



May 21, 2024
|
Lesedauer: 5 Minuten


Erhalten Sie sofortigen Zugriff auf eine TrueFoundry-Live-Umgebung. Stellen Sie Modelle bereit, leiten Sie den LLM-Verkehr weiter und erkunden Sie die gesamte Plattform — Ihre Sandbox ist in Sekundenschnelle einsatzbereit, ohne dass eine Kreditkarte erforderlich ist.









Published: April 22, 2026

Unglaublich schnelle Methode zum Erstellen, Verfolgen und Bereitstellen Ihrer Modelle!
Wir sind zurück mit einer weiteren Folge von True ML Talks. In dieser Ausgabe tauchen wir erneut tief in die MLOps- und LLMS-Anwendungen bei GitLab ein und wir sprechen mit Monmayuri Ray.
Monmayuri leitet den Bereich KI-Forschung bei GitLab mit viel Fokus auf die LLMs im letzten Jahr. Und davor war sie als technische Leiterin in der ModelOps Division bei GitLab tätig. Sie arbeitete auch mit anderen Unternehmen wie Microsoft und eBay zusammen.
📌
Unsere Gespräche mit Monmayuri werden die folgenden Aspekte behandeln:
- ML- und LLM-Anwendungsfälle bei GitLab
- Weiterentwicklung der ML-Infrastruktur von GitLab zur Unterstützung großer Sprachmodelle (LLMs)
- GitLabs Reise mit LLMs: Von Open Source bis Fine-Tuning
- Training großer Sprachmodelle bei GitLab
- Triton im Vergleich zu PyTorch, Ensembled GPUs und dynamisches Batching für LLM-Inferenz
- Herausforderungen und Forschung bei der Evaluierung von LLMs bei GitLab
- Die LLM-Architektur von GitLab und die Zukunft von LLMs
Maschinelles Lernen (ML) verändert den Lebenszyklus der Softwareentwicklung, und GitLab steht an der Spitze dieser Innovation. GitLab nutzt ML, um Entwickler auf ihrem gesamten Weg zu unterstützen, von der Erstellung von Problemen über das Zusammenführen von Anfragen bis hin zur Bereitstellung von Apps.
Einer der aufregendsten Anwendungsfälle für ML bei GitLab sind große Sprachmodelle (LLMs). GitLab verwendet LLMs und GenAI, um neue Funktionen für seine Produkte zu entwickeln, wie z. B. die Codevervollständigung und die Zusammenfassung von Problemen.
GitLab war an vorderster Front dabei, große Sprachmodelle (LLMs) zu verwenden, um Entwickler zu unterstützen. Infolgedessen musste GitLab seine ML-Infrastruktur weiterentwickeln, um diese komplexen Modelle zu unterstützen.
Um den oben genannten Herausforderungen zu begegnen, hat GitLab eine Reihe von Änderungen an seiner ML-Infrastruktur vorgenommen. Diese Änderungen können in die folgenden Bereiche unterteilt werden:
GitLab war an vorderster Front dabei, große Sprachmodelle (LLMs) zu verwenden, um Entwickler zu unterstützen. In den frühen Tagen begann GitLab mit der Verwendung Open-Source-LLMs, wie Salesforce Code Gen. Da sich die Landschaft jedoch geändert hat und LLMs immer leistungsfähiger geworden sind, hat GitLab dazu übergegangen, seine eigenen LLMs für bestimmte Anwendungsfälle wie die Codegenerierung zu verfeinern.
Die Feinabstimmung von LLMs erfordert erhebliche Investitionen in die Infrastruktur, da diese Modelle sehr umfangreich und komplex sind. GitLab musste neue Schulungs- und Bereitstellungspipelines für LLMs sowie neue Möglichkeiten zur Verwaltung seiner ML-Infrastruktur in einer verteilten Umgebung entwickeln.
Eine der wichtigsten Herausforderungen, mit denen GitLab bei der Feinabstimmung von LLMs konfrontiert war, besteht darin, das richtige Gleichgewicht zwischen Kosten und Latenz zu finden. Die Schulung und Bereitstellung von LLMs kann sehr teuer sein, und es kann auch langsam sein, Ergebnisse zu erzielen. GitLab musste mit verschiedenen Clustergrößen, GPU-Konfigurationen und Batching-Techniken experimentieren, um das richtige Gleichgewicht für seine Bedürfnisse zu finden.
Eine weitere Herausforderung, mit der GitLab konfrontiert war, besteht darin, sicherzustellen, dass seine LLMs genau und zuverlässig sind. LLMs können mit riesigen Text- und Code-Datensätzen trainiert werden, aber diese Datensätze können auch Fehler und Vorurteile enthalten. GitLab musste neue Techniken entwickeln, um seine LLMs zu evaluieren und zu widerlegen.
Trotz der Herausforderungen hat GitLab erhebliche Fortschritte bei der Verwendung von LLMs zur Unterstützung von Entwicklern erzielt. GitLab ist jetzt in der Lage, LLMs in großem Umfang zu trainieren und bereitzustellen, und es verwendet diese Modelle, um neue Funktionen und Produkte zu entwickeln, die den Softwareentwicklungsprozess effizienter und angenehmer machen werden.
Das Training großer Sprachmodelle (LLMs) ist eine herausfordernde Aufgabe, die erhebliche Investitionen in Infrastruktur und Ressourcen erfordert. GitLab war bei der Verwendung von LLMs zur Unterstützung von Entwicklern an vorderster Front, und das Unternehmen hat dabei viel gelernt.
Hier sind einige Erkenntnisse und Erkenntnisse aus GitLabs Erfahrung beim Training von LLMs:
Zusätzlich zu den oben genannten Erkenntnissen hat GitLab auch eine Reihe wertvoller Lektionen darüber gelernt, wie wichtig es ist, ein gutes Verständnis des Basismodells und der Trainingsdaten zu haben. GitLab hat beispielsweise herausgefunden, dass es wichtig ist, das Konstrukt des Basismodells zu kennen und zu wissen, wie man die Trainingsdaten kuratiert, um sie für den gewünschten Anwendungsfall zu optimieren.
GitLab verwendet Triton für LLM-Inferenz, da es sich besser für die Skalierung auf das hohe Volumen an Anfragen eignet, die GitLab empfängt. Triton ist auch einfacher zu umschließen und zu skalieren als andere Modellserver, wie z. B. PyTorch-Server.
GitLab hat noch nicht mit den TGI- oder VLLM-Modellservern von Hugging Face experimentiert, da sich diese noch in einem frühen Entwicklungsstadium befanden, als GitLab seine LLM-Inferenzpipeline zum ersten Mal einsetzte.
Wenn es um dynamisches Batching geht, besteht die Strategie von GitLab darin, für den spezifischen Anwendungsfall, die Last, die Abfrageebene, das Volumen und die Anzahl der verfügbaren GPUs zu optimieren. Wenn GitLab beispielsweise 500 GPUs für ein 7B-Modell hat, kann es eine andere Batch-Strategie verwenden, als wenn es nur ein paar GPUs für ein kleineres Modell hat.
GitLab verwendet auch ein Ensemble von GPUs, um Anfragen zu bearbeiten. Das bedeutet, dass GitLab eine Mischung aus verschiedenen GPU-Typen verwendet, darunter Hochleistungs-GPUs und GPUs mit geringerer Leistung. GitLab verteilt die Anforderungen auf das gesamte Ensemble von GPUs, um Leistung und Kosten zu optimieren.
Im Folgenden finden Sie einige Tipps für den Entwurf einer Architektur zur Zusammenstellung von GPUs und zur Optimierung des Lastenausgleichs:
Hier sind einige konkrete Beispiele dafür, wie GitLab seine Architektur für zusammengesetzte GPUs und dynamisches Batching optimiert hat:
Wenn Sie diese Tipps befolgen, können Sie eine Architektur entwerfen, die große Mengen an LLM-Inferenzanforderungen effizient verarbeiten kann.
Wir haben auch versucht zu streamen, und ich denke, wir prüfen auch Streamings für unsere Drittanbieter - Monmayuri
Die Bewertung der Leistung großer Sprachmodelle (LLMs) ist eine herausfordernde Aufgabe. GitLab hat an diesem Problem gearbeitet und war mit mehreren Herausforderungen konfrontiert, darunter:
GitLab begegnet diesen Herausforderungen durch:
Das Ziel von GitLab ist es, einen skalierbaren und datengesteuerten Ansatz zur Bewertung von LLMs zu entwickeln. Dieser Ansatz wird GitLab dabei helfen, sicherzustellen, dass seine LLMs in der Produktion gut funktionieren und die Bedürfnisse seiner Benutzer erfüllen.
GitLab forscht auch an neuen Möglichkeiten zur Bewertung von LLMs. Zu den Forschungsrichtungen, die GitLab derzeit erforscht, gehören:
Die Forschung von GitLab zur Bewertung von LLMs ist noch nicht abgeschlossen. GitLab hat es sich zur Aufgabe gemacht, neue und innovative Methoden zur Bewertung von LLMs zu entwickeln, um sicherzustellen, dass seine LLMs den Bedürfnissen seiner Nutzer entsprechen.
Die LLM-Architektur von GitLab ist ein umfassender Ansatz für Training, Bewertung und Bereitstellung von LLMs. Die Architektur ist so konzipiert, dass sie flexibel und skalierbar ist, sodass GitLab problemlos neue Technologien einführen und die Bedürfnisse seiner Benutzer erfüllen kann.
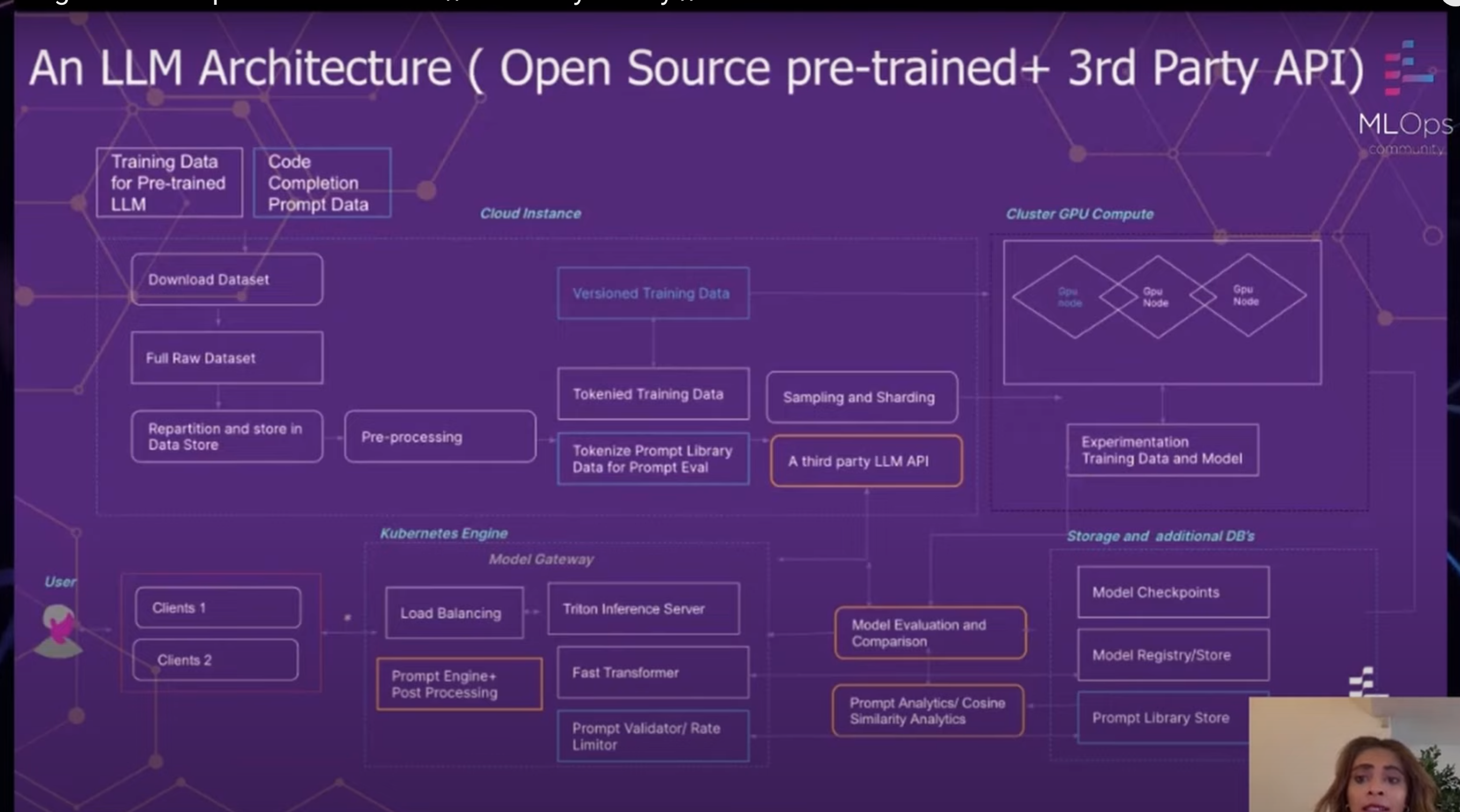
Die Architektur besteht aus mehreren Schlüsselkomponenten:
Die LLM-Architektur von GitLab ist ein leistungsstarkes Tool, das es GitLab ermöglicht, LLMs in großem Maßstab zu trainieren, zu evaluieren und bereitzustellen. Die Architektur ist so konzipiert, dass sie flexibel und skalierbar ist, sodass GitLab problemlos neue Technologien einführen und die Bedürfnisse seiner Benutzer erfüllen kann.
LLMs sind immer noch eine relativ neue Technologie, aber sie haben das Potenzial, viele Branchen zu revolutionieren. GitLab glaubt, dass LLMs einen erheblichen Einfluss auf die Softwareentwicklungsbranche haben werden.
GitLab verwendet bereits LLMs, um seine Produkte und Dienstleistungen zu verbessern. GitLab verwendet beispielsweise LLMs, um Codevorschläge zu generieren, Sicherheitslücken zu erklären und die Benutzererfahrung seiner Produkte zu verbessern.
GitLab ist der Ansicht, dass auch andere Organisationen in LLMs investieren sollten. LLMs haben das Potenzial, Produktivität, Effizienz und Qualität in vielen Branchen zu verbessern.
GitLab empfiehlt Unternehmen, in die folgenden Bereiche zu investieren, um im LLM-Bereich immer einen Schritt voraus zu sein:
Durch Investitionen in diese Bereiche können Unternehmen im LLM-Bereich der Konkurrenz immer einen Schritt voraus sein und die Vorteile dieser leistungsstarken Technologie nutzen.
Schaue weiter TrueML YouTube-Serie und das TrueML lesen Blog-Serie.
Wahre Gießerei ist ein ML Deployment PaaS über Kubernetes, um die Workflows von Entwicklern zu beschleunigen und ihnen gleichzeitig volle Flexibilität beim Testen und Bereitstellen von Modellen zu bieten und gleichzeitig die volle Sicherheit und Kontrolle für das Infra-Team zu gewährleisten. Über unsere Plattform ermöglichen wir Teams für maschinelles Lernen bereitstellen und überwachen Modelle innerhalb von 15 Minuten mit 100% iger Zuverlässigkeit, Skalierbarkeit und der Möglichkeit, innerhalb von Sekunden rückgängig zu machen. So können sie Kosten sparen und Modelle schneller für die Produktion freigeben, wodurch ein echter Geschäftswert erzielt wird.
TrueFoundry AI Gateway bietet eine Latenz von ~3—4 ms, verarbeitet mehr als 350 RPS auf einer vCPU, skaliert problemlos horizontal und ist produktionsbereit, während LiteLM unter einer hohen Latenz leidet, mit moderaten RPS zu kämpfen hat, keine integrierte Skalierung hat und sich am besten für leichte Workloads oder Prototyp-Workloads eignet.











Die neuesten Nachrichten, Artikel und Ressourcen werden in Ihren Posteingang gesendet
© 2026 Alle Rechte vorbehalten.





.png)
.webp)

.webp)
.webp)


.webp)
.webp)
.webp)
.png)




