
July 30, 2026
|
5 minutos de lectura


Obtenga acceso instantáneo a un entorno TrueFoundry en vivo. Implemente modelos, dirija el tráfico de LLM y explore la plataforma completa: su sandbox estará listo en segundos, sin necesidad de tarjeta de crédito.









Published: June 25, 2026

¡Una forma increíblemente rápida de crear, rastrear e implementar sus modelos!
Cuando los agentes pasan de sesiones interactivas a pipelines de CI/CD, el mecanismo de ritmo humano desaparece y los bucles de ReAct aumentan el contexto cuadráticamente. La factura del proveedor le dice cuánto gastó. No puede decirle por qué, ni dónde recortar sin paralizar la velocidad.
Las sesiones interactivas de IA tienen un mecanismo de ritmo incorporado: el humano frente al teclado. El humano lee la salida del agente, decide qué hacer a continuación y consume aproximadamente un prompt cada pocos minutos. Ese ritmo es un límite de tasa suave incluso cuando ninguna política lo impone. [SEG 6] Los pipelines de CI/CD no tienen eso. Un agente configurado para la revisión automatizada de PR puede ser activado cientos de veces por hora por el tráfico de commits ordinario, y no hay nada en su entorno que lo ralentice. Los cálculos son peores de lo que sugiere la frecuencia de activación, porque el costo por llamada en sí mismo aumenta: los frameworks agénticos como ReAct añaden el resultado de cada acción de nuevo a la ventana de contexto antes del siguiente paso de razonamiento. El consumo de tokens por ejecución de agente crece aproximadamente O(n²) en el número de pasos.
.
Figura 1 — Un bucle que parece barato en las pruebas locales —tres pasos, contexto modesto— se convierte silenciosamente en una ejecución de fin de semana de millones de tokens cuando se queda atascado reintentando. La primera vez que la dirección de ingeniería se da cuenta es cuando finanzas reenvía una factura con una cifra que no coincide con el modelo mental de nadie.

El punto ciego de la facturación del proveedor
Sin una atribución granular, finanzas recurre a la única herramienta disponible: las prohibiciones generales. El uso de la IA se pausa a la espera de una revisión. Las cargas de trabajo legítimas se ralentizan junto con las descontroladas. Los líderes de ingeniería aprenden a temer la llamada de cierre mensual. El problema fundamental es que la atribución debe ocurrir en la ingesta, no en la facturación; para cuando llega la factura, las etiquetas que necesitaba ya no están.
La factura del proveedor responde «cuánto». El libro mayor atribuido por la pasarela responde «qué repositorio, qué pipeline, qué paso del agente y qué arreglar». Esa diferencia convierte una crisis financiera en un ticket de ingeniería.
Etiquetado de metadatos a nivel de pasarela
HTTP · encabezado requerido en cada solicitud de CI
Las etiquetas son obligatorias, no opcionales. Las solicitudes sin etiquetar son rechazadas en la pasarela, no se pasan silenciosamente. Esta es la política que produce una observabilidad del 100%: no hay un cubo «desconocido» en el panel, porque no hay una ruta que lo produzca. El costo de la aplicación es una regla de Cedar/OPA. El costo de no aplicarla es una escalada financiera trimestral.
X-TFY-METADATA: {
"team": "payments-platform",
"repo": "transaction-service",
"pipeline": "pr-security-audit",
"agent_step": "step-2-policy-check",
"cost_center": "eng-backend",
"environment": "production"
}
Figura 2 -- Flujo de atribución de costos
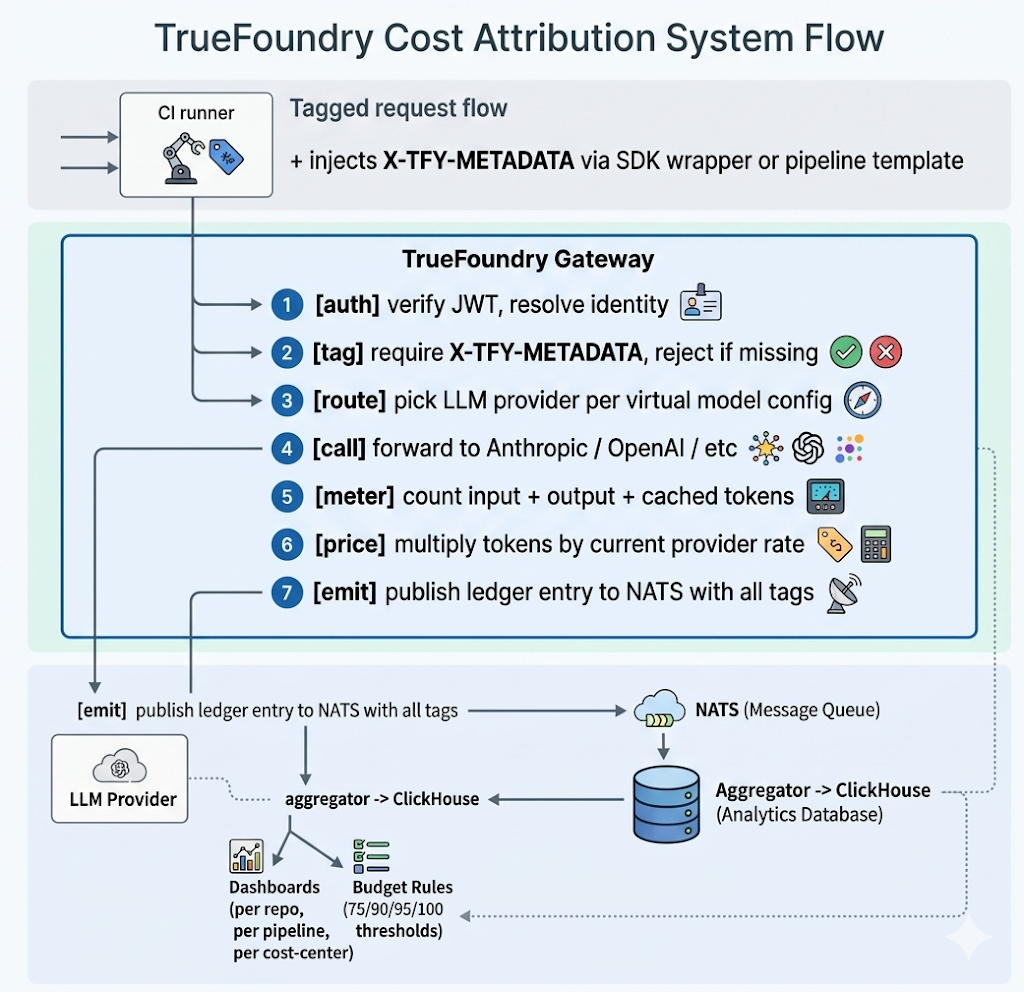
Con las etiquetas a mano, la pasarela cuenta los tokens de entrada, salida y en caché para cada llamada, calcula el precio del resultado según las tarifas actuales del proveedor y registra una entrada de libro mayor completamente atribuida. Las vistas de costos se pueden segmentar por usuario, modelo y equipo de forma predeterminada, con una opción de Descargar datos sin procesar que permite exportar con campos de agrupación personalizados (nombre de usuario, nombre del modelo, equipos o cualquier clave de metadatos que hayas estado etiquetando). Cada dólar tiene un nombre.
La visibilidad sin aplicación es un panel de control en el que nadie actúa. TrueFoundry asigna presupuestos jerárquicos, con cumplimiento matemático estricto, a cada centro de costos que genera el etiquetado. Los presupuestos son una lista ordenada de reglas, cada una definida por sujetos, modelos o claves de metadatos. Dos semánticas distinguen las reglas de presupuesto de las reglas de límite de tasa y vale la pena entenderlas con precisión:
Las alertas de presupuesto se activan en cuatro umbrales configurables —75%, 90%, 95% y 100% del límite—, con canales de notificación para correo electrónico, webhook de Slack y bot de Slack. La verificación se ejecuta cada 20 minutos contra el último libro mayor atribuido:
Tabla 1 — Umbrales de presupuesto. Cada umbral se activa una vez por período presupuestario (día / semana / mes) y se restablece al comienzo del siguiente período. Las alertas se verifican cada 20 minutos.
El comportamiento del 100% es parte del diseño, no una ocurrencia tardía. La pasarela devuelve un error estructurado que nombra el presupuesto agotado e indica al operador el panel de control:
JSON · Respuesta 429 por límite estricto
{
"error": "Budget Exceeded",
"rule_id": "transaction-service-daily",
"detail": "Repository \"transaction-service\" has exhausted its
daily $50 AI budget at 14:32 UTC.",
"mitigation": "Review pipeline logs for infinite loops or request a
quota increase via the platform team.",
"dashboard": "https://gateway.example.com/budgets/transaction-service"
}
Una pipeline que alcanza su presupuesto debería saber qué hacer a continuación sin que el desarrollador tenga que buscar al equipo de la plataforma para obtener contexto. Los ejecutores de CI interpretan el 429 como una señal estándar de retroceso; la compilación falla de forma limpia con un mensaje accionable en lugar de colapsar de maneras confusas.
Hay un comportamiento más que vale la pena conocer: el modo de auditoría. Establecer block_on_budget_exceed: false en cualquier regla mantiene el seguimiento y las alertas activos, pero permite que las solicitudes pasen. Este es el valor predeterminado correcto durante el primer mes de implementación. Observa cómo se activan las alertas contra límites simulados; ajusta los límites; solo entonces activa la aplicación. Saltarse el modo de auditoría es la forma de encontrarse con un equipo enojado cuyas pipelines fallaron todas a las 03:00.
YAML · Configuración de presupuesto en capas
name: cicd-budget
type: gateway-budget-config
rules:
- id: "ml-team-override"
when: { subjects: ["team:ml-engineering"] }
limit_to: 200
unit: cost_per_day
budget_applies_per: ["user"]
- id: "default-user-daily"
when: {}
limit_to: 10
unit: cost_per_day
budget_applies_per: ["user"]
- id: "per-repo-daily"
when: {}
limit_to: 50
unit: cost_per_day
budget_applies_per: ["metadata.repo"]
alerts:
thresholds: [75, 90, 100]
notification_target:
- type: slack-webhook
notification_channel: "ai-budget-alerts"
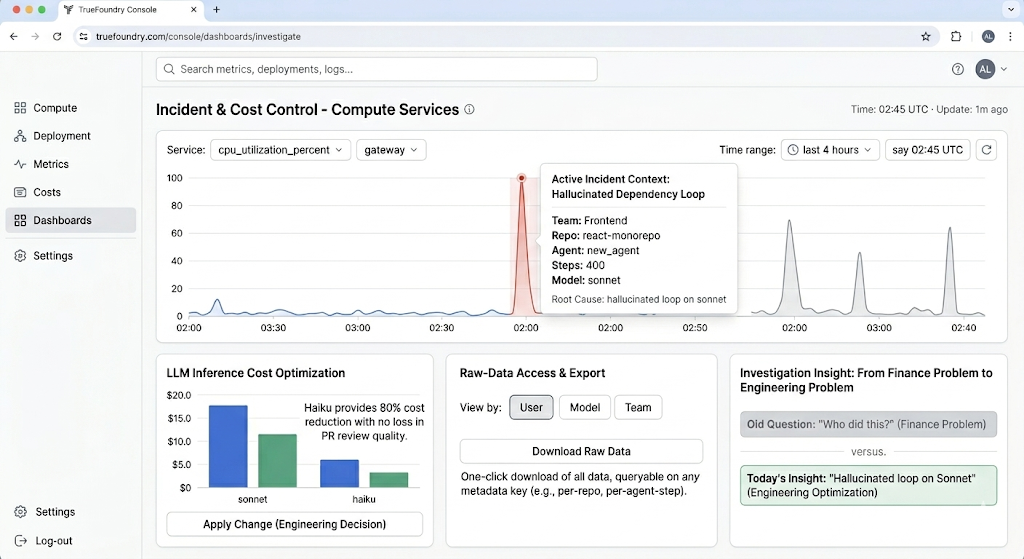
Los datos etiquetados que fluyen a la capa de métricas de la pasarela permiten al equipo de la plataforma construir paneles de control que responden preguntas de propiedad en lugar de producir más ruido agregado. En lugar de mirar un pico y preguntar "¿quién hizo esto?", el panel de control ya te dice que a las 02:00 UTC el equipo de frontend desplegó un nuevo agente en react-monorepo que alucinó una dependencia faltante y entró en un bucle de resolución de 400 pasos.
Ese tipo de contexto operativo convierte el costo de un problema financiero en un problema de ingeniería. Una vez que puedes ver que cambiar el paso inicial de resumen de código de Sonnet a Haiku reduce el costo de ese paso en un 80% sin afectar la calidad de la revisión de PR, realizas el cambio. No discutes sobre los límites de presupuesto en un comité directivo. Las vistas de seguimiento de costos de TrueFoundry se entregan listas para usar para las perspectivas de Usuario, Modelo y Equipo, y la exportación de datos sin procesar te permite segmentar por cualquier clave de metadatos —así, una vista por repositorio, por pipeline o por paso de agente es una descarga con un solo clic, no un proyecto de ingeniería de datos.
Los datos de etiquetado agregados también hacen que la previsión sea manejable. Las cargas de trabajo de agentes son intermitentes —los trabajos pesados y periódicos de CI dominan la factura—, por lo que los promedios móviles simples subestiman sistemáticamente el gasto. La media de los últimos 7 días es la previsión incorrecta para una carga de trabajo cuyo percentil 95 es 4 veces su media.
El modelo adecuado es un pronóstico móvil P95, ejecutado por repositorio y por equipo. El P95 captura el riesgo de picos que un promedio suaviza, proyectando el gasto de fin de mes con suficiente antelación para ajustar presupuestos, aumentar cuotas o detener un pipeline problemático antes de que finanzas se lleve una sorpresa. «Sorpresa» es la palabra clave: este es un pronóstico diseñado para no producirlas. En la práctica, un P95 de 7 días ha rastreado el gasto real de fin de mes con una precisión del 8-12% en las cargas de trabajo que hemos medido, lo suficientemente cerca como para tomar medidas, mucho mejor que la alternativa de la media móvil.
Una organización de 50 ingenieros construyó un agente de revisión de código Claude de tres pasos que se ejecutaba en cada solicitud de extracción (pull request): (1) resumir las diferencias, (2) revisar las diferencias con las políticas de seguridad a través de un servidor de documentación MCP, (3) sugerir cambios en el código. Arquitectura sensata, flujo de trabajo útil, sin señales de alarma obvias.
Con aproximadamente 15 PRs por ingeniero por semana, teniendo en cuenta los reintentos y el costo de la ventana de contexto al inyectar archivos completos en las indicaciones, el agente promedió alrededor de 400.000 tokens de entrada por PR. Factura del primer mes para la automatización de CI/CD: $8.400.
Tabla 2 — Análisis detallado de una depuración de atribución de costos. Cinco clics en la pasarela, un cambio de configuración. Sin atribución, la respuesta habría sido una prohibición general de Sonnet para los flujos de trabajo de CI. Con atribución, la respuesta fue un cambio de configuración de una sola línea.
Esa brecha —entre «prohibir el modelo» y «almacenar en caché una indicación»— es la recompensa total de hacer la atribución correctamente. Los datos de costos existen de cualquier manera; la cuestión es si tienes las etiquetas para leerlos.
¿Deberían los presupuestos denominarse en dólares o tokens?
Ambos, simultáneamente. Los dólares se alinean con las finanzas y la planificación operativa. Los tokens son la métrica de ingeniería que permite depurar la eficiencia de las indicaciones. TrueFoundry rastrea ambos: finanzas posee los paneles de dólares, ingeniería posee los paneles de tokens, y la pasarela es la fuente de verdad para ambos. Los cambios de precios del proveedor se absorben en la capa de dólares sin que ingeniería tenga que refactorizar nada; los nuevos ajustes finos se absorben en la capa de tokens sin que finanzas necesite saber el nombre del modelo.
¿Qué sucede cuando se alcanza un límite estricto a mitad del pipeline?
El pipeline recibe un 429 con el error descriptivo mostrado anteriormente y un enlace al panel de presupuesto. Los ejecutores de CI interpretan el 429 como una señal de retroceso estándar; la compilación falla limpiamente con un mensaje accionable en lugar de colapsar de formas confusas. Los aumentos de cuota se registran como tickets estándar para el equipo de plataforma; la URL del panel en el cuerpo del error evita la ronda habitual de «No entiendo por qué esto está fallando».
¿El etiquetado obligatorio ralentiza el despliegue?
En la práctica, no; los wrappers del SDK manejan la inyección automáticamente dentro de las plantillas de CI, por lo que los desarrolladores individuales nunca editan los encabezados. El costo único es actualizar las plantillas de pipeline del equipo; el costo recurrente es cero. El beneficio recurrente es cada panel, cada alerta y cada análisis post-mortem que le sigue.
¿Cuál es la diferencia entre límites de tasa y límites de presupuesto, y cuándo usar cada uno?
Los límites de tasa detienen los picos; los límites de presupuesto detienen el gasto. Los límites de tasa se denominan en solicitudes/minuto o tokens/minuto; protegen los servicios posteriores de ser sobrecargados y se evalúan por solicitud. Los presupuestos se denominan en dólares por día/semana/mes; protegen la cartera de la empresa y se evalúan contra el libro mayor acumulativo. La mayoría de las pilas de producción ejecutan ambos, con alcance a diferentes entidades. Los patrones son complementarios, no redundantes.
TrueFoundry AI Gateway ofrece una latencia de entre 3 y 4 ms, gestiona más de 350 RPS en una vCPU, se escala horizontalmente con facilidad y está listo para la producción, mientras que LitellM presenta una latencia alta, tiene dificultades para superar un RPS moderado, carece de escalado integrado y es ideal para cargas de trabajo ligeras o de prototipos.











Las últimas noticias, artículos y recursos enviados a tu bandeja de entrada

.webp)
.png)
.webp)




.webp)


.webp)
.png)
.webp)
.webp)
.webp)




