

July 1, 2026
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 27, 2026
Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Die Plattform von Vercel, insbesondere das KI-SDK und das One-Click Bereitstellen bei Push Der Workflow erleichtert es Frontend-Teams, KI-Demos innerhalb von Minuten zum Laufen zu bringen. Das Vercel AI SDK ist ein kostenloses Open-Source-Toolkit, mit dem Teams KI-Funktionen schnell bereitstellen können.
Die Preisgestaltung von Vercel war jedoch ursprünglich für statische Websites und kurzlebige Webfunktionen konzipiert. Sobald die KI-Arbeitslast einer App langwierig wird, z. B. das Streamen mehrstufiger Agentenantworten oder umfangreiche RAG-Pipelines, ändert sich das KI-Preismodell von Vercel dramatisch.
Anstatt fester monatlicher Raten zahlen Sie ab sofort pro Millisekunde serverloser Ausführungszeit und Gigabyte an übertragenen Daten. In der Praxis stellen Teams fest, dass ihre vorhersehbaren Rechnungen von 20$ pro Monat sprunghaft ansteigen, wenn Chatbots und Agenten an die Ressourcengrenzen von Vercel stoßen.
In diesem Leitfaden wird beschrieben, wie die Preisgestaltung von Vercel AI funktioniert, welche versteckten Gebühren für KI-Workloads anfallen und warum Entwicklungsteams schließlich auf private Cloud-Plattformen wie TrueFoundry migrieren, um diese Kosten zu vermeiden.
Um mehr über die AI-Gateway-Landschaft und die Überlegungen zu erfahren, die vor der Auswahl eines Anbieters zu berücksichtigen sind, lesen Sie den vollständigen Artikel Der Gartner-Marktleitfaden für KI-Gateways 2025 finden Sie hier.
.webp)
Vercel verwendet jetzt eine Hybrid-Modell Kombination von Benutzerlizenzen mit Nutzungskontingenten und Überschreitungsgebühren. Einfach ausgedrückt: Die Nutzung durch Hobbyanwender ist kostenlos, aber die Kosten für die professionelle Nutzung steigen mit der Größe Ihres Teams und Ihren Rechenanforderungen. Im Folgenden finden Sie eine Zusammenfassung der einzelnen Stufen und ihrer Auswirkungen auf KI-Anwendungen.
Das Hobby plan ist „der perfekte Ausgangspunkt für Ihre Web-App oder Ihr persönliches Projekt“ und ist für immer kostenlos. Es ist strikt auf den persönlichen und nichtkommerziellen Gebrauch beschränkt — die geschäftliche oder umsatzgenerierende Nutzung des Hobby-Tarifs verstößt gegen die Bedingungen von Vercel. Hobby beinhaltet großzügige Funktionen (CDN, 1 Million Edge-Anfragen/Monat, einfache WAF), aber sehr enge Rechenlimits. Insbesondere können Funktionen auf Hobby nur für bis zu 60 Sekunden (Standard), weil Dauer der Funktion ist bei kostenlosen Tarifen begrenzt (und nur geringfügig anpassbar). KI-Anwendungen müssen häufig Antworten streamen oder Agenten-Loops ausführen, die länger als eine Minute dauern. Bei Hobby werden diese langen Aufgaben einfach Auszeit mit 504 Fehlern. Kurz gesagt, wenn Ihre KI-Demo eine dauerhafte Berechnung benötigt (z. B. eine komplexe Abfrage oder Vektorsuche), wird Hobby wahrscheinlich den Vorgang abbrechen, bevor das Ergebnis eintrifft. In der Praxis stellen Teams fest, dass selbst mäßig komplexe LLM-Anrufe oder Agentenketten die Laufzeitlimits von Hobby überschreiten. Das kostenlose Kontingent eignet sich daher gut für Prototypen und leichte Experimente, aber ungeeignet für KI-Workloads in der Produktion, die erweiterte Rechen- oder Streaming-Ausgaben erfordern.
Das Profi Plan beginnt um 20$ pro bereitstellenden Benutzer und Monat. (Jeder Entwicklersitz kostet 20$ pro Monat; du kannst unbegrenzt kostenlose Zuschauerplätze hinzufügen.) Pro rechnet diese Hobbykontingente in höhere Limits um, allerdings mit Kosten. Pro beinhaltet zum Beispiel 1 TB Bandbreite pro Monat (etwa 350$ im Wert) — das Zehnfache der 100 GB, die in Hobby enthalten sind. Ab 1 TB wird für ausgehenden Datenverkehr ein Betrag in Rechnung gestellt 0,15 $/GB. Pro erhöht auch die mitgelieferte Funktion compute: standardmäßig kommst du herum 1.000 GB-Stunden der serverlosen Ausführung pro Monat (für alle Funktionen) — ungefähr das, was ein Entwickler, der kleine Aufgaben ausführt, verbrauchen würde — bevor der Mehrpreis bezahlt wird.
KI-Workloads überschreiten diese Grenzen jedoch extrem schnell. Jeder offene Stream oder jede lange Inferenz beansprucht Speicher und CPU-Zeit. In der Praxis berichten Entwickler, dass die Pro-Kontingente innerhalb weniger Tage ausgeschöpft sind: Ein Beispiel zeigte einen bereitgestellten Screenshot-Dienst mit 494 GB-Stunden in nur 12 Tagen des Testens, Projizierens 1.276 GB-Stunden in einem Monat. Da Vercel nach der Ausführungszeit abrechnet, würden die 1.276 GB-Stunden dieses Arbeiters einen zusätzlich 160 $/Monat (bei etwa 0,18 $/GB-Stunde) über den Basisplan hinaus. Kurz gesagt, die Kosten für Vercel AI im Pro-Tarif können leicht auf Hunderte oder Tausende steigen, sobald Sie KI-Streams mit langer Laufzeit, umfangreiche RAG-Abrufe oder große Datenübertragungen starten.
Die wichtigsten Erkenntnisse für Pro: it Dose unterstütze Produktions-Apps, aber jeder Entwickler, den du hinzufügst, kostet mehr als 20$ pro Monat, und eine unvorhersehbare Nutzung (KI-Streaming, große Modelle) kann zu hohen Durchschnittswerten führen. Die inbegriffenen kostenlosen Credits verschieben lediglich die Abrechnung. Das Streamen von 45-Sekunden-Antworten bedeutet, dass die Server 45 Sekunden am Leben bleiben, was 45-mal mehr Kosten verursacht als ein API-Aufruf von 1 Sekunde.
Die Enterprise-Stufe ist maßgeschneidert und richtet sich an große Organisationen. Offiziell sind die Angaben in Anführungszeichen angegeben, aber in der Praxis beginnt die Eingabe ungefähr 25.000$ pro Jahr für Basismerkmale.
Diese Stufe ermöglicht erweiterte Compliance- und Skalierungstools, wie z. B.:
Beispielsweise erhält nur der Enterprise-Vertrag Hunderte von WAF-Regelslots (bis zu 1.000 IP-Blockregeln). Was die Preisgestaltung von Vercel AI angeht, hebt Enterprise einige Nutzungsobergrenzen auf und ermöglicht größere Funktionen, die Speicherstunden- und Datenraten pro Gigabyte bleiben jedoch erhalten.
Viele Startups empfinden den Sprung von Pro zu Enterprise als „Klippe“, da die zusätzlichen Funktionen auf Unternehmen ausgerichtet sind, der Preis jedoch um eine Größenordnung höher ist. Wie ein Entwickler feststellte, ist die Pro-Stufe vielleicht „alles, was Sie brauchen“, aber die Kosten in der Größenordnung hängen von der Nutzung ab, nicht von der Lizenz.
Die Preisgestaltung von Vercel AI ist für Web-Apps optimiert (viele kurze, statuslose Anfragen). KI-Apps verhalten sich anders. Das Kernkostentreiber für KI auf Vercel sind: Ausführung Dauer, daten Austritt, und Parallelität Einschränkungen.
Auf Vercel zahlen Sie für jede Millisekunde, in der eine Funktion läuft aktiv. Wartezeiten im Leerlauf auf I/O oder Streaming gelten als fakturierbare Zeit. In den Dokumenten heißt es ausdrücklich: „Function Duration generiert Rechnungen auf der Grundlage der Gesamtausführungszeit einer Vercel-Funktion.“. Bei einem normalen Web-API-Aufruf (10—100 ms) ist dies vernachlässigbar, aber ein LLM-Chat könnte 30—60 Sekunden lang gestreamt werden. In diesem Fall kann eine einzelne Anfrage um Größenordnungen mehr kosten.
Stellen Sie sich ein typisches Szenario vor:
Eine Edge-Funktion von Next.js öffnet eine Streaming-Antwort an den Browser, bis das LLM abgeschlossen ist. Während dieses Streams ist die serverlose Instance die ganze Zeit über ausgelastet, sodass eine kontinuierliche Speicherabrechnung (und ein Teil der CPU) anfällt. In der Praxis haben Teams eine schockierend hohe Auslastung gemeldet. In einer Fallstudie migrierte ein Entwickler einen umfangreichen Puppeteer-Screenshot-Dienst zu Vercel. Der Pro-Plan beinhaltete 1000 GB-h, aber innerhalb von 12 Tagen war dieser Dienst bereits verbraucht 494 GB-Stunden. Hochgerechnet auf einen ganzen Monat ist das 1.276 GB-Stunden, das heißt ungefähr 160$ an zusätzlichen Vercel-Gebühren für diese einzelne Funktion. (Dieser Entwickler wechselte schließlich zu AWS Lambda, weil dieselbe Arbeitslast auf AWS nur etwa 101 GB-Stunden/Monat betrug.)
Die Lektion: Bei langen KI-Streams ist die serverlose Abrechnung grundsätzlich „schwer“. Eine einminütige Chat-Antwort könnte 60 Sekunden lang 20—50 MB Speicher verbrauchen und etwa 0,001$ pro Anfrage kosten. Multiplizieren Sie das mit hoher Auslastung, und es summiert sich schnell.
KI-Anwendungen beinhalten häufig RAG (Retrieval-Augmented Generation) oder Datenpipelines, die Megabyte an Text und Einbettungen bewegen. Jedes Mal, wenn Ihre Vercel-Funktion ein Dokument oder Modell von einem Remote-Speicher abruft, verlassen diese Daten das Vercel-Netzwerk.
Eine starke RAG-Nutzung bedeutet große Überschreitungen. Wenn Sie beispielsweise ein Dokument mit 100 MB zehnmal abrufen, würde dies 1 GB Bandbreite verbrauchen. Wenn eine RAG-Pipeline monatlich Hunderte von Gigabyte durchsucht, könnten sich die Kosten auf Hunderte von Dollar summieren.
Kurz gesagt, die Bandbreitenkontingente von Vercel fühlen sich für normalen Web-Traffic großzügig an, aber KI-Apps, die routinemäßig große Payloads senden oder Batches einbetten, werden diese schnell überschreiten und teure Überschreitungen auslösen.
Vercel-Funktionen skalieren automatisch bis zu einem Punkt, aber es gibt Grenzen. In der Standardeinstellung erlaubt die Plattform bis zu ~30.000 gleichzeitige Ausführungen auf Hobby/Pro (und über 100.000 auf Enterprise). Bei den meisten Apps scheint das hoch zu sein, aber KI-Workloads können die Parallelität auf unerwartete Weise erhöhen.
Beispielsweise kann ein KI-Chat-Dienst Dutzende von gleichzeitigen Funktionsstreams für viele Benutzer gleichzeitig öffnen. Sobald Sie die Obergrenze für die Parallelität erreicht haben, werden neue Anfragen in die Warteschlange gestellt oder gedrosselt. An diesem Punkt müssen Sie entweder ein Upgrade durchführen (z. B. Enterprise) oder eine externe Skalierung implementieren.
Tatsächlich legt Vercel eine Obergrenze für überlasteten KI-Traffic fest, es sei denn, Sie zahlen deutlich mehr. Anekdotisch haben Teams beobachtet, wie Chatbots bei Verkehrsspitzen zu versagen begannen (504/429 Fehler), weil der zugrundeliegende serverlose Pool überlastet war.
.webp)
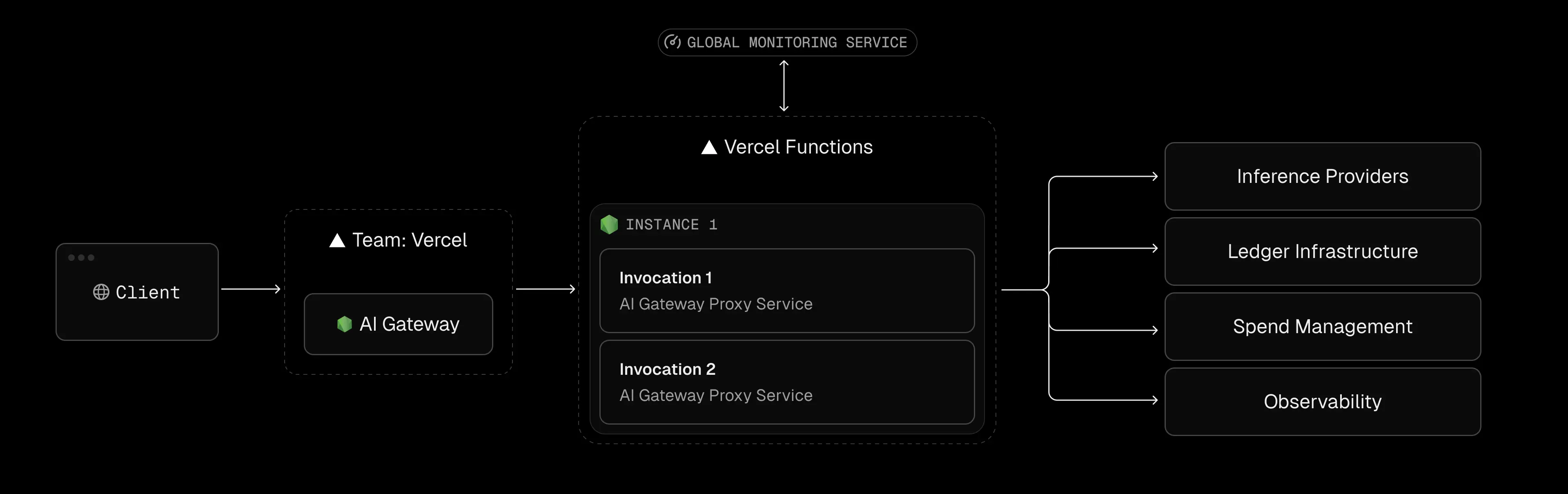
Ein weit verbreitetes Missverständnis ist die Verwendung des Vercel AI-SDK zwingt dich zur Infrastruktur von Vercel. In Wirklichkeit ist das KI-SDK nur ein Toolkit (Open Source, kostenlos) zum Erstellen von KI-Funktionen in next.js/TypeScript.
Sie können das SDK verwenden, um an jeden LLM-Anbieter weiterzuleiten, einschließlich selbst gehosteter Modelle, was beim Vergleich eine wichtige Überlegung ist Vercel AI-Gateway gegen OpenRouter für Anbieterflexibilität und Kostenkontrolle. Es gibt keine Anforderung um Ihren Code auf den Servern von Vercel auszuführen. Tatsächlich funktionieren die meisten Teile des SDK (UI-Komponenten, Anbieter, Clientbibliotheken) überall. Beispielsweise könnte ein Team seine App Next.js mit dem AI-SDK containerisieren und sie auf Kubernetes (EKS/GKE) oder einer beliebigen Cloud-VM bereitstellen. Der Code „weiß“ nicht, dass er von Vercel ist.
Warum Teams nicht weiterkommen:
Normalerweise der Einfachheit halber. Das Hosting von Vercel ist eng mit dem SDK integriert — Sie übertragen Code, und Vercel erstellt, implementiert und bietet sogar einen integrierten AI-Gateway-Tab. Viele Teams klicken standardmäßig auf „Auf Vercel bereitstellen“.
Der Nachteil ist, dass sich hinter dem serverlosen Kostenmodell die Bequemlichkeit verbirgt. Techniker können gerne Prototypen mit Vercel erstellen, ohne zu wissen, dass jeder Modellanruf zu den (oft höheren) serverlosen Tarifen von Vercel abgerechnet wird, bis die Rechnung eintrifft.
Mit der Zunahme von KI-Projekten, die von Vercel betrieben werden, treten neben Vercel-KI-Preisproblemen auch mehrere betriebliche Probleme auf:
Selbst bei kostenpflichtigen Tarifen setzt Vercel strenge Ausführungsbeschränkungen durch. Standardmäßig laufen HTTP-Funktionen auf Pro danach ab 5 Minuten (konfigurierbar bis zu 13 Minuten mit „Fluid Compute“). Bei Hobby sind es nur 60 Sekunden.
In der Praxis wird jeder KI-Agent oder Forschungsworkflow, der länger als ein paar Minuten läuft, getötet. Beispielsweise überschreitet ein mehrstufiger Agent, der 10—15 Minuten benötigt, um Datenbanken abzufragen, Dokumente zusammenzufassen und einen Bericht zu erstellen, das Limit zuverlässig und schlägt fehl.
Teams melden häufig 504 Fehler in ihren KI-Aufgaben, sobald sie diese Obergrenzen überschreiten. Im Gegensatz dazu können Sie in Ihrer eigenen Cloud-Infrastruktur Funktionen oder Container je nach Bedarf unbegrenzt (oder zumindest stundenlang) laufen lassen.
Die Edge-Middleware von Vercel (wie Next.js Edge Functions) kann die Leistung verbessern, ist aber mit Lock-In ausgestattet.
In der Praxis bauen Teams aus Geschwindigkeitsgründen manchmal kritische Logik in Edge-Funktionen ein, nur um dann herauszufinden Die Abwanderung von Vercel wird zu einer umfassenden Neufassung.
Derzeit hat Vercel keine nativen GPU-Instances für KI-Workloads. Das bedeutet, dass alle Modellinferenzen oder Einbettungen, die beschleunigt werden müssen, außerhalb der Plattform erfolgen müssen.
Teams hosten oft Modelle im GPT-Stil oder Vektorsuchen auf AWS/GCP/Render/Azure mit GPUs und rufen sie dann über Vercel-Funktionen auf. Dieses geteilte Setup erhöht die Latenz (jeder Anruf wechselt zu einem externen Dienst) und die betriebliche Komplexität.
Im Gegensatz dazu kann eine auf Kubernetes aufgebaute Infrastruktur (wie TrueFoundry) reinen CPU-Webcode und GPU-Inferenz nebeneinander im selben Cluster ausführen, wodurch diese Fragmentierung vermieden wird.
Trotz dieser Vorbehalte ist Vercel keine schlechte Wahl für einige KI-Szenarien. Ihre Stärken kommen zum Vorschein, wenn:
Zusammengefasst: Die Vercel-KI-Preisgestaltung eignet sich gut für Frontend-Apps, die KI nur geringfügig verwenden, oder für Teams, die vor allem Wert auf Markteinführungszeiten legen. Die Gewinnschwelle ist erreicht, wenn KI-Workloads zu „echten“ Bestandteilen der Anwendung werden und nicht nur zu Neuheitsdemos. Das ist der Zeitpunkt, an dem die Kosten schwer vorherzusagen sind.
.webp)
Da KI-Funktionen in den Mittelpunkt des Produkts rücken, erreichen viele Teams einen Wendepunkt und suchen nach Alternativen. TrueFoundry positioniert sich als eine Lösung, die den Komfort einer serverlosen Lösung mit der Wirtschaftlichkeit einer reinen Cloud verbindet. Im Folgenden finden Sie einen Vergleich der wichtigsten Faktoren für KI-Workloads:
Was bedeutet das in der Praxis? Viele Teams stellen fest, dass ihre monatlichen Rechnungen auf Vercel steigen unverhältnismäßig verglichen mit ihrer tatsächlichen Berechnung. In einem Beispiel aus der Praxis verbrauchte ein Service auf Vercel ~1.276 GB-h (verursacht ~2000 $ pro Jahr), aber nur ~101 GB-h auf unformatiertem AWS Lambda (kostenloses Kontingent) für dieselbe Last. Einfach ausgedrückt: Äquivalente KI-Workloads können auf einer selbstverwalteten Cloud-Infrastruktur weitaus günstiger ausgeführt werden. Bei TrueFoundry besteht Ihre Rechnung im Grunde aus Cloud-Computing (EC2, GKE-Knoten usw.) zuzüglich einer Plattformgebühr und nicht aus dem Multiplikator, den Serverless mit sich bringt.
.webp)
TrueFoundry bietet einen hybriden Ansatz: Sie behalten das entwicklerfreundliche Modell der Serverlosigkeit (automatische Skalierung, einfache APIs) bei, laufen aber auf Ihrem eigenen Cloud-Konto. Zu den wichtigsten Aspekten gehören:
Mit TrueFoundry können Sie Next.js (und jede andere App) als Standard-Docker-Dienste auf Kubernetes (EKS, GKE oder AKS) in Ihrem eigenen Cloud-Konto bereitstellen. Wie ein Blog erklärt, „TrueFoundry macht es wirklich einfach, Anwendungen auf Kubernetes-Clustern in Ihrem eigenen Cloud-Provider-Konto bereitzustellen.“. Unter der Haube laufen Ihre Next.js Endpunkte in Pods/Knoten, die Sie kontrollieren.
Das bedeutet, dass Ihnen in Rechnung gestellt wird Cloud-Raten im Rohformat für CPU und Arbeitsspeicher, ohne versteckte serverlose Prämie. Ein inaktiver WebSocket oder ein offener Stream verbraucht immer noch RAM auf dem Knoten, aber dieser RAM kostet nur einen Bruchteil dessen, was eine serverlose GB-Stunde kostet.
Da Sie die Kubernetes-Knoten verwalten, kontrollieren Sie die Timeouts und Lebensdauern von Funktionen. Sie können langlebige Pods oder Jobs je nach Bedarf minuten- oder stundenlang ausführen. TrueFoundry legt keinen 5- oder 15-minütigen Cutoff fest — Ihre Infrastruktur schon.
Komplexe Agenten-Pipelines und Forschungsaufgaben werden einfach bis zum Abschluss ausgeführt (sofern vorhanden, nur unter Berücksichtigung der normalen maximalen Lebensdauer des Pods). Dadurch entfällt das bei Vercel häufig auftretende Problem mit 504-Fehlern im Mid-Stream-Modus. Wenn ein KI-Agent 20 Minuten braucht, bis er fertig ist, kann er das auf TrueFoundry tun; auf Vercel wäre er nach 5 Minuten ausgefallen.
Ein großer Vorteil von TrueFoundry for AI ist die integrierte GPU-Unterstützung. Da es sich um Kubernetes unter der Haube handelt, können Sie GPU-Knotenpools anhängen und Inferenz-Workloads zusammen mit Ihren Webdiensten planen. Das bedeutet, dass Ihre Frontend-APIs und Ihre umfangreiche ML-Inferenz im selben Cluster ausgeführt werden können (wodurch Latenz und Datenübertragung reduziert werden). Tatsächlich ist die Cloud-native Architektur von TrueFoundry explizit „ermöglicht uns den Zugriff auf die unterschiedliche Hardware, die von verschiedenen Cloud-Anbietern bereitgestellt wird, insbesondere bei GPUs“.
In der Praxis bedeutet dies, dass Sie LLM-Inferenz oder Embed-Generierung auf GPU-beschleunigten Knoten ausführen können, ohne die Plattform verlassen zu müssen. Es ist nicht erforderlich, einen separaten GPU-Dienst miteinander zu verbinden (und für den regionsübergreifenden Verkehr zu bezahlen).
Vercel bleibt eine hervorragende Plattform für die Frontend-Bereitstellung. Aber sobald die KI vom Backend aus berechnet wird, ändert sich die Wirtschaft. Die wichtigste Erkenntnis: vermeide es, Vercels dauerabhängige Prämie für schwere KI-Aufgaben zu zahlen.
Im Gegensatz zu einfachem HTTP-Verkehr laufen KI-Backends oft viel länger pro Anfrage und übertragen viele Daten. Im Rahmen des KI-Preismodells von Vercel bedeutet das, für jede Sekunde an Rechenleistung und jedes ausgehende Gigabyte zu zahlen. Im Gegensatz dazu zahlen Sie bei TrueFoundry für unformatierte Knoten und eine Betriebszeit von Sekunden — dasselbe Kostenmodell, das Sie sehen würden, wenn Sie einen Container auf EC2 oder GKE betreiben würden.
Das Endergebnis ist eine reibungslosere Skalierung der Kosten. Die Teams stellen fest, dass ihre monatlichen Ausgaben steigen linear wobei die tatsächliche Berechnung verwendet wird, nicht mit jeder Millisekunde der Funktionszeit. In vielen Fällen kann das, was sie auf Vercel Hunderte pro Monat gekostet hat, für Dutzende in ihrer eigenen Cloud erledigt werden.
Wenn dein Team mit steigenden Vercel-Rechnungen konfrontiert ist oder ständig mit Timeouts zu kämpfen hat, lohnt es sich, einen Infrastrukturwechsel in Betracht zu ziehen. Wahre Gießerei ist so konzipiert, dass Sie die Produktivität eines serverlosen Systems beibehalten können (einfache Bereitstellung, Skalierung) und gleichzeitig die damit verbundenen Nachteile vermeiden. Eine kurze Demo kann zeigen, wie die Verlagerung Ihres KI-Workloads auf TrueFoundry die Kosten senken kann ohne Geschwindigkeit opfern.
Buchen Sie eine kurze Demo um zu erfahren, wie die Verlagerung Ihres KI-Workloads auf TrueFoundry die Kosten senken kann, ohne an Geschwindigkeit einzubüßen.
Das Vercel AI Gateway bietet eine kostenloses Kontingent. Jedes Vercel-Teamkonto erhält AI Gateway-Guthaben in Höhe von 5$ pro Monat sobald Sie Ihre erste Anfrage gestellt haben. Sie können dieses kostenlose Guthaben auf unbestimmte Zeit weiter verwenden (es wird alle 30 Tage aktualisiert), um mit LLMs über Vercel zu experimentieren. Darüber hinaus wechseln Sie zur nutzungsbasierten Bezahlung und müssen zusätzliche Credits kaufen. Beachten Sie, dass dieses Guthaben in Höhe von 5$ nur für die Nutzung des Gateways bestimmt ist; das tut es nicht decken Sie Ihre Funktionsrechen- oder Bandbreitenkosten auf der Plattform ab — diese werden im Rahmen Ihres Kontoplans separat in Rechnung gestellt.
Vercels Hobby-Stufe ist frei für persönliche Projekte. Das Profi Plan beginnt um 20$ pro Entwicklersitz und Monat, plus alle nutzungsbasierten Add-Ons. In der Praxis zahlt ein kleines Team von 3 Entwicklern pro Monat etwa 60$ pro Monat. Wenn Sie mehr Funktionen benötigen (SSO, garantierte Verfügbarkeit usw.), beginnt die Enterprise-Stufe im fünfstelligen Bereich pro Jahr. Neben diesen Grundgebühren zahlen Sie für zusätzliche GB-Stunden, Edge-Anfragen und Datenübertragungen gemäß den Nutzungstarifen von Vercel.
Das 20-Dollar-Plan bezieht sich auf Vercel's Profi-Stufe (manchmal einfach „Pro-Konto“ genannt), das 20 USD pro Benutzer und Monat kostet. Es beinhaltet alle Hobbyfunktionen sowie Tools für die Teamzusammenarbeit und höhere Kontingente. Pro umfasst beispielsweise 1 TB Edge-Bandbreite pro Monat und ein größeres GB-Stundenkontingent für Funktionen. Wenn ein Pro-Team diese Kontingente überschreitet, wird die zusätzliche Nutzung zu den Überschusstarifen von Vercel in Rechnung gestellt. Kurz gesagt, der 20-Dollar-Plan ist der kostenpflichtige Einstiegstarif für professionelle Teams (über das kostenlose Hobby-Tarif hinaus).
Die Plattform von Vercel hat mehrere Einschränkungen, die sich auf KI-Apps auswirken. Standardmäßig funktionieren serverlose Funktionen schnell auszeiten (60—300 Sekunden auf Hobby/Pro). KI-gestreamte Antworten zählen als volle aktive Zeit, sodass lange Abfragen kostspielig werden. Es gibt strenge Grenzwerte für die Parallelität und die Größe der Anforderungsnutzdaten (max. 4,5 MB Hauptvolumen). Das tut Vercel auch unterstützt keine GPUs, daher muss jede schwere Modellinferenz außerhalb der Plattform ausgeführt werden. Das AI Gateway selbst verfügt nur über ein kostenloses Guthaben von 5$ pro Monat. Darüber hinaus zahlen Sie die Listenpreise der Anbieter für Token. In der Praxis melden Vercel-Teams unerwartete 504-Fehler, hohe Rechnungen für GB-Stunden und eine architektonische Abhängigkeit von der Edge-Umgebung von Vercel, falls sie zu sehr davon abhängig werden. Aus diesen Gründen stoßen fortgeschrittene KI-Workloads bei Vercel oft an ihre Obergrenze und führen zu einer Migration auf Plattformen wie TrueFoundry.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.




.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




