




October 26, 2023
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Heute Wahre Gießerei startet eine Deep Dive-Serie für maschinelles Lernen, in der wir mit ML- und Data-Science-Führungskräften aus Unternehmen sprechen, die ML verwenden, um die Anwendungsfälle und Workflows von ML in ihren Organisationen zu untersuchen. Im Rahmen dieser Reihe werden wir den ML-Stack von Unternehmen wie diesen hosten und tiefer in sie eintauchen Gong, Stich Fix, SalesForce, Gusto, Einfach, und viele mehr.
📌
In dieser Serie tauchen wir in die Welt des maschinellen Lernens ein, um das Spektrum an ML-Anwendungen und Infrastruktur-Setups branchenübergreifend zu enthüllen.
Unsere Gespräche werden sich um vier Hauptthemen drehen:
1. Anwendungsfälle des maschinellen Lernens für das Unternehmen
2. Wie haben sie ihren Machine-Learning-Stack aufgebaut, einschließlich der Schulungs- und Experimentier-Pipeline, Bereitstellung und Bereitstellung, Überwachung, und sie dabei im Hinblick auf Kosten und Latenz optimiert
3. Herausforderungen beim Aufbau des ML-Stacks mit spezifischen Herausforderungen, die sich auf die Branche beziehen
4. Ein Überblick über die neuesten Innovationen, die beim Aufbau und der Skalierung der ML-Infrastruktur zum Einsatz kamen.
Zum Auftakt der ersten Diskussion der Reihe sprachen wir mit Noam Lotner von Gong. Gong ist eine Revenue Intelligence-Plattform. Sie ermöglicht es den Vertriebsteams, ihr volles Potenzial auszuschöpfen, indem sie die Kundenrealität aus den Gesprächen des Vertriebsteams enthüllt. Gong analysiert die Kundeninteraktionen per Telefon, E-Mail, Internet usw., um den Vertriebsteams die besten Erkenntnisse zu liefern, sodass sie diese nutzen können, um mehr Geschäfte abzuschließen.
Noam Lotner leitet das Research Operations Team bei Gong. Er baut die operative Plattform für die KI/ML-Forschungsgruppe auf. Er automatisiert Modellfreigabeprozesse, Experimentmanagement und Leistungstests, entwickelt Tools für die Kennzeichnung und Datensatzerstellung und ermöglicht den sicheren Zugriff auf Produktionsdatenquellen.
Gong analysiert Kundeninteraktionen per Telefon, E-Mail, Internet usw. Maschinelles Lernen wird immer wichtiger, um Verkaufsinteraktionen zu analysieren und den Vertriebsteams Einblicke zu geben. ML-Algorithmen können Aufgaben automatisieren, die zuvor manuell erledigt wurden, wie z. B. die Analyse von Videoanrufen, das Transkribieren und Analysieren von Verkaufstelefonanrufen. Das spart Zeit und verbessert die Effizienz des Verkaufsprozesses.
Dies ist zwar eine Frage, die wir Gong gestellt haben, aber wir sehen, dass ausnahmslos alle SaaS-Unternehmen:
📌
Anzahl der Modelle: Anzahl der Kunden X Modelle Typen
📌
„Wir verwenden für alle das gleiche Basismodell. Wir lassen die Kunden auch tatsächlich Schulungen für bestimmte Modelle für ihre eigenen Inhalte durchführen.“
Um die Kosten zu optimieren, verwendet Gong die Bereitstellung mehrerer Modelle in der Inferenzschicht, da die Ausführung separater Modelle auf separaten Maschinen ein kostenintensives System bedeuten würde.
Hier ist ein ausführlicher Blog von Gong, der über den Einsatz von ML im B2B-Vertrieb spricht
Bei Gong ist das ML-System gemäß der ML-Organisation strukturiert.
In diesem Blog (und in der Chat-Serie) werden wir uns eingehender mit den Herausforderungen von Research Side Infra for Gong befassen
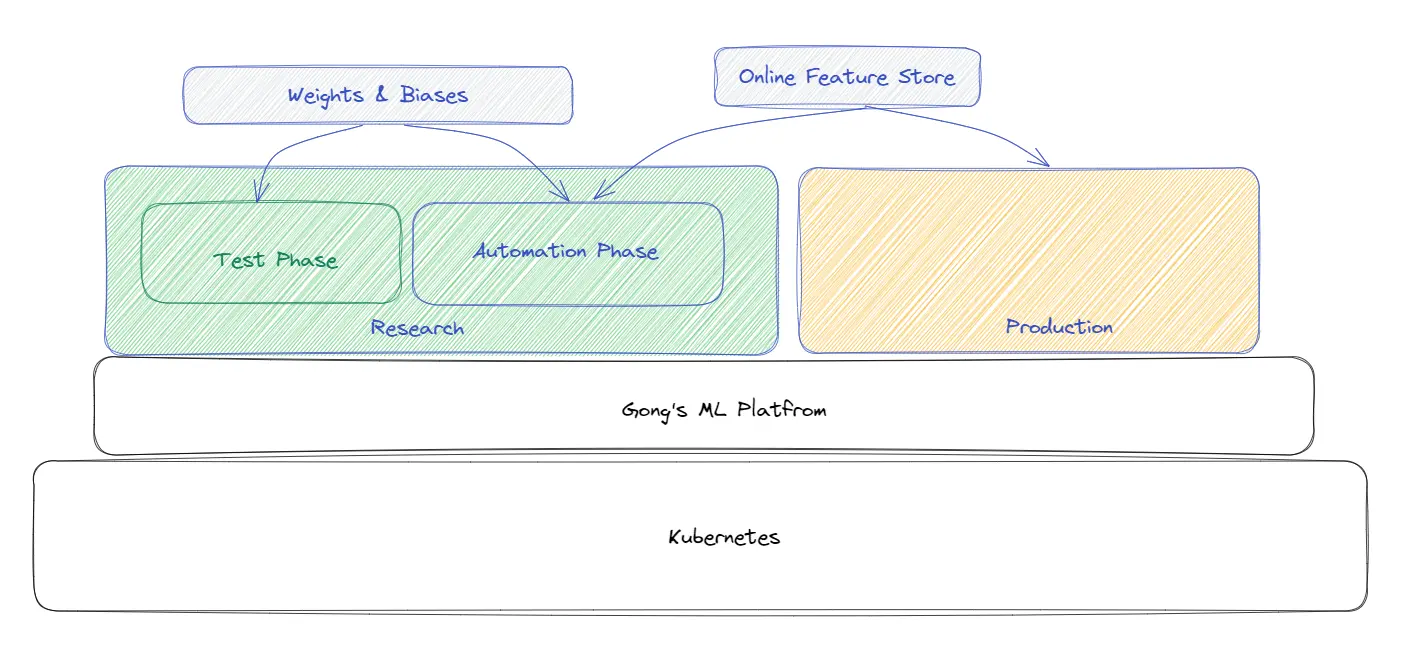
Um es Forschern zu ermöglichen, Maschinen einfach hochzufahren, ist der gesamte Stack auf Kubernetes for the Research Infra eingerichtet. Die meisten Modelle im Forschungsteam verwenden keine Online-Funktionen.
Wolke: Der Großteil der Infrastruktur befindet sich auf AWS und funktioniert auch mit anderen Cloud-Anbietern in etwas geringerer Kapazität zusammen.
Verwaltung der Infrastruktur: In den Pipelines werden die Modelle tatsächlich speziell für jeden Kunden ausgeführt. Es gibt eine Maschine, die alle Anrufe dieser Firma bearbeitet
Alles, was im Forschungsteam getan wird, wird jetzt auf Kubernetes verschoben. Ein Teil von Noams Arbeit besteht darin, seinem Team zu helfen, automatisch auf Ressourcen aus der Kubernetes-Cloud zuzugreifen. Es ist derzeit ein laufendes Projekt.
📌
„Ich würde jedem, der sich damit beschäftigt, empfehlen, dass Sie schon zu Beginn Ihrer Reise an die Skalierung denken und darüber nachdenken müssen, wie Ihre Gruppe arbeiten wird.“
„Ich denke, die meisten MLOps-Systeme benötigen Kubernetes für die Verwaltung der Ressourcen. Ich sehe in Zukunft keine Plattform, die etwas mit MLOps zu tun hat, ohne Kubernetes zu verwenden.“
Wenige wichtige Dinge, die es zu beachten gilt:
📌
„Meiner Ansicht nach musste bei Gong diese Plattform aufgebaut werden.“
Nichts kann für ein SaaS-Unternehmen mehr sein als Sicherheit. Die ML-Pipeline muss der Sicherheit aus Datenschutzgründen beim Umgang mit sensiblen Kundendaten sowie bei der Kontrolle unbefugter Zugriffe Priorität einräumen.
Ich hoffe, die erste Blogserie der TrueML Talks konnte Ihnen wertvolle Einblicke geben, wie Sie Ihre Forschungsinfrastruktur für maschinelles Lernen aufbauen können, um Ihre ML-Teams zu unterstützen. #MLOps #MachineLearning #DataScience #DevOps #ModelOps #AIInfrastructure
Gehe zu unserem zweite Folge der TrueML-Vorträge, bei denen wir mit Platform Lead bei Stitch sprechen. Schauen Sie sich die TrueML weiter an YouTube-Serie und alle Folgen der TrueML-Blogserie finden Sie hier -
Wahre Gießerei ist ein ML Deployment PaaS über Kubernetes, um die Workflows von Entwicklern zu beschleunigen und ihnen gleichzeitig volle Flexibilität beim Testen und Bereitstellen von Modellen zu bieten und gleichzeitig die volle Sicherheit und Kontrolle für das Infra-Team zu gewährleisten. Über unsere Plattform ermöglichen wir Teams für maschinelles Lernen bereitstellen und überwachen Modelle innerhalb von 15 Minuten mit 100% iger Zuverlässigkeit, Skalierbarkeit und der Möglichkeit, innerhalb von Sekunden rückgängig zu machen. So können sie Kosten sparen und Modelle schneller für die Produktion freigeben, wodurch ein echter Geschäftswert erzielt wird.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.






.png)
.webp)
.webp)
.webp)


.webp)
.webp)
.webp)
.png)




