

May 23, 2024
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: June 8, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Large Language Models (LLMs) sind zum Rückgrat moderner KI-Anwendungen geworden und unterstützen alles, von Chatbots und virtuellen Assistenten bis hin zu Recherchetools und Unternehmenslösungen. Allerdings sind nicht alle LLMs gleich — jedes hat seine eigenen Stärken, Grenzen und Kostenfaktoren. Einige zeichnen sich durch hervorragende Argumentation aus, während andere besser darin sind, kreativ zu schreiben, zu programmieren oder strukturierte Abfragen zu bearbeiten. Das ist der Ort, an dem ein LLM-Router kommt rein.
Ein LLM-Router fungiert wie ein intelligenter Verkehrscontroller, der Benutzeraufforderungen automatisch an das für die jeweilige Aufgabe am besten geeignete Modell weiterleitet. Anstatt sich auf ein einziges Modell zu verlassen, können Unternehmen und Entwickler Leistung, Genauigkeit und Kosten optimieren, indem sie Anfragen in Echtzeit an das richtige LLM weiterleiten. Mit der zunehmenden Verbreitung von KI wird LLM-Routing zu einer wichtigen Ebene für den Aufbau skalierbarer, zuverlässiger und effizienter KI-Systeme.
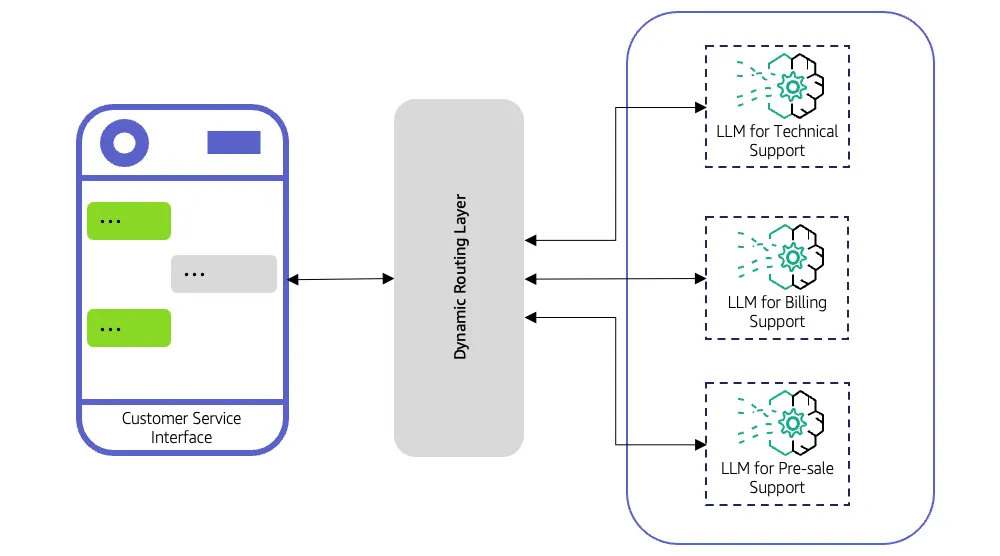
Ein LLM-Router entscheidet, welches Large Language Model jede Anfrage bearbeiten soll. Anstatt jede Anfrage an ein einzelnes Modell zu senden, wertet es die Eingabe aus, wendet Routing-Logik an und leitet sie an das am besten geeignete Modell weiter.
Der Router kann einfache Regeln befolgen, z. B. codebezogene Abfragen an ein programmorientiertes Modell weiterleiten oder fortschrittliche Strategien wie Klassifikatoren, Einbettungen oder einfache Prognosemodelle verwenden, um zu bestimmen, welches LLM die beste Antwort liefert.
So funktioniert's
Dieser Ansatz beseitigt das „Einheitsproblem“. Einfache Modelle verarbeiten Routineabfragen effizient, während komplexe oder überlegungsintensive Aufgaben leistungsfähigeren LLMs zugewiesen werden.
Praktisch befindet sich der Router zwischen Anwendungen und mehreren LLMs, wodurch die Leistung optimiert, die Kosten gesenkt und die Abhängigkeit von einem einzelnen Anbieter minimiert wird. Dieses Setup stellt sicher, dass jede Anfrage das richtige Modell erreicht und gleichzeitig die Zuverlässigkeit und Flexibilität der KI-Systeme gewährleistet ist.
Unternehmen verlassen sich zunehmend auf Large Language Models für Aufgaben, die von Chatbots und virtuellen Assistenten bis hin zur Erstellung von Inhalten und Datenanalysen reichen.
Die Verwendung eines einzigen LLM für alle Aufgaben ist jedoch mit Herausforderungen verbunden. Einige Modelle reagieren schnell, aber es fehlt ihnen an Tiefe, während andere genaue Ergebnisse bei hoher Latenz und hohen Kosten liefern. Ohne eine Möglichkeit, mit diesen Unterschieden umzugehen, gehen Teams ständig Kompromisse zwischen Leistung, Genauigkeit und Budget ein.
Ein LLM-Router löst dieses Problem, indem er Anfragen intelligent an das Modell weiterleitet, das für die Aufgabe am besten geeignet ist.
Stellen Sie sich dieses Szenario vor -
Ein Kundenbetreuungssystem erhält zwei Arten von Anfragen.
Eine einfache Anfrage wie „Was sind deine Arbeitszeiten?“ benötigt kein hochentwickeltes Modell, eine komplexe technische Frage zur Produktfehlerbehebung jedoch schon. Ohne einen LLM-Router gehen alle Anfragen möglicherweise an ein leistungsstarkes, teures Modell. Dies erhöht die Kosten und verlangsamt die Antwortzeiten. Bei einem Router wird die einfache Abfrage an ein schnelles, schlankes Modell weitergeleitet, während die komplexe Anfrage an ein leistungsfähigeres LLM weitergeleitet wird, wodurch Geschwindigkeit, Kosten und Genauigkeit optimiert werden.
Vorteile für Unternehmen
Durch intelligentes Routing von Abfragen stellen Unternehmen schnellere, genauere und kostengünstigere KI-Dienste bereit. LLM-Router verwandeln die KI-Bereitstellung von einem Einheitsansatz in ein flexibles, zuverlässiges und effizientes System, was sie für eine moderne KI-Infrastruktur unverzichtbar macht.
Ein LLM-Router ist mehr als ein Verkehrsleiter. Er bietet mehrere Kernfunktionen, die KI-Systeme intelligenter, schneller und zuverlässiger machen. Das Verständnis dieser Funktionen hilft Unternehmen dabei, KI-Workflows zu entwerfen, die effizient skalierbar sind und gleichzeitig die Qualität beibehalten.
Bevor ein Routing stattfindet, analysiert der Router eingehende Anfragen. Er untersucht Metadaten, Tags, den Abfragetyp, die Komplexität und manchmal auch Absicht oder Stimmung. Diese Analyse liefert den Kontext, sodass der Router entscheiden kann, welches Modell für die Bearbeitung der Anfrage am besten geeignet ist. Beispielsweise kann eine Kundenfrage zur Abrechnung an ein einfaches Allzweck-LLM weitergeleitet werden, während eine technische Anfrage zur Problembehandlung an ein domänenspezifisches Modell gesendet wird.
Der Router wählt das am besten geeignete Modell anhand mehrerer Kriterien aus, darunter:
Durch die Berücksichtigung dieser Faktoren stellt der Router sicher, dass jede Anfrage das beste Gleichgewicht zwischen Geschwindigkeit, Genauigkeit und Kosten erhält.
Wenn mehrere Modelle dieselbe Aufgabe bewältigen können, verteilt der Router Anfragen intelligent, um eine Überlastung eines einzelnen Modells zu vermeiden. Dies verbessert die allgemeine Reaktionsfähigkeit des Systems und gewährleistet eine gleichbleibende Leistung bei Spitzenauslastung.
Selbst die besten Modelle können versagen, ein Timeout haben oder Antworten mit geringem Selbstvertrauen zurückgeben. Der Router implementiert Fallback-Mechanismen und leitet Abfragen automatisch an Backup-Modelle um. Dies gewährleistet Kontinuität und Zuverlässigkeit ohne Benutzerunterbrechung.
Fortschrittliche Router verfolgen Nutzungsmuster, Modellleistung und Abfrageergebnisse. Diese Erkenntnisse helfen Teams dabei, Routing-Strategien zu optimieren, bessere Modelle auszuwählen und die Kosten im Laufe der Zeit zu senken.
Ein LLM-Router fungiert als Entscheidungszentrum für KI-Systeme mit mehreren Modellen. Durch die Analyse von Anfragen, die Auswahl des richtigen Modells, den Lastausgleich, die Behandlung von Fehlern und die Bereitstellung von Erkenntnissen stellt es sicher, dass jede Anfrage effizient, genau und zuverlässig verarbeitet wird. Diese Kombination von Funktionen macht LLM-Router zu einer wichtigen Komponente beim Aufbau robuster, skalierbarer und kostengünstiger KI-Lösungen.
LLM-Router verwenden unterschiedliche Strategien, um Anfragen effizient an das am besten geeignete Sprachmodell weiterzuleiten. Diese Strategien lassen sich im Allgemeinen in drei Kategorien einteilen: statisch, dynamisch und hybrid, wobei fortgeschrittene Systeme manchmal verstärkendes Lernen beinhalten.
Statisches Routing basiert auf vordefinierten Regeln, um zu entscheiden, welches Modell eine Abfrage verarbeitet. Es gewährleistet ein konsistentes Routing-Verhalten und ist einfach zu implementieren.
Das dynamische Routing passt sich in Echtzeit an und wählt Modelle auf der Grundlage der aktuellen Systemleistung und des Abfragekontextes aus.
Hybride Strategien kombinieren statische und dynamische Ansätze für mehr Flexibilität und Effizienz.
Einige fortschrittliche Systeme verwenden Reinforcement Learning, um Routing-Entscheidungen kontinuierlich zu verbessern. Diese Router lernen aus früheren Abfragen und modellieren die Leistung, wodurch sie das Routing im Laufe der Zeit für komplexe oder sich entwickelnde Workloads optimieren.
Ein LLM-Router bietet mehrere wichtige Vorteile, die KI-Systeme effizienter, zuverlässiger und kostengünstiger machen. Einer der Hauptvorteile ist die optimierte Leistung.
Durch die intelligente Weiterleitung jeder Anfrage an das Modell, das für die jeweilige Aufgabe am besten geeignet ist, stellt der Router sicher, dass leistungsstarke, argumentationsfähige Modelle komplexe Fragen behandeln, während schlanke, schnellere Modelle einfachere Anfragen verarbeiten. Dieser Ansatz sorgt für ein ausgewogenes Verhältnis zwischen Geschwindigkeit und Genauigkeit und verbessert das allgemeine Benutzererlebnis.
Ein weiterer wesentlicher Vorteil ist die Kosteneffizienz. Ohne einen Router können Unternehmen alle Abfragen über leistungsstarke Modelle ausführen, was die Betriebskosten unnötig erhöht. Der Router stellt sicher, dass teure Modelle für hochwertige oder komplexe Abfragen reserviert sind, während routinemäßige oder sich wiederholende Aufgaben mit weniger ressourcenintensiven Modellen erledigt werden, wodurch die Rechenkosten gesenkt und der ROI maximiert wird.
Die Zuverlässigkeit verbessert sich auch mit einem LLM-Router. Fortgeschrittene Router verfügen über Fallback-Mechanismen, die Abfragen automatisch umleiten, wenn ein Modell ausfällt, eine Zeitüberschreitung auftritt oder Ergebnisse mit geringer Zuverlässigkeit zurückgibt. Dies gewährleistet eine konsistente und zuverlässige Leistung und verhindert Unterbrechungen bei Echtzeitanwendungen wie Kundensupport oder virtuellen Assistenten.
Darüber hinaus bieten LLM-Router Flexibilität. Unternehmen können mehrere Modelle verschiedener Anbieter integrieren und für jede Aufgabe das beste Modell auswählen.
Dies reduziert die Abhängigkeit von einem einzigen Anbieter und ermöglicht es Teams, mit verschiedenen Modellen zu experimentieren, sobald neue Funktionen hinzukommen.
Schließlich unterstützen Router Skalierbarkeit. Wenn das Abfragevolumen zunimmt, verteilt der Router Anfragen intelligent auf die Modelle, verhindert so eine Überlastung und sorgt für eine reibungslose Systemleistung.
Durch die Kombination von optimiertem Routing, Kosteneinsparungen, Zuverlässigkeit, Flexibilität und Skalierbarkeit transformiert ein LLM-Router KI-Bereitstellungen von einem starren Einzelmodellansatz in ein dynamisches, effizientes und belastbares System.
LLM-Router werden zunehmend in Unternehmen eingesetzt, um die Leistung, Zuverlässigkeit und Effizienz der KI zu optimieren. Sie ermöglichen intelligentes Abfrage-Routing und stellen sicher, dass das richtige Modell jede Aufgabe je nach Komplexität, Domäne und Kontext bewältigt.
Automatisierung des Kundensupports
Unternehmen bearbeiten täglich Tausende von Kundenanfragen, von einfachen FAQs bis hin zu komplexen technischen Problemen. LLM-Router leiten Routinefragen an schnelle, schlanke Modelle weiter und leiten komplizierte Probleme an leistungsfähigere Modelle weiter. Dies gewährleistet schnelle, genaue und konsistente Antworten, verbessert die Kundenzufriedenheit und reduziert die betriebliche Belastung.
Wissensmanagement und Unternehmenssuche
Unternehmen verwalten große Repositorien mit internen Dokumenten, Handbüchern und Richtlinien. Router analysieren Abfragen und leiten sie an Modelle weiter, die für Argumentation, Zusammenfassung oder domänenspezifisches Wissen optimiert sind. Die Mitarbeiter erhalten präzise, kontextrelevante Informationen, ohne teure Modelle zu überlasten.
Workflow- und Aufgabenautomatisierung
LLMs werden häufig für die Erstellung von Berichten, Datenanalysen und Aufgaben zur Entscheidungsunterstützung verwendet. Router weisen leistungsfähigen Modellen dynamisch hochkomplexe Abfragen zu und Routineaufgaben leichteren Modellen zu, sodass Geschwindigkeit, Genauigkeit und Rechenkosten für alle Unternehmensabläufe ausgewogen abgewogen werden.
Orchestrierung mit mehreren Modellen
Unternehmen setzen häufig mehrere LLMs anbieter- oder domänenübergreifend ein. Router verwalten die Modellauswahl, den Lastausgleich und die Fallback-Mechanismen und sorgen so für Zuverlässigkeit, Flexibilität und Skalierbarkeit in großen KI-Systemen.
Produktempfehlungen und Personalisierung
Für E-Commerce- oder SaaS-Plattformen können LLM-Router Modellen, die auf Benutzerverhalten und Kontext trainiert sind, Personalisierungsaufgaben zuweisen und gleichzeitig generische Empfehlungen an einfachere Modelle delegieren. Dies verbessert die Genauigkeit und Leistung der Empfehlungen und kontrolliert gleichzeitig die Kosten.
Compliance und Risikoanalyse
In Finanz-, Rechts- oder Gesundheitsunternehmen können Anfragen die strikte Einhaltung von Vorschriften oder domänenspezifischen Richtlinien erfordern. Router können sensible Anfragen oder Anfragen, bei denen viel auf dem Spiel steht, an Modelle mit Fachkenntnissen weiterleiten, um die Einhaltung der Vorschriften sicherzustellen, während allgemeine Aufgaben mit Standardmodellen erledigt werden.
Generierung und Zusammenfassung von Inhalten
Für Marketing, Wissensaustausch oder Dokumentation können LLM Routers hochwertige Modelle mit komplexen Aufgaben zur Erstellung von Inhalten beauftragen und schnellere Modelle mit einfacheren Zusammenfassungs- oder Entwurfsaufgaben versehen, wodurch die Effizienz optimiert wird, ohne die Ausgabequalität zu beeinträchtigen.
Durch den Einsatz von LLM-Routern in diesen unterschiedlichen Szenarien können Unternehmen KI intelligent skalieren und dabei Leistung, Zuverlässigkeit und Wirtschaftlichkeit über mehrere Workflows und Anwendungen hinweg aufrechterhalten.
Nachdem wir untersucht haben, wie LLM-Router eine Vielzahl von Unternehmensanwendungen unterstützen, ist es wichtig zu verstehen, wie sie sich von einer anderen wichtigen Komponente in KI-Systemen mit mehreren Modellen unterscheiden.
Ein LLM-Router konzentriert sich auf intelligentes Anforderungsrouting. Ihre Hauptfunktion besteht darin, eingehende Abfragen zu analysieren, Kontext, Komplexität und Metadaten zu bewerten und dann jede Anfrage an das am besten geeignete Modell weiterzuleiten. Router verwenden häufig fortschrittliche Strategien wie dynamisches Routing, kontextsensitive Entscheidungsfindung und Fallback-Mechanismen, um Genauigkeit, Geschwindigkeit und Kosten zu optimieren.
Sie sind besonders wichtig in Umgebungen, in denen Abfragen in Bezug auf Typ, Domäne oder Rechenanforderungen stark variieren, sodass Unternehmen die Last ausgleichen und eine hohe Leistung aufrechterhalten können.
Ein LLM-Gatewayfungiert andererseits als zentraler Zugangspunkt für die Interaktion mit einem oder mehreren LLMs. Ihre Hauptaufgabe besteht darin, die Integration zu vereinfachen, standardisierte APIs bereitzustellen, die Authentifizierung zu verwalten, die Ratenbegrenzung zu regeln und die Nutzung zu überwachen.
Im Gegensatz zu Routern treffen Gateways in der Regel keine intelligenten Entscheidungen zur Modellauswahl. Sie bieten einheitliche Zugriffs- und Betriebskontrollen, um Bereitstellungen mit mehreren Modellen zu ermöglichen. Gateways konzentrieren sich eher auf die Verwaltung, Sicherheit und Skalierbarkeit auf Infrastrukturebene als auf Optimierung auf Abfrageebene.
Die wichtigsten Unterschiede
Router und Gateways arbeiten oft in geschichteten Architekturen zusammen. Das Gateway bietet einen sicheren, standardisierten Einstiegspunkt für Anwendungen, während sich der Router dahinter befindet und intelligente Entscheidungen zur Modellauswahl trifft. Diese Kombination ermöglicht Unternehmen sowohl eine betriebliche Kontrolle als auch eine optimierte Abfrageverarbeitung.
Wenn Unternehmen den Unterschied zwischen LLM-Routern und LLM-Gateways verstehen, können Unternehmen KI-Systeme mit mehreren Modellen effektiv einsetzen.
Router sorgen für intelligente, kontextsensitive Leistung, während Gateways einen sicheren, skalierbaren und zuverlässigen Zugriff gewährleisten und so eine robuste Grundlage für KI in Unternehmen schaffen.
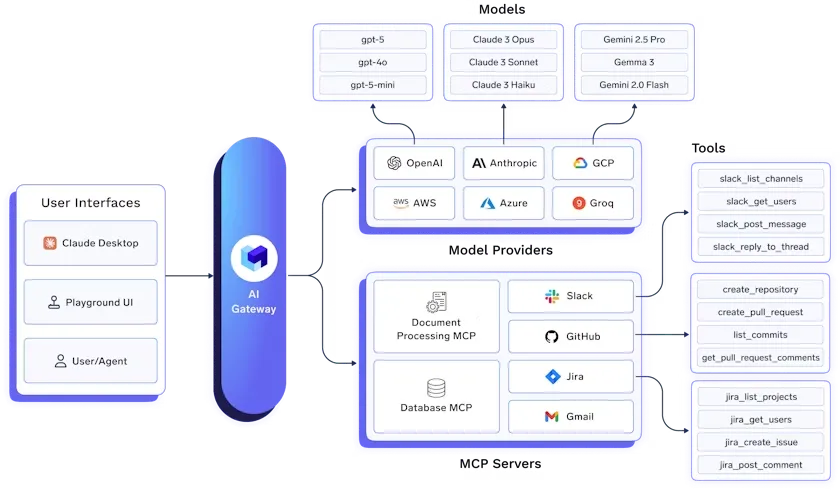
Das TrueFoundry LLM Gateway ist eine unternehmenstaugliche Plattform, die den Zugriff auf alle wichtigen großen Sprachmodelle (LLMs) über eine einzige, sichere und leistungsstarke API vereinheitlicht.
Es vereinfacht die GenAI-Infrastruktur durch die Integration von über 250 Modellen, darunter OpenAI, Anthropic Claude, Gemini, Groq, Mistral und Open-Source-Frameworks, ohne dass Codeänderungen erforderlich sind. Teams können eine einheitliche API für Chat, Abschluss, Einbettung und Neueinteilung von Workloads verwenden und gleichzeitig die Authentifizierung und die API-Schlüsselverwaltung zentralisieren.
Die wichtigsten Funktionen:
Da Unternehmen zunehmend auf mehrere Large Language Models angewiesen sind, sind Tools wie LLM-Router und LLM-Gateways für die Verwaltung von KI in großem Maßstab unverzichtbar geworden. LLM-Router bringen Intelligenz ins System, analysieren jede Abfrage und stellen sicher, dass sie das für die jeweilige Aufgabe am besten geeignete Modell erreicht. Dies verbessert die Leistung, senkt die Kosten und erhöht die Zuverlässigkeit, insbesondere bei komplexen Workflows mit hohem Volumen.
Gateways bilden unterdessen das Rückgrat für den sicheren, standardisierten Zugriff auf Modelle und vereinfachen so die Integration, die Überwachung der Nutzung und die Durchsetzung betrieblicher Kontrollen.
Zusammen bilden diese Komponenten eine mehrschichtige KI-Architektur, die Intelligenz mit betrieblicher Effizienz in Einklang bringt. Durch die Kombination der Entscheidungsfunktionen von Routern mit der strukturellen Zuverlässigkeit von Gateways können Unternehmen den Wert mehrerer LLMs maximieren und gleichzeitig Skalierbarkeit und Kontrolle beibehalten.
Die Einführung von LLM-Routern ist nicht mehr optional; sie ist eine Notwendigkeit für Unternehmen, die schnelle, genaue und kostengünstige KI-Dienste bereitstellen wollen. Das Verständnis ihrer Rolle und der Gateways ermöglicht es den Teams, robuste KI-Infrastrukturen zu entwerfen, die den unterschiedlichen Geschäftsanforderungen gerecht werden.
Da sich KI-Modelle ständig weiterentwickeln und vermehren, wird die Beherrschung von intelligentem Routing und strukturiertem Zugriff für Unternehmen, die in der sich schnell entwickelnden KI-Landschaft wettbewerbsfähig bleiben wollen, von entscheidender Bedeutung sein.
LLM-Routing funktioniert, indem eingehende Anfragen anhand vordefinierter Logik, semantischer Einbettungen oder Klassifizierungsregeln bewertet werden. Das System leitet den Datenverkehr auf der Grundlage des Kontextes, der erforderlichen Genauigkeit oder der Latenz des Upstream-Providers weiter. Ein zentrales Gateway verwaltet diese komplexen Konfigurationen, um die Modellauswahl und den Failover zu automatisieren, ohne dass bei jeder Modellaktualisierung manuelle Codeänderungen erforderlich sind.
Die LLM-Routing-Klassifizierung verwendet ein hocheffizientes Modell, um Prompts vor der Inferenzausführung zu kategorisieren. In diesem Schritt wird die Absicht identifiziert, z. B. einfache Begrüßungen im Vergleich zu komplexen Codierungsaufgaben. Die automatische Klassifizierung verhindert die übermäßige Nutzung teurer Frontier-Modelle, indem Abfragen mit geringer Komplexität nach kleineren, schnelleren und kostengünstigeren Alternativen gefiltert werden.
TrueFoundry vereint LLM-Routing- und AI-Gateway-Funktionen, indem es die Verkehrsorchestrierung mit Governance und Sicherheit verbindet. Die Plattform kümmert sich um Modell-Failover, Ratenbegrenzung und kostenbewusstes Routing innerhalb einer einzigen zentralen Steuerungsebene. Diese Infrastruktur stellt sicher, dass KI-Bereitstellungen in Unternehmen für große Produktionsumgebungen äußerst robust und kostengünstig sind.
Zu den besten LLM-Routern gehören TrueFoundry für Orchestrierung auf Unternehmensebene, LitelLM für eine einheitliche Proxy-API und Martian für die automatisierte Modellauswahl. Zu den weiteren branchenweit führenden Optionen gehören Portkey für erweiterte Guardrails, Helicone für blitzschnelle Observability und OpenRouter für den einfachen Zugriff auf Hunderte von Open- und ClosedSource-Modellen.
LLM-Router untersuchen Abfragemetadaten, -typ und -kontext, um ein Modell auszuwählen. Zu den Auswahlfaktoren gehören Fachwissen, Argumentationsfähigkeit, Latenz und Kosten. Einfache Abfragen beziehen sich auf einfache Modelle, komplexe Aufgaben auf Modelle mit hoher Kapazität. Fortgeschrittene Router können Einbettungen oder prädiktive Klassifikatoren für das intelligente Modell-Routing in Echtzeit verwenden.
Zu den Kernfunktionen eines LLM-Routers gehören Anforderungsanalyse, intelligente Modellauswahl, Lastausgleich, Fallback-Behandlung und Überwachung. Router verteilen Abfragen auf mehrere LLMs, leiten fehlgeschlagene Anfragen um und verfolgen die Leistung. Dadurch wird sichergestellt, dass Aufgaben effizient verarbeitet werden, Modelle optimal genutzt werden und das System in KI-Workflows von Unternehmen zuverlässig und skalierbar bleibt.
Zu den gängigen Typen von LLM-Routern gehören regelbasiertes Routing, kostenbasiertes Routing, leistungsbasiertes Routing und aufgabenbasiertes Routing. Regelbasierte Router folgen vordefinierten Bedingungen, kostenbasierte Router wählen günstigere Modelle, leistungsbasierte Router wählen Modelle mit besserer Genauigkeit oder Geschwindigkeit aus, und aufgabenbasierte Router senden Anfragen an Modelle, die auf Aufgaben wie Codierung, Chat oder Zusammenfassung spezialisiert sind.
Das LLM-Routing erfolgt, indem die Benutzeranfrage analysiert und an das am besten geeignete Modell weitergeleitet wird. Entwickler definieren Regeln oder verwenden Algorithmen, die Faktoren wie Aufgabentyp, Kosten, Latenz und Modellfähigkeit berücksichtigen. Eine Routing-Ebene wertet die Eingabe aus und sendet die Anfrage automatisch an das entsprechende LLM.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.








.png)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




