

May 23, 2024
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
In der heutigen datengesteuerten Welt ist das Durchsuchen riesiger Datenmengen nach ähnlichen Objekten eine grundlegende Operation, die in verschiedenen Anwendungen verwendet wird, von Datenbanken über Suchmaschinen bis hin zu Empfehlungssystemen. Bei diesem als Ähnlichkeitssuche bezeichneten Vorgang werden Elemente identifiziert, die sich anhand bestimmter Kriterien ähneln.
Während herkömmliche Datenbanksuchen, die auf festen numerischen Kriterien basieren (z. B. die Suche nach Mitarbeitern innerhalb einer bestimmten Gehaltsspanne), unkompliziert sind, befasst sich die Ähnlichkeitssuche mit komplexeren Abfragen. Beispielsweise könnte ein Benutzer nach „Schuhen“, „schwarzen Schuhen“ oder einem bestimmten Modell wie „Nike AF-1 LV8“ suchen. Diese Abfragen können vage und unterschiedlich sein, sodass das System Konzepte wie verschiedene Schuhtypen verstehen und zwischen ihnen unterscheiden muss.
Die Ähnlichkeitssuche ist in vielen Bereichen von entscheidender Bedeutung, darunter:
Die größte Herausforderung bei der Ähnlichkeitssuche besteht darin, mit großen Datenmengen umzugehen und gleichzeitig die tieferen konzeptionellen Bedeutungen der gesuchten Elemente genau zu verstehen. Herkömmliche Datenbanken, die auf symbolischen Objektdarstellungen basieren, sind in solchen Szenarien unzureichend. Stattdessen benötigen wir fortschrittlichere Techniken, die semantische Repräsentationen von Daten verarbeiten und Suchanfragen auch bei scale.presentations, distance-Metriken und verschiedenen Suchalgorithmen effizient durchführen können.
Durch die Nutzung der Ähnlichkeitssuche können wir komplexe, abstrakte Abfragen in umsetzbare Erkenntnisse umwandeln, was sie zu einem leistungsstarken Tool in verschiedenen Bereichen macht. In den folgenden Abschnitten werden wir uns mit der Funktionsweise der Ähnlichkeitssuche befassen und uns dabei auf die Rolle von Vektordarstellungen, Entfernungsmetriken und verschiedenen Suchalgorithmen konzentrieren.
.webp)
Beim maschinellen Lernen stellen wir reale Objekte und Konzepte als Vektoren dar. Dabei handelt es sich um Mengen kontinuierlicher Zahlen, die als Einbettungen bezeichnet werden. Dieser Ansatz ermöglicht es uns, die tieferen semantischen Bedeutungen von Objekten zu erfassen. Wenn Objekte wie Bilder oder Text in Vektoreinbettungen umgewandelt werden, kann ihre Ähnlichkeit beurteilt werden, indem der Abstand zwischen diesen Vektoren in einem hochdimensionalen Raum gemessen wird.
In einem Vektorraum haben ähnliche Bilder beispielsweise Vektoren, die nahe beieinander liegen, während unterschiedliche Bilder weiter voneinander entfernt sind. Dadurch ist es möglich, mathematische Operationen durchzuführen, um ähnliche Objekte effizient zu finden und zu vergleichen.
.webp)
Zur Generierung dieser Vektoreinbettungen werden mehrere Modelle verwendet:
Diese Modelle werden an großen Datensätzen und Aufgaben trainiert, sodass sie Einbettungen erstellen können, die den semantischen Inhalt der Elemente effektiv darstellen.
Um festzustellen, wie ähnlich sich zwei Vektoreinbettungen sind, verwenden wir Entfernungsmetriken. Diese Metriken berechnen den „Abstand“ zwischen Vektoren im Vektorraum, wobei kleinere Abstände auf eine größere Ähnlichkeit hinweisen.
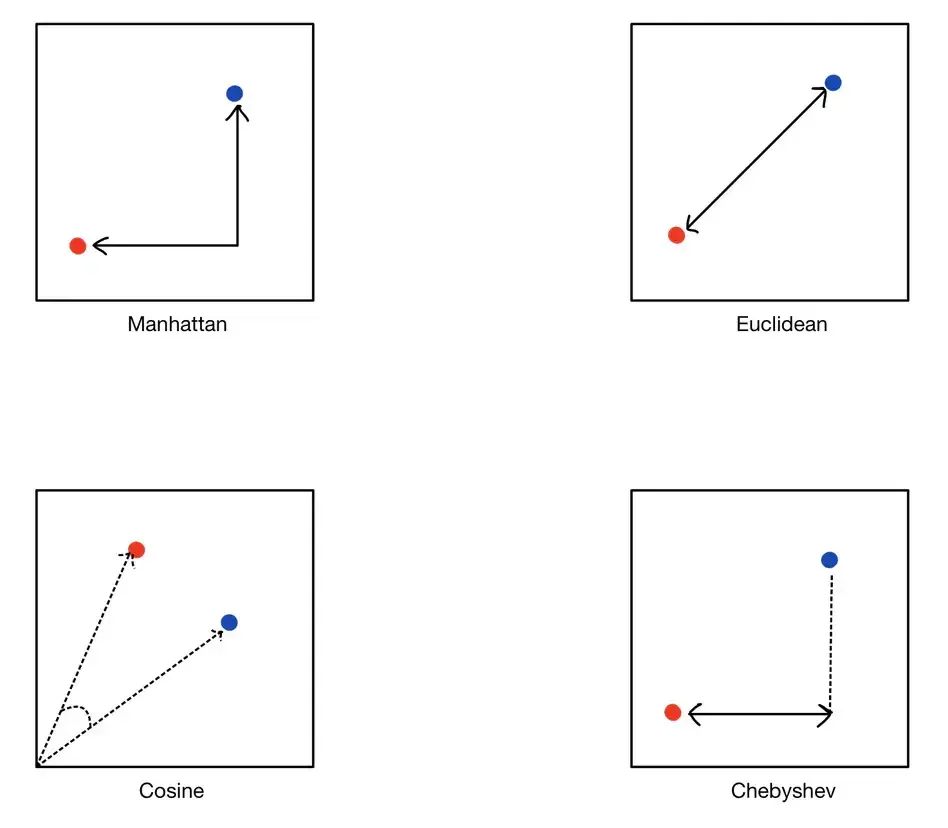
Die euklidische Entfernung misst den geradlinigen Abstand zwischen zwei Punkten in einem hochdimensionalen Raum. Es ist die intuitivste Methode zur Entfernungsmessung, ähnlich der geometrischen Entfernung, die Sie mit einem Lineal messen könnten. Dies ist nützlich, wenn die Daten dicht sind und das Konzept der physischen Entfernung relevant ist.
Formel:
.webp)
Die Manhattan-Entfernung, auch L1-Entfernung genannt, summiert die absoluten Unterschiede ihrer Koordinaten. Diese Metrik eignet sich für rasterartige Datenstrukturen und kann als die gesamte „Stadtblockentfernung“ visualisiert werden, die man zwischen Punkten in einem Raster zurücklegen würde.
Formel:
.webp)
Die Kosinusähnlichkeit misst den Kosinus des Winkels zwischen zwei Vektoren, wobei der Schwerpunkt eher auf ihrer Richtung als auf ihrer Größe liegt. Dies ist besonders nützlich für Textdaten, bei denen die Größe des Vektors (Worthäufigkeit) variieren kann, die Richtung (Wortverwendungsmuster) jedoch wichtiger ist.
.webp)
Die Chebyshev-Distanz misst den maximalen Abstand zwischen den Koordinaten eines Vektorpaares. Es wird häufig in schachähnlichen Rasterszenarien verwendet, in denen Sie sich in jede Richtung bewegen können, auch diagonal.
.webp)
Die Wahl der richtigen Entfernungsmetrik hängt von den spezifischen Eigenschaften und Anforderungen der Anwendung ab. Hier sind einige Richtlinien für die Auswahl der geeigneten Metrik:
K-Nearest Neighbors (k-NN) ist ein beliebter Algorithmus, der verwendet wird, um die Vektoren zu finden, die einem bestimmten Abfragefektor am nächsten sind. So funktioniert es und seine Vor- und Nachteile:
.webp)
Um der Ineffizienz von k-NN bei großen Datensätzen entgegenzuwirken, bieten Approximate Nearest Neighbor (ANN) -Methoden eine schnellere, wenn auch weniger präzise Alternative. ANN-Algorithmen zielen darauf ab, eine „gute Schätzung“ der nächsten Nachbarn zu finden, wobei eine gewisse Genauigkeit gegen Geschwindigkeit eingetauscht wird.
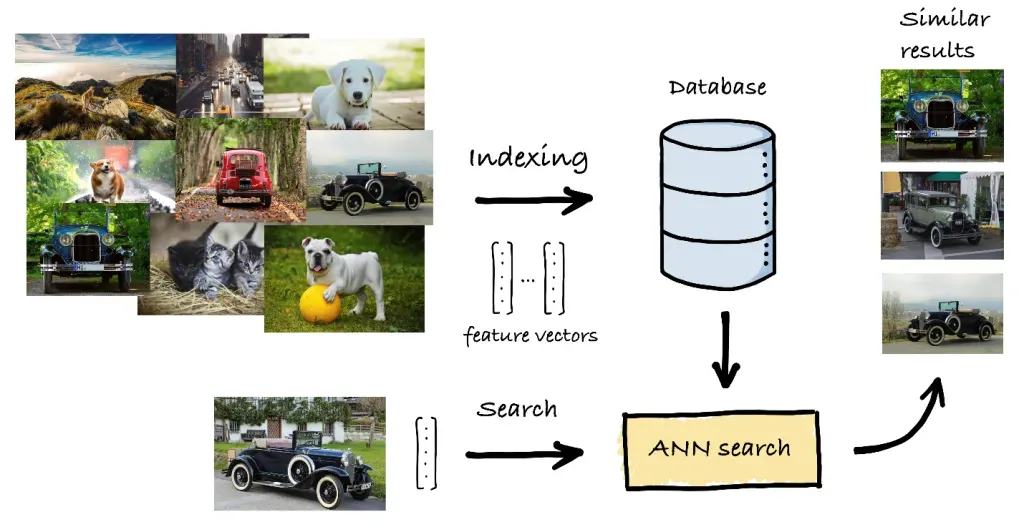
Bei der praktischen Implementierung der Ähnlichkeitssuche können verschiedene Bibliotheken und Frameworks helfen:
Die Ähnlichkeitssuche hat ein breites Anwendungsspektrum in verschiedenen Bereichen und nutzt die Fähigkeit, ähnliche Artikel schnell und genau zu finden und zu vergleichen. Hier sind einige wichtige Anwendungen:
Empfehlungssysteme verwenden die Ähnlichkeitssuche, um Produkte, Inhalte oder Dienstleistungen vorzuschlagen, die auf den Präferenzen und dem Verhalten der Nutzer basieren.
Die Ähnlichkeitssuche ist entscheidend, um visuell ähnliche Bilder oder Videos aus großen Datenbanken abzurufen.
In NLP hilft die Ähnlichkeitssuche in verschiedenen textbasierten Anwendungen, indem sie semantisch ähnliche Dokumente oder Phrasen findet.
Erkennung betrügerischer Aktivitäten durch Auffinden von Mustern und Anomalien, die vom normalen Verhalten abweichen.
Die Ähnlichkeitssuche hilft bei der medizinischen Diagnose und Genforschung, indem sie Patientendaten und genetische Sequenzen vergleicht.
Eine der größten Herausforderungen bei der Ähnlichkeitssuche ist die Art der Benutzeranfragen. Die Anfragen können von sehr allgemeinen Begriffen wie „Schuhe“ bis hin zu sehr spezifischen Artikeln wie „Nike AF-1 LV8“ reichen. Das System muss in der Lage sein, diese Nuancen zu erkennen und zu verstehen, wie verschiedene Artikel miteinander in Beziehung stehen. Dies erfordert ein tiefes Verständnis der semantischen Bedeutung der Abfragen, das über den einfachen Abgleich von Schlüsselwörtern hinausgeht.
Eine weitere große Herausforderung ist die Skalierbarkeit. In realen Anwendungen haben wir es oft mit riesigen Datensätzen zu tun, die Milliarden von Elementen enthalten können. Das effiziente Durchsuchen solch großer Datenmengen erfordert fortschrittliche Techniken und leistungsstarke Rechenressourcen. Herkömmliche Datenbanksysteme, die auf exakte Übereinstimmungen und symbolische Darstellungen ausgelegt sind, haben in diesen Szenarien Schwierigkeiten, gute Ergebnisse zu erzielen.
Die Ähnlichkeitssuche, auch Vektorsuche genannt, spielt in verschiedenen modernen Anwendungen eine zentrale Rolle. Durch die Nutzung von Vektoreinbettungen und ausgeklügelten Entfernungsmetriken ermöglicht uns die Ähnlichkeitssuche, Elemente anhand ihrer semantischen Bedeutung zu finden und zu vergleichen. Hier sind die wichtigsten Erkenntnisse:
Um das Potenzial der Ähnlichkeitssuche wirklich nutzen zu können, ist es wichtig, die zugrunde liegenden Prinzipien zu verstehen und die richtigen Tools und Techniken für Ihre spezifischen Bedürfnisse auszuwählen. Ganz gleich, ob Sie eine Empfehlungsmaschine, ein inhaltsbasiertes Abrufsystem oder einen Mechanismus zur Betrugserkennung entwickeln, die Ähnlichkeitssuche kann die Genauigkeit und Effizienz Ihrer Lösungen erheblich verbessern.
Die Ähnlichkeitssuche ist eine Technik, um Elemente zu finden, die sich in riesigen Datensätzen ähneln. Sie stützt sich auf Vektoreinbettungen, die die konzeptionelle Bedeutung von Daten erfassen, wobei häufig Vektordarstellungen und Entfernungsmetriken verwendet werden. Dieser Prozess ist für Anwendungen wie Produktempfehlungen und Textabgleich von entscheidender Bedeutung und ermöglicht es Systemen, relevante Informationen effizient und genau zu identifizieren.
Um eine Ähnlichkeitssuche durchzuführen, werden Objekte wie Text oder Bilder zunächst mithilfe spezieller Modelle in Vektoreinbettungen umgewandelt. Dann messen Entfernungsmetriken — wie die euklidische Entfernung oder die Kosinusdistanz — den „Abstand“ zwischen diesen Vektoren in einem hochdimensionalen Raum. Kleinere Abstände weisen auf eine höhere Ähnlichkeit hin. Alternativ bewerten Ähnlichkeitsmetriken wie Kosinusähnlichkeit die Nähe direkt, wobei ein höherer Wert (näher an 1) eine größere Ähnlichkeit bedeutet.
Ein hervorragendes Beispiel für eine Ähnlichkeitssuche ist eine E-Commerce-Plattform, die Produkte empfiehlt, die denen ähneln, die ein Benutzer angesehen oder gekauft hat. Dies hilft Käufern, relevante Artikel mühelos zu entdecken. Die Bildsuche, bei der visuell ähnliche Bilder aus riesigen Datenbanken gefunden werden, ist eine weitere wichtige Anwendung, die Ähnlichkeitssuchtechnologie verwendet.
In LLM-gestützten Systemen — insbesondere RAG-Pipelines (Retrieval-Augmented Generation) — arbeitet die Ähnlichkeitssuche parallel zum Modell, indem sie Text in Vektoreinbettungen umwandelt, die die semantische Bedeutung erfassen. Eine Abrufebene durchsucht diese Vektoren nach Inhalten, die einer Abfrage am ähnlichsten sind, und leitet die Ergebnisse dann an das LLM weiter, indem sie den Abstand zwischen diesen Vektoren misst. Dies ist entscheidend für das Abrufen relevanter Informationen und das Generieren kontextsensitiver Antworten, was das Verständnis und den Nutzen des Modells für die Benutzer erheblich verbessert.
Die Ähnlichkeitssuche ist in vielen Anwendungen von entscheidender Bedeutung. Sie verbessert die Produktempfehlungen im E-Commerce, erleichtert die Bild- und Videosuche und verbessert die Verarbeitung natürlicher Sprache für den Textabgleich. Im Gesundheitswesen hilft es bei der Identifizierung ähnlicher medizinischer Fälle und wandelt komplexe Daten branchenübergreifend in umsetzbare Erkenntnisse um.
Die semantische Suche basiert auf der Ähnlichkeitssuche, um Elemente anhand ihrer Bedeutung zu finden, nicht nur anhand von Schlüsselwörtern. Sie verwendet Vektoreinbettungen, um Daten semantisch darzustellen. Während die Ähnlichkeitssuche die Technik ist, um diese Vektoren zu vergleichen, ist die semantische Suche die Anwendung, die sie für ein tieferes kontextuelles Verständnis nutzt.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.







.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




