

July 20, 2023
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: April 22, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Los LLMOP, también conocidos como operaciones de modelos lingüísticos grandes, abarcan las prácticas y procesos especializados esenciales para administrar y operar de manera eficiente los modelos lingüísticos grandes (LLM). Los LLM son modelos avanzados de procesamiento del lenguaje natural que tienen la capacidad de generar textos similares a los humanos y realizar una amplia gama de tareas relacionadas con el lenguaje. Estos modelos representan un avance significativo en la IA y han encontrado aplicaciones en varios dominios, como los chatbots, los servicios de traducción, la generación de contenido y más.
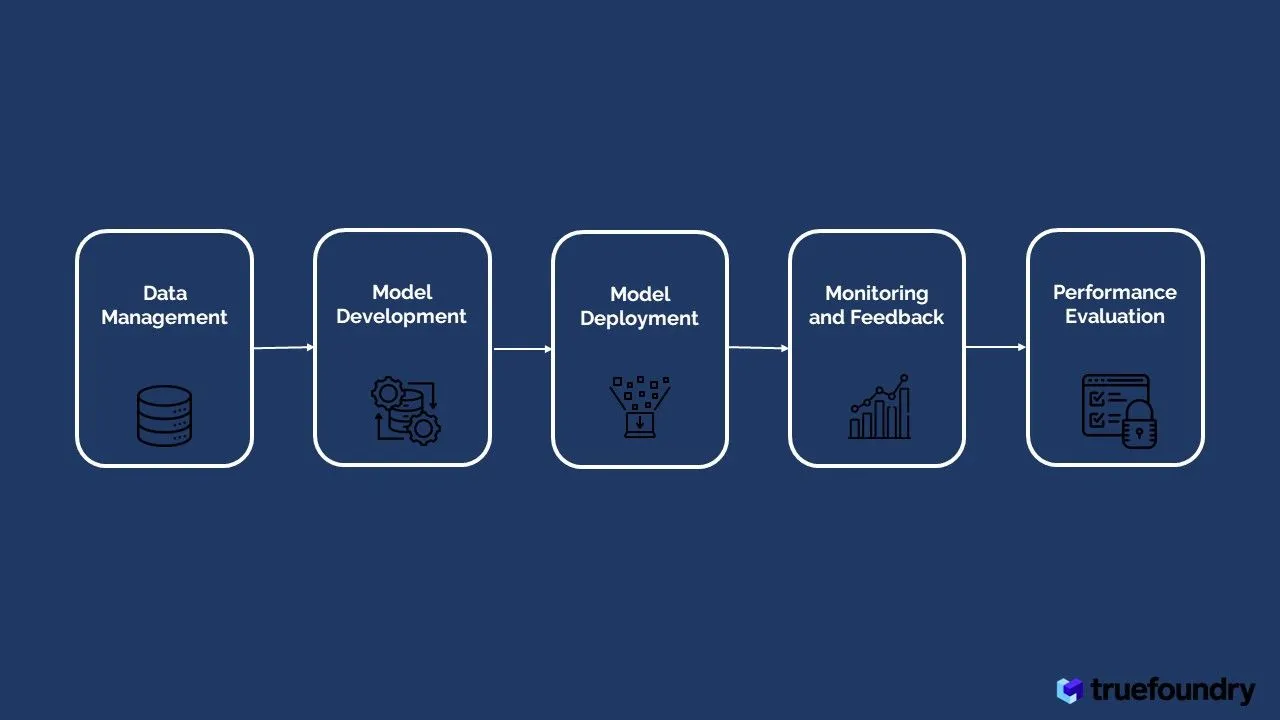
La función de los LLMOP es garantizar el desarrollo, la implementación y el mantenimiento sin problemas de los LLM a lo largo de su ciclo de vida. Implica varias etapas, desde la adquisición y el preprocesamiento de datos hasta el ajuste del modelo, su implementación en producción y su supervisión y actualización continuas para garantizar un rendimiento óptimo.
El desarrollo y la implementación de modelos de lenguaje grande conllevan un conjunto único de desafíos debido a su complejidad y su naturaleza intensiva en recursos:
Si bien las LLMOP comparten similitudes con las MLOP (operaciones de aprendizaje automático) tradicionales, hay algunos aspectos distintos que las diferencian:
Los datos son la piedra angular de todo modelo de lenguaje grande (LLM) exitoso, una poderosa herramienta que ha revolucionado el procesamiento del lenguaje natural. Sin embargo, el paso de los datos sin procesar a un LLM de alto rendimiento implica una serie de pasos cruciales en la gestión de datos. En esta sección, profundizaremos en las complejidades del abastecimiento de datos, el preprocesamiento, el etiquetado y el desarrollo de modelos, y aclararemos los desafíos y las mejores prácticas a los que se enfrentan los equipos de LLMOP en esta etapa crucial de la excelencia lingüística de la IA.
La recopilación de datos diversos y representativos es un desafío monumental que puede afectar significativamente la eficacia de un LLM. Los equipos de LLMOP recorren la vasta extensión de la web y seleccionan multitud de textos, conversaciones y documentos para crear un conjunto de datos sólido y completo. Estrategias como la recopilación de datos web, el aprovechamiento de los repositorios de código abierto y la colaboración con expertos en la materia permiten a los equipos crear conjuntos de datos que reflejen la complejidad del lenguaje en el mundo real.
Una vez recopilados, los datos se someten a un riguroso preprocesamiento para estar listos para el entrenamiento de LLM. Limpiar los datos implica eliminar el ruido y la información irrelevante, y corregir los errores ortográficos y gramaticales. La tokenización divide el texto en unidades significativas, como palabras o subpalabras, lo que permite que el modelo procese y comprenda mejor el idioma. La normalización garantiza la uniformidad al convertir el texto a un formato estándar, lo que reduce las posibles discrepancias durante la formación.
El aprendizaje supervisado exige datos etiquetados, y los equipos de LLMOps invierten un esfuerzo sustancial en la creación de conjuntos de datos anotados para tareas específicas de LLM. La anotación manual por parte de expertos humanos o las plataformas colaborativas ayudan a proporcionar etiquetas para el análisis de opiniones, el reconocimiento de entidades nombradas y mucho más. Técnicas como el aprendizaje activo y el aumento de datos optimizan aún más las iniciativas de etiquetado, ya que utilizan los recursos de manera eficaz para lograr un mejor rendimiento de los modelos.
Los modelos lingüísticos extensos (LLM) son cada vez más importantes en una variedad de aplicaciones, como el procesamiento del lenguaje natural, la traducción automática y la respuesta a preguntas. Sin embargo, los LLM pueden ser complejos y difíciles de administrar. Las bases de datos vectoriales pueden ayudar a simplificar la administración de los LLM al proporcionar una forma de almacenar y buscar sus representaciones vectoriales de gran tamaño.
Una base de datos vectorial es un tipo de base de datos que almacena datos en forma de vectores. Los vectores son un tipo de objeto matemático que se puede usar para representar datos complejos, como texto, imágenes y audio. Las bases de datos vectoriales son adecuadas para almacenar y buscar LLM porque pueden almacenar y recuperar de manera eficiente las grandes representaciones vectoriales que utilizan los LLM.
Hay varias bases de datos vectoriales disponibles, incluidas Pinceone, Milvus, Vespa AI, Qdrant, Redis, SingleStore, Weviate, etc. Estas bases de datos vectoriales proporcionan una variedad de funciones que se pueden utilizar para administrar los LLM. Estos son algunos ejemplos específicos de cómo se pueden usar las bases de datos vectoriales en los LLMOP:
El desarrollo de modelos se encuentra en el centro de las operaciones de modelos de grandes lenguajes (LLMOP), donde comienza la búsqueda de un rendimiento óptimo y la brillantez del lenguaje. En esta etapa crucial, los equipos de LLMOP emprenden un proceso de selección arquitectónica, perfeccionamiento y ajuste de hiperparámetros para convertir los modelos lingüísticos en entidades versátiles y competentes. En este análisis exhaustivo, profundizamos en las complejidades de cada paso y arrojamos luz sobre los desafíos y las técnicas de vanguardia que impulsan la excelencia del lenguaje de la IA.
La elección de la arquitectura LLM adecuada es un factor decisivo que influye profundamente en sus capacidades. Los equipos de LLMOps evalúan meticulosamente varias opciones arquitectónicas, teniendo en cuenta factores como el tamaño del modelo, la complejidad y los requisitos específicos de las tareas previstas. Las arquitecturas basadas en transformadores, como la familia GPT (Generative Pretrained Transformer), han revolucionado el campo del procesamiento del lenguaje natural. Sin embargo, se exploran continuamente arquitecturas novedosas que incorporan innovaciones como los mecanismos de atención, el aumento de la memoria y los cálculos adaptativos para abordar desafíos específicos, mejorar el rendimiento y adaptarse a diversas aplicaciones.
El seguimiento de los experimentos es un aspecto crucial de las operaciones con modelos lingüísticos extensos (LLMOP), ya que permite a los equipos gestionar y analizar sistemáticamente la miríada de experimentos realizados durante el desarrollo de la LLM. Al implementar marcos de seguimiento sólidos, los equipos de LLMOP registran de manera eficiente las configuraciones, los hiperparámetros y los resultados de los modelos, lo que permite tomar decisiones basadas en datos. Fomenta la reproducibilidad, la transparencia y la colaboración, lo que contribuye al proceso de refinamiento y alinea las respuestas del modelo con las expectativas de los usuarios. El seguimiento de los experimentos desempeña un papel fundamental en el enfoque humano, ya que incorpora valiosos comentarios y nos acerca a la realización de la inteligencia basada en el lenguaje de la IA en su máxima expresión.
Los LLM previamente entrenados sirven como punto de partida para ajustar tareas específicas. Este proceso implica adaptar el conocimiento y la comprensión del modelo para sobresalir en las tareas específicas. Los equipos de LLMOP navegan hábilmente por el panorama del ajuste, logrando el equilibrio adecuado entre conservar los conocimientos previamente entrenados del modelo e incorporar información específica sobre las tareas. La selección de los hiperparámetros adecuados, incluidas las tasas de aprendizaje, los tamaños de los lotes y los algoritmos de optimización, desempeña un papel fundamental para lograr el rendimiento deseado. Además, la cantidad de datos de entrenamiento adicionales necesarios para realizar ajustes precisos se determina cuidadosamente para evitar sobreajustar o infrautilizar el potencial del modelo.
Los hiperparámetros sirven como diales que controlan el comportamiento del modelo durante el entrenamiento. Encontrar la configuración óptima de estos hiperparámetros es un paso fundamental para maximizar el rendimiento del modelo. Los equipos de LLMOP emplean una variedad de técnicas para emprender el proceso de ajuste de los hiperparámetros. Desde la búsqueda en cuadrículas hasta la optimización bayesiana y los algoritmos evolutivos, cada método explora el vasto espacio de los hiperparámetros para identificar el punto óptimo en el que el modelo alcanza su máximo rendimiento. Además, se aprovechan enfoques como los cronogramas de tasas de aprendizaje y la reducción del peso para mejorar la generalización y mitigar el sobreajuste.
Los equipos de LLMOP aprovechan los paradigmas de aprendizaje por transferencia y aprendizaje multitarea para mejorar la adaptabilidad y la eficiencia del modelo. El aprendizaje por transferencia implica el entrenamiento previo de un modelo lingüístico en un corpus masivo, seguido de un ajuste específico de las tareas. Esta técnica permite que el modelo se beneficie del conocimiento extraído de una amplia gama de datos lingüísticos. El aprendizaje multitarea permite a los modelos aprender simultáneamente de múltiples tareas, lo que les permite aprovechar las relaciones y los patrones comunes entre las tareas, lo que conduce a una mejor generalización y rendimiento.
El éxito de Modelos de lenguaje extensos (LLM) depende no solo de sus impresionantes capacidades, sino también de su implementación perfecta y de sus operaciones eficientes. En esta fase crucial de las operaciones con modelos lingüísticos extensos (LLMOP), la planificación y ejecución meticulosas son fundamentales. Esta sección profundiza en las complejidades de Despliegue del modelo de IA las estrategias, la importancia de la supervisión y el mantenimiento continuos y el inestimable papel de la retroalimentación humana y la ingeniería rápida en la configuración de los LLM para lograr la excelencia en el lenguaje de la IA.
La implementación de LLM en entornos de producción exige consideraciones estratégicas para garantizar un rendimiento óptimo y la satisfacción del usuario. Los equipos de LLMOP evalúan meticulosamente las estrategias de implementación, teniendo en cuenta los requisitos de infraestructura, la escalabilidad y las consideraciones de rendimiento. La implementación basada en la nube ofrece flexibilidad y recursos bajo demanda, mientras que las soluciones locales satisfacen los problemas de privacidad y seguridad de los datos. La implementación perimetral permite a los LLM operar más cerca de los usuarios finales, lo que reduce la latencia y mejora la interacción en tiempo real. La adopción de la estrategia de implementación más adecuada mejora la disponibilidad y la capacidad de respuesta del LLM, satisfaciendo las diversas necesidades de las aplicaciones en el mundo real.
El despliegue y las operaciones de las LLM requieren un enfoque holístico y colaborativo. Los equipos de LLMOP colaboran con expertos en el campo, especialistas en ética y diseñadores de interfaces de usuario para abordar los desafíos de manera integral. La participación de expertos de diversos campos garantiza que los LLM estén diseñados para servir a industrias y dominios específicos de manera efectiva. Las consideraciones éticas desempeñan un papel crucial a la hora de mitigar los prejuicios y garantizar un despliegue responsable de la IA, creando LLM que sean justos, inclusivos y equitativos en sus interacciones con los usuarios. Los diseñadores de interfaces de usuario mejoran la experiencia general del usuario, haciendo que los LLM sean más intuitivos y fáciles de usar, lo que promueve interacciones fluidas y productivas.
La integración continua (CI) es la práctica de automatizar la creación y las pruebas del código cada vez que se asigna a un sistema de control de versiones. Esto ayuda a garantizar que el código esté siempre funcionando y que cualquier cambio se identifique y aborde rápidamente.
La entrega continua (CD) es la práctica de automatizar la implementación del código en un entorno de producción. Esto ayuda a garantizar que el código se pueda implementar de manera rápida y confiable y que cualquier cambio se revierta si es necesario.
Cuando se combinan CI y CD, forman una canalización de CI/CD. Una canalización de CI/CD puede automatizar todo el proceso de creación, prueba e implementación de modelos de aprendizaje automático. Esto puede ayudar a mejorar la confiabilidad, la eficiencia y la visibilidad del proceso de desarrollo e implementación del modelo de aprendizaje automático.
Estos son algunos de los beneficios de usar CI/CD para LLMOP:
Estos son algunos ejemplos de herramientas de CI/CD para LLMOP:
Estos son solo algunos de los beneficios de usar CI/CD para LLMOP. Si busca mejorar la confiabilidad, la eficiencia y la visibilidad del proceso de desarrollo e implementación de su modelo de aprendizaje automático, la CI/CD es una herramienta valiosa a tener en cuenta.
El monitoreo continuo es el corazón de las operaciones exitosas de LLM. Permite a los equipos de LLMOP identificar y abordar los problemas con prontitud, lo que garantiza un rendimiento y una confiabilidad óptimos. La supervisión abarca las métricas de rendimiento, como el tiempo de respuesta, el rendimiento y la utilización de los recursos, lo que permite una intervención oportuna en caso de cuellos de botella o degradación del rendimiento. Además, detectar sesgos o resultados perjudiciales es fundamental para un despliegue responsable de la IA. Al emplear técnicas de monitoreo basadas en la equidad, los equipos de LLMOP se aseguran de que los LLM funcionen de manera ética, lo que reduce los sesgos no deseados y mejora la confianza de los usuarios. Las actualizaciones y el mantenimiento periódicos de los modelos, facilitados por procesos automatizados, garantizan que el LLM se mantenga actualizado con los últimos avances y tendencias de datos, lo que garantiza una eficiencia y adaptabilidad sostenidas
La retroalimentación humana sirve como una fuerza impulsora crucial para refinar el rendimiento de la LLM. Los equipos de LLMOP adoptan un enfoque centrado en la persona, lo que permite a los expertos y a los usuarios finales proporcionar valiosos comentarios sobre los resultados del LLM. Este proceso iterativo facilita la mejora y el ajuste del modelo, alineando las respuestas del LLM con las expectativas humanas y las necesidades del mundo real. El aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF) es una técnica de aprendizaje automático que entrena a los modelos para generar texto que se ajuste a las preferencias humanas. El RLHF funciona enviando al modelo una señal de recompensa por generar un texto que un evaluador humano considere «bueno». Luego, el modelo aprende a generar texto que maximizará la señal de recompensa. El RLHF se puede utilizar para mejorar el rendimiento de los LLM en una variedad de tareas, como el resumen de textos, la respuesta a preguntas y la generación de diálogos. Al combinar la retroalimentación humana con el aprendizaje automático, RLHF puede crear modelos más precisos, informativos y atractivos.
Además, la ingeniería rápida desempeña un papel fundamental a la hora de guiar a los LLM para que produzcan los resultados deseados. La elaboración de las instrucciones adecuadas ayuda a dirigir las respuestas del modelo, lo que permite a los equipos de LLMOP experimentar y optimizar las instrucciones para diferentes casos de uso, dominios y preferencias de usuario. Como resultado, los LLM se vuelven más controlables, adaptables y eficientes a la hora de ofrecer respuestas significativas
Las pruebas son un aspecto integral de las operaciones con modelos de lenguaje grande (LLMOP) que garantizan la solidez y confiabilidad de los LLM en escenarios del mundo real. Los exhaustivos procedimientos de prueba ayudan a los equipos de LLMOP a validar el rendimiento y la precisión del modelo lingüístico en una amplia gama de tareas y escenarios de entrada. Para evaluar diferentes aspectos de la funcionalidad del LLM, se emplean diversas metodologías de prueba, incluidas las pruebas unitarias, las pruebas de integración y las pruebas integrales. Además, las pruebas de resistencia y las pruebas contradictorias ayudan a identificar las posibles debilidades o vulnerabilidades en las respuestas del modelo, lo que garantiza que pueda gestionar con aplomo las entradas desafiantes y los ejemplos contradictorios. Al realizar pruebas rigurosas, los equipos de LLMOP infunden confianza en las capacidades del modelo, lo que fomenta el despliegue responsable e impactante de los LLMOP en las aplicaciones prácticas.
La evaluación del rendimiento de los modelos de lenguaje grande (LLM) es crucial para evaluar sus capacidades y potencial para diversas tareas de procesamiento del lenguaje natural. Existen numerosos métodos de evaluación, cada uno de los cuales arroja luz sobre diferentes aspectos de la eficacia de un modelo. A continuación se presentan cinco dimensiones de evaluación de uso común que ofrecen información valiosa sobre el rendimiento de los LLM:
La perplejidad es una medida fundamental que se utiliza con frecuencia para evaluar el rendimiento del modelo lingüístico. Cuantifica la eficacia con la que el modelo predice una muestra de texto determinada. Una puntuación de perplejidad más baja indica que el modelo puede predecir mejor la siguiente palabra de una secuencia, lo que sugiere un resultado más coherente y fluido. Esta métrica ayuda a los investigadores y desarrolladores a ajustar sus modelos para mejorar la generación y la comprensión del lenguaje.
Si bien las métricas automatizadas son valiosas, la evaluación humana desempeña un papel fundamental a la hora de evaluar la verdadera calidad de los modelos lingüísticos. Para este enfoque, se recurre a evaluadores humanos expertos para revisar y calificar las respuestas generadas en función de múltiples criterios, como la relevancia, la fluidez, la coherencia y la calidad general. El juicio humano proporciona comentarios subjetivos y capta matices que las métricas automatizadas podrían pasar por alto. Es un paso crucial para comprender qué tan bien funciona el modelo en escenarios del mundo real y permite a los investigadores abordar cualquier inquietud o limitación específica.
Utilizado principalmente en tareas de traducción automática, BLEU compara el resultado generado con una o más traducciones de referencia para medir la similitud entre ellas. Una puntuación BLEU más alta indica que la traducción generada por el modelo se alinea bien con las traducciones de referencia proporcionadas. Ayuda a evaluar la precisión y la eficacia de la traducción del modelo.
ROUGE es un conjunto de métricas que se emplea ampliamente para evaluar la calidad del resumen del texto. Mide la superposición entre el resumen generado y uno o más resúmenes de referencia, teniendo en cuenta la precisión, la memoria y la puntuación de F1. Las puntuaciones ROUGE proporcionan información valiosa sobre la eficacia del modelo lingüístico para generar resúmenes concisos e informativos, lo que las hace inestimables para tareas como el resumen de documentos y la generación de contenido.
Es esencial garantizar que un modelo lingüístico produzca resultados diversos y únicos, especialmente en aplicaciones como los chatbots o los sistemas de generación de texto. Las medidas de diversidad implican analizar métricas como la diversidad de n gramos o medir la similitud semántica entre las respuestas generadas. Los puntajes de diversidad más altos indican que el modelo puede producir una gama más amplia de respuestas y evitar resultados repetitivos o monótonos.
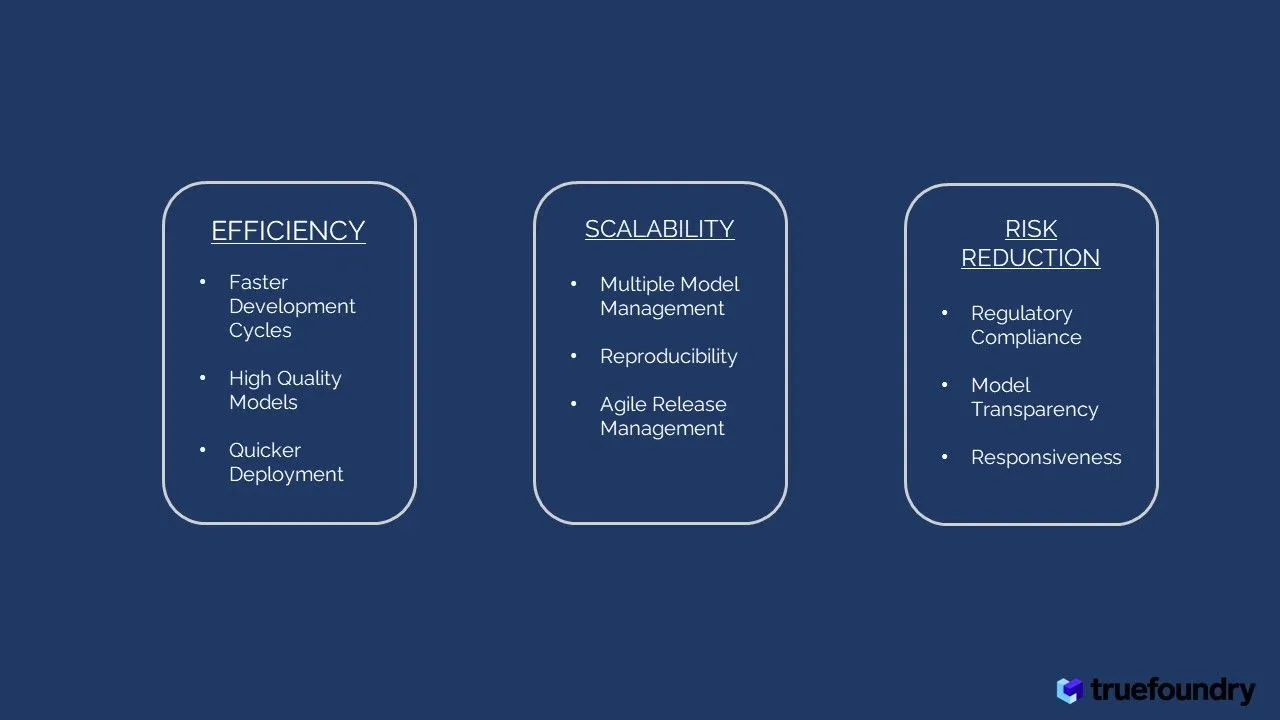
Los LLMOP agilizan el proceso de desarrollo de LLM, lo que genera varios beneficios:
Los LLMOP respaldan la escalabilidad y la reproducibilidad de las canalizaciones de LLM:
LLMops aborda los posibles riesgos asociados con el despliegue de LLM:
En conclusión, los LLMOP desempeñan un papel vital en la gestión del proceso complejo y que consume muchos recursos de desarrollo, implementación y mantenimiento de modelos lingüísticos grandes. Al abordar desafíos únicos y aprovechar técnicas especializadas, los LLMOP garantizan el uso eficiente y ético de estos poderosos modelos de inteligencia artificial en diversas aplicaciones del mundo real.
A medida que el ecosistema de LLM madura, los equipos suelen evaluar diferentes plataformas para identificar las Las mejores herramientas de LLMOps para sus flujos de trabajo específicos, ya sea que incluyan el seguimiento de experimentos, la entrega de modelos, el etiquetado de datos o el monitoreo de la producción.
HuggingFace es una plataforma de código abierto para crear y usar modelos lingüísticos de gran tamaño. Proporciona una biblioteca de modelos previamente entrenados, una interfaz de línea de comandos y una aplicación web para experimentar con modelos. La especialidad de HuggingFace es su enfoque en hacer que los modelos lingüísticos de gran tamaño sean accesibles para todos.
La biblioteca de modelos preentrenados de HuggingFace incluye una amplia variedad de modelos, desde BERT hasta GPT-3. Estos modelos se pueden usar para una variedad de tareas, como la comprensión del lenguaje natural, la generación del lenguaje natural y la respuesta a preguntas. La interfaz de línea de comandos de HuggingFace facilita la carga y el uso de estos modelos, y su aplicación web proporciona una interfaz visual para experimentar con modelos.
ClearML es una plataforma para gestionar experimentos de aprendizaje automático. Proporciona una forma de realizar un seguimiento de los experimentos, almacenar datos y visualizar los resultados. La especialidad de ClearML es su capacidad para rastrear experimentos en múltiples plataformas de aprendizaje automático. Las funciones de seguimiento de experimentos de ClearML facilitan el seguimiento del progreso de sus proyectos de aprendizaje automático. Puede realizar un seguimiento de los parámetros que utilizó, las métricas que midió y los resultados que obtuvo. ClearML también te permite almacenar los datos de tus experimentos para que puedas reproducir fácilmente los resultados.
AWS SageMaker es una plataforma totalmente administrada que proporciona un conjunto completo de capacidades para crear, entrenar e implementar modelos de aprendizaje automático. Incluye una variedad de herramientas y servicios para administrar todo el ciclo de vida del aprendizaje automático, desde la preparación de los datos hasta la implementación del modelo. SageMaker es una opción popular para los LLMOP porque proporciona una serie de funciones diseñadas específicamente para modelos lingüísticos de gran tamaño, como:
Bedrock es una nueva plataforma de AWS diseñada específicamente para la IA generativa. Proporciona una serie de funciones diseñadas para facilitar la creación, el entrenamiento y la implementación de modelos de IA generativa, que incluyen:
Los servicios Azure OpenAI son un conjunto de servicios que permiten usar los grandes modelos de lenguaje de OpenAI en Azure. Estos servicios incluyen un punto final administrado para la familia de modelos GPT-3, un servicio de conversión de texto a código y un servicio de preguntas y respuestas. La especialidad de los servicios Azure OpenAI es su integración con Azure. Los servicios Azure OpenAI facilitan el uso de los grandes modelos de lenguaje de OpenAI en las aplicaciones de Azure. Puede usar el punto final administrado para obtener acceso a un modelo GPT-3 o puede usar el servicio de conversión de texto a código para generar código a partir de descripciones en lenguaje natural. Los servicios Azure OpenAI también ofrecen un servicio de preguntas y respuestas, para que pueda hacer preguntas sobre los modelos de OpenAI y obtener respuestas.
La API Palm de GCP es una API de procesamiento del lenguaje natural que se puede usar para generar texto, traducir idiomas y responder preguntas. Se basa en los LLM de Google, como BERT y GPT-3. La especialidad de la API Palm de GCP es su capacidad para generar texto, traducir idiomas y responder preguntas. La API Palm de GCP ofrece una variedad de funciones para generar texto, traducir idiomas y responder preguntas. Puedes usarla para generar texto realista, traducir idiomas con precisión y responder a las preguntas de forma exhaustiva e informativa. La API Palm de GCP es una herramienta poderosa para los desarrolladores que necesitan usar el procesamiento del lenguaje natural en sus aplicaciones.
LlamaIndex es una plataforma para indexar y buscar modelos lingüísticos de gran tamaño. LlamainDex es especialmente adecuado para los LLMOP, ya que proporciona una variedad de funciones para indexar y buscar LLM, incluidas las consultas rápidas, la clasificación por relevancia y la facetación. La función de consulta rápida de LlamaIndex le permite buscar rápidamente en sus LLM la información que necesita. La función de clasificación por relevancia te permite clasificar los resultados de tus búsquedas en función de su relevancia para tu consulta. La función de facetado te permite filtrar los resultados de tus búsquedas según diferentes criterios.
LangChain es un Plataforma LLMops que ayuda a los equipos a crear, implementar y gestionar modelos lingüísticos de gran tamaño (LLM) a escala. Proporciona una variedad de funciones para administrar los LLM, incluido el control de versiones, el seguimiento de experimentos y el despliegue en producción. La especialidad de LangChain es su capacidad de escalar los LLM para gestionar grandes cantidades de datos. También proporciona una variedad de funciones para monitorear los LLM, de modo que los equipos puedan asegurarse de que funcionan según lo esperado.
Toloka es una plataforma de crowdsourcing que permite etiquetar datos para modelos de aprendizaje automático. Toloka es especialmente adecuada para los LLMOP, ya que se puede utilizar para etiquetar grandes cantidades de datos de forma rápida y eficiente. Toloka tiene una gran cantidad de trabajadores que están disponibles para etiquetar datos las 24 horas del día, los 7 días de la semana. La plataforma ayuda a obtener la opinión humana en todas las etapas del desarrollo de la LLM: la formación previa, el ajuste y la RLHF.
LabelBox es una plataforma basada en la nube para etiquetar datos para modelos de aprendizaje automático. LabelBox es especialmente adecuada para los LLMOP, ya que proporciona una variedad de herramientas y funciones para etiquetar los datos, incluida una interfaz basada en la web, una aplicación móvil y una API REST. La interfaz basada en la web de LabelBox es fácil de usar y se puede acceder a ella desde cualquier dispositivo. La aplicación móvil le permite etiquetar los datos sobre la marcha. La API REST le permite integrar LabelBox con sus flujos de trabajo existentes.
Argilla es una plataforma para administrar e implementar modelos de aprendizaje automático. Argilla es especialmente adecuada para los LLMOP, ya que proporciona una plataforma de curación de datos de código abierto para los LLM que utilizan circuitos de retroalimentación humanos y automáticos. Argilla también tiene una variedad de funciones para administrar modelos, como el control de versiones, el seguimiento de experimentos y el despliegue en producción. El sistema de control de versiones de Argilla le permite realizar un seguimiento de los cambios en sus modelos a lo largo del tiempo. El sistema de seguimiento de experimentos le permite registrar los hiperparámetros y los resultados de sus experimentos. El sistema de implementación en producción le permite implementar sus modelos en entornos de producción.
Surge es una plataforma para implementar modelos de aprendizaje automático en la producción. Surge cuenta con una plataforma dedicada a la tecnología RLHF con funciones clave, como las etiquetadoras especializadas en dominios, la interfaz de experimentación rápida, la experiencia en RLHF y en modelos lingüísticos. Surge sirve para una amplia gama de casos de uso, como la evaluación de búsquedas y la moderación de contenido. Surge es especialmente adecuado para los LLMOP, ya que proporciona varias funciones para implementar modelos en la producción, como el escalado automático, la supervisión y las alertas. La función de escalado automático de Surge te permite escalar automáticamente tus modelos hacia arriba o hacia abajo en función de la demanda. La función de monitoreo le permite realizar un seguimiento del rendimiento de sus modelos en producción. La función de alerta le permite recibir una notificación cuando haya problemas con sus modelos.
Scale es una plataforma integral que impulsa la estrategia de IA generativa, que incluye el ajuste, la ingeniería rápida, la seguridad, la seguridad de los modelos, la evaluación de modelos y las aplicaciones empresariales. También es compatible con el RLHF, la generación de datos, la seguridad y la alineación. La escala es especialmente adecuada para los LLMOP, ya que proporciona una variedad de funciones para administrar modelos a escala, como el escalado automático, el equilibrio de carga y la tolerancia a errores. La función de escalado automático de Scale te permite escalar automáticamente tus modelos hacia arriba o hacia abajo en función de la demanda. La función de equilibrio de carga distribuye el tráfico entre los modelos para garantizar que no se sobrecarguen. La función de tolerancia a fallos permite que sus modelos sigan funcionando incluso si algunos de ellos fallan.
Databricks lanzó recientemente su LLM Open Instruction-Tuned, Dolly. Databricks MLFlow es especialmente adecuado para los LLMOP, ya que se puede usar para rastrear el rendimiento de los LLM a lo largo del tiempo y para implementarlos en entornos de producción. Proporciona un repositorio centralizado para almacenar experimentos, modelos y artefactos de aprendizaje automático. MLFlow de Databricks también proporciona una variedad de funciones para rastrear el rendimiento de los modelos de aprendizaje automático, incluido el seguimiento de experimentos, el control de versiones de los modelos y la administración de artefactos.
Estas son algunas de las características clave de MLFlow de Databricks:
Un conjunto de herramientas LLMOps dentro de la plataforma W&B mLOps, la primera para desarrolladores. Utilice W&B Prompts para visualizar e inspeccionar el flujo de ejecución de la LLM, realizar un seguimiento de las entradas y salidas, ver los resultados intermedios y gestionar de forma segura las solicitudes y las configuraciones de la cadena de LLM. W&B también le permite compartir sus experimentos con otros equipos, lo que puede resultar útil para la colaboración y el intercambio de conocimientos. W&B es especialmente adecuado para los LLMOP, ya que se puede utilizar para hacer un seguimiento del rendimiento de los LLM a lo largo del tiempo y compartirlo con otros equipos.
Estas son algunas de las principales características de W&B:
TrueLens es una plataforma para administrar e implementar modelos lingüísticos de gran tamaño (LLM). TrueLens ofrece una variedad de funciones para administrar los LLM, como el control de versiones, el seguimiento de experimentos y el despliegue en producción. TrueLens utiliza funciones de retroalimentación para medir la calidad y la eficacia de su aplicación de LLM. TrueLens también le permite implementar LLM en una variedad de proveedores de nube, lo que puede resultar útil para la escalabilidad y la confiabilidad. TrueLens es especialmente adecuado para los equipos que utilizan una variedad de marcos de aprendizaje automático, ya que se puede utilizar para gestionar modelos de diferentes marcos.
Estas son algunas de las principales características de TrueLens:
MosaicML le permite ejecutar modelos de código abierto con licencia comercial. Integre fácilmente los LLM en sus aplicaciones. Además, le permite implementar modelos listos para usar o ajustar sus datos. Mosaic ML es una plataforma para crear, implementar y administrar modelos de aprendizaje automático a escala. Mosaic ML proporciona una variedad de funciones para administrar modelos a escala, como el escalado automático, el equilibrio de carga y la tolerancia a errores. Mosaic ML también le permite supervisar el rendimiento de sus modelos en producción, lo que puede ayudarle a identificar y resolver los problemas con rapidez.
Estas son algunas de las principales funciones de Mosaic ML:
Implemente herramientas de LLMOP, como bases de datos vectoriales, servidores de incrustación, etc., en su propia infraestructura de Kubernetes (EKS, AKS, GKE, local), incluida la implementación, el ajuste y el seguimiento de las indicaciones y el suministro de modelos LLM de código abierto con total seguridad de datos y una gestión óptima de la GPU. Entrene y lance su aplicación de LLM a escala de producción con las mejores prácticas de ingeniería de software. TrurFoundry proporciona un ajuste fino 5 veces más rápido y una implementación 10 veces más rápida para los modelos de LLM. TrueFounry también se centra en reducir los costos (un 50% menos) y en la seguridad de los datos para sus operaciones con modelos lingüísticos de gran tamaño.
Run:AI es una plataforma para la gestión integral del ciclo de vida de la LLM, que permite a las empresas ajustar, diseñar rápidamente e implementar modelos de LLM con facilidad. Es especialmente adecuada para despliegues a gran escala, ya que puede ampliarse para gestionar cualquier cantidad de tráfico. La especialidad de Run:AI es su capacidad para automatizar todo el ciclo de vida del aprendizaje automático, desde la preparación de los datos hasta la implementación y la supervisión de los modelos. Esto puede ahorrar tiempo y esfuerzo, y puede ayudar a garantizar que los proyectos de aprendizaje automático se completen a tiempo y dentro del presupuesto
ZenML es una plataforma para crear, administrar y implementación de LLM. Es especialmente adecuado para los equipos que desean automatizar sus flujos de trabajo de LLMOP. La especialidad de ZenML es su facilidad de uso. Proporciona una interfaz de arrastrar y soltar y una biblioteca de componentes prediseñados, para que los equipos puedan crear e implementar canalizaciones de aprendizaje automático de forma rápida y sencilla.
Iguazio permite los aspectos clave de las LLMOP: la automatización del flujo, el procesamiento a escala, las actualizaciones continuas, el rápido desarrollo e implementación de los oleoductos y el monitoreo de modelos. Sin embargo, es necesario adaptar algunos de los pasos. Por ejemplo, es necesario ajustar los pasos de incrustación, tokenización y limpieza de datos, por nombrar algunos. Es especialmente adecuado para los equipos que necesitan implementar aplicaciones de aprendizaje automático en varias nubes. La especialidad de Iguazio es su capacidad de escalar las aplicaciones de aprendizaje automático para gestionar cualquier cantidad de tráfico. También proporciona una plataforma única para administrar todas las implementaciones de aprendizaje automático de un equipo, lo que puede ahorrar tiempo y esfuerzo.
Aviary de Anyscale es una infraestructura de servicio de LLM totalmente de código abierto, gratuita y basada en la nube, diseñada para ayudar a los desarrolladores a elegir e implementar las tecnologías y el enfoque correctos para sus aplicaciones basadas en LLM. Aviary de Anyscals facilita la evaluación continua del rendimiento de varios LLM en comparación con sus datos y la selección e implementación del más adecuado para sus aplicaciones. La especialidad de Anyscale es su servicio gestionado de Kubernetes. Esto facilita la escalabilidad de las cargas de trabajo de aprendizaje automático y garantiza que estén siempre disponibles.
Arize es una plataforma LLMOps que ayuda a los equipos a crear, implementar y administrar LLM para una variedad de tareas, incluida la comprensión del lenguaje natural, la generación del lenguaje natural y la respuesta a preguntas. Proporciona una variedad de funciones para administrar los LLM, incluido el control de versiones, el seguimiento de experimentos y el despliegue en producción. La especialidad de Arize es su capacidad de integrarse con una variedad de otras plataformas de aprendizaje automático, de modo que los equipos puedan utilizar su infraestructura existente. También proporciona una variedad de funciones para monitorear los LLM, de modo que los equipos puedan asegurarse de que están funcionando según lo esperado.
Las herramientas LLMOP de Comet están diseñadas para permitir a los usuarios aprovechar los últimos avances en la gestión de prontas y los modelos de consulta de Comet para iterar más rápido, identificar los cuellos de botella en el rendimiento y visualizar el estado interno de las cadenas de avisos. Comet también ofrece integraciones con las principales bibliotecas y modelos de lenguajes de gran tamaño, como LangChain y el Python SDK de OpenAI. La especialidad de Comet es su capacidad para rastrear experimentos en múltiples plataformas de aprendizaje automático. También proporciona una variedad de funciones para administrar proyectos de aprendizaje automático, de modo que los equipos puedan realizar un seguimiento de su progreso y colaborar de manera eficaz.
PromptLayer es una plataforma para crear e implementar modelos de lenguaje grandes (LLM) como API. Proporciona una variedad de funciones para crear LLM, incluida una biblioteca de componentes prediseñados y una interfaz de arrastrar y soltar. La especialidad de PromptLayer es su capacidad de implementar LLM como API. Esto facilita el uso de los LLM en una variedad de aplicaciones, como los chatbots y los sistemas de preguntas y respuestas.
OpenPrompt es un marco de código abierto para crear e implementar modelos lingüísticos de gran tamaño (LLM). Proporciona una variedad de funciones para crear LLM, incluida una biblioteca de componentes prediseñados y una interfaz de línea de comandos. La especialidad de OpenPrompt es su naturaleza de código abierto. Esto facilita a los equipos la personalización de OpenPrompt según sus necesidades específicas.
Orquesta es una plataforma para orquestar canales de aprendizaje automático. Proporciona una variedad de funciones para orquestar las canalizaciones, incluida una interfaz de arrastrar y soltar y una biblioteca de componentes prediseñados. La especialidad de Orquesta es su capacidad para organizar canalizaciones en múltiples plataformas de aprendizaje automático. Esto facilita la implementación de canales de aprendizaje automático en la producción.
Pinceone es un motor de búsqueda vectorial diseñado para grandes modelos lingüísticos (LLM). Se puede usar para buscar LLM por sus representaciones vectoriales, lo que facilita la búsqueda del LLM que se parezca más a una consulta determinada. La especialidad de Pinceone es su capacidad para buscar LLMs por sus representaciones vectoriales. Por ejemplo, si estás interesado en usar el modelo lingüístico GPT-3, puedes usar Pinceone para buscar LLMs similares al GPT-3. A continuación, Pinceone devolvería una lista de LLM que tienen representaciones vectoriales similares a las del GPT-3. Esto le permitirá encontrar fácilmente el LLM que mejor se adapte a sus necesidades.
Zilliz es una base de datos vectorial diseñada para LLMs. Se puede usar para almacenar y consultar los LLM, así como para rastrear el rendimiento de los LLM a lo largo del tiempo. La especialidad de Zilliz es su capacidad para almacenar y consultar los LLM de manera eficiente. Zilliz es una buena opción para almacenar y consultar los LLM porque está diseñado para ser eficiente con grandes cantidades de datos. Esto significa que puede almacenar y consultar los LLM en Zilliz sin tener que preocuparse por los problemas de rendimiento.
Milvus es una base de datos vectorial diseñada para aplicaciones de aprendizaje automático a gran escala. Se puede usar para almacenar y consultar vectores, así como para realizar búsquedas de similitud. La especialidad de Milvus es su capacidad para realizar búsquedas de similitud de manera eficiente. Milvus es una buena opción para realizar búsquedas de similitud en grandes conjuntos de datos porque está diseñado para ser eficiente con grandes cantidades de datos. Esto significa que puede realizar búsquedas de similitud en grandes conjuntos de datos en Milvus sin tener que preocuparse por los problemas de rendimiento.
Elastic es un motor de búsqueda diseñado para una variedad de aplicaciones, incluida la búsqueda vectorial. Se puede usar para buscar vectores por sus representaciones vectoriales, así como para realizar una búsqueda de similitud. La especialidad de Elastic es su flexibilidad y escalabilidad. Elastic es una buena opción para la búsqueda vectorial porque es flexible y escalable. Esto significa que puedes usar Elastic para una variedad de aplicaciones de búsqueda vectorial y puedes escalar Elastic para satisfacer tus necesidades.
Vespa AI es un motor de búsqueda diseñado para aplicaciones de aprendizaje automático a gran escala. Se puede usar para almacenar y consultar vectores, así como para realizar búsquedas de similitud. La especialidad de Vespa AI es su capacidad para realizar búsquedas de similitudes de manera eficiente y a escala. La IA de Vespa es una buena opción para la búsqueda de similitudes a gran escala porque está diseñada para ser eficiente con grandes cantidades de datos. Esto significa que puedes realizar búsquedas de similitud en grandes conjuntos de datos en Vespa AI sin tener que preocuparte por los problemas de rendimiento.
Searchium AI es un motor de búsqueda diseñado para aplicaciones de procesamiento del lenguaje natural. Se puede usar para buscar documentos de texto, así como para realizar una búsqueda de similitud en el texto. La especialidad de Searchium AI es su capacidad para realizar búsquedas de similitud en documentos de texto. Searchium AI es una buena opción para las aplicaciones de procesamiento del lenguaje natural porque está diseñada para ser eficiente con los datos de texto. Esto significa que puede realizar búsquedas de similitud en documentos de texto en Searchium AI sin tener que preocuparse por los problemas de rendimiento.
Chroma es un motor de búsqueda vectorial diseñado para aplicaciones de procesamiento del lenguaje natural. Se puede usar para buscar documentos de texto, así como para realizar búsquedas de similitud en el texto. La especialidad de Chroma es su capacidad para realizar búsquedas de similitud en documentos de texto en tiempo real. Chroma es una buena opción para la búsqueda de similitudes en tiempo real porque está diseñado para ser eficiente con los datos de texto. Esto significa que puedes realizar búsquedas de similitud en documentos de texto en Chroma sin tener que preocuparte por los problemas de rendimiento.
Vearch es una base de datos vectorial diseñada para aplicaciones de procesamiento del lenguaje natural. Se puede usar para almacenar y consultar documentos de texto, así como para realizar búsquedas de similitud en el texto. La especialidad de Vearch es su capacidad para almacenar y consultar documentos de texto de manera eficiente. Vsearch es una buena opción para almacenar y consultar documentos de texto porque está diseñado para ser eficiente con los datos de texto. Esto significa que puede almacenar y consultar documentos de texto en Vearch sin tener que preocuparse por los problemas de rendimiento.
Qdrant es una base de datos vectorial diseñada para aplicaciones de aprendizaje automático a gran escala. Se puede usar para almacenar y consultar vectores, así como para realizar búsquedas de similitud. La especialidad de Qdrant es su capacidad para realizar búsquedas de similitud de manera eficiente a escala y su compatibilidad con la computación distribuida. Qdrant es una buena opción para la búsqueda de similitudes a gran escala y la computación distribuida porque está diseñado para ser eficiente con grandes cantidades de datos y para soportar la computación distribuida. Esto significa que puede realizar búsquedas de similitud en grandes conjuntos de datos en Qdrant sin tener que preocuparse por los problemas de rendimiento,
A medida que los modelos de lenguaje grande se vuelven más frecuentes en varias aplicaciones, garantizar la privacidad de los datos se ha convertido en una preocupación importante. Las tendencias futuras de los LLMOP harán hincapié en la adopción de técnicas de preservación de la privacidad para proteger los datos confidenciales. El aprendizaje federado es uno de esos enfoques que está ganando terreno, en el que los modelos se entrenan directamente en los dispositivos de los usuarios y solo se comparten con el servidor central las actualizaciones agregadas de los modelos. De esta manera, los LLMOP pueden mitigar los riesgos de privacidad y crear modelos más confiables sin comprometer los datos de los usuarios.
La naturaleza intensiva en recursos de los modelos de lenguaje grande exige esfuerzos continuos para optimizar y comprimir estos modelos. Los futuros LLMOP se centrarán en desarrollar arquitecturas y algoritmos más eficientes que mantengan un alto rendimiento y, al mismo tiempo, reduzcan los requisitos computacionales y de memoria. Técnicas como la cuantificación, la destilación y la depuración desempeñarán un papel crucial en la creación de LLM livianos pero potentes que sean más fáciles de implementar y escalar en varios dispositivos y plataformas.
Las contribuciones de código abierto seguirán impulsando la innovación y la colaboración dentro de la comunidad de LLMOP. A medida que los LLM se conviertan en una parte esencial del panorama de la IA, los investigadores, desarrolladores y profesionales contribuirán activamente a las herramientas, bibliotecas y marcos de trabajo de los LLMOP. Este esfuerzo colaborativo acelerará las prácticas de los LLMOP, mejorará el ajuste de los modelos y fomentará el desarrollo de aplicaciones de vanguardia.
Con la creciente adopción de los LLM en aplicaciones críticas, aumenta la demanda de interpretabilidad y explicabilidad. Los futuros LLMOP se centrarán en las técnicas para hacer que estos modelos sean más transparentes y comprensibles. Métodos como la visualización de la atención, los mapas de prominencia y las explicaciones específicas de los modelos ayudarán a comprender cómo los LLM toman sus decisiones, aumentando la confianza de los usuarios y permitiendo una mejor depuración y mejora de los modelos.
Los modelos de lenguaje grande son solo un componente de los complejos sistemas de IA. En el futuro, los LLMOP se extenderán más allá del ajuste y la implementación de LLM individuales para abarcar una integración perfecta con otras tecnologías de inteligencia artificial. Esta integración facilitará los sistemas de IA multimodales, combinando capacidades de procesamiento de la visión, el habla y el lenguaje para crear soluciones de IA más holísticas y potentes.
La evolución de los modelos de lenguaje grande ha revolucionado el procesamiento del lenguaje natural y ha permitido aplicaciones de IA innovadoras. Sin embargo, su gestión eficaz requiere prácticas y procesos especializados que se encuadren en los LLMOP.
Los LLMOP desempeñan un papel crucial a la hora de abordar los desafíos de desarrollar, implementar y mantener los LLMOP. Al seguir las mejores prácticas, adoptar herramientas y plataformas especializadas y aprovechar técnicas avanzadas, los equipos de LLMOP pueden superar los desafíos computacionales, garantizar la calidad de los datos y optimizar el rendimiento de los modelos.
A medida que el campo de la IA continúe avanzando rápidamente, los LLMOP permanecerán a la vanguardia de la innovación. Las tendencias futuras de los LLMOP se centrarán en las técnicas de preservación de la privacidad, la optimización de los modelos y la explicabilidad para abordar las preocupaciones éticas y los requisitos reglamentarios. Las contribuciones de código abierto fomentarán la colaboración y el intercambio de conocimientos dentro de la comunidad de LLMOP, impulsando el desarrollo de herramientas y marcos más sólidos.
Además, la integración de los modelos de grandes lenguajes con otras tecnologías de IA conducirá a avances interesantes, lo que permitirá que los sistemas de IA multimodales tengan capacidades transformadoras. A medida que los LLMOP evolucionen, desempeñarán un papel fundamental a la hora de aprovechar todo el potencial de los modelos lingüísticos extensos, haciéndolos más accesibles, eficientes y responsables en diversas aplicaciones del mundo real.
En conclusión, los LLMoPS son la columna vertebral de una gestión exitosa de los modelos de grandes lenguajes, ya que garantizan su uso responsable y liberan su poder para dar forma al futuro de la IA. A medida que la IA siga avanzando, los LLMOP allanarán el camino para aplicaciones de IA basadas en el lenguaje más eficientes, confiables y transformadoras.
True Foundry es un PaaS de implementación de aprendizaje automático sobre Kubernetes que permite a los equipos de aprendizaje automático implementar y monitorear modelos en 15 minutos con un 100% de confiabilidad, escalabilidad y la capacidad de retroceder en segundos. En caso de que estés intentando utilizar MLOps en tu organización, estaremos encantados de charlar e intercambiar notas.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada








.png)

.webp)
.webp)
.webp)



.webp)
.webp)


