la base de datosget_collections método para obtener todas las colecciones presentes en la base de datoseliminar_colección método para eliminar la colección de la base de datosget_vector_store método para obtener el almacén vectorial de la colección dadaget_vector_client método para obtener el cliente vectorial para la colección dada, si lo haylista_data_punto_vectores método para enumerar los vectores ya presentes en la base de datos que son similares a los documentos que se están insertandoeliminar vectores de puntos de datos método para eliminar los vectores de la base de datos, utilizado para eliminar los vectores antiguos del documento actualizadoContiene las configuraciones necesarias que definen de forma exclusiva un proyecto o una aplicación RAG. Una aplicación RAG puede contener un conjunto de documentos de una o más fuentes de datos combinadas, lo que denominamos colección. Los documentos de estas fuentes de datos se indexan en la base de datos vectorial mediante métodos de carga, análisis e incrustación de datos. Para cada caso de uso de RAG, el almacén de metadatos contiene:
Actualmente definimos dos formas de almacenar estos datos, una localmente y otros usos True foudry. Estas tiendas se definen en - backend/modules/metada_store/
Una vez que los datos estén indexados y almacenados en una base de datos vectorial, ahora es el momento de combinar todas las partes para usar nuestra aplicación. ¡Los Query Controllers solo hacen eso! Nos ayudan a recuperar la respuesta a la consulta del usuario correspondiente. Los pasos típicos de un controlador de consultas son los siguientes:
nombre de la colección relevante base de datos vectorial se completa con su configuración, como el incrustador utilizado, el tipo de base de datos vectorial, etc.consulta, los documentos relevantes se recuperan mediante el perro perdiguero de vector db.contexto y junto con la consulta a.k.a pregunta se entrega a la LLM para generar la respuesta. Este paso también puede implicar un ajuste rápido.Nota: En el caso de los agentes, las etapas intermedias también se pueden transmitir. La decisión depende de la aplicación específica.
Los métodos del controlador de consultas se pueden exponer directamente como una API, añadiendo decoradores http a las funciones respectivas.
Para agregar su propio controlador de consultas, lleve a cabo los siguientes pasos:
aplicación-2. Por lo tanto, escribiremos nuestro controlador en /backend/modules/query_controller/app-2/controller.pycontrolador de consultas decorador a tu clase y pasa el nombre de tu controlador personalizado como argumentocorreo, conseguir, eliminar para convertir tus métodos en una APIbackend/modules/query_controllers/__init__.pyUn ejemplo de controlador de consultas está escrito en: /backend/modules/query_controller/example/controller.py Consulte para una mejor comprensión
Un proceso típico de Cognita consta de dos fases:
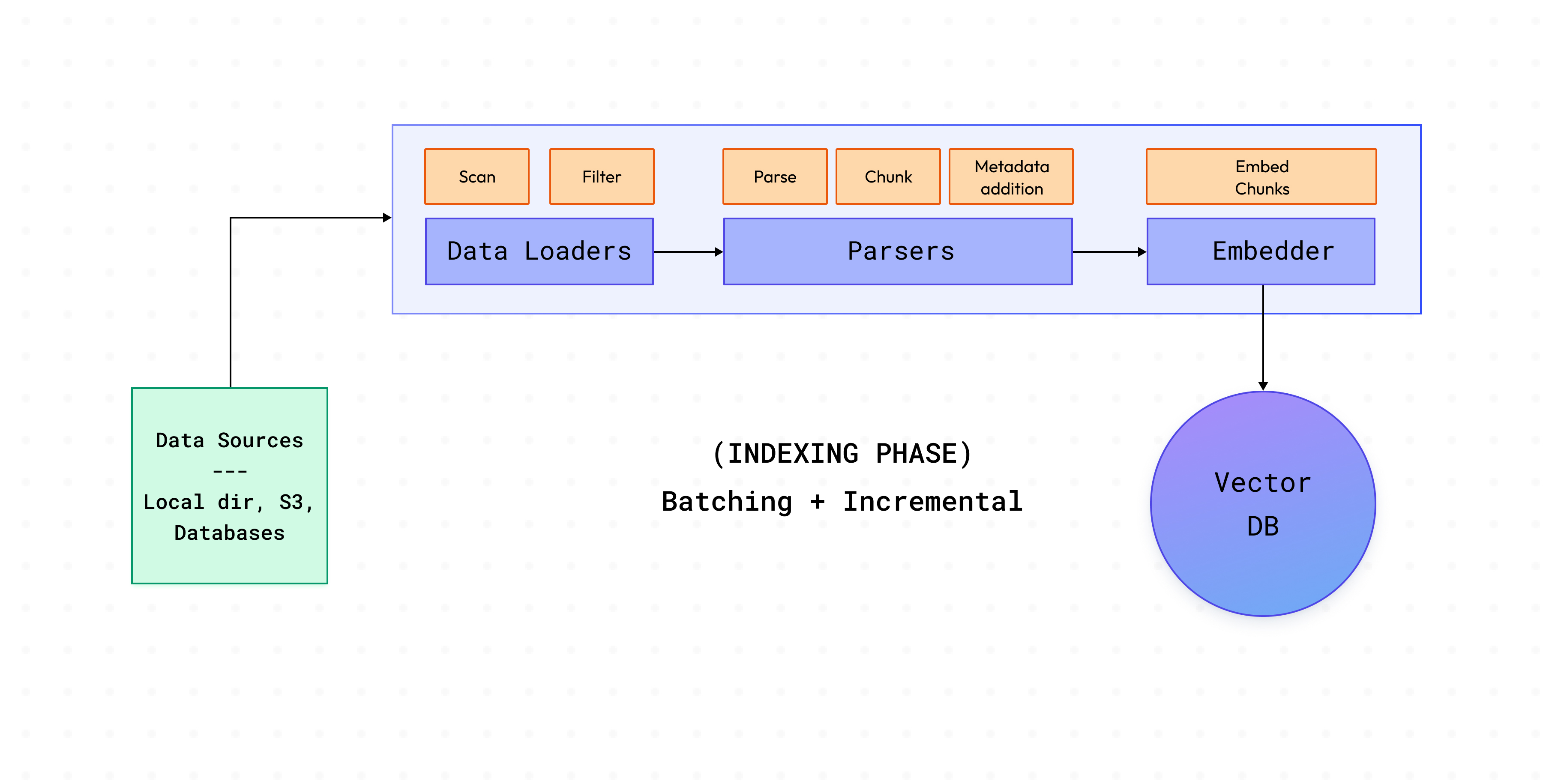
Esta fase implica cargar datos de las fuentes, analizar los documentos presentes en estas fuentes e indexarlos en la base de datos vectorial. Para gestionar las grandes cantidades de documentos que se encuentran en la producción, Cognita va un paso más allá.
INCREMENTAL indexación, también hay otro modo que es compatible con Cognita, que es COMPLETO indexación. COMPLETO la indexación vuelve a introducir los datos en la base de datos vectorial independientemente de los datos vectoriales presentes en la colección dada.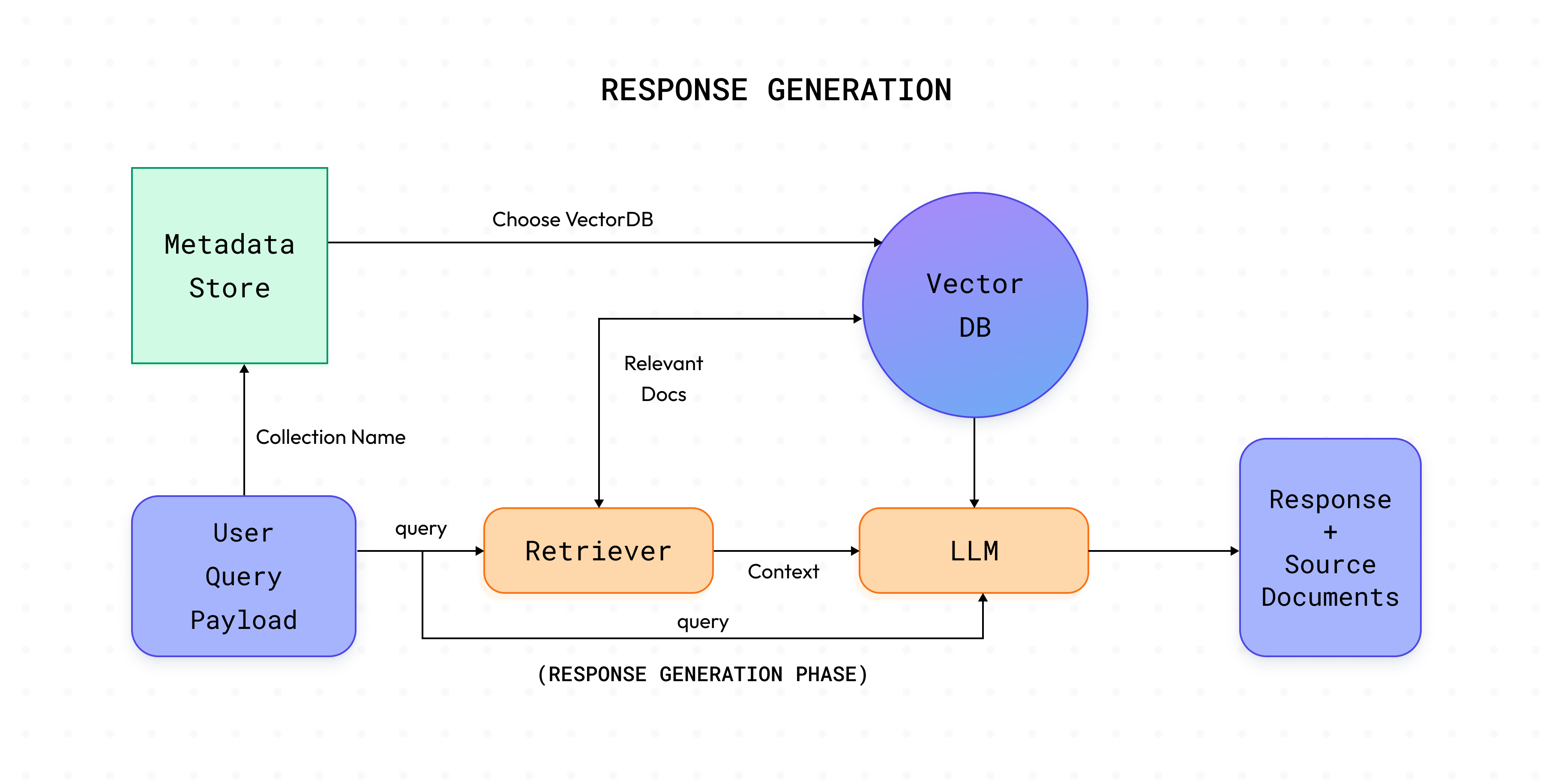
La fase de generación de respuestas hace un llamado al /respuesta punto final de su definido Controlador de consultas y genera la respuesta para la consulta solicitada.
Los siguientes pasos mostrarán cómo usar la interfaz de usuario de cognita para consultar documentos:
1. Crear fuente de datos
Fuentes de datos lengüeta 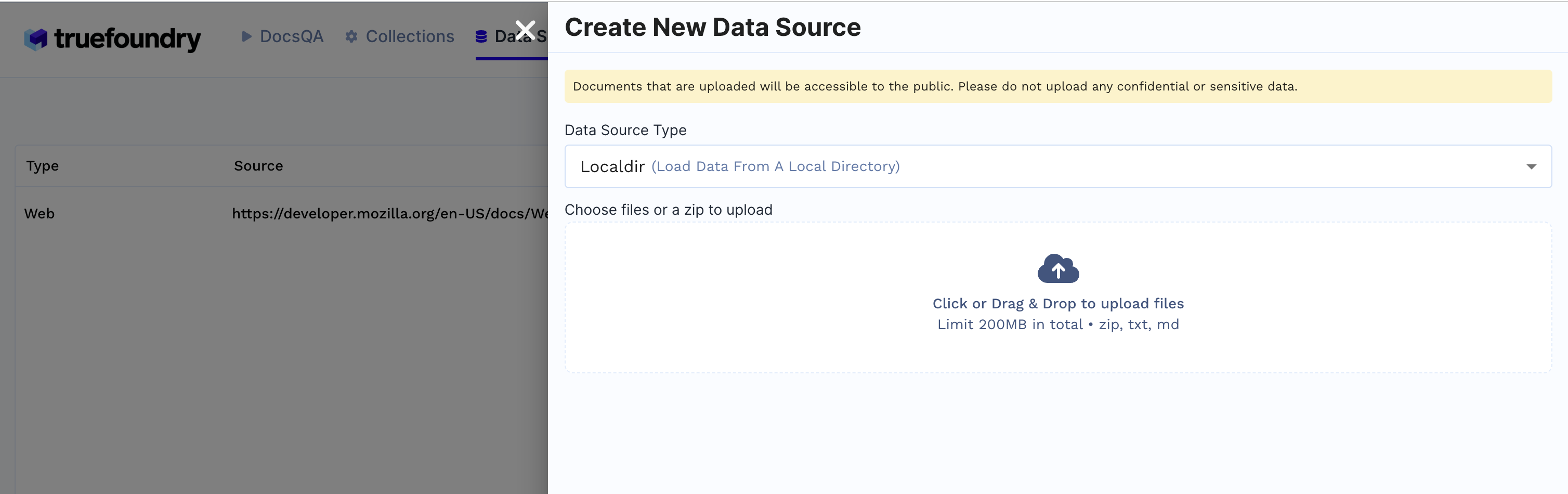
+ Nueva fuente de datosdirectorio local está seleccionado, suba los archivos desde su máquina y haga clic Enviar.
2. Crear colección
Colecciones lengüeta+ Nueva colección 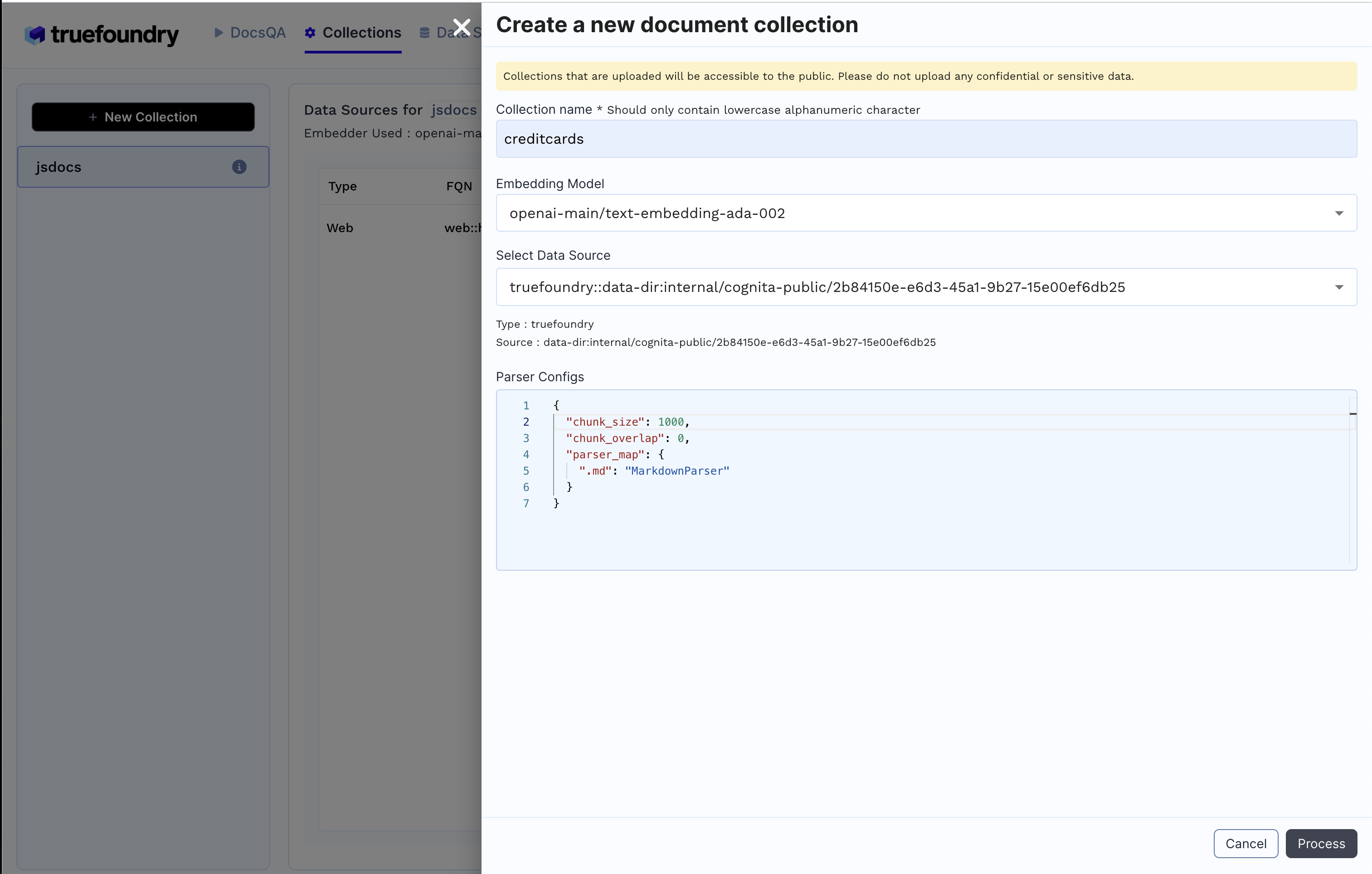
Proceso para crear la colección e indexar los datos. 
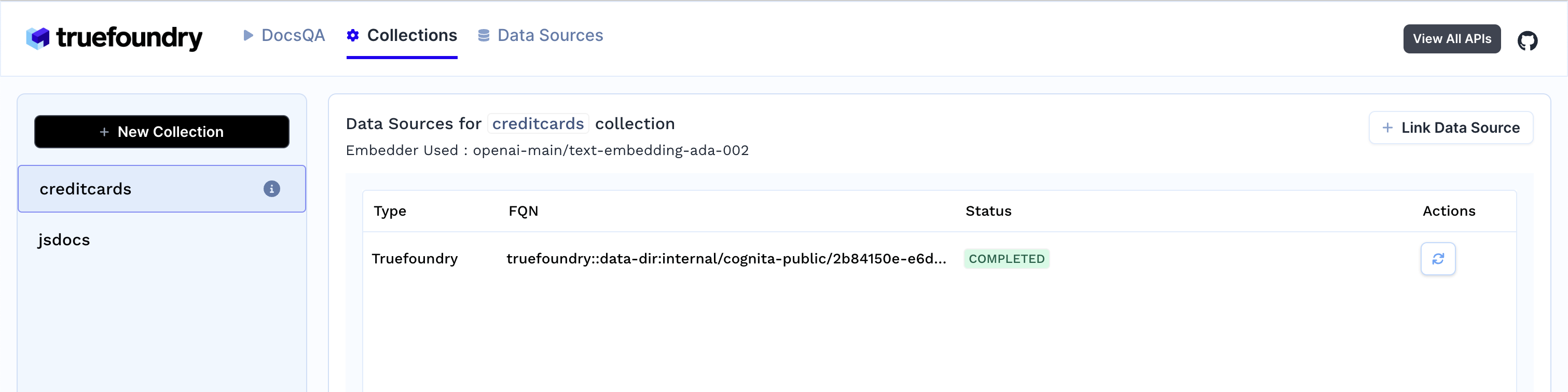
3. Tan pronto como crees la colección, comienza la ingesta de datos. Puedes ver su estado seleccionando tu colección en la pestaña de colecciones. También puedes añadir fuentes de datos adicionales más adelante e indexarlas en la colección.
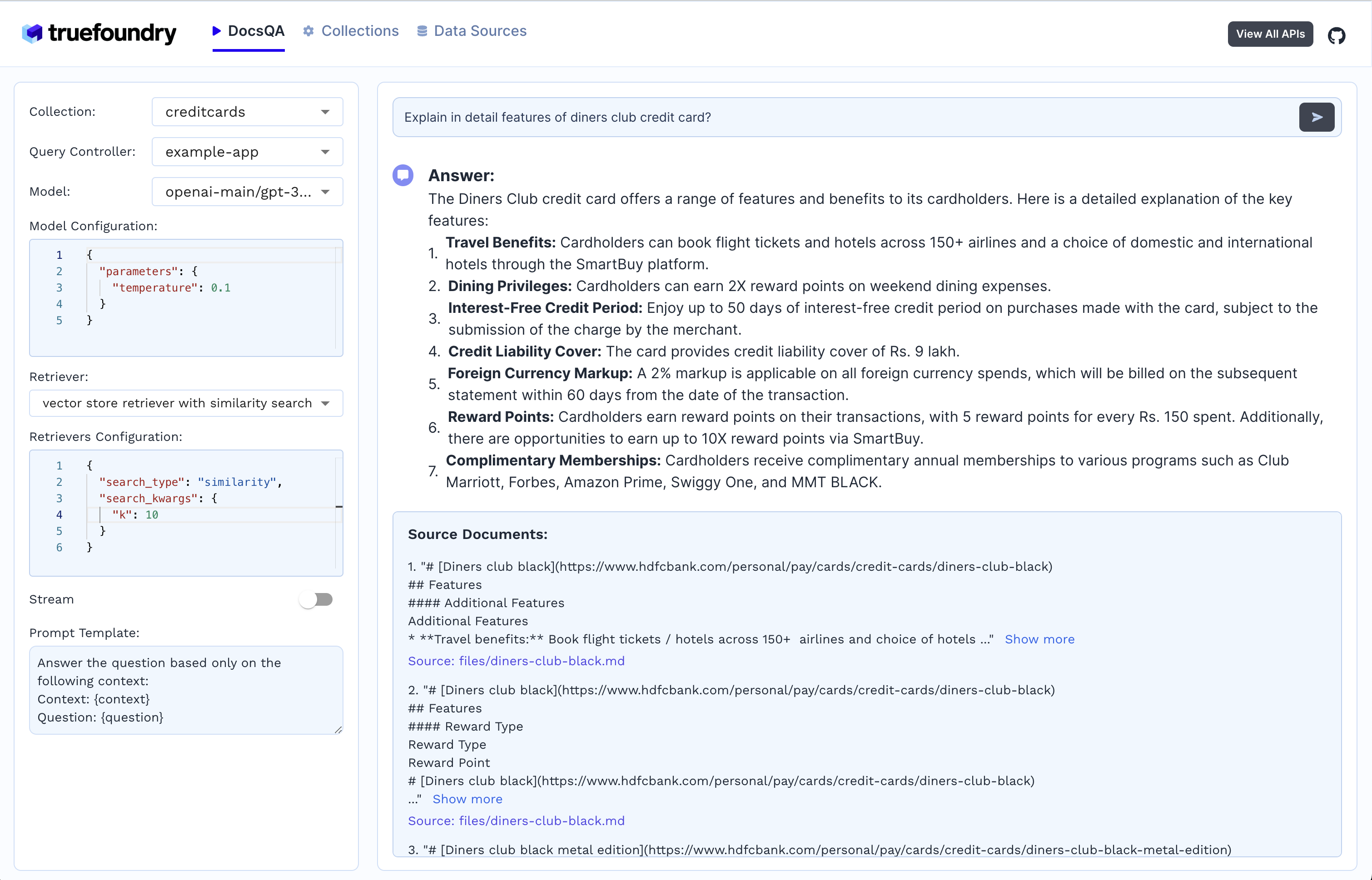
4. Generación de respuestas
Reserva una pDemo personalizada o regístrate hoy para empezar a crear sus casos de uso de RAG.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada












.png)

.webp)
.webp)
.webp)



.webp)
.webp)


